







本篇文章主要探讨的问题有三个:
1、首先我们为什么需要重写hashCode()方法和equals()方法?
2、在什么情况下需要重写hashCode()方法和equals()方法?
3、如何重写这两个方法?
二、为什么需要重写hashCode()方法和equals()方法
首先,为什么要重写equals()方法。我们在定义类时,我们经常会希望两个不同对象的某些属性值相同时就认为他们相同,所以我们要重写equals()方法,按照原则,我们重写了equals()方法,也要重写hashCode()方法。
Java中的超类Object类中定义的equals()方法是用来比较两个引用所指向的对象的内存地址是否一致,Object类中equals()方法的源码:
public boolean equals(Object obj) {
return (this == obj);
}
- 1
- 2
- 3
Object类中hashCode()方法的源码:
public native int hashCode();
- 1
Object类中的hashCode()方法,用的是native关键字修饰,说明这个方法是个原生函数,也就说这个方法的实现不是用java语言实现的,是使用c/c++实现的,并且被编译成了DLL,由java去调用,jdk源码中不包含。对于不同的平台它们是不同的,java在不同的操作系统中调用不同的native方法实现对操作系统的访问,因为java语言不能直接访问操作系统底层,因为它没有指针。
(1)这种方法调用的过程:
1、在java中申明native方法,然后编译;
2、用javah产生一个 .h 文件;
3、写一个 .cpp文件实现native导出方法,其中需要包含第二步产生的.h文件(其中又包含了jdk带的jni.h文件);
4、将.cpp文件编译成动态链接库文件;
5、在java中用System.loadLibrary()文件加载第四步产生的动态链接库文件,然后这个navite方法就可被访问了
Java的API文档对hashCode()方法做了详细的说明,这也是我们重写hashCode()方法时的原则【Object类】;
(2)重点要注意的是:
a. 在java应用程序运行时,无论何时多次调用同一个对象时的hashCode()方法,这个对象的hashCode()方法的返回值必须是相同的一个int值;
b. 如果两个对象equals()返回值为true,则他们的hashCode()也必须返回相同的int值;
c. 如果两个对象equals()返回值为false,则他们的hashCode()返回值也必须不同;
现在,我们到这里可以看出,我们重写了equals()方法也要重写hashCode()方法,这是因为要保证上面所述的b,c原则;所以java中的很多类都重写了这两个方法,例如String类,包装类等。
三、在什么情况下需要重写hashCode()方法和equals()方法
当我们自定义的一个类,想要把它的实例保存在集合中时,我们就需要重写这两个方法;集合(Collection)有两个类,一个是List,一个是Set。
List:集合中的元素是有序的,可以重复的;
Set:无序,不可重复的;
- 1
- 2
(1)以HashSet来举例:
HashSet存放元素时,根据元素的hashCode方法计算出该对象的哈希码,快速找到要存储的位置,然后进行比较,
比较过程如下:
- 如果该对象哈希码与集合已存在对象的哈希码不一致,则该对象没有与其他对象重复,添加到集合中!
- 如果存在于该对象相同的哈希码,那么通过equals方法判断两个哈希码相同的对象是否为同一对象(判断的标准是:属性是否相同)
- 相同对象,不添加。
- 不同对象,添加。
注意:如果返回值为false,则这个时候会以链表的形式在同一个位置上存放两个元素,这会使得HashSet的性能降低,因为不能快速定位了。示意图如下:
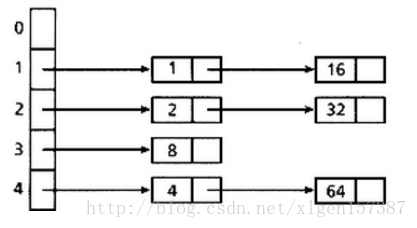
还有一种情况就是两个对象的hashCode()返回值不同,但是equals()返回true,这个时候HashSet会把这两个对象都存进去,这就和Set集合不重复的规则相悖了;所以,我们重写了equals()方法时,要按照b,c规则重写hashCode()方法!
四、如何重写这两个方法
如果你决定要重写equals()方法,那么你一定还要明确这么做所带来的风险,并确保自己能写出一个健壮的equals()方法。
一定要注意的一点是,在重写equals()后,一定要重写hashCode()方法。
(1)我们先看看 JavaSE 8 Specification中对equals()方法的说明:
The equals method implements an equivalence relation on non-null object references:
-
It is reflexive: for any non-null reference value x, x.equals(x) should return true.
