









今天给大家分享一个改造过的 Animatediff 模型,使用它生成视频的速度相比原始模型可以提升10倍以上,这就是字节跳动最近开源的 Animatediff-Lightning,本文就来介绍下 Animatediff-Lightning 的原理和使用方法。
演示效果
下面三个视频,分别是精细视频转绘、姿态视频转绘和文本生成视频的生成效果,整个视频的前后一致性控制的相当不错,普通浏览不会发现什么明显问题。

Animatediff-Lightning介绍
Animatediff-Lightning 是一个跨模型扩散蒸馏模型,这里有两个关键词,特别介绍下;
跨模型:指的是训练时使用多个不同的 Stable Diffusion 基础模型来进行训练,比如 DreamShaper、ToonYou等现实模型和动漫模型。使用这种方法训练出的模型可以搭配各种 Stable Diffusion 基础模型,都有比较好的视频生成效果,可以说拥有较强的泛化能力。
**蒸馏:**是神经网络模型压缩的一种方法,压缩后模型的体积更小,处理速度更快,但是模型的性能没有明显的损失,目前很多生成效率比较高的模型都是使用这种方法搞出来的,比如GPT-4 Turbo。在训练 Animatediff-Lightning 模型时,原始模型是 AnimateDiff v2 模型,训练时新模型不断学习 AnimateDiff v2 生成视频时的输出信息,从而逐步掌握到原始模型的大部分知识和能力。
在使用 Animatediff-Lightning 生成视频时,仅需要较少的步数即可完成图像采样,官方分别提供了 1、2、4、8步的Lightning模型,实测:1步效果不佳,仅作为测试和研究使用;2、4、8步质量较好,4步在速度和质量间找到了平衡,建议使用,8步质量最好,但是生成耗时较长。
