






前言:数据库范式是数据库的设计概念,或者说是数据库的设计准则,就跟野外求生指南一样,书上怎么说,你就怎么做,数据库范式说怎么设计,那你就怎么设计。数据库范式在数据库中非常重要,可以减少数据繁杂,提高查询效率。
一,数据库第一范式
特点:
1,数据库第一范式是最基本的范式,是其他范式的基础。
2,根据第一范式设计的数据库表每列都是不可分割的基本数据项,同一个列不能有多个值,确保每列保持原子性。
简单介绍特点2:
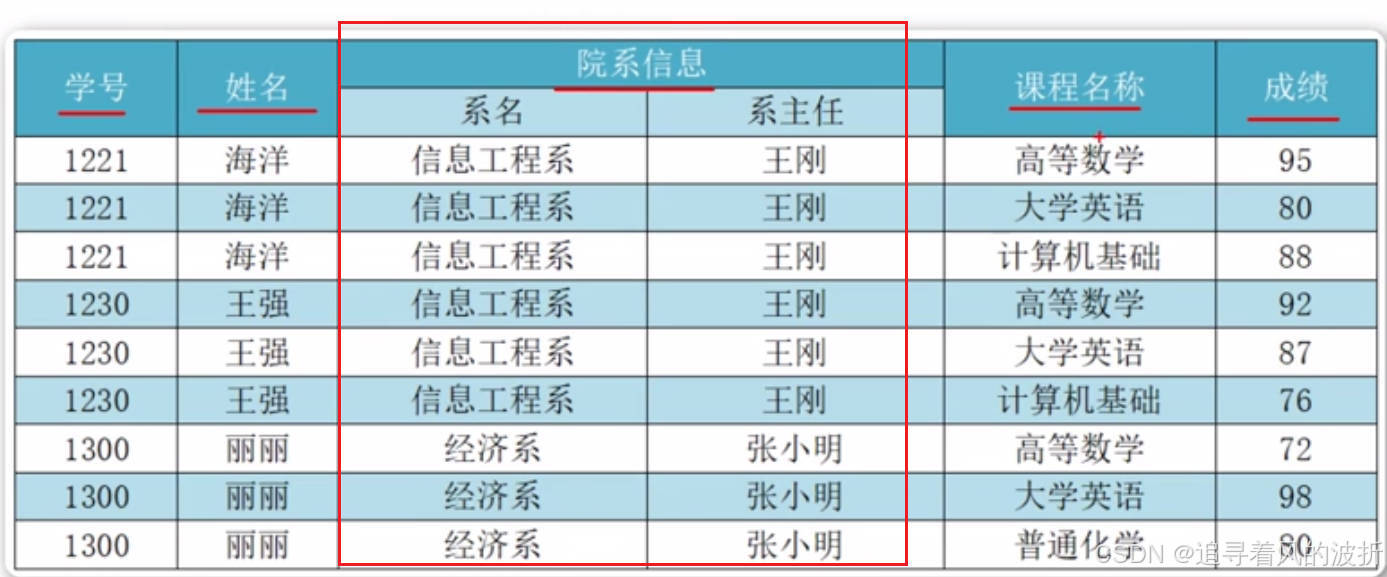
我们可以看到上面图片中院系信息这一列就不是原子列,因为它还可以再分为“系名”和“系主任”这两个列,而正确的是下面的
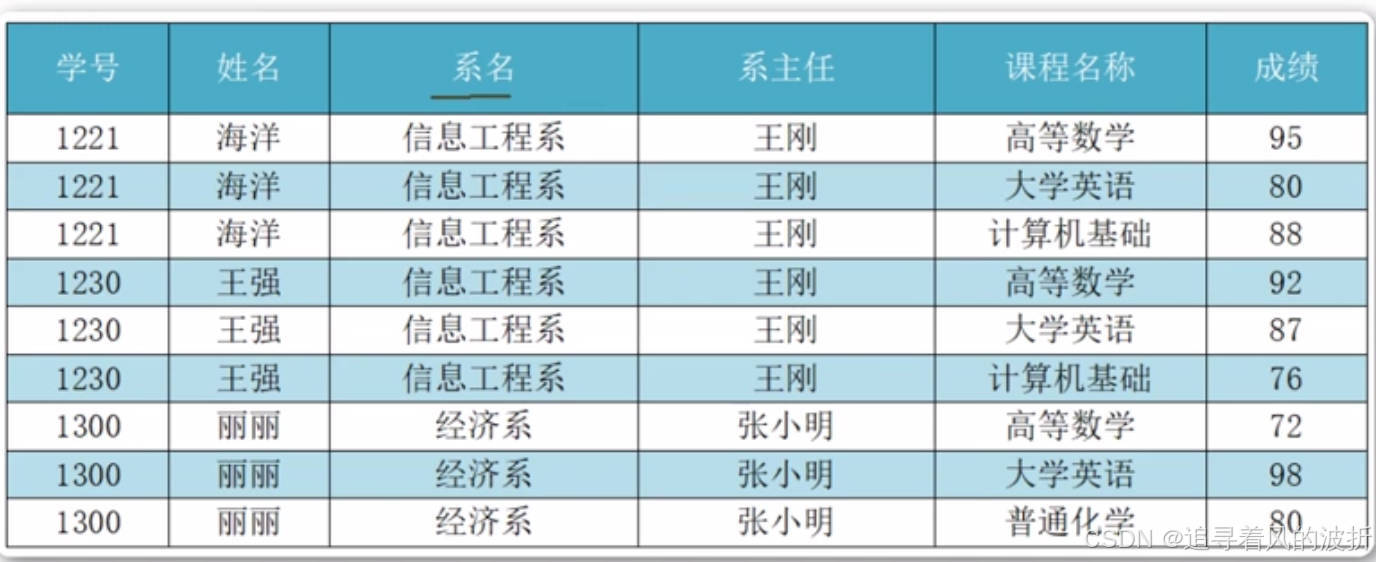
这就是个原子列了。
第一范式的弊端:
1,数据繁杂
可以看到,上面红框部分信息重复,这就是数据重复,但因为该学生的课程不一样,我们只能重复添加 。
2,数据修改复杂
可以看到,如果我们要把上面画红框中的某一个信息修改,比如把信息工程系修改,那么我就需要修改三次。
二,数据库第二范式
