









目录
一、数据库约束(Foreign Key Constraint)
一、数据库约束(Foreign Key Constraint)
约束类型:
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标
- 识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略
- CHECK子句
其他的都比较常见,也比较好理解,这里主要介绍一下外键约束。
外键用于关联其他表的主键或唯一键。
语法:foreign key (字段名) references 主表(列)
1、NO ACTION
案例:
1.创建班级表classes,id为主键:

2.创建学生表stuents,一个学生对应一个班级,一个班级对应多个学生。使用sid为主键,
cid为外键,关联班级表cid

建立学生表的外键关系时,给右边Options选项改为NO ACTION

建表完成后再去插入语句,然后我们尝试去删除班级表中的记录,这时我们会发现,无论选择用DELETE、TRUNCATE还是DROP方法,都无法删除班级表中跟约束有关的记录。外键约束在这里的作用是没有删除学生表中的记录就不允许删除班级表。

2、SET NULL
还是以上面两个表为例,先建立好班级表,然后建立学生表的时候使用cai作为外键,右侧的Options选择SET NULL。注意,这里学生表的cid要允许为空,因为SET NULL之后删除班级表的cid字段学生表的cid会置为空,如果不允许为空就会报错。
这里只放学生表截图了,班级表同上


这时我们执行DELETE语句删除班级表就不会报错了。SET NULL可以允许班级表的外键字段为空,也就是删除了,随之学生表的cid字段也都会置为空。

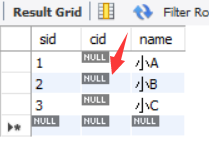
3、CASCADE
以NO ACTION的表为例,首先建立班级表,和上面的一样,这里就不再多说了,然后建立学生表时只需要将右边的Options改为CASCADE就可以了。

此时我们再执行语句delete from classes where cid = 1;删除班级表的cid,就会发现班级表的相关字段和学生表的相关字段都被置为空,可以和上面的SET NULL 做对比。
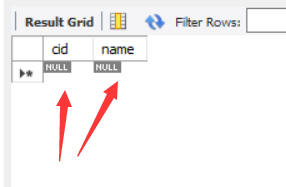

可以很明显发现两者区别。
总结:无论哪种策略,drop班级表都无法成功,必须先drop学生表才能drop学生表,外键策略主要影响的是update、delete。第一种NO ACTION不允许delete或者update,第二种SET NULL 和第三种CASCADE都允许delete删除班级表的cid,SET NULL 会把学生表的cid置为null,CASCADE会把对应的学生记录删除。
二、聚合查询(Aggregation Query)
1、聚合函数
常见的统计数据、计算平均值操作都可以通过聚合函数来实现。常见的聚合函数有:

- count函数

- sum函数

- avg函数

- max函数

- min函数

2、GROUP BY 子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
语法:![]()
聚合查询时,SELECT子句只能出现两种内容:1、分组依据(group by后面的字段)
2、聚合函数(count...)
举例说明1:现有如下表

若要查询一个班级的每个科目成绩最高的分数,则语句应为
SELECT 科目,max(成绩) FROM 成绩表 GROUP BY 科目;
得到的结果应该是这样:

举例说明2:
准备测试表及数据:职员表,有id(主键)、name(姓名)、role(角色)、salary(薪水)
建表如下:

现在要查询每个角色最高工资、最低工资、平均工资。语句如下:
SELECE role,max(salary),min(salary),avg(salary) FROM 职员表 GROUP BY role;
这里也可以起别名、排序...
SELECT role, max(salary) max_salary,avg(salary) avg_salary from emp GROUP BY role ORDER BY max_salary DESC;
执行结果如下:

3、having 聚合后再过滤
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING。
现在要查询平均工资大于600的角色以及这个角色的最高薪资
SELECE role,max(salary) max_salary,avg(salary) avg_salary FROM 职工表 GROUP BY role HAVING avg_salary >= 600 ORDER BY avg_salary DESC;
执行结果如下:

三、联合查询/多表查询(Associated Query)
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积。
联合查询优点:降低了数据的冗余,提升了操作的便利性。
缺点:增加了查询的复杂性。
- 那么什么是笛卡尔积?

