







1、分析下列程序:
#include<iostream>
#define SUB(x,y) x-y
#define ACCESS_BEFORE(element,offset,value) *SUB(&element,offset)=value
using namespace std;
int main() {
int i;int array[10]={1,2,3,4,5,6,7,8,9,10};
ACCESS_BEFORE(array[5],4,6);
cout<<endl;
for(i=0;i<10;++i) {printf("%d",array[i]);
}
return 0;
}分析:宏的那句被预处理替换成了: *&array[5]-4=6;
由于减号比赋值优先级高,因此先处理减号;由于减号返回一个数而不是合法的值,所以编译出错。
#include<iostream>
#define SUB(x,y) (x-y)
#define ACCESS_BEFORE(element,offset,value) *SUB(&element,offset)=value
using namespace std;
int main() {
int i;int array[10]={1,2,3,4,5,6,7,8,9,10};
ACCESS_BEFORE(array[5],4,6);
cout<<endl;
for(i=0;i<10;++i) {printf("%d",array[i]);
}
return 0;
}
2 用预处理指令#define声明一个常数,用以表明1年中有多少秒?
#define SECONDS_PER_YEAR (60*60*24*365)UL
注意:预处理器可以计算常数表达式的值,写出一年有多少秒而不是计算出的实际的值,更有意义。 另外这个表达式将使将使一个16位机的整形数溢出,因此要用到长整形符号L,告诉这个编译器这个常数是长整形数。
3 分析const
(1)const int *a=&b;//const位于星号左侧,则const是用来修饰指针所指向的变量,即指针指向为常量。对于此种情况,可以先不进行初始化。虽然指针内容是常量,但指针本身不是常量。
(2)int const *a=&b;//与(1)的情况相同,都是指针所指向的内容为常量(与const放在声明符中的位置无关),这种情况下不允许对内容进行更改操作。
(3)int * const a=&b;//const位于星号右侧,const就是修饰指针本身,即指针本身是常量。这种情况下不能对指针本身进行更改操作,而指针所指向的内容不是常量。定义时必须同时初始化。
(4) const int *const a=&b;//指针本身和指向的内容均为常量。
const成员函数:
定义的类的成员函数中,常常有一些成员函数不改变类的数据成员,也就是说,这些函数是”只读“函数,而有一些函数要修改类数据成员的值。如果把不改变数据成员的函数加上const关键字进行标识,可以提高程序的可读性。其实,还能提高程序的可靠性,已定义成const的成员函数,一旦企图修改数据成员的值,则编译器按错误处理。
注意:关键字const必须用同样的方式重复出现在函数实现里,否则编译器会把它看成一个不同的函数。
4 const 与#define比较
分析: C++语言可以用const定义常量,也可以用#define定义常量,但是前者比后者有更多优点:
(1)const常量由数据类型,宏常量没有数据类型。编译器可以对前者进行类型安全检查,而对后者只进行字符替换,没有类型检查,并且在字符替换中可能产生错误。(边际效应)
(2)有些集成化的调试工具可以对const常量进行调试,但是不能对宏常量进行调试。在C++程序中只使用const常量而不使用宏常量,即const常量完全取代宏常量。
补充:
const,一个不能被改变的普通常量,在C中,它总是占用内存,而且它的名字是全局符。C编译器不能把const看成一个编译期间的常量。在C中,如果写:
const bufsize=100;
char buf[bufsize];
尽管看起来好像做了一件合理的事,但这将得到一个错误结果。因为bufsize占用内存的某个地方,所以C编译器不知道它在编译时的值。在C语言中可以这样写:
const bufsize;
这样写在C++中是不对的,而C编译器则把它作为一个声明,这个声明指明在别的地方有内存分配。因为C默认const是外部连接的,而C++默认const是内部连接的。这样,如果在C++中想完成与C同样的事情,必须用extern把内部连接改成外部链接。
extern const bufsize;//declaration only
这种语言也可以用在C语言中。在C语言中const使用限定符const不是很有用。C迫使程序员在预处理器里使用#define。
5 有类如下:
class A_class {
void f() const
{
//...
