







用nodejs写一个简单的爬虫
前几天学习了nodejs,又在刷B站的时候看见有人在求视频封面,所以就想着用nodejs来获取B站的视频封面进行一次实践。
点我去先试试
首先,要找到每个视频的封面图片所在的位置。

可以看到在head的一个meta里可以找到图片的url。接下来就可以用nodejs来根据不同的视频av号来获取它的视频封面图片。
view部分
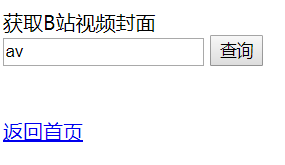
需要写一个输入视频id然后显示获取结果的blcover.html页面。
<form action="./blcover" method="get">
<label for="">获取B站视频封面</label>
<br>
<input type="text" name="avcode" value="av">
<input type="submit" value="查询">
</form>
<br>
<div class="tip"></div>
<div><a href="{url}" rel="noreferrer" target="_blank">{avcode}</a></div>
<br>
<div><a href="./index">返回首页</a></div>
nodejs服务器部分
我们先要用nodejs的http模块创建一个服务器,写在router.js中。
const http = require('http');//引入http模块
const file = require('./file');//引入自己写的模块
http.createServer(function(req, res){
try{
file.getCover('./blcover.html', req, res);
}catch(error){
res.write('error');
}
}).listen(8000);//启动一个8000端口的nodejs服务器
console.log('server is running at http://localhost:8000');
对html源代码进行处理
单独把处理html文件的操作封装在一个file.js文件中,先把需要用到的模块引入进来,再对外声明一下。
const fs = require('fs');
const querystring = require('querystring');
const url = require('url');
const https = require('https');
const cheerio = require('cheerio');//第三方
const zlib = require('zlib');
module.exports = {
getCover: function(file, req, response){};//处理的操作全放在这里
}
处理过程
var avcode = url.parse(req.url, true).query.avcode;//获取我们输入的avcode
var options = {//设置请求部分
hostname: 'www.bilibili.com',
port: 443,
path: `/video/${avcode}`,
method: 'GET',
headers:{
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
};
请求部分。刚开始的时候请求到的是一堆的乱码,后来查了一下,发现html的content-Encoding是gzip格式的,所以当我们得到response的内容后,先要解压缩。
https.get(options, function(res){
var html = '', output;
if(res.headers['content-encoding'] == 'gzip'){//处理gzip格式的网页
var gzip=zlib.createGunzip();
res.pipe(gzip);
output=gzip;
}else{
output = res;
}
output.on('data', function(data){//接收数据
data = data.toString('utf-8');
html += data;
});
output.on('end', function(){//接收完成
var $ = cheerio.load(html);
var $head = $('head');
var cover = $head.find(`[property='og:image']`);//找到图片所在的meta
var imgUrl = cover.attr('content');//找到图片的url
fs.readFile(file, 'utf-8', function(error, data){//读取自己写的html页面
if(error){
throw error;
}
response.writeHead(200, {"Content-Type": "text/html;charset=utf-8"});
if(!avcode){//如果没有avcode,代表是第一次进入,把提示隐藏掉
data = data.replace('<a href="{url}" rel="noreferrer" target="_blank">{avcode}</a>', '');
}else{
if(!imgUrl){//视频不存在,img肯定不存在
data = data.replace('<a href="{url}" rel="noreferrer" target="_blank">{avcode}</a>', '该视频不存在!');
}else{//成功找到,替换提示部分的html代码
data = data.replace('<div class="tip"></div>', '<div class="tip">查询完毕</div>');
data = data.replace('{url}', imgUrl);
data = data.replace('{avcode}', avcode);
var log = avcode + ': ' + imgUrl + '\n';
fs.appendFile('log.txt', log, function(){});//可以把search过的记录下来
}
}
response.write(data);//把处理完后的view的代码显示到浏览器
response.end();
});
});
res.on('error', function(){//报错
console.log('down data error');
});
});
输入av41522363后查询到的内容:
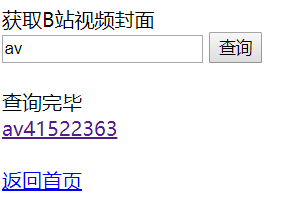
点击后跳转到新窗口,内容是查询到的图片,就可以右键保存了。















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