举例说明:现在有班级表和学生表,学生所属不同班级,现有如下语句:
SELECT * FROM 班级表,学生表;

那么查询记录应该有几条呢?答案是4*7=28条。
这里可以用SELECT COUNT(*) FROM class,student;来验证一下

1、内连接(inner join)
笛卡尔积给出了28行结果,而我们查询学生所在的班级,真正想要的只有七行结果,所以我们现在的目标是从28行中过滤出有效的7行记录。这里就可以使用where语句进行过滤。
SELECT c.cid,c.name,sid,s.name from class c,student s where c.cid = s.cid;
这里我们使用的是别名,因为班级表和学生表的cid字段有歧义,使用别名加以区分。
查询到的结果如下:

为了更好地理解内联,这里我们换个语法来讲。
SELECT c.cid,c.name,sid,s.name FROM class c join student s on c.cid = s.cid;
这里得到的结果和上面的是一样的。但是我们现在的表体现不出来内联的效果,当我们在班级表增加一个没有学生的班级,在学生表添加一名班级cid不存在的学生,内联的效果就能体现出来了。具体的可以参考下面的外连接。
可以看到,语法中是class join student ,班级链接学生表,这里我们以班级为左表(主表),学生为右表。内连接相当于左右表的并集。查询范围是左表和右表的公共部分。

所以当表为这样的时候:


班级表有些班级没有学生,学生表中有的学生对应的班级id不存在。如cid为105的班级和sid为8的学生。
执行上述语句出现的结果还是会一样。
2、自连接
自连接是指在同一张表连接自身进行查询。
自己和自己联合,要求至少给一个表起别名,因为字段有歧义。
如:SELECT * from class c,class t;
两张表都是班级表上做联合查询。
举例:这里建立一张带有学生和班长的学生表。


现在要查找出学生的id+其班长的id:
SELECT s.name stu,t.name leader FROM students_with_leader s,students_with_leader t WHERE s.sid = t.leader_id;
得到执行结果:每个学生对应自己班长。这里班长可以理解为组长,我就不再改了。

这里也可以用 join on 语法写。具体语法如下:
SELECT s.name stu,t.name leader FROM students_with_leader s join students_with_leader t on s.leader_id = t.sid;
这样写和上面拿到的结果是相同的,FROM后面跟的是表名称,可以认为s是主表,join后面的t是副表,两个表都是由students_with_leader引申出来的,然后再做联合查询。但是一定要注意别名,别名字这里很重要,用以区分两张表有歧义的部分。
3、外连接(outer join)
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
这里我们还是以班级表和学生表为例。
班级表有些班级没有学生,学生表中有的学生对应的班级id不存在。如cid为105的班级和sid为8的学生。
1> 左外联
左外联以左表为主,即查询范围为有班级没学生和有班级有学生。

当我们执行如下语句的时候,会看到这样的结果:
SELECT * FROM class c left outer join student s on c.cid = s.cid;
当然,这条语句如果去掉outer结果是一样的,上面语句等同于这条语句:
SELECT * FROM class c left join student s on c.cid = s.cid;
2>右外联
右外联以右表为主,即查询范围为有班级有学生和有班级没学生

现执行右外联语句:
SELECT * FROM class c right outer join student s on c.cid = s.cid;
得到如下结果:

同样,语句这样写也可以:
SELECT * FROM class c right join student s on c.cid = s.cid;
3>全外联
全外联,顾名思义,左表右表都包括在查询范围内。

MySQL暂时不支持全外联查询,这里就不做演示啦。
小结:只有两张表数据对不上时,区分内联外联才有意义。内联相当于左表右表的并集,左外联包括整个左表相关的记录,右外联包括整个右表相关的记录。
在语法上,join后面接连接的表名,on后面接条件。
4、子查询(subquery)
5、合并查询
子查询和合并查询我们下次讲吧...太累了
求个赞..
注:文章有参考比特课件和老师板书














 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









