







1. 神经网络
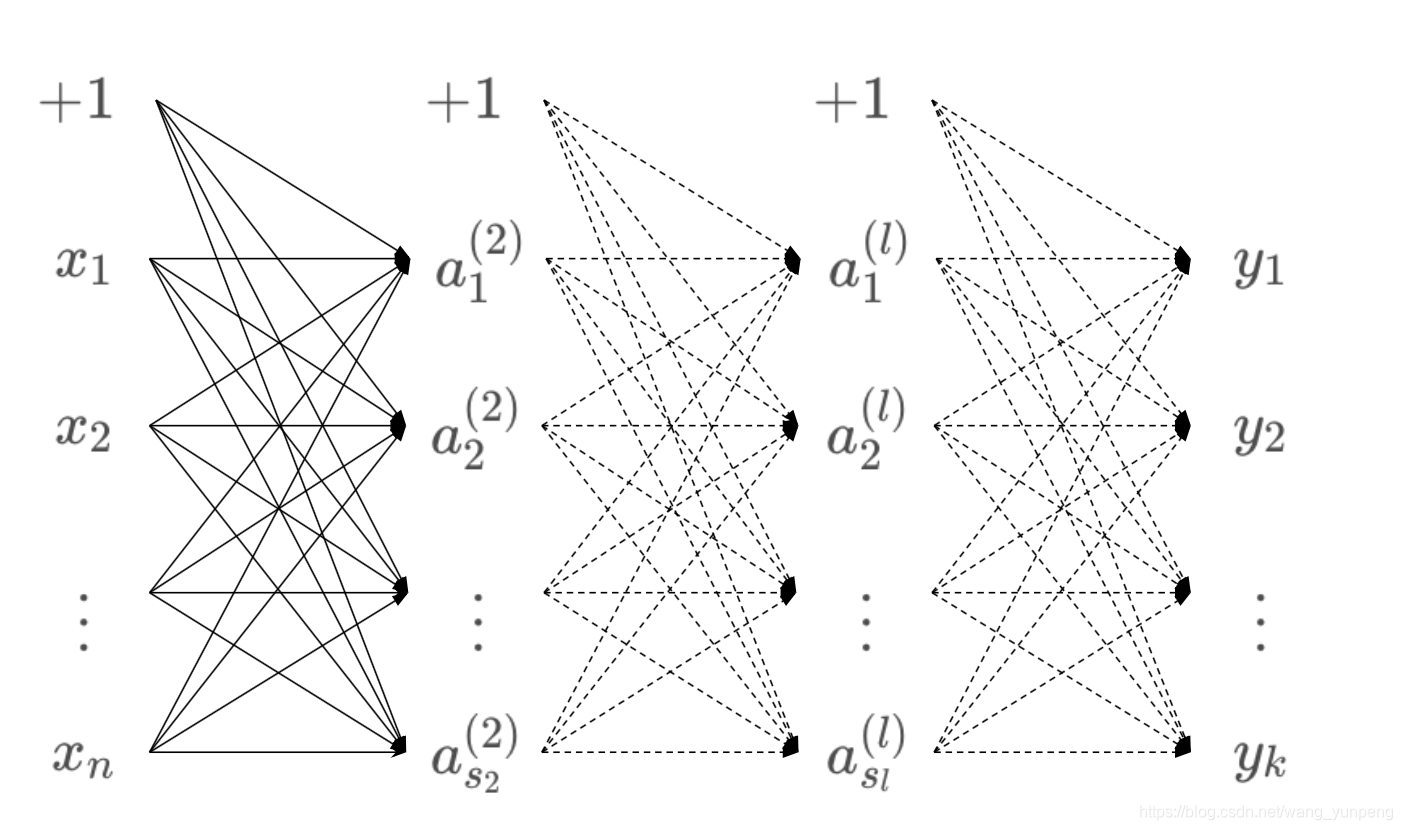
输入
[
x
1
,
x
2
,
.
.
.
,
x
n
]
[x_1, x_2,...,x_n]
[x1,x2,...,xn],输出
[
y
1
,
y
2
,
.
.
.
,
y
k
]
[y_1, y_2,...,y_k]
[y1,y2,...,yk]。
当输出分类
k
>
2
k>2
k>2时,使用
[
1
0
.
.
.
0
]
,
[
0
1
.
.
.
0
]
,
[
0
.
.
.