}
}分析:在C++程序在,类里面的数据成员加上mutable后,修饰为const的成员变量,就可以修改了。
6 关于sizeof的一些注意点
char q2[]="a\n";
struct {
short a1;
short a2;
short a3
}A;
struct {
long a1;
short a2;
}B;
cout<<sizeof(q2)<<endl;//3
cout<<sizeof(A)<<" "<<sizeof(B)<<endl;//6,8CPU优化原则:对于n字节的元素,它的首地址能被n整除,才能获得最好性能。 设计编译器的时候可以遵循这个原则:对于每一个变量,可以从当前位置向后找到第一个满足这个条件的地址作为首地址。但是结构体一般面临数组分配问题。
补充:数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍。DWORD数据的内存起始地址能被4除尽,WORD数据的内存起始地址能被2除尽。X86CPU能直接访问对齐的数据,当它试图访问一个未对齐的数据时,会在内部进行一系列的调整。这些调整对于程序来说是透明的,但是会降低运行速度,所以编译器在编译程序时会尽量保证数据对齐。
7 分析下列程序
#include<iostream>
using namespace std;
class A1{
public:
int a;
static int b;
A1();
~A1();
};
class A2{
public:
int a;
char c;
A2();
~A2();
};
class A3{
public:
float a;
char c;
A3();
~A3();
};
class A4{
public:
float a;
int b;
char c;
A4();
~A4();
};
class A5{
public:
double d;
float a;
int b;
char c;
A5();
~A5();
};
int main() {
cout<<sizeof(A1)<<endl;
cout<<sizeof(A2)<<endl;
cout<<sizeof(A3)<<endl;
cout<<sizeof(A4)<<endl;
cout<<sizeof(A5)<<endl;
return 0;
}
因为静态变量是存放在全局数据区的,而sizeof计算栈中分配的大小,是不会计算在内的,所以sizeof(A1)是4.
8 strlen与sizeof之间的区别
(1)char* ss="0123456789";
sizeof(ss)=4,ss是指向字符串常量的字符指针。sizeof(*ss)=1,*ss是第一个字符。
(2) char ss[]="0123456789"
sizeof(ss)=11,ss是数组,计算到”\0“的位置,因此是10+1。sizeof(*ss)=1,*ss是第一个字符。
(3)char ss[100]="0123456789";
sizeof(ss)=100,ss表示在内存中预分配的大小,100*1。 strlen(ss)=10,它的内部实现是用一个循环计算字符串的长度,直到”\0“为止。
(4) int ss[100]="0123456789";
sizeof(ss)=400,ss表示在内存中的大小,100*4。 strlen(ss)错误,strlen的参数只能是char*,且必须是以”\0“结尾。
(5) class X {
int i; int j;char k;
};
X x;
sizeof(X)<<" "<<sizeof(x)<<endl;//结果都是12.
分析:
(1)sizeof操作符的结果类型是size_t,它的头文件中的typedef为unsigned int类型。该类型保证能容纳实现所建立的最大对象的字节大小。
(2)sizeof是运算符,strlen是函数。
(3)sizeof可以用类型和函数作参数,strlen只能用char *做参数,且必须以\0结尾。
(4)数组做sizeof的参数不退化,传递给strlen就退化为指针。
(5)大部分程序在编译时就把sizeof计算过,是类型或是变量的长度。这就是sizeof(x)可以用来定义数组维数的原因。
(6)strlen的结果要在运行的时候才能计算出来,用来计算字符串的长度,而不是类型占内存的大小。
(7)sizeof后如果是类型必须加括号,如果是变量名可以不加括号。这是因为sizeof是运算符而不是个函数。
(8)当使用一个结构类型或变量时,sizeof返回实际的大小。当使用一静态空间数组时,sizeof返回全部数组的尺寸。sizeof不能返回被动态分配的数组或外部的数组尺寸。
(9)数组作为参数传递给函数时传递的是指针而不是数组,传递是的数组的首地址。在C++里传递数组永远都是传递指向数组的首元素的指针,编译器不知道数组的大小。
(10)计算结果变量的大小必须塔伦数据对齐问题。
(11)sizeof操作符不能用于函数类型、不完全类型或位字段。
9 sizeof的使用场合
(1)一个主要用途是与存储分配和I/O系统那样的例程进行通信。
void *malloc(size_t size)
size_t fread(void *ptr,size_t size,size_t nmemb,FILE *stream)(2)用它可以看看某种类型的对象在内存中所占的单元字节。
(3)在动态分配一对象时,可以让系统知道要分配多少自己。
(4)便于一些类型扩充。
(5)由于操作数的字节数在实现时可能出现变化,建议在设计操作数字节大小时用sizeof代替常量计算。
(6)如果操作数是函数中的数组形参或函数类型的形参,sizeof给出其指针的大小。
10 int **a[3][4]; 这个数组占据4*3*4=48个字节。
