







- 从https://github.com/apache/incubator-doris-spark-connector 下载并编译,编译的时候建议使用Doris官方提供的编译镜像编译。
$ docker pull apache/incubator-doris:build-env-ldb-toolchain-latest
- 编译结果如下:
[root@xxx spark-doris-connector]# pwd
/data/incubator-doris-spark-connector/spark-doris-connector
[root@jiafeng spark-doris-connector]# ls target/ -trhl
总用量 7.7M
drwxr-xr-x 3 root root 4.0K 5月 11 22:32 maven-shared-archive-resources
-rw-r--r-- 1 root root 1 5月 11 22:32 classes.520860527.timestamp
drwxr-xr-x 5 root root 4.0K 5月 11 22:32 classes
drwxr-xr-x 5 root root 4.0K 5月 11 22:32 generated-sources
drwxr-xr-x 3 root root 4.0K 5月 11 22:32 maven-status
drwxr-xr-x 3 root root 4.0K 5月 11 22:32 thrift-dependencies
drwxr-xr-x 2 root root 4.0K 5月 11 22:32 maven-archiver
-rw-r--r-- 1 root root 174K 5月 11 22:32 spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT-sources.jar
-rw-r--r-- 1 root root 1 5月 11 22:32 test-classes.104362910.timestamp
drwxr-xr-x 4 root root 4.0K 5月 11 22:32 test-classes
drwxr-xr-x 3 root root 4.0K 5月 11 22:32 generated-test-sources
drwxr-xr-x 2 root root 4.0K 5月 11 22:32 surefire-reports
-rw-r--r-- 1 root root 551K 5月 11 22:32 original-spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT.jar
-rw-r--r-- 1 root root 7.0M 5月 11 22:32 spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT.jar
