







 本文详细介绍了如何在Linux环境下启动HBase和ThriftServer,配置日志,使用Happybase库在Python中进行HBase连接、DDL(定义表结构)和DML(数据管理)操作,包括创建表、查询、删除等实例。
本文详细介绍了如何在Linux环境下启动HBase和ThriftServer,配置日志,使用Happybase库在Python中进行HBase连接、DDL(定义表结构)和DML(数据管理)操作,包括创建表、查询、删除等实例。
一、启动Hbase、ThriftServer
(1)确保HDFS、Hbase、Zookeeper服务正常运行:
1.启动hdfs
start-dfs.sh
2.启动Hbase
start-hbase.sh
3.开启ThriftServer
hbase-daemon.sh start thrift
4.创建日志文件log4j.properties
进入HBase安装目录:cd /usr/local/hbase-2.5.6/conf
创建文件:vi log4j.properties
输入内容:log4j.rootLogger=ERROR,console
保存文件并关闭::wq
5.启动hbase shell
hbase shell
二、查看启动进程
[root@hadoop~]# jps
1556 HRegionServer
485 SecondaryNameNode
230 NameNode
1400 HMaster
1993 ThriftServer
1114 HQuorumPeer
2111 Jps
3514 DataNode
三、happybase操作
(一)pycharm新建项目
(1)windows下安装happybase库:
pip install happybase -i https://pypi.tuna.tsinghua.edu.cn/simple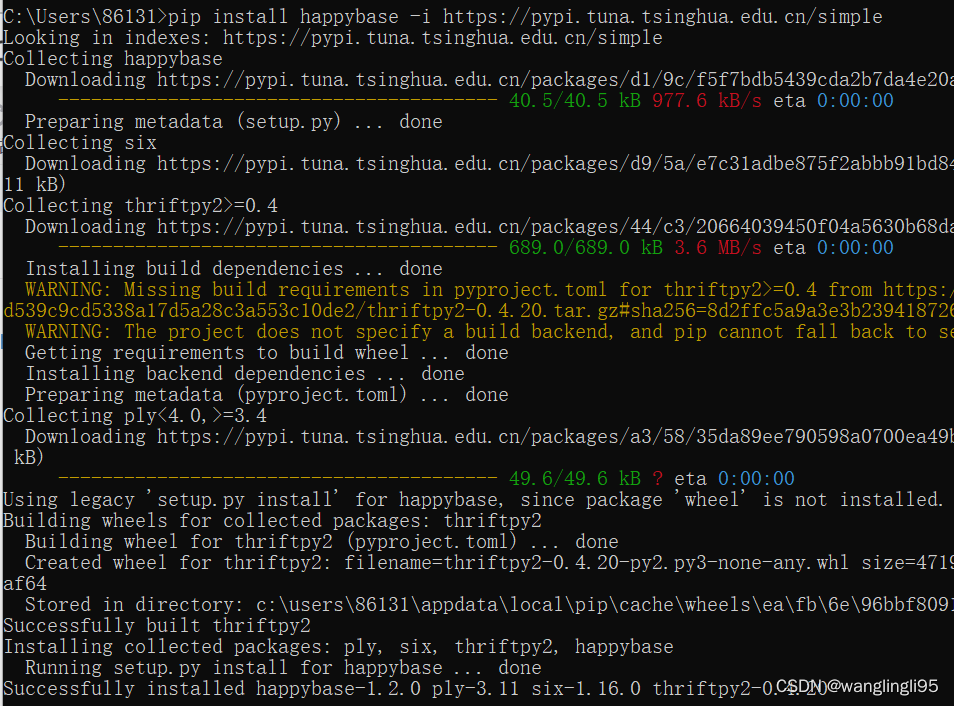
查看happybase是否安装成功(进入python进行导包):

(2)使用pycharm新建一个python项目(使用本地的python解释器,要知道电脑安装python的路径):
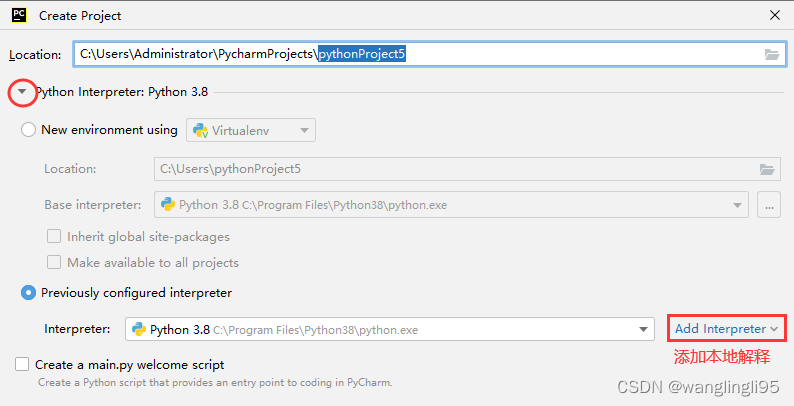