1
0
]
,
[
0
0
.
.
.
1
]
\begin{bmatrix}1\\0\\... \\0\end{bmatrix},\begin{bmatrix}0\\1\\...\\0\end{bmatrix},\begin{bmatrix}0\\...\\1\\0\end{bmatrix},\begin{bmatrix}0\\0\\...\\1\end{bmatrix}
⎣⎢⎢⎡10...0⎦⎥⎥⎤,⎣⎢⎢⎡01...0⎦⎥⎥⎤,⎣⎢⎢⎡0...10⎦⎥⎥⎤,⎣⎢⎢⎡00...1⎦⎥⎥⎤
作为输出。
2. 代价函数
J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K y k ( i ) l o g ( h Θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − ( h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s ( l + 1 ) ( Θ j i ( l ) ) 2 J(\Theta)=-\frac{1}{m}\left[\sum_{i=1}^{m}\sum_{k=1}^{K}y_k^{(i)}log(h_{\Theta}(x^{(i)}))_k+(1-y_k^{(i)})log(1-(h_{\Theta}(x^{(i)}))_k)\right]+\frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{(l+1)}}(\Theta_{ji}^{(l)})^2 J(Θ)=−m1[i=1∑mk=1∑Kyk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑s(l+1)(Θji(l))2
3. 前向传播
a ( 1 ) = x a ( l ) = h Θ ( l ) ( a ( l − 1 ) ^ ) = g ( Θ ( l − 1 ) [ 1 a ( l − 1 ) ] ) , 1 < l ≤ L Θ ( l ) ∈ R s l + 1 × ( s l + 1 ) a^{(1)}=x \\a^{(l)} = h_{\Theta^{(l)}}(\widehat{a^{(l-1)}})=g\left({\Theta^{(l-1)}}\begin{bmatrix}1\\a^{(l-1)}\end{bmatrix}\right),1<l\le L \\\Theta^{(l)} \in \Bbb R^{s_{l+1}\times(s_l+1)} a(1)=xa(l)=hΘ(l)(a(l−1) )=g(Θ(l−1)[1a(l−1)]),1<l≤LΘ(l)∈Rsl+1×(sl+1)
4. 后向传播
δ ( L ) = ( a ( L ) − y ) a ( L ) ( 1 − a ( L ) ) δ ( l ) = ( Θ ( l ) ^ ) T δ ( l + 1 ) . ∗ a ( l ) . ∗ ( 1 − a ( l ) ) , 1 < l < L Θ ( l ) ^ 为 不 包 含 θ 0 的 Θ ( l ) \delta^{(L)} = (a^{(L)}-y)a^{(L)}(1-a^{(L)}) \\ \delta^{(l)} = (\widehat{\Theta^{(l)}})^T\delta^{(l+1)}.*a^{(l)}.*(1-a^{(l)}), 1<l<L \\\widehat{\Theta^{(l)}}为不包含\theta_0的\Theta^{(l)} δ(L)=(a(L)−y)a(L)(1−a(L))δ(l)=(Θ(l) )Tδ(l+1).∗a(l).∗(1−a(l)),1<l<LΘ(l) 为不包含θ0的Θ(l)
5. 后向传播推导
由前向传播可得:
[
θ
1
,
0
(
l
)
θ
1
,
1
(
l
)
.
.
.
θ
1
,
s
l
(
l
)
θ
2
,
0
(
l
)
θ
2
,
1
(
l
)
.
.
.
θ
2
,
s
l
(
l
)
.
.
.
.
.
.
.
.
.
.
.
.
θ
s
(
l
+
1
)
,
0
(
l
)
θ
s
(
l
+
1
)
,
1
(
l
)
.
.
.
θ
s
(
l
+
1
)
,
s
l
(
l
)
]
[
1
a
1
(
l
)
a
2
(
l
)
.
.
.
a
s
l
(
l
)
]
=
[
z
1
(
l
+
1
)
z
2
(
l
+
1
)
.
.
.
z
s
(
l
+
1
)
(
l
+
1
)
]
→
g
(
x
)
→
[
a
1
(
l
+
1
)
a
2
(
l
+
1
)
.
.
