






Zookeeper源码阅读 1 本地源码伪集群环境搭建
前言
该系列文章的源码版本为zookeeper3.7.0版本
一、下载源码
1.GitHub下载源码zip包,版本选择3.7.0 https://github.com/apache/zookeeper
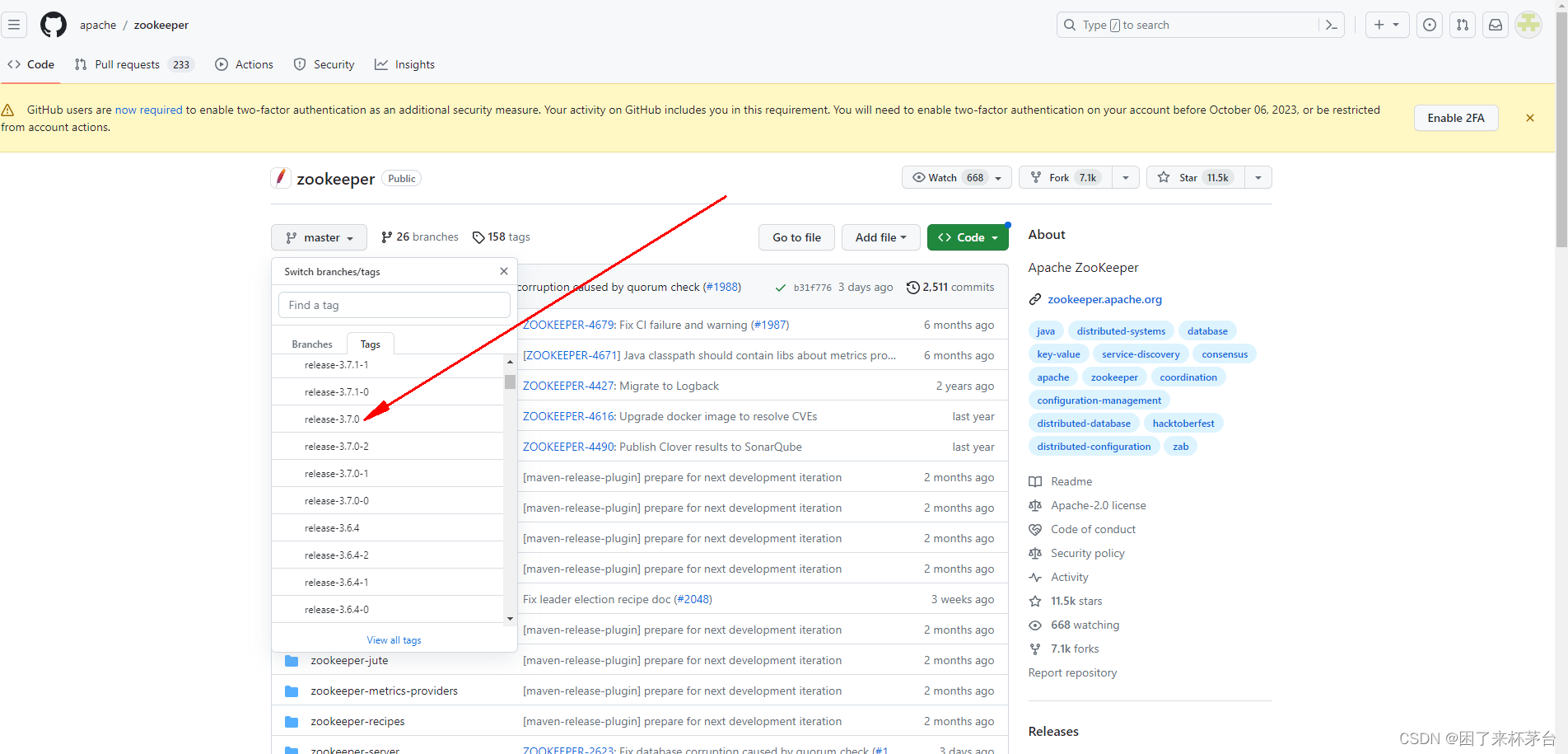
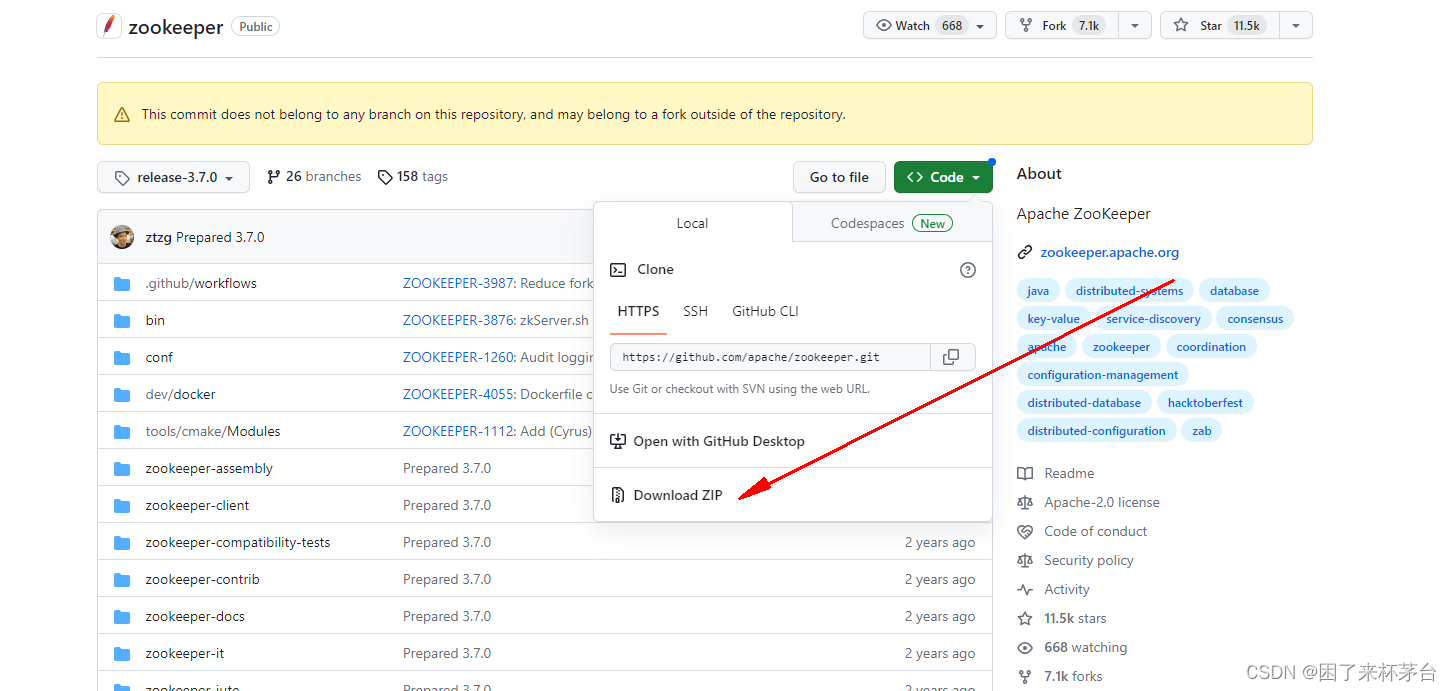
下载ZIP包到本地,并解压到你的开发目录下
二、导入IDEA
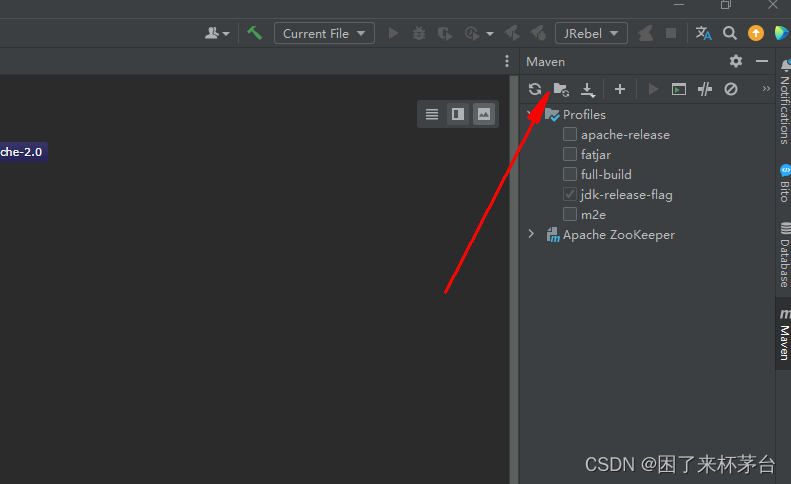
1.使用IDEA => OPEN => 打开刚才的源码目录,等IDEA加载进度条完后,刷新下maven
2.maven配置修改
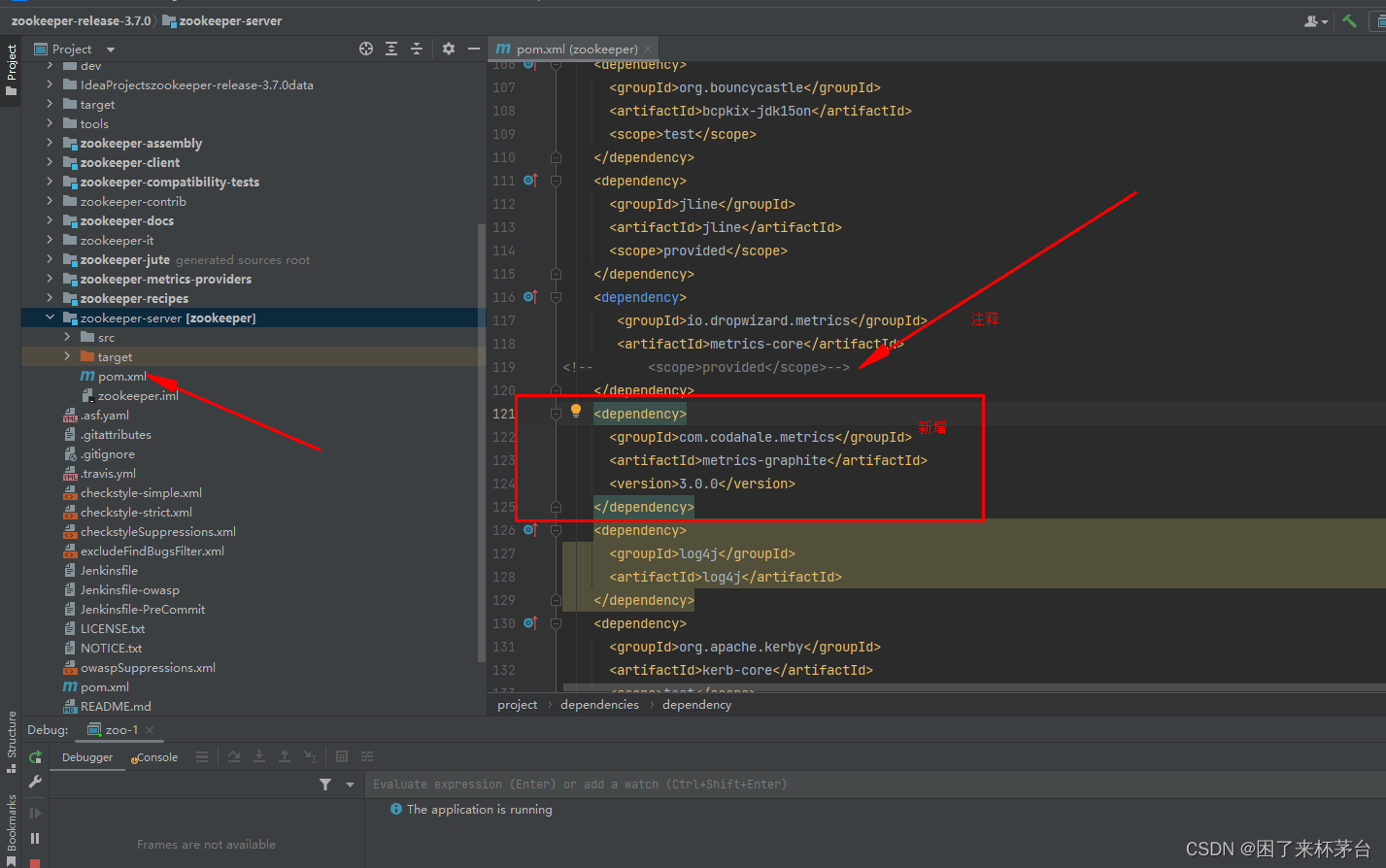
1.找到metrics-core依赖,把scope注释
2.新增metrics-graphite依赖