数据库第二范式就是解决第一范式的,第一范式把大量信息存进表里,造成对数据操作是的问题 。第一范式要保证数据库表中的每一列都和主键相关,即表中的非主键列完全依赖于主键,而不是依赖于主键的一部分,不能和主键的某一部分相关(主要针对联合主键而言,联合主键是表中有两个以上的列是主键列),如果表中只有一个列是主键列,那其它列就都要和这个唯一的主键列产生联系,如果表中有两个及以上的列是主键列,如:
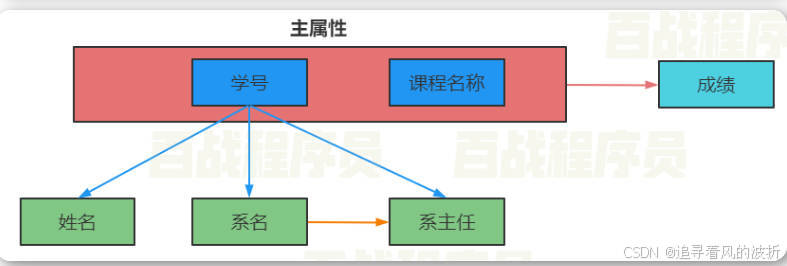 这个图中,主键列有两个,一是学号,二是课程名称,这时不满足 数据库表中的每一列都和主键相关 ,怎么办呢?简单,我就把表拆成两个表,一个表中的主键列是学号,一个表中的主键列是课程名称,把他们各自相关的列分到各自的表中,如下:
这个图中,主键列有两个,一是学号,二是课程名称,这时不满足 数据库表中的每一列都和主键相关 ,怎么办呢?简单,我就把表拆成两个表,一个表中的主键列是学号,一个表中的主键列是课程名称,把他们各自相关的列分到各自的表中,如下: 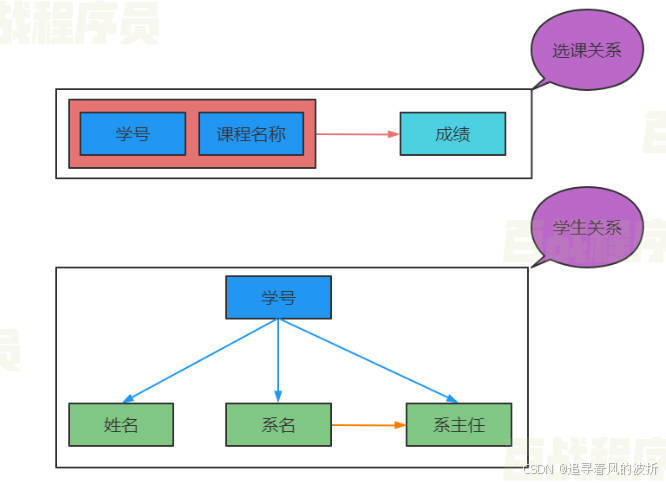