.
a
s
(
l
+
1
)
(
l
+
1
)
]
\begin{bmatrix}\theta_{1,0}^{(l)} & \theta_{1,1}^{(l)} & ... & \theta_{1,s_l}^{(l)}\\\theta_{2,0}^{(l)} & \theta_{2,1}^{(l)} & ... & \theta_{2,s_l}^{(l)}\\... & ... & ... & ...\\\theta_{s_{(l+1)},0}^{(l)} & \theta_{s_{(l+1)},1}^{(l)} & ... & \theta_{s_{(l+1)},s_l}^{(l)}\\\end{bmatrix}\begin{bmatrix}1 \\a_1^{(l)} \\a_2^{(l)} \\... \\a_{s_l}^{(l)} \\\end{bmatrix}=\begin{bmatrix}z_1^{(l+1)} \\z_2^{(l+1)} \\... \\z_{s_{(l+1)}}^{(l+1)} \\\end{bmatrix}\to g(x) \to\begin{bmatrix}a_1^{(l+1)} \\a_2^{(l+1)} \\... \\a_{s_{(l+1)}}^{(l+1)} \\\end{bmatrix}\\
⎣⎢⎢⎢⎡θ1,0(l)θ2,0(l)...θs(l+1),0(l)θ1,1(l)θ2,1(l)...θs(l+1),1(l)............θ1,sl(l)θ2,sl(l)...θs(l+1),sl(l)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎡1a1(l)a2(l)...asl(l)⎦⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎡z1(l+1)z2(l+1)...zs(l+1)(l+1)⎦⎥⎥⎥⎤→g(x)→⎣⎢⎢⎢⎡a1(l+1)a2(l+1)...as(l+1)(l+1)⎦⎥⎥⎥⎤
a
i
(
l
+
1
)
=
g
(
z
i
(
l
+
1
)
)
=
g
(
θ
i
,
0
(
l
)
+
θ
i
,
1
(
l
)
a
1
(
l
)
+
θ
i
,
2
(
l
)
a
2
(
l
)
+
.
.
.
+
θ
i
,
s
l
(
l
)
a
s
1
(
l
)
)
a_i^{(l+1)} = g(z_i^{(l+1)}) = g(\theta_{i,0}^{(l)}+\theta_{i,1}^{(l)}a_1^{(l)}+\theta_{i,2}^{(l)}a_2^{(l)}+...+\theta_{i,s_l}^{(l)}a_{s_1}^{(l)})\\
ai(l+1)=g(zi(l+1))=g(θi,0(l)+θi,1(l)a1(l)+θi,2(l)a2(l)+...+θi,sl(l)as1(l))
设输出对激励输入的偏导数为当前输入的误差,则:
d
J
(
x
,
θ
)
=
δ
i
(
l
+
1
)
d
(
z
i
(
l
+
1
)
)
=
δ
i
(
l
+
1
)
d
(
∑
k
=
0
s
l
θ
i
,
k
(
l
)
a
k
(
l
)
)
(1)
dJ(x,\theta)=\delta_i^{(l+1)}d(z_i^{(l+1)}) = \delta_i^{(l+1)}d(\sum_{k=0}^{s_l}\theta_{i, k}^{(l)}a_k^{(l)}) \tag{1}
dJ(x,θ)=δi(l+1)d(zi(l+1))=δi(l+1)d(k=0∑slθi,k(l)ak(l))(1)
所以有:
d
J
(
x
,
θ
)
d
(
z
m
(
l
)
)
=
d
J
(
x
,
θ
)
d
(
z
(
l
+
1
)
)
d
(
z
(
l
+
1
)
)
d
(
z
m
(
l
)
)
=
∑
i
=
1
s
l
+
1
δ
i
(
l
+
1
)
d
(
∑
k
=
0
s
l
θ
i
,
k
(
l
)
a
k
(
l
)
)
/
d
(
z
m
(
l
)
)
=
∑
i
=
1
s
l
+
1
δ
i
(
l
+
1
)
∑
k
=
0
s
l
θ
i
,
k
(
l
)
d
(
a
k
(
l
)
)
d
(
z
m
(
l
)
)
=
∑
i
=
1
s
l
+
1
δ
i
(
l
+
1
)
θ
i
,
m
(
l
)
a
m
(
l
)
(
1
−
a
m
(
l
)
)