另外文生视频时,Animatediff-Lightning 生成正方形视频的效果最好,长方形视频容易出现崩坏的情况,使用时需要注意。
关于 Animatediff-Lightning 的更多细节,请访问其研究论文:https://arxiv.org/abs/2403.12706
模型下载地址请前往文末。
使用Animatediff-Lightning
这里介绍下使用 Animatediff-Lightning 快速生成视频的三个小例子,希望能对你有所启发。
安装ComfyUI
视频生成工具使用的是 ComfyUI,这是一个工业级的AI绘画创作工具。
项目地址:https://github.com/comfyanonymous/ComfyUI
本地安装
请参考 Github 项目主页的介绍,也可以搜索其他人的安装教程。本文主要介绍 Animatediff-Lightning,ComfyUI的安装过程就不介绍了,后续看大家的需求再决定是否出一篇本地安装说明。
云环境使用
本文演示使用的 ComfyUI 是我分享在 AutoDL 云平台上的一个容器镜像:yinghuoai-ComfyUI ,如果你本地没有8G以上的Nivida显卡,建议试试云环境。
创建容器实例时,选择“社区镜像”,输入:yinghuoai-ComfyUI,点击选择弹出的镜像即可。
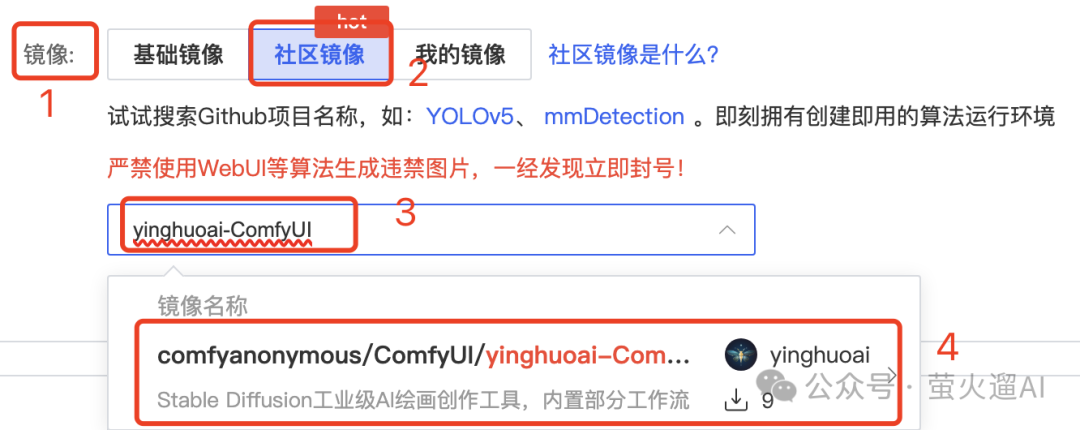
