







初学Spark Streaming和Kafka,直接从网上找个例子入门,大致的流程:有日志数据源源不断地进入kafka,我们用一个spark streaming程序从kafka中消费日志数据,这些日志是一个字符串,然后将这些字符串用空格分割开,实时计算每一个单词出现的次数。
部署安装zookeeper:
1、官网下载zookeeper:http://mirror.metrocast.net/apache/zookeeper/
2、解压安装:
| 1 |
|
3、配置conf/zoo.cfg:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
4、启动,到zookeeper的bin目录下执行命令:
| 1 |
|
5、可以用ps命令是否启动
| 1 |
|
部署安装Kafka:
1、官网下载kafka:https://kafka.apache.org/downloads
2、解压安装:
| 1 |
|
3、配置:
config/server.properties:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
这里只修改了listeners、advertised.listeners、zookeeper.connect。
config/consumer.properties:
| 1 2 3 4 5 6 7 |
|
4、启动,到kafka的bin目录下执行命令:
| 1 |
|
5、可以用ps命令是否启动:
| 1 |
|
示例程序:
依赖:jdk1.7,spark-2.0.1,kafka_2.11-0.10.1.0,zookeeper-3.4.8,scala-2.118
开发环境:ideaIU-14.1.4
测试环境:win7
建立maven工程KafkaSparkDemo,在pom.xml配置文件添加必要的依赖:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
KafkaSparkDemo对象:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
直接运行程序:
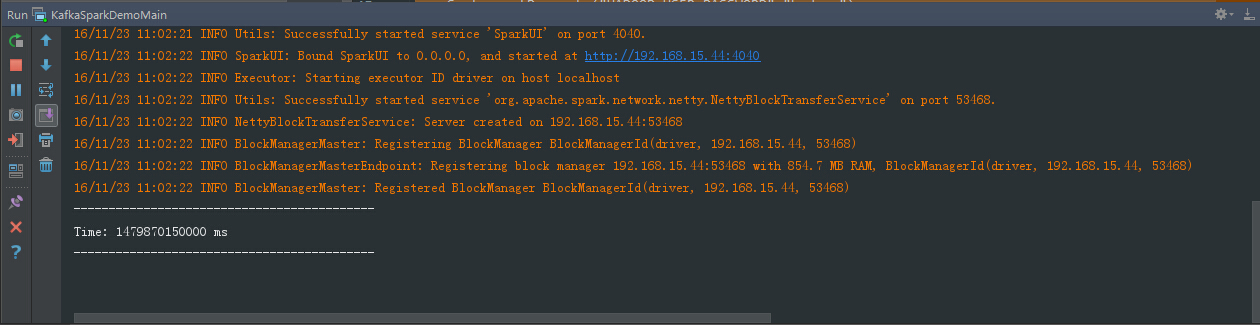
因为kafka队列里面还没有消息,所以为空。
启动kafka-console-producer工具,手动往kafka中依次写入如下数据:
| 1 |
|

结果如下:
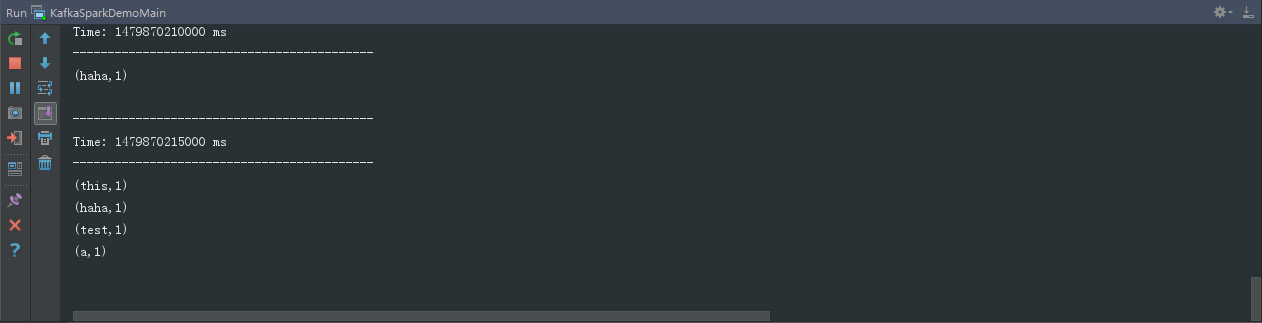
注:这里的broker-list的主机别用localhost,不然可能会遇到以下错误:
| 1 2 3 4 |
|
如果broker-list的端口不对,会遇到以下错误:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
你还可以用程序写入数据到kafka。
KafkaProducer类:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