[root@xx spark-doris-connector]#
- 从官网下载Spark,如果官网比较慢,这里有个腾讯的镜像地址,十分方便。
https://mirrors.cloud.tencent.com/apache/spark/spark-3.1.2/
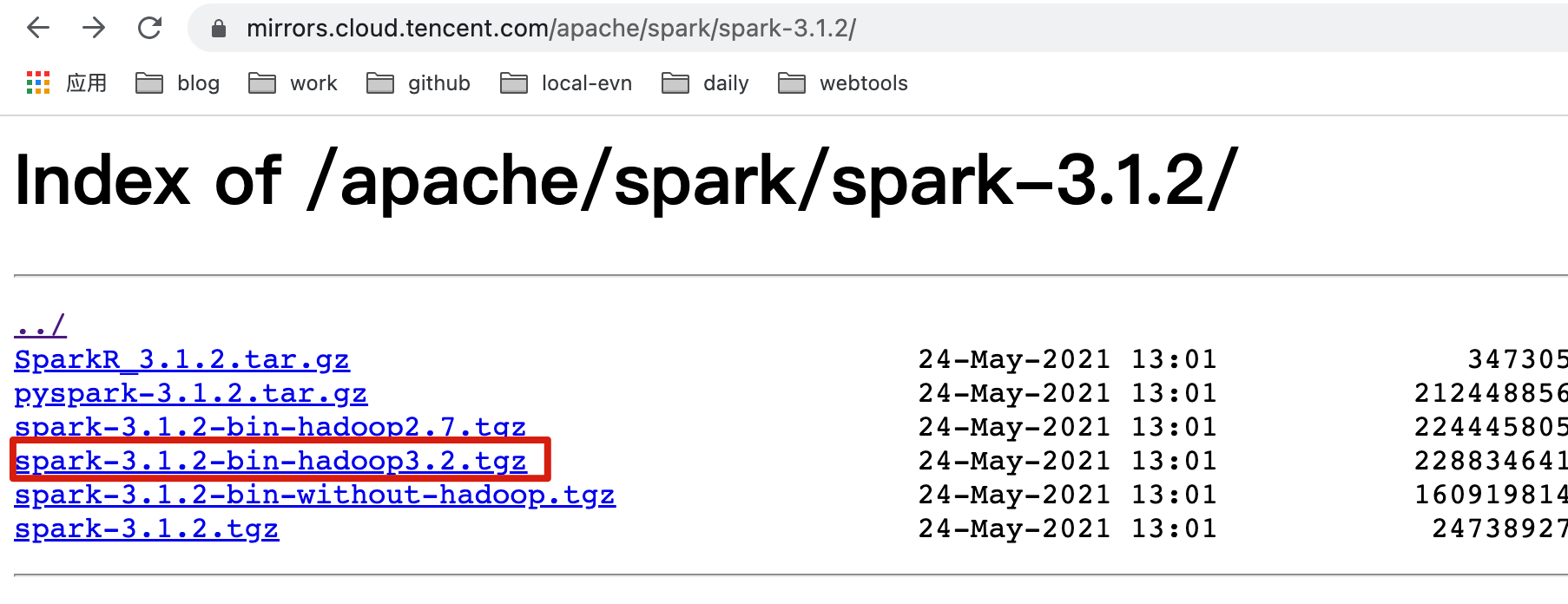
执行命令下载编译好的spark包,并解压。
#下载
wget https://mirrors.cloud.tencent.com/apache/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
#解压
tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
- 配置Spark环境。
vim /etc/profile
export SPARK_HOME=/your_parh/spark-3.1.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
- 将编译好的spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT.jar复制到spark 的jars目录。
cp /your_path/spark-doris-connector/target/spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT.jar $SPARK_HOME/jars
- 准备Doris表和数据,具体参照:https://blog.csdn.net/wangleigiser/article/details/124706433?spm=1001.2014.3001.5501 中的18和19 步骤。
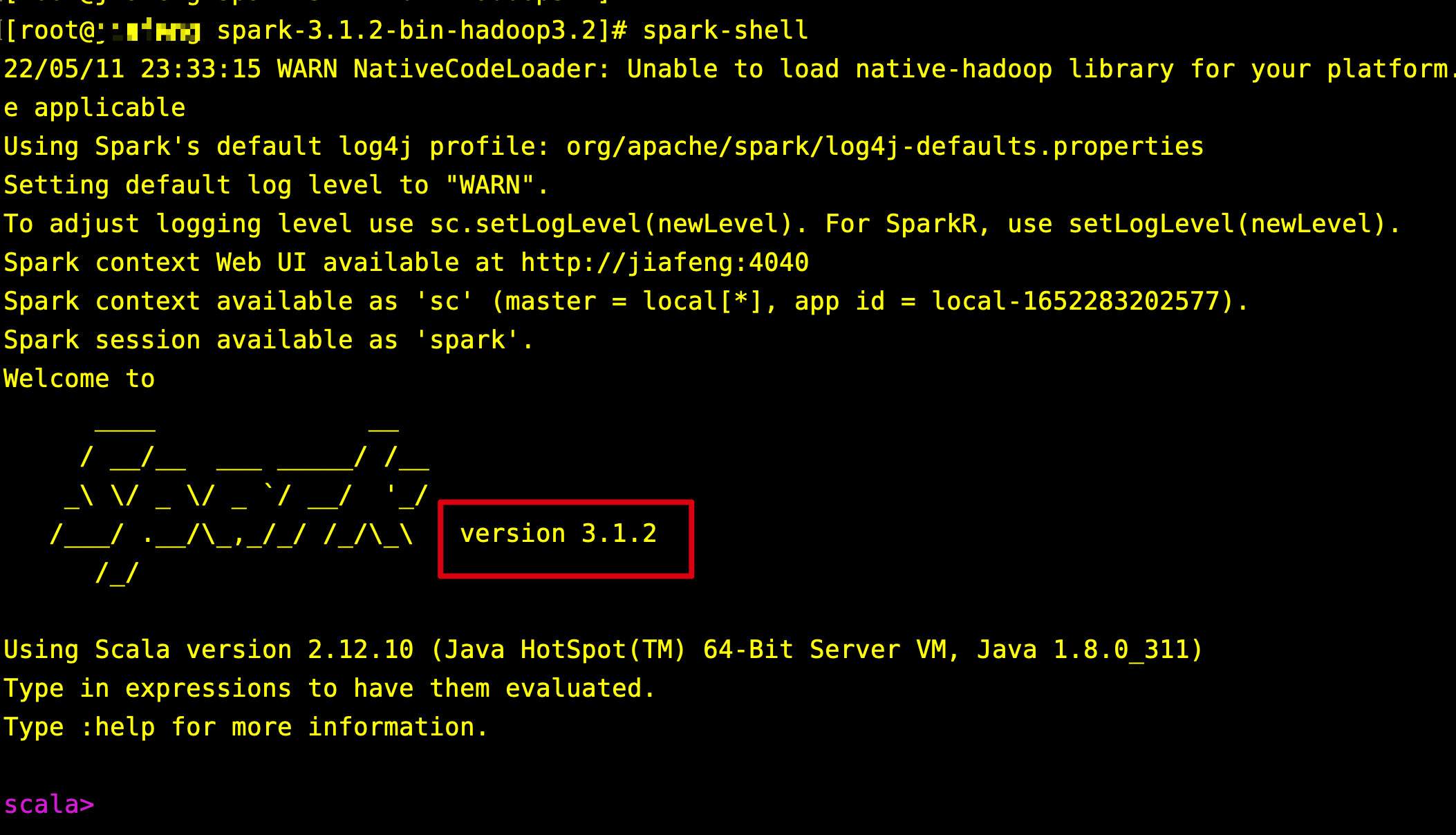
- 执行 spark-shell,进入Spark交互环境。确定Spark的版本。
 8. 执行如下命令,通过Spark-Doris-Conneter 查询Doirs数据。
8. 执行如下命令,通过Spark-Doris-Conneter 查询Doirs数据。
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("mongo_doris.data_sync_test"),
cfg = Some(Map(
"doris.fenodes" -> "127.0.0.1:8030",
"doris.request.auth.user" -> "root",
"doris.request.auth.password" -> ""
))
)
dorisSparkRDD.collect()