(二)建立与hbase的连接
在python项目下新建一个conn.py文件:
(1)创建连接
#1.导入happybase库
import happybase
#2.建立HBase的连接
conn = happybase.Connection(
host="192.168.25.200", #主机名
port=9090, #Thrift的默认端口号
timeout=60000 #超时时间
)
#3.通过conn对象,调用tables方法,获取hbase中的表格
print(conn.tables())
#4.关闭连接
conn.close()注意:如果运行结果报错显示无法连接到虚拟机节点,则需要检查你的虚拟机是否已经关闭防火墙,如果防火墙为开启状态,需要关闭防火墙:systemctl stop firewalld.service
(三)DDL操作(表结构的管理)
(1)创建表
#在默认命名空间下创建新表mytable,包含列族cf1、cf2、cf3
conn.create_table(
'tab_name', # 表名,字符串类型
{'cf1': dict(max_versions=10), # 列族1
'cf2': dict(max_versions=1), # 列族2
'cf3': dict(), # 列族3,默认属性
}
)
#在school命名空间school下,创建新表student,包含列族info,属性为默认;包含列族score,属性设置最大版本号为5
conn.create_table("school:student",{"info":dict(),"score":dict(max_versions=5)})
# 通常,管理HBase,建议使用HBase Shell,因为HappyBase使用的Thrift接口仅有有限功能。(2)查询表格的列族信息
#1.获取某个表格对象
stu_table = conn.table("school:student")
#2.查询表格的列族信息
print(stu_table.families())(3)删除表
#4.删除某个表格school:student(先禁用再删除)
#第二参数:如果禁用参数为True,则此方法首先禁用该表(如果尚未禁用),然后将其删除。
conn.delete_table("school:student",True)
#打印当前表格信息
print(conn.tables())(四)DML操作(数据的管理)
(1)获取表对象
stu_table = conn.table('school:student') # 传入表名
# 表不存在也不会报错,本步骤不会真的链接到HBase,只是在代码内创建一个table对象(2)插入单行数据
要在我们的表中存储单个单元格的数据,我们可以使用table.put(),它接收行键和要存储的数据。数据应该是一个字典,包含多个单元格值,将列名映射到一个值:
stu_table = conn.table('school:student')
stu_tab.put(b"s001",{b"info:name":b"zhangsan",b"info:age":b"20"})
stu_tab.put(b"s002",{b"info:name":b"lisi",b"info:age":b"22"})
stu_tab.put(b"s003",{b"info:name":b"wangwu",b"info:age":b"21"})
stu_tab.put(b"s004",{b"info:name":b"xiaohong",b"info:age":b"25"})(3)查询单行数据
table.row()从表中检索单行,并将其作为映射列到值的字典返回。
#通过行键查询单行数据(返回值是字典)
row1 = student_tab.row("s001")
#通过行键、列族:列限定符查询某个单元格值
row1_name = student_tab.row("s001",["info:name"])
print(row1_name)
row1_name_val=row1_name[b'info:name']# 返回值:b'zhangsan',注意是<class 'bytes'>类型
#将字节数组转为字符串类型
print("行键s001对应的姓名是:" + str((row1_name_val),encoding="utf-8"))
# 转换字符串的语法格式:
str(bytes对象, encoding="编码格式,通常使用utf-8")(7)查询多行数据
table.rows() 方法的工作方式与table.row() 类似,但需要多个行键并将它们作为 (key, data) 元组返回。
#通过行键查询多行数据(返回值是字典列表)
row_1_2 = student_tab.rows(["s001","s002"])
print(row_1_2)
"""
返回值:
[(b's001', {b'info:age': b'20', b'info:name': b'zhangsan'}), (b's002', {b'info:age': b'22', b'info:name': b'lisi'})]
"""
#遍历每一行的数据
for key,value in row_1_2:
print(key,value)(8)获取多版本数据单元格值
HBase支持存储同一单元的多个版本。这可以为每个列族配置。要检索给定行的列的所有版本,可以使用 table.cells()。此方法返回一个有序的单元格列表,最新版本排在最前面。
# 首先,准备一个保存多版本的表,先往s001,插入3个版本的数学成绩
stu_table.put(b"s001",{b"score:math":b"80"})
stu_table.put(b"s001",{b"score:math":b"90"})
stu_table.put(b"s001",{b"score:math":b"100"})stu_table = conn.table('school:student')
#获取s001,数学的三个版本数据
mathVal = stu_table.cells("s001","score:math",versions=1)
print(mathVal) #[b'100']
mathVal = stu_table.cells("s001","score:math",versions=3)
print(mathVal) #[b'100', b'90', b'80']
(9)scan表格数据
除了检索已知行键的数据外,HBase 中的行还可以使用 table.scan() 遍历表中所有行,基本扫描程序如下所示。
#扫描整个表格
table_rows = stu_table.scan()
#将rows转为列表
rowsList = list(table_rows)
#遍历每一行数据
for key,value in rowsList:
print(key,value)通过设置limit参数,指定扫描前多少行数据。
#扫描前2行数据,limit
limit_rows = stu_table.scan(limit=2)
print(list(limit_rows))通过设置row_start和row_stop参数指定扫描器应启动和停止的行键。row_start之后的第一行将是第一个结果, row_stop之前的最后一行将是最后一个结果。
# 请注意,范围的开头是包含在内的,而结尾是不包括的。
rows = stu_table.scan(row_start="s002",row_stop="s004")
print(list(rows))(10)删除数据
table.delete() 方法从表中删除数据。要删除完整的行,只需指定行键:
stu_table.delete("s001")要删除一列或多列而不是整行,还需指定 columns 参数:
stu_table = conn.table('school:student')
#删除某一个单元格数据(所有版本的数据都会删除)
stu_table.delete("s001",columns=["score:math"])happybase官方文档:
HappyBase — HappyBase 1.2.0 documentation https://happybase.readthedocs.io/en/latest/index.html
https://happybase.readthedocs.io/en/latest/index.html


















 2275
2275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