实例启动成功后,在AutoDL的实例列表中点击对应实例的【JupyterLab】进入实例管理页面。在【启动器】页面点击下图中的这个【重启】按钮。
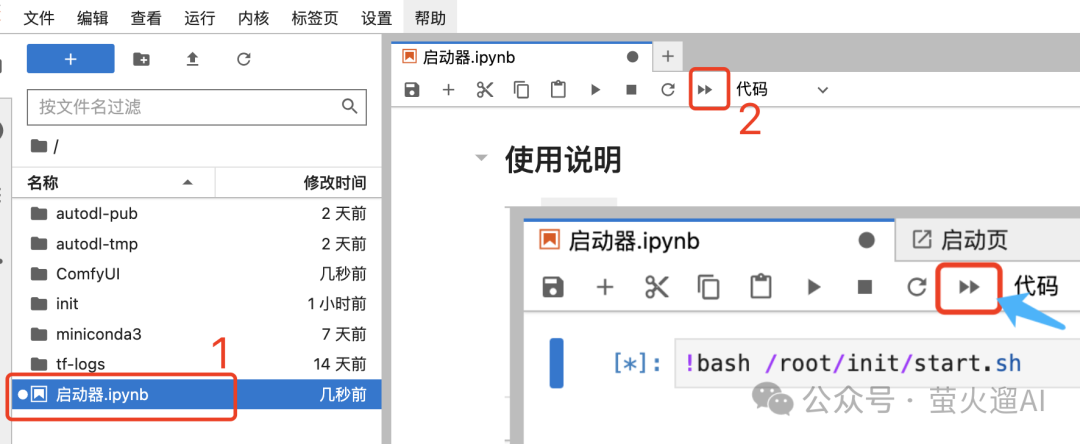
首次启动会下载一些模型,请耐心等待,后边再启动这个实例就快了。出现 “http://127.0.0.1” 字样后,代表启动成功。

最后返回 AutoDL 实例列表,点击对应实例的【自定义服务】,即可在浏览器访问 ComfyUI。
使用ComfyUI
ComfyUI 和 Stable Diffusion WebUI 的使用方式差别很大,它是基于工作流的思想构建的,生成图片的过程被构建为多个节点的连续处理过程,不过也不用担心上手困难,我们可以直接使用别人发布的工作流,完美复刻别人的作品,也不用自己从头开始设计工作流。
这里简单介绍下在 ComfyUI 中使用 Animatediff-Lightning 生成视频的方法。
加载工作流
在 ComfyUI 的使用界面找到下图这个“管理菜单”(一般在页面的右侧),其中有一个【加载】按钮,直接点击【加载】按钮会让我们从本地选择工作流文件或者包含工作流的图片,【加载】按钮右侧有个下拉小按钮,点击可以使用我内置的一些工作流,如下图所示:
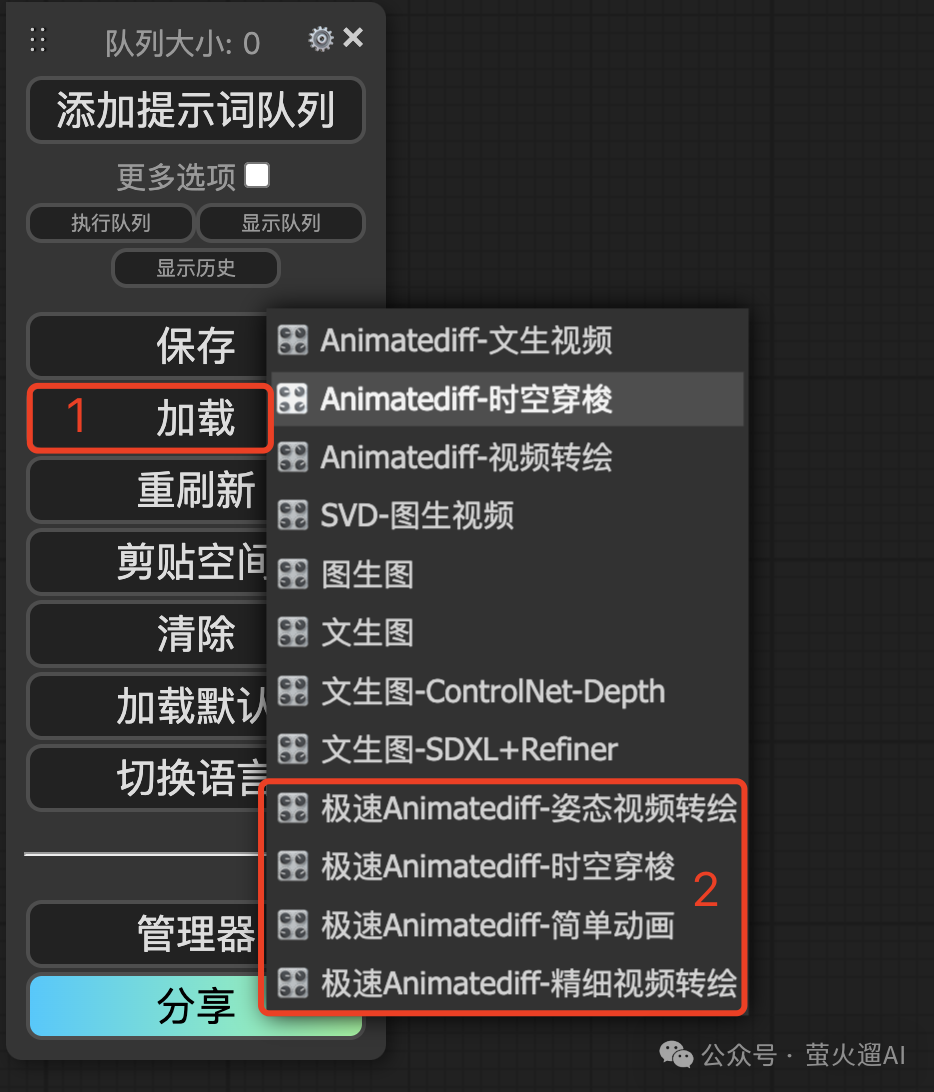
工作流中的节点很多,全部讲清楚比价困难,这里主要介绍下其中几个通用的可以自定义的地方,方便大家生成满足自己需求的视频。
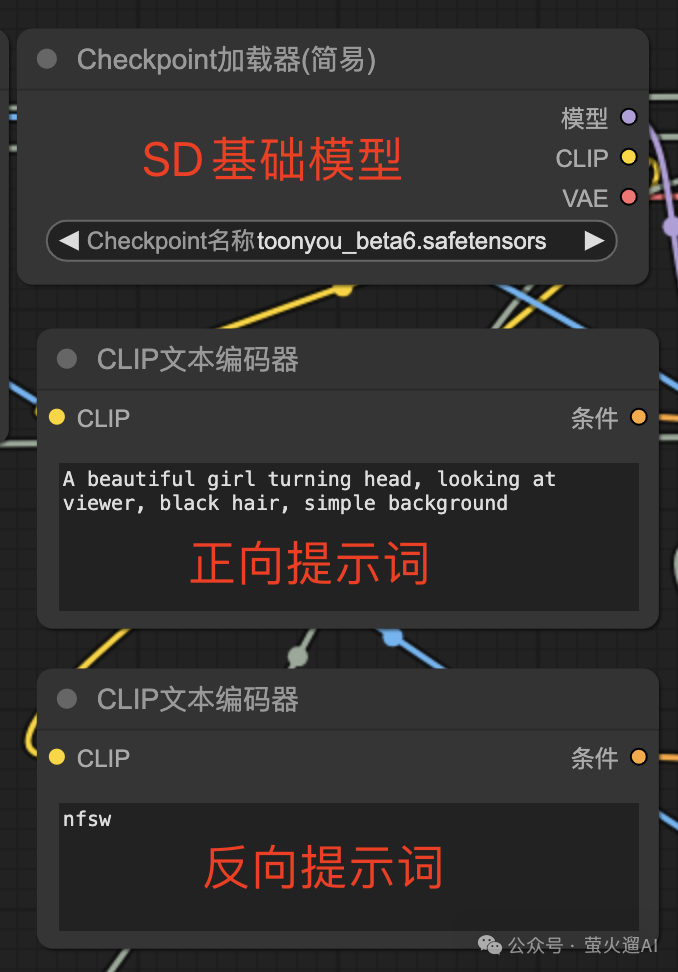