mongo_doris为数据库名称,data_sync_test为表名称,doris.fenodes为FE节点的IP和http_port,doris.request.auth.user为用户名,doris.request.auth.password为密码。
8. 执行完成后会将数据输出在控制台,如果看到数据输出则代表对接完成了。完整的情况如下:
scala> import org.apache.doris.spark._
import org.apache.doris.spark._
scala> val dorisSparkRDD = sc.dorisRDD(
| tableIdentifier = Some("mongo_doris.data_sync_test"),
| cfg = Some(Map(
| "doris.fenodes" -> "127.0.0.1:8030",
| "doris.request.auth.user" -> "root",
| "doris.request.auth.password" -> ""
| ))
| )
dorisSparkRDD: org.apache.spark.rdd.RDD[AnyRef] = ScalaDorisRDD[0] at RDD at AbstractDorisRDD.scala:32
scala> dorisSparkRDD.collect()
res0: Array[AnyRef] = Array([4, 1, alex, Document{{key1=1.0}}, 20.0, 3.14, 123456.0, 2022-05-10, false], [2, 1, alex, [1.0, 2.0, 3.0], 20.0, 3.14, 123456.0, 2022-05-09, false], [3, 1, alex, [Document{{key1=1.0}}], 20.0, 3.14, 123456.0, 2022-05-10, false])
scala>
- 集群版Spark一般会将依赖Jar包上传到HDFS,然后通过spark.yarn.jars添加HDFS路径,Spark会从HDFS上读取Jar包。
spark.yarn.jars=local:/usr/lib/spark/jars/*,hdfs:///spark-jars/doris-spark-connector-3.1.2-2.12-1.0.0.jar
具体参照:https://github.com/apache/incubator-doris/discussions/9486
想要更全面了解Spark内核和应用实战,可以购买我的新书。
京东地址: https://item.jd.com/13613302.html















 2295
2295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