11 注意
(1)unsigned 影响的只是最高位bit的意义(正/负),数据长度是不会被改变的,所以 sizeof(unsigned int)==sizeof(int)
(2)自定义类型的sizeof取值等同于它的类型原型。如: typedef short WORD;sizeof(short) == sizeof(WORD)
(3)对函数使用sizeof,在编译阶段会被函数返回值的类型取代。如:int f1() {return 0;}
cout<<sizeof(f1())<<endl;//f1()返回值为int,因此被认为是int(5)数组的大小是各维数的乘积*数组元素的大小。
12 分析下列程序:
#include<iostream>
using namespace std;
class Base{
public:
Base() {
cout<<"Base-ctor"<<endl;
}
~Base() {
cout<<"Base-dtor"<<endl;
}
virtual void f(int) {
cout<<"Base::f(int)"<<endl;
}
virtual void f(double) {
cout<<"Base::f(double)"<<endl;
}
virtual void g(int i=10) {
cout<<"Base::g()"<<i<<endl;
}
void g2(int i=10) {
cout<<"Base::g2()"<<i<<endl;
}
};
class Derived: public Base{
public:
Derived() {
cout<<"Derived-ctor"<<endl;
}
~Derived() {
cout<<"Derived-dtor"<<endl;
}
void f(double j) {
cout<<"Derived::f(double)"<<endl;
}
virtual void g(int i=20) {
cout<<"Derived::g()"<<i<<endl;
}
};
int main() {
Base b;
Derived d;
Base *pb=new Derived;
cout<<sizeof(Base)<<"tt"<<endl;
cout<<sizeof(Derived)<<"bb"<<endl;
return 0;
}
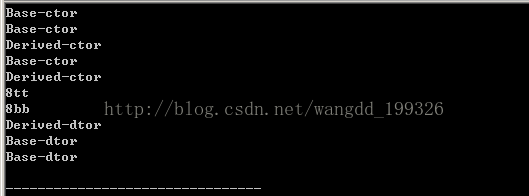
求Base类的大小,因为Base只有一个指针,所以类Base大小是8.Derive大小与Base一样,是8.
13 下列程序输出结果是4. 因为var[]等价于*var,已经退化成指针,所以大小是4.
char var[10];
int test(char var[])
{
return sizeof(var);
}14 空类所占空间是1,单一继承的空类空间也是1,多重继承的空类空间还是1.但是虚继承涉及到虚表(虚指针),所以是4.
15 内联函数和宏定义
答案:内联函数和普通函数相比可以加快程序运行的速度,因为不需要中断调用,在编译的时候内联函数可以直接被镶嵌在目标代码中。而宏只是一个简单的替换。
内联函数要做参数类型检查,这是内联函数跟宏相比优势。
inline是指嵌入代码,就是在调用函数的地方不是跳转,而是把代码直接写到那里。对于短小的代码来说inline增加空间消耗换来的是效率提高,这方面是和宏一样,但是inline在和宏相比没有付出任何额外代价的情况下更安全。
inline一般只适用如下情况:
(1)一个函数不断被重复调用
(2)函数只有简单几行,且函数内不包含for、while、switch语句。
一般,写小程序没有必要定义成inline,但是如果要完成一个工程项目,当一个简单函数被调用多次时,则应该考虑用inline。
宏在C语言极其重要,而在C++里面用的就少很多。关于宏的第一规则是绝不应该去使用它,除非你不得不这样做。几乎每个宏都表明程序设计语言里、程序里或者程序员的一个缺陷,因为它将在编译器看到程序的正文之前重新摆布这些正文。
宏在代码处不加以任何验证的简单替换,而内联函数是将代码直接插入调用处,而减少普通函数调用时的资源消耗。
宏不是函数,只是在编译前(编译预处理阶段)将程序中有关字符串替换成宏体。
关键字inline必须与函数定义体放在一起才能使函数成为内联,仅将inline放在函数声明前不起任何作用。如下风格的FOO不能成为内联函数:
inline void FOO(int x,int y);//inline仅与函数声明放在一起
void FOO(int x,int y)void FOO(int x,int y)
inline void FOO(int x,int y);//inline与函数体放在一起所以inline是一种”用于实现的关键字“,而不是一种”用于声明的关键字“。
内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
以下情况不适合使用内联:
1.函数体内的代码比较长,使用内联将导致内存消耗代价较高。
2.如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开销大。
类的构造函数和析构函数容易让人误解使用内联更有效。要当心构造函数和析构函数可能会隐藏一些行为,如”偷偷“执行了基类或成员对象的构造函数和析构函数。所以不要将构造函数和析构函数的定义体放在类声明中。一个好的编译器将会根据函数的定义体,自动取消不值得的内联。
《程序员面试宝典》 欧立奇 P46~P64















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









