






Apache Ozone 是一种分布式、可扩展和高性能的对象存储,可与Cloudera 数据平台(CDP) 一起使用,可以扩展到数十亿个不同大小的对象。它被设计为原生的对象存储,可提供极高的规模、性能和可靠性,以使用 S3 API 或传统的 Hadoop API 处理多个分析工作负载。
今天的平台所有者、企业所有者、数据开发人员、分析师和工程师在 Cloudera 数据平台CDP上创建新的应用程序,他们必须决定在哪里以及如何存储这些数据。结构化数据(例如姓名、日期、ID 等)将存储在常规 SQL 数据库中,如 Hive 或 Impala 数据库。还有更新的 AI/ML 应用程序需要数据存储,使用 Python Boto API 等开发人员友好的范例针对非结构化数据进行了优化。
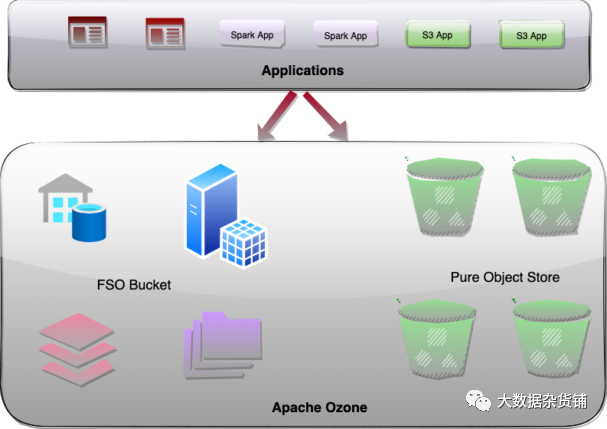
Apache Ozone 满足各种垂直行业的这两种存储用例,其中包括:
-
制造业,他们生成的数据除了提高运营效率外,还可以提供新的商机,例如预测性维护
-
零售,在零售流程的所有阶段都使用大数据——从产品开发、定价、需求预测到商店的库存优化。
-
医疗保健,大数据用于提高盈利能力、进行基因组研究、改善患者体验和挽救生命。
类似的用例存在于所有其他垂直领域,如保险、金融和电信。
在这篇博文中,我们将讨论具有 Hadoop 核心文件系统 (HCFS) 和对象存储(如 Amazon S3)功能的单个 Ozone 集群。一种统一的存储架构,可以同时存储文件和对象,并提供灵活、可扩展和高性能的系统。此外,可以通过不同的协议为各种用例访问存储在 Ozone 中的数据,从而消除数据重复的需要,从而降低风险并优化资源利用率。
工作负载的多样性
当今快速增长的数据密集型工作负载推动了分析、机器学习、人工智能和智能系统,需要一个既灵活又高效的存储平台。Apache Ozone 原生提供与 Amazon S3 和 Hadoop 文件系统兼容的端点,旨在与企业级数据仓库、批处理、机器学习和流式工作负载无缝协作。根据与存储服务集成的性质,Ozone 支持各种工作负载,包括以下突出的存储用例:
-
Ozone 作为纯 S3 对象存储语义
-
Ozone 作为 HDFS 的替代文件系统来解决可扩展性问题
-
Ozone 作为 Hadoop 兼容文件系统 (“HCFS”),具有有限的 S3 兼容性。例如,对于其中带有“/”的关键路径,将创建中间目录
-
多个工作负载的相同数据的互操作性:多协议访问