\begin{aligned} \frac{dJ(x,\theta)}{d(z_m^{(l)})} &= \frac{dJ(x,\theta)}{d(z^{(l+1)})}\frac{d(z^{(l+1)})}{d(z_m^{(l)})}=\sum_{i=1}^{s_{l+1}}\delta_i^{(l+1)}d(\sum_{k=0}^{s_l}\theta_{i, k}^{(l)}a_k^{(l)})/d(z_m^{(l)}) \\&=\sum_{i=1}^{s_{l+1}}\delta_i^{(l+1)}\sum_{k=0}^{s_l}\theta_{i, k}^{(l)}\frac{d(a_k^{(l)})}{d(z_m^{(l)})}=\sum_{i=1}^{s_{l+1}}\delta_i^{(l+1)}\theta_{i, m}^{(l)}a_m^{(l)}(1-a_m^{(l)})\\ \end{aligned}
d(zm(l))dJ(x,θ)=d(z(l+1))dJ(x,θ)d(zm(l))d(z(l+1))=i=1∑sl+1δi(l+1)d(k=0∑slθi,k(l)ak(l))/d(zm(l))=i=1∑sl+1δi(l+1)k=0∑slθi,k(l)d(zm(l))d(ak(l))=i=1∑sl+1δi(l+1)θi,m(l)am(l)(1−am(l))
得到:
δ
m
(
l
)
=
a
m
(
l
)
(
1
−
a
m
(
l
)
)
∑
i
=
1
s
l
+
1
δ
i
(
l
+
1
)
θ
i
,
m
(
l
)
\delta_m^{(l)}=a_m^{(l)}(1-a_m^{(l)})\sum_{i=1}^{s_{l+1}}\delta_i^{(l+1)}\theta_{i, m}^{(l)}\\
δm(l)=am(l)(1−am(l))i=1∑sl+1δi(l+1)θi,m(l)
向量扩充:
[
δ
1
(
l
)
δ
2
(
l
)
.
.
.
δ
s
l
(
l
)
]
=
[
a
1
(
l
)
a
2
(
l
)
.
.
.
a
s
l
(
l
)
]
.
∗
(
1
−
[
a
1
(
l
)
a
2
(
l
)
.
.
.
a
s
l
(
l
)
]
)
.
∗
(
[
θ
1
,
1
(
l
)
θ
2
,
1
(
l
)
.
.
.
θ
s
l
+
1
,
1
(
l
)
θ
1
,
2
(
l
)
θ
2
,
2
(
l
)
.
.
.
θ
s
l
+
1
,
2
(
l
)
.
.
.
θ
1
,
s
l
(
l
)
θ
2
,
s
l
(
l
)
.
.
.
θ
s
l
+
1
,
s
l
(
l
)
]
[
δ
1
(
l
+
1
)
δ
2
(
l
+
1
)
.
.
.
δ
s
l
+
1
(
l
+
1
)
]
)
\begin{bmatrix}\delta_1^{(l)} \\ \delta_2^{(l)} \\ ... \\ \delta_{s_l}^{(l)}\end{bmatrix}=\begin{bmatrix}a_1^{(l)} \\ a_2^{(l)} \\ ... \\ a_{s_l}^{(l)}\end{bmatrix}.*\left (1-\begin{bmatrix}a_1^{(l)} \\ a_2^{(l)} \\ ... \\ a_{s_l}^{(l)}\end{bmatrix}\right).*\left(\begin{bmatrix}\theta_{1, 1}^{(l)} &\theta_{2, 1}^{(l)} &...&\theta_{s_{l+1}, 1}^{(l)}\\ \theta_{1, 2}^{(l)} &\theta_{2, 2}^{(l)} &...&\theta_{s_{l+1}, 2}^{(l)} \\ ... \\ \theta_{1, s_l}^{(l)} &\theta_{2, s_l}^{(l)} &...&\theta_{s_{l+1}, s_l}^{(l)}\end{bmatrix}\begin{bmatrix}\delta_1^{(l+1)} \\ \delta_2^{(l+1)} \\ ... \\ \delta_{s_{l+1}}^{(l+1)}\end{bmatrix}\right) \\
⎣⎢⎢⎢⎡δ1(l)δ2(l)...δsl(l)⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡a1(l)a2(l)...asl(l)⎦⎥⎥⎥⎤.∗⎝⎜⎜⎜⎛1−⎣⎢⎢⎢⎡a1(l)a2(l)...asl(l)⎦⎥⎥⎥⎤⎠⎟⎟⎟⎞.∗⎝⎜⎜⎜⎛⎣⎢⎢⎢⎡θ1,1(l)θ1,2(l)...θ1,sl(l)θ2,1(l)θ2,2(l)θ2,sl(l).........θsl+1,1(l)θsl+1,2(l)θsl+1,sl(l)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡δ1(l+1)δ2(l+1)...δsl+1(l+1)⎦⎥⎥⎥⎤⎠⎟⎟⎟⎞
最后得到:
δ
(
l
)
=
a
(
l
)
.