3.找到snappy-java依赖,把scope注释
<dependency>
<groupId>io.dropwizard.metrics</groupId>
<artifactId>metrics-core</artifactId>
<!-- <scope>provided</scope> 加注释-->
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-graphite</artifactId>
<version>3.0.0</version>
</dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
<!-- <scope>provided</scope> 加注释-->
</dependency>
2.配置文件添加
config目录下新增三个cfg文件,给集群的三个节点启用使用
zoo_1.cfg 内容如下
zoo_2.cfg 以及 zoo_3.cfg 在zoo_1.cfg的基础上改动dataDir,clientPort即可,clientPort根据节点数量往上递增 如 zoo-1 -> 2191 ; zoo-2 -> 2192 ; zoo-3 -> 2193
dataDir=D:\\IdeaProjects\\zookeeper-release-3.7.0\\data\\zoo-1
dataLogDir=D:\\IdeaProjects\\zookeeper-release-3.7.0\\data\\logs
clientPort=2191
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
cfg文件加完后,根据配置文件里的路径创建data目录和logs目录
最后,在每个节点目录下新增一个myid文件,其内容取决于cfg文件里的myid是什么
server.{myid}=127.0.0.1:2888:3888
server.{myid}=127.0.0.1:2889:3889
server.{myid}=127.0.0.1:2890:3890
比如刚才zoo-1作为第一个节点,使用 server.1=127.0.0.1:2888:388 ,myid里就填1即可,其他节点以此类推
3.启动
IDEA配置启动类
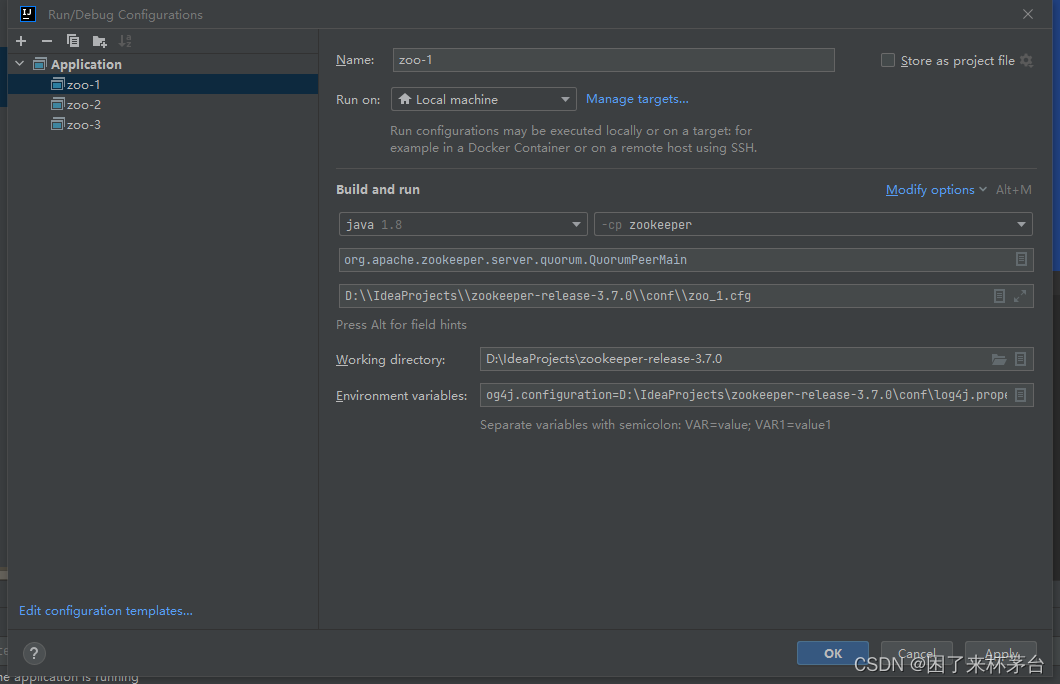
windows下路径一定要加双斜杠,包括cfg配置文件里的路径。
本文参考:https://bbs.huaweicloud.com/blogs/336112
https://www.codenong.com/js906d26cc2da0/
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 155
155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