以下是需要 HCFS 语义的大数据工作负载的主要方面。
-
Apache Hive:删除表查询、删除托管的 Impala 表、递归目录删除和目录移动操作更快且高度一致,在任何失败的情况下都不会出现任何部分结果。有关 Ozone 的性能优势和原子性保证的更多详细信息,请参阅我们早期的Cloudera 博客。
-
这些操作也很有效,不需要 O(n) 对命名空间服务器的 RPC 调用,其中“n”是表的文件系统对象的数量。
-
Apache Hive、Apache Impala、Apache Spark 和传统 MapReduce 等大数据分析工具的作业提交者经常在作业结束时将其临时输出文件重命名为最终输出位置,以公开可见。作业的性能直接受到重命名操作完成速度的影响。
将文件和对象集中在一个屋檐下
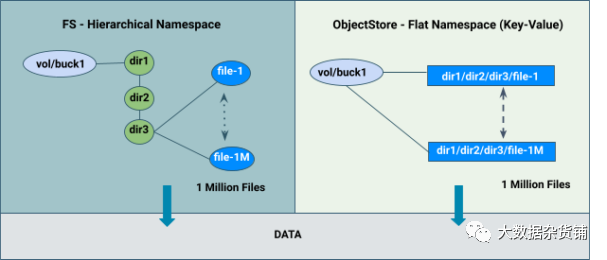
统一设计表示存储在单个系统中的文件、目录和对象。Apache Ozone 通过在元数据命名空间服务器中引入存储桶类型,通过使用一些新颖的架构选择来实现这一重要功能。这允许单个 Ozone 集群通过有效地存储文件、目录、对象和存储桶来同时具备 Hadoop 核心文件系统 (HCFS) 和对象存储(如 Amazon S3)功能的功能。它消除了将数据从对象存储移植到文件系统的需要,以便分析应用程序可以读取它。相同的数据可以作为对象或文件读取。
Bucket类型
Apache Ozone 对象存储最近在HDDS-5672中实现了多协议感知存储桶布局功能,可在 CDP-7.1.8 发布版本中使用。这里的想法是根据存储用例对Ozone的Bucket进行分类。
FILE_SYSTEM_OPTIMIZED存储桶(“FSO”)
-
具有类似于 HDFS 的目录和文件的分层文件系统命名空间视图。
-
提供类似于 HDFS 的高性能命名空间元数据操作。
-
提供使用 S3 API* 进行读/写的功能。
OBJECT_STORE存储桶(“OBS”)
- 提供类似于 Amazon S3 的平面命名空间(键值)。
旧版的存储桶
- 代表现有的预先创建的 Ozone 存储桶,用于从以前的 Ozone 版本平滑升级到新的 Ozone 版本。