基础模型和提示词
首先是关于SD基础模型的选择,正向提示词和反向提示词的填写。SD基础模型通过这个【Checkpoint加载器】进行选择,正向提示词和反向提示词使用的都是【CLIP文本编码器】,它们会连接到采样器的不同输入参数上。在使用Animatediff-Lightning模型时,反向提示词不用写太多。
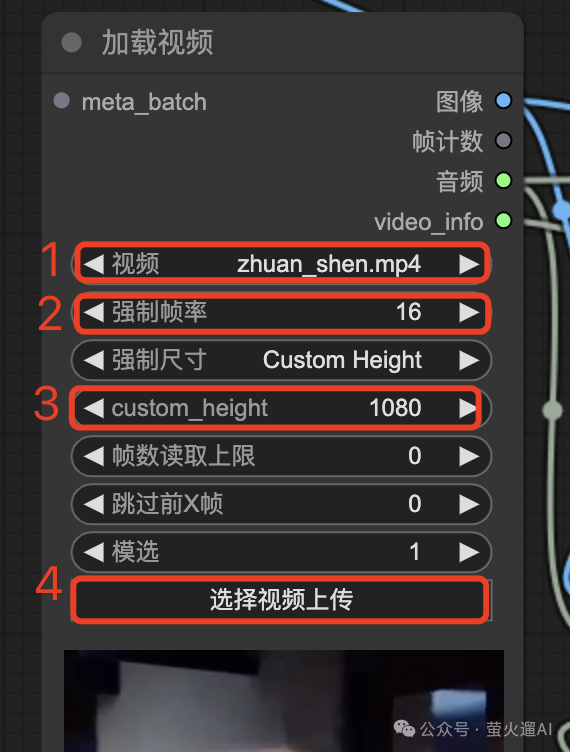
加载视频
如果你做视频重绘,需要通过【加载视频】这个节点来选择一个要被重绘的视频。这里有几个参数重点介绍下:
- 这里是从ComfyUI的目录下选择视频,你可以把视频先放到这个目录下:ComfyUI/input
- 原始视频有一个帧率,你可以强制缩小下,让视频生成的更快。比如原来是30,你修改为15,处理的视频画面就少了一半,速度自然提上去了。
- custom_height: 这里是强制更改视频的高度为1080,宽度会自适应,如果你想放大或缩小视频,这很有用。
- 可以在这里直接上传本地的视频。
Animatediff模型设置
上边介绍的两个部分都比较基础,Animatediff模型是本文的重点。
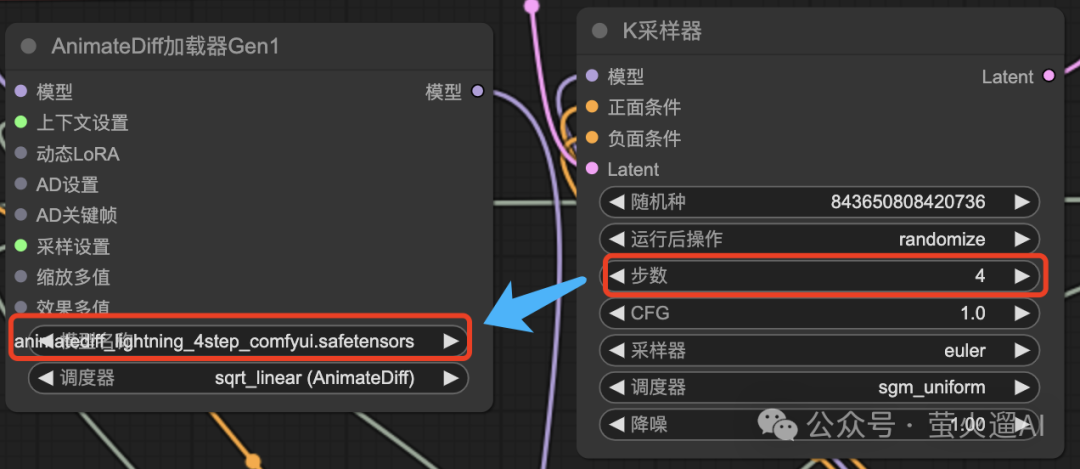
我们首先通过【AnimateDiff加载器】加载Lightning模型,模型需要放到ComfyUI的这个目录下:ComfyUI/models/animatediff_models
然后就可以在这里选择到,注意【K采样器】中的【步数】要和模型的步数匹配,比如这里我选择的模型是 4step 的,步数这里就需要设置为4。
