







1.目标
利用Selenium抓取当当网图书并用正则表达式获取到得到商品的图片、名称、价格、评论人数信息。
2.开发环境
python2.7 +windows10 +pycharm
3.页面分析
如图,其中包含商品的图片、名称、价格、评论人数信息。

抓取入口就是当当网主页,主页链接可以通过直接构造参数访问。然后在搜索框中输入“日语”
,呈现的就是第一页的搜索结果。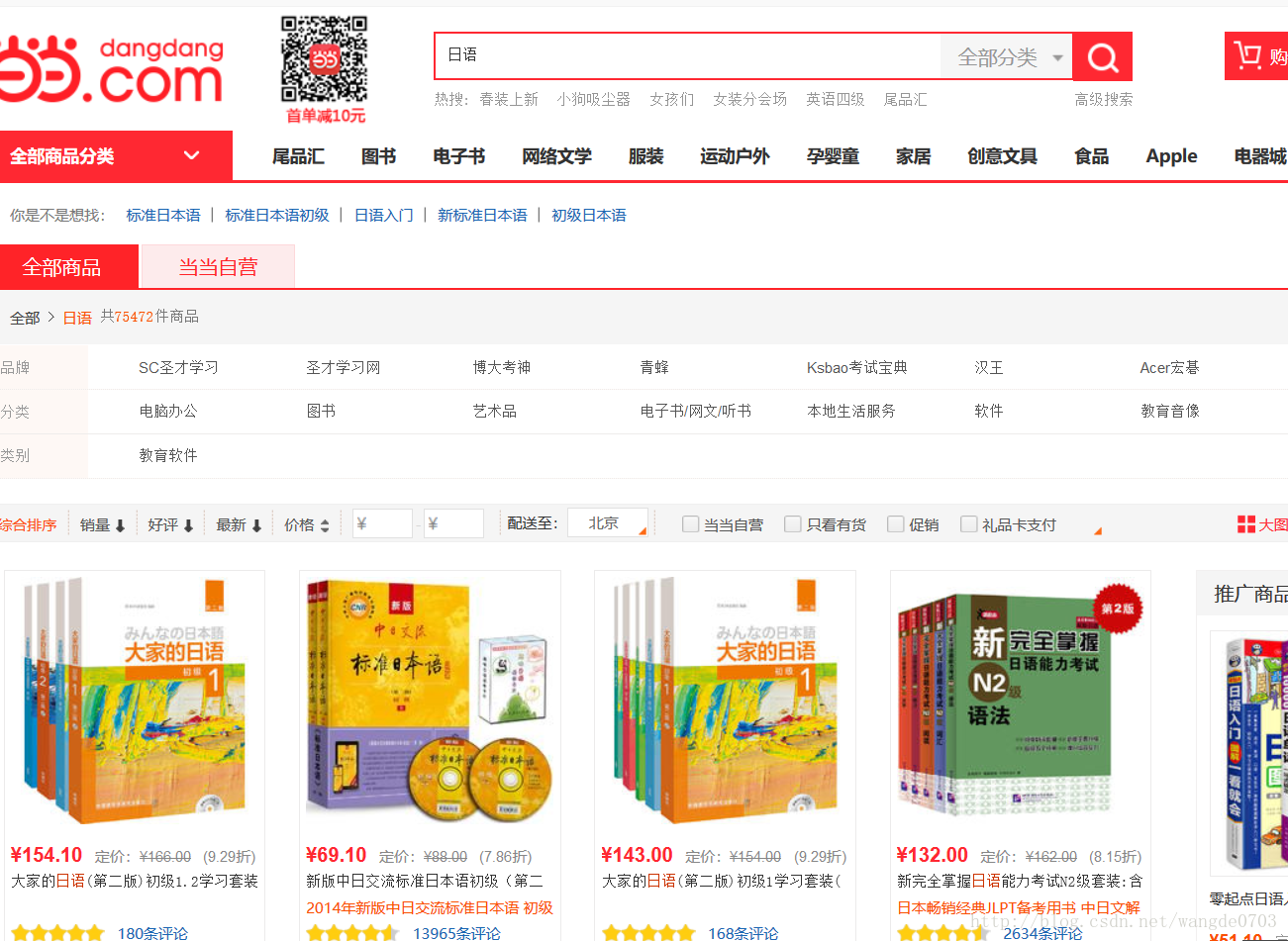
在页面下方,有一个分页导航,其中既包括前6页的链接,也包括下一页的链接,同时还有一个任意页码跳转的链接,如下图所示。

商品的搜索结果为100页,要获取每一页的内容,只需要将页码从1到100顺序遍历即可,页码数是确定的。所以,直接输入要跳转的页码,即可跳转到页码对应的页面。
相对输入跳转页码而不直接点击“下一页”的理由是:一旦爬取过程中出现异常退出,比如到50页退出了,此时继续点击“下一页”,就无法快速切换到对应的后续页面。并且,在爬取过程中,同时需要记录当前的页码数,一旦点击“下一页”之后页面加载失败,就需要做异常检测,通过检测才能判断当前加载页面的页码数。导致运行时间增加,能效降低,所以选取输入页码跳转的方式来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