使用 Ozone shell 命令创建 FSO/OBS/LEGACY 存储桶。用户可以在布局参数中指定存储桶类型。
$ozone sh bucket create --layout FILE_SYSTEM_OPTIMIZED /s3v/fso-bucket
$ozone sh bucket create --layout OBJECT_STORE /s3v/obs-bucket
$ozone sh bucket create --layout LEGACY /s3v/bucket
BucketLayout Feature Demo,介绍了Ozone shell、Ozone FS和aws cli操作。
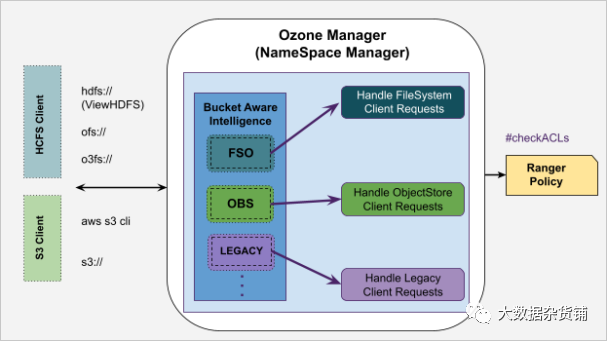
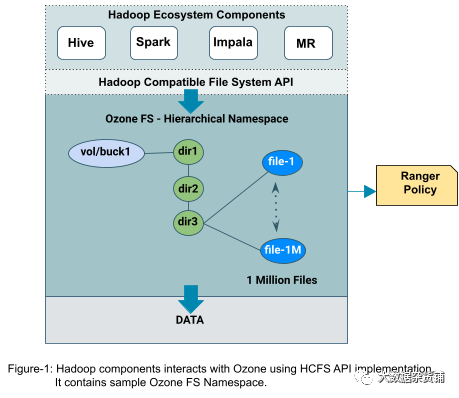
Ozone的Namespace命名空间概述
以下是 Ozone 如何管理其元数据命名空间并根据存储桶类型处理来自不同工作负载的客户端请求的快速概述。此外,bucket 类型的概念在架构上以可扩展的方式设计,以支持未来的 NFS、CSI 等多协议。
===
Ranger策略
Ranger 策略启用对 Ozone 资源(卷、存储桶和密钥)的授权访问。Ranger 策略模型捕获以下详细信息:
-
资源类型、层次结构、支持递归操作、区分大小写、支持通配符等
-
对特定资源执行的权限/操作,例如读取、写入、删除和列表
-
允许、拒绝或例外授予用户、组和角色的权限
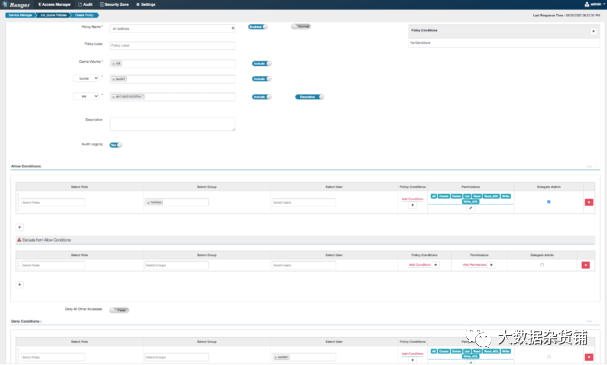
与 HDFS 类似,使用 FSO 资源,Ranger 支持重命名和递归目录删除操作的授权,并提供性能优化的解决方案,而与其中包含的大量子路径(目录/文件)无关。
跨集群的工作负载迁移或复制
分层文件系统(“FILE_SYSTEM_OPTIMIZED”)功能可以轻松地将工作负载从 HDFS 迁移到 Apache Ozone,而无需显着的性能变化。此外,Apache Ozone 与 Hive、Spark 和 Impala 等 Apache 数据分析工具无缝集成,同时保留了 Ranger 策略和性能特征。
===
数据互通:多协议客户端访问
用户可以将他们的数据存储到 Apache Ozone 集群中,并通过不同的协议访问相同的数据:Ozone S3 API*、Ozone FS、Ozone shell 命令等。
例如,用户可以使用 Ozone S3 API* 将数据摄取到 Apache Ozone,并且可以使用 Apache Hadoop 兼容的文件系统接口访问相同的数据,反之亦然。
基本上,这种多协议功能对于主要面向文件系统 (如工作负载)但希望添加一些对象存储功能支持的系统具有吸引力。这可以通过本地对象存储提高用户平台的效率。此外,存储在 Ozone 中的数据可以在各种用例中共享,从而消除了数据复制的需要,从而降低了风险并优化了资源利用率。

===
总结
Apache Ozone 集群在 CDP 上提供了一个统一的架构,可以通过多协议访问有效地存储文件、目录和对象。借助此功能,用户可以将其数据存储到单个 Ozone 集群中,并使用不同的协议(Ozone S3 API*、Ozone FS)为各种用例访问相同的数据,从而消除数据复制的需要,从而降低风险并优化资源利用率。
简而言之,将文件和对象协议组合到一个 Ozone 存储系统中可以带来效率、规模和高性能的优势。现在,用户在如何存储数据和如何设计应用程序方面拥有更大的灵活性。
S3 API* – 指的是 S3 API 协议的 Amazon S3 实施。
原文作者:Aryan Gupta, and Sailaja Polavarapu
**原文链接:**https://blog.cloudera.com/a-flexible-and-efficient-storage-system-for-diverse-workloads/















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