下面我们来看三个列子来区分第二范式 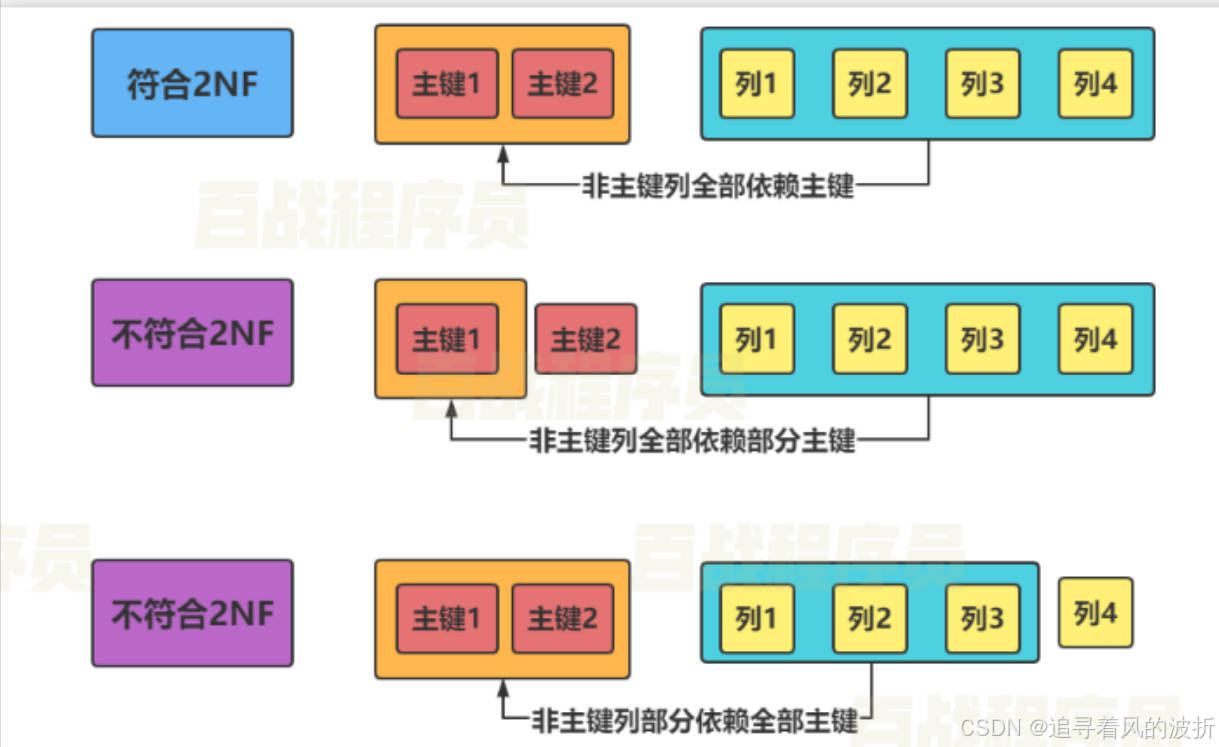 总结来说就是,全部的非主键全部依赖主键。
总结来说就是,全部的非主键全部依赖主键。
三,数据库第三范式
1,特点:
其必须满足第二范式;数据表中的每一列数据都和主键直接相关,而不能间接相关 。
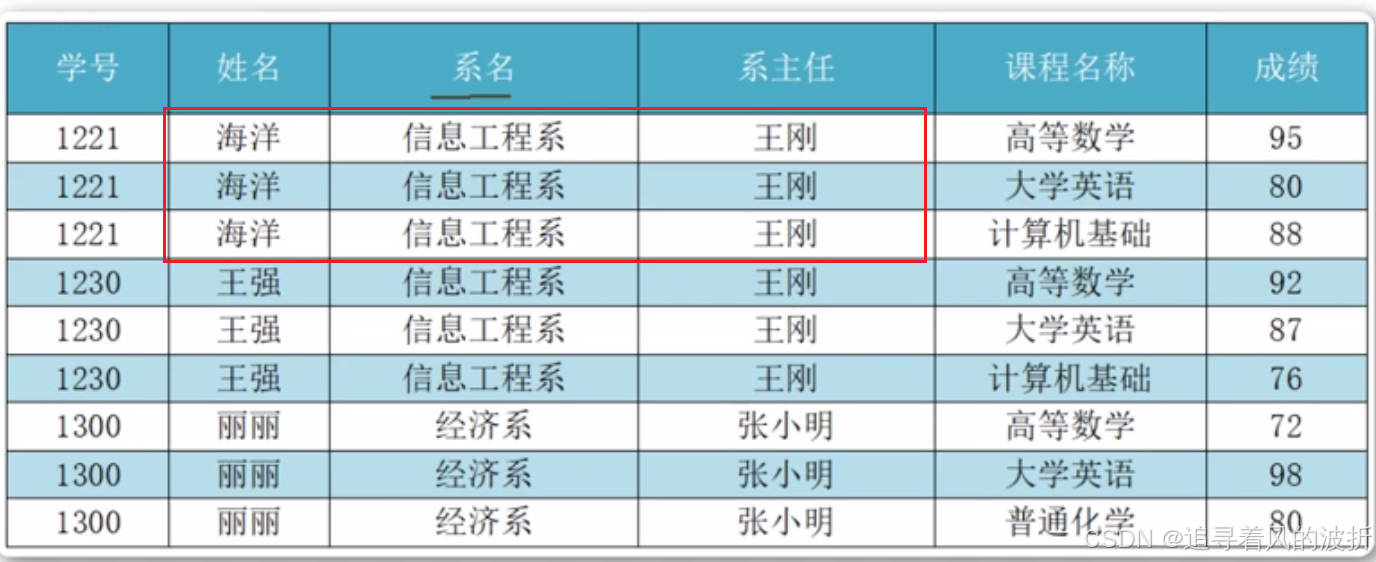
举例: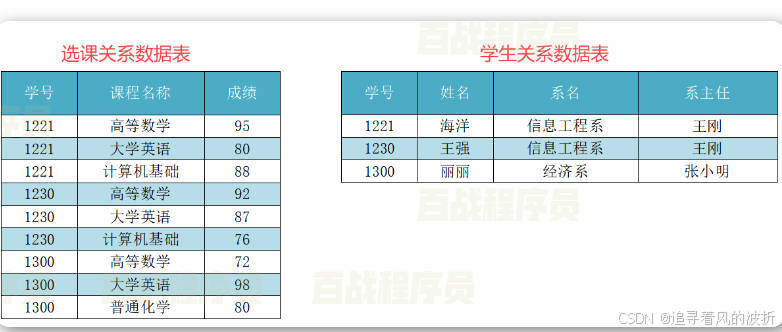 在关系数据表中,我们以学号为主属性,那么就要求姓名、系名、系主任这三个列的数据都和主键直接相关,就是我们只能通过学号查找到这三个列的数据,但是现在我们看在这个表中,我们也可以通过姓名查到系名和系主任的信息(别问我为什么,select 系名,系主任 from 学生关系数据表 where 姓名 like '海洋'),这就代表系名和系主任不是和主键直接相关的,相当于古代的皇子血脉不纯呗,那么这时我们就要对表在分了,look下面:
在关系数据表中,我们以学号为主属性,那么就要求姓名、系名、系主任这三个列的数据都和主键直接相关,就是我们只能通过学号查找到这三个列的数据,但是现在我们看在这个表中,我们也可以通过姓名查到系名和系主任的信息(别问我为什么,select 系名,系主任 from 学生关系数据表 where 姓名 like '海洋'),这就代表系名和系主任不是和主键直接相关的,相当于古代的皇子血脉不纯呗,那么这时我们就要对表在分了,look下面: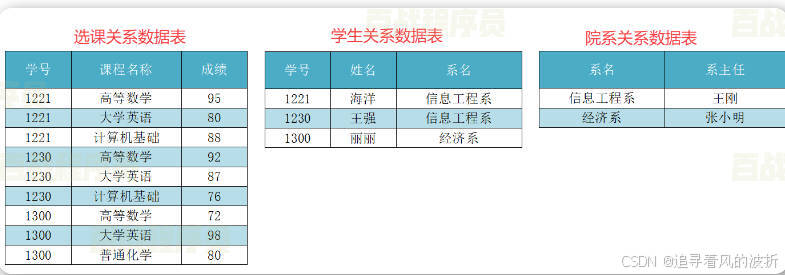 这样一来,分成三个表,在第三个表中,系主任就是和系名就是直接相关了,但有老铁会问,为啥学生关系表中系名还在?那我不就仍可以通过姓名查到系名,那系名不就仍和学号间接相关?那不就仍然不满足第3范式?确实是这样,理由是虽然我们通过拆分表将第二范式变成第三范式,这个数据冗余减少,但是呢,表格多了,表格太多也不行,所以分出去一部分,能显现它是第3范式就行,这个如果真要细分成绝对的第三范式,还可以将学生关系数据表中的系名拆除去。