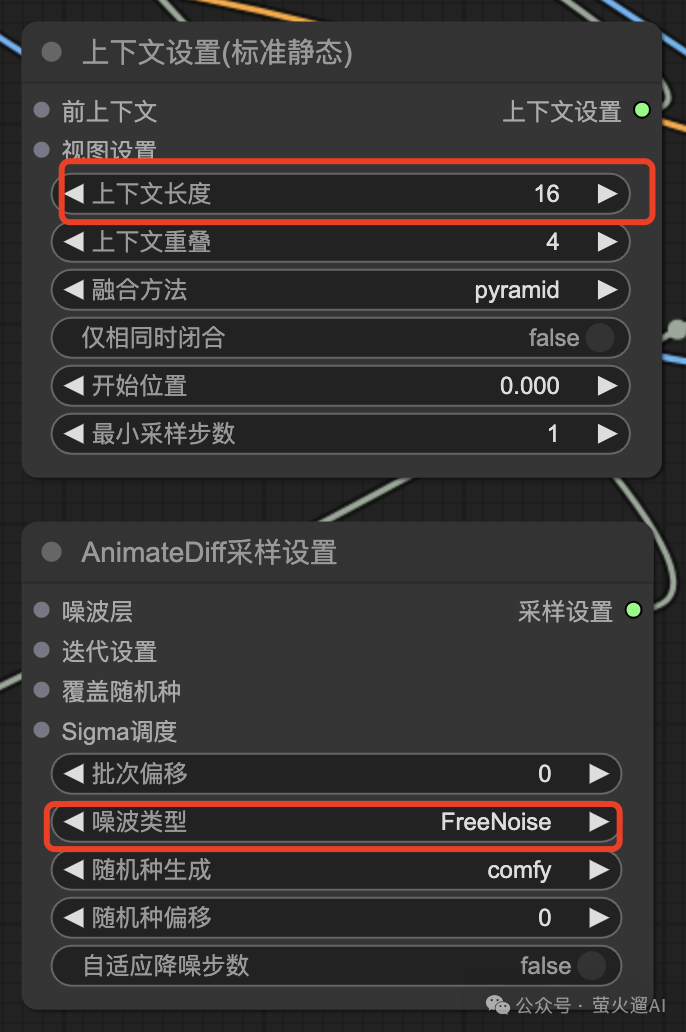
为了生成更长时间的视频,以及保持视频中任务的一致性,我们还需要设置下 Animatediff 的上下文和采样设置。【上下文长度】使用默认的16就好了,Animatediff训练时使用的就是16。采样设置中的【噪波类型】选择 FreeNoise,这会让视频中的人物尽量保持一致,人物的形象和姿势会更趋于一致。
合成视频
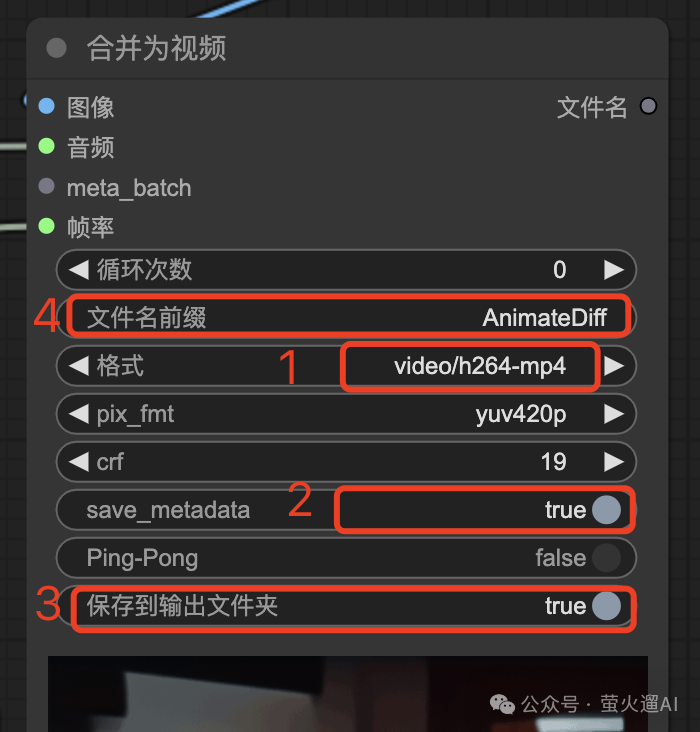
合成视频是工作流的最后一步,这里有几个参数也很关键,给大家唠叨一下:
- 格式:可以输出为图片格式,比如Gif动画,也可以输出为正常的 mp4 视频格式。
- save_meradata:会生成一张png图片,可以通过在ComfyUI中加载这张图片来获取生成视频的工作流。
- 保存到输出文件夹:一般都要选上,方便后续下载。默认是:ComfyUI/output,可以通过启动命令修改,我在 AutoDL 上的镜像已经修改为 autodl-tmp/output。
- 文件名前缀:建议为不同的工作流使用不同的前缀,方便管理生成的视频。
OK,关键的操作就这么多,祝你生成顺利!
资源下载
Animatediff-Lightning 模型下载:
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 3019
3019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