-
It is symmetric: for any non-null reference values x and y, x.equals(y) should return true if and only if y.equals(x) returns true.
-
It is transitive: for any non-null reference values x, y, and z, if x.equals(y) returns true and y.equals(z) returns true, then x.equals(z) should return true.
-
It is consistent: for any non-null reference values x and y, multiple invocations of x.equals(y) consistently return true or consistently return false, provided no information used in equals comparisons on the objects is modified.
-
For any non-null reference value x, x.equals(null) should return false.
The equals method for class Object implements the most discriminating possible equivalence relation on objects; that is, for any non-null reference values x and y, this method returns true if and only if x and y refer to the same object (x == y has the value true).
这段话用了很多离散数学中的术数.简单说明一下:
- 自反性:A.equals(A)要返回true;
- 对称性:如果A.equals(B)返回true, 则B.equals(A)也要返回true;
- 传递性:如果A.equals(B)为true, B.equals(C)为true, 则A.equals(C)也要为true. 说白了就是 A = B , B = C , 那么A = C;
- 一致性:只要A,B对象的状态没有改变,A.equals(B)必须始终返回true;
- A.equals(null) 要返回false;
(2)简单步骤:
为了说明方便,我们先定义一个程序员类(Coder):
class Coder {
private String name;
private int age;
// getters and setters
}
- 1
- 2
- 3
- 4
- 5
- 6
我们想要的是,如果2个程序员对象的name和age都是相同的,那么我们就认为这两个程序员是一个人。这时候我们就要重写其equals()方法。因为默认的equals()实际是判断两个引用是否指向内在中的同一个对象,相当于 == 。 重写时要遵循以下三步:
1、判断是否等于自身:
if(other == this){
return true;
}
- 1
- 2
- 3
2、 使用instanceof运算符判断 other 是否为Coder类型的对象:
if(!(other instanceof Coder)) {
return false;
}
- 1
- 2
- 3
3、比较Coder类中你自定义的数据域,name和age,一个都不能少:
Coder o = (Coder)other;
return o.name.equals(name) && o.age == age;
- 1
- 2
看到这有人可能会问,第3步中有一个强制转换,如果有人将一个Integer类的对象传到了这个equals中,那么会不会扔ClassCastException呢?这个担心其实是多余的.因为我们在第二步中已经进行了instanceof 的判断,如果other是非Coder对象,甚至other是个null, 那么在这一步中都会直接返回false, 从而后面的代码得不到执行的机会。
上面的三步也是<Effective Java>中推荐的步骤,基本可保证万无一失。
我们在大学计算机数据结构课程中都已经学过哈希表(hash table)了,hashCode()方法就是为哈希表服务的。
当我们在使用形如HashMap, HashSet这样前面以Hash开头的集合类时,hashCode()就会被隐式调用以来创建哈希映射关系。
<Effective Java>中给出了一个能最大程度上避免哈希冲突的写法,但我个人认为对于一般的应用来说没有必要搞的这么麻烦.如果你的应用中HashSet中需要存放上万上百万个对象时,那你应该严格遵循书中给定的方法.如果是写一个中小型的应用,那么下面的原则就已经足够使用了:
要保证Coder对象中所有的成员都能在hashCode中得到体现.
@Override
public int hashCode() {
int result = 17;
result = result * 31 + name.hashCode();
result = result * 31 + age;
return result;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
其中int result = 17你也可以改成20, 50等等都可以.看到这里我突然有些好奇,想看一下String类中的hashCode()方法是如何实现的.查文档知:
“Returns a hash code for this string. The hash code for a String object is computed as
s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
using int arithmetic, where s[i] is the ith character of the string, n is the length of the string, and ^ indicates exponentiation. (The hash value of the empty string is zero.)”
对每个字符的ASCII码计算n - 1次方然后再进行加和,可见Sun对hashCode的实现是很严谨的. 这样能最大程度避免2个不同的String会出现相同的hashCode的情况.
参考文章:
1、http://blog.csdn.net/jing_bufferfly/article/details/50868266
2、http://blog.csdn.net/neosmith/article/details/17068365















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