这样一来,分成三个表,在第三个表中,系主任就是和系名就是直接相关了,但有老铁会问,为啥学生关系表中系名还在?那我不就仍可以通过姓名查到系名,那系名不就仍和学号间接相关?那不就仍然不满足第3范式?确实是这样,理由是虽然我们通过拆分表将第二范式变成第三范式,这个数据冗余减少,但是呢,表格多了,表格太多也不行,所以分出去一部分,能显现它是第3范式就行,这个如果真要细分成绝对的第三范式,还可以将学生关系数据表中的系名拆除去。
2,优点
好了,接下来 我们看看第三范式的优点,就以上面三个表为例子
1,添加数据
当我们向表中添加数据,比如向院系关系表中添加‘法律系 李丽’时,我们可以直接向里面添了,但是在第一和第二范式中,我们要添加‘法律系 李丽’ ,还要添加什么学号、姓名、课程名称......现在,就只有添加两个就行,这就跟你去求县长办事,先得给科长送礼打点认识处长,再给处长送礼打点认识副县长,再给副县长送礼打点认识县长,来来回回送了一堆礼,但是现在,你只用给县长送礼就OK了。
2,修改、删除数据
这个我就不多讲了,和上面一样,因为表分的细,所以相关联的少,对一部分数据进行处理时不用考虑另一部分数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









