







转自:https://blog.csdn.net/aiynmimi/article/details/53993803
有下面两个表:将表tab1中id值与和表tab2中id值相同的行的val更新为tab2中val的值. select * from tab1; 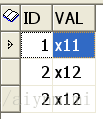
select * from tab2

最容易犯的错误是:update tab1 set val=(select val from tab2 where tab1.id=tab2.id);
更新完后的结果是:select * from tab1,在tab1中有的行,如果在tab2中没有对应的行,值被更新为null.
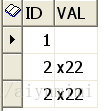
改正为:
update tab1 set val = (select val from tab2 where tab1.id = tab2.id) where exists (select 1 from tab2 where tab1.id = tab2.id)但是如果tab2中有多条对应tab1中一条的情况也会出错.
最好的方法是用merge语法:
merge into tab1
using tab2
on(tab1.id=tab2.id)
when matched then
update set tab1.val = tab2.val 同样,如果tab2中有多条对应tab1中一条的情况也会出错:ORA-30926: unable to get a stable set of rows in the source tables
比如在tab2中再插入一条 insert into tab2 values(2,’xxxx’)
可以通过在using中的subquery中将重复记录过滤来避免这种错误,merge终极版:
merge into tab1
using (select * FROM tab2 X WHERE X.ROWID =
(SELECT MAX(Y.ROWID) FROM tab2 Y WHERE X.ID = Y.ID)) tab2
on(tab1.id=tab2.id)
when matched then
update set tab1.val = tab2.val














 1396
1396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