∗
(
1
−
a
(
l
)
)
.
∗
(
θ
(
l
)
T
δ
(
l
+
1
)
)
(2)
\delta^{(l)}=a^{(l)}.*(1-a^{(l)}).*({\theta^{(l)}}^T\delta^{(l+1)}) \tag{2}
δ(l)=a(l).∗(1−a(l)).∗(θ(l)Tδ(l+1))(2)
又由公式(1)得:
d
J
(
x
,
θ
)
d
θ
i
,
j
(
l
)
=
δ
i
(
l
+
1
)
a
j
(
l
)
(3)
\frac{dJ(x,\theta)}{d\theta_{i, j}^{(l)}}=\delta_i^{(l+1)}a_j^{(l)} \tag{3}
dθi,j(l)dJ(x,θ)=δi(l+1)aj(l)(3)
假设
J
(
x
,
θ
)
=
1
2
(
h
(
x
)
−
y
)
2
J(x,\theta)=\frac{1}{2}(h(x)-y)^2
J(x,θ)=21(h(x)−y)2,则:
δ
(
L
)
=
d
J
(
x
,
θ
)
d
z
L
=
d
J
(
x
,
θ
)
d
a
L
d
a
L
d
z
L
\delta^{(L)}=\frac{dJ(x,\theta)}{dz^{L}}=\frac{dJ(x,\theta)}{da^{L}}\frac{da^{L}}{dz^{L}}
δ(L)=dzLdJ(x,θ)=daLdJ(x,θ)dzLdaL
得到
δ
(
L
)
=
(
a
L
−
y
)
a
L
(
1
−
a
L
)
(4)
\delta^{(L)}=(a^{L}-y)a^{L}(1-a^{L}) \tag{4}
δ(L)=(aL−y)aL(1−aL)(4)
6. 后向传播算法
- 误差矩阵 Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l)初始化为零
- For i=1:m
(1). a ( 1 ) = x ( i ) a^{(1)}=x^{(i)} a(1)=x(i) 其中 a a a的上标表示不同的层数, x x x的上标表示不同的测试样本
(2). 利用前向传播计算 a ( 2 ) , a ( 3 ) , . . . , a ( L ) a^{(2)},a^{(3)},...,a^{(L)} a(2),a(3),...,a(L)
(3). 初始 δ ( L ) = ( a ( L ) − y ( i ) ) a ( L ) ( 1 − a ( L ) ) \delta^{(L)}=(a^{(L)}-y^{(i)})a^{(L)}(1-a^{(L)}) δ(L)=(a(L)−y(i))a(L)(1−a(L))
(4). 利用后向传播计算 δ ( l ) \delta^{(l)} δ(l)
(5). Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l):= Δ i j ( l ) + a j ( l ) δ i l + 1 \Delta_{ij}^{(l)}+a_j^{(l)}\delta_i^{l+1} Δij(l)+aj(l)δil+1
求出偏导数 D i j ( l ) = 1 m Δ i j ( l ) + λ θ i j ( l ) D_{ij}^{(l)}=\frac{1}{m}\Delta_{ij}^{(l)}+\lambda\theta_{ij}^{(l)} Dij(l)=m1Δij(l)+λθij(l) - 利用偏导数进行梯度下降
7. 神经网络训练
A. 参数随机化,若 Θ \Theta Θ全为0,会导致全为相同值,所以必须初始化初始值为随机值。
B. 利用正向传播计算所有层的值 a ( l ) a^{(l)} a(l)
C. 计算此时的代价函数 J ( Θ ) J(\Theta) J(Θ)
D. 利用后向传播计算所有偏导数
E. 利用数值检验法检验偏导数( D ≈ J ( Θ + ϵ ) − J ( Θ − ϵ ) 2 ϵ D\approx\frac{J(\Theta+\epsilon)-J(\Theta-\epsilon)}{2\epsilon} D≈2ϵJ(Θ+ϵ)−J(Θ−ϵ))
F. 利用优化算法最小化代价函数(梯度下降)















 4958
4958











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









