







集合总结(II):
1. Set体系特征是什么,下面不同子类的区别是什么样的, 他们使用起来有什么特点?
a. Set内元素不可重复(需设定唯一性的判断标准), 元素是无序的(存入和取出的顺序不一定一致)
b. Set接口中没有不同于Collection的特有方法
2. Set子类中HashSet和TreeSet的区别?
a. Set中子类HashSet的底层数据结构是Hash Table; TreeSet的底层数据结构是二叉树
b. 由于两种底层数据结构不同,他们保证元素唯一性的方法不一样
3. HashSet和TreeSet是如何保证元素唯一性的?
a. HashSet 是通过调用元素的两个方法保证元素的唯一性的:hashCode()+equals()
a.1 先比较元素的hashCode(),如果不一致,即存入HashSet
a.2 如果hashCode一致,再调用equals()比较元素内容是否一致
a.3 所以, 存HashSet集合需要复写存入元素的hashCode()和equals()方法
a.4 同理, 判断HashSet内是否存在元素contains和删除remove操作,都需要先判断hashCode再判断equals
// a. HashSet 存入自定义元素的示例
class Student{
private String name;
private int age;
public Student(String name,int age){
this.name=name;
this.age=age;
}
pubic int hashCode(){ // --> a.1 a.3 复写hashCode()
return name.hashCode()+age*40;
}
pubic boolean equals(Object obj){ // --> a.2 a.3 复写equals方法
if(obj instanceof Student) // 此处即使后期存在泛型也需要判断,equals参数是Object
return false;
Student st=(Student)obj // 此处需呀cast
return this.name.equals(obj.name) && this.age==obj.age;
}
}b. TreeSet可以有两种方式保证元素唯一性:(自定义类必须要这么做)
b.1 自然顺序比较:让元素具有比较性,
- 元素需要实现Comparable接口
- 复写 int compareTo(obj); a.compareTo(b); 返回正, a>b; 返回0, a=b;返回负, a<b
b.2 传给TreeSet一个比较器:让集合自身具备比较性
- 如果元素自身不具备比较性(调用类没有复写compareTo)或元素自身的比较性不是所需要,需要让集合自身具备比较性
- 指定比较器排序: 定义一个Class实现Comparator接口
- 复写compare方法; // int compare(obj1,obj2); // compare内部代码需要确定比较原则, 并根据原则返回正数, 0, 负数
- 将比较器传给Tree set Constructor; // 让集合初始化的时候就具备比较性
c. 当两种排序都存在时,以比较器为主;
d. Collections 工具类有方法可以使比较器反序 Comparator reverseOrder(comparator)
// b.1 TreeSet实现元素比较性的排序(实现Comparable接口)
class Student implements Comparable{
// name,age,constructor...
...
// 比较条件: 先判断age,再判断name
public int compareTo(Object obj){
if(!(obj instanceof Student)) // 此处因为没有定义泛型,需要判断
throws new RuntimeException("Not a Student.");
Student st=(Student)obj; // 此处因为没有泛型,需要cast
if(this.age>st.age)
return 1;
else if(this.age<st.age)
return -1;
return this.name.compareTO(st.name); //String 实现过comparable
}
}// b.2 让TreeSet自身具有比较性
class MyComparator implements Comparator{ // 实现Comparator
int compare(Object obj1,Object obj2){ // 复写compare
if(!(obj1 instanceof Student)||!(obj2 instanceof Student)) //没有定义泛型,需要判断
throws RuntimeException("Not Student.");
Student st1=(Student)obj1; // 没有定义泛型,需要cast
Student st2=(Student)obj2;
int num=st1.getName().compareTo(st2.getName());
if (num=0)
num=st1.getAge()-st2.getAge();
return num;
}
}
class Demo{
public static void main(String[] args){
TreeSet ts=new TreeSet(new MyComparator()); // 传入 TreeSet
}
}
4. 二叉树结构是什么样的?

a. 存的时候, 第一个元素存入作为树的顶点开始后, 每存入一个元素,从顶点开始比较, 大的存入右边,小的存入左边 (注意这个大小是comparaTo/compare定义的)
b. 如果相等, 不存入
c. 取出的时候, 默认的顺序是从小到大取(注意这个大小是comparaTo/compare定义的)
d. 当存入元素多的时候, 二叉树会自动折中一个数作为起始比较值
d. 二叉树的好处是可以节省比较次数
5. HashSet和TreeSet各自的优劣是什么?
需要补充数据结构知识,此时无法详尽回答
6. JDK1.5之后引入了泛型的概念, 集合类有了自己的泛型限定,这样的好处是什么?
a. 泛型类似添加了限定集合中存放元素类型, 这样可以把错误的存放扼杀在编译时期,增加了代码的安全性
b. 泛型的定义也避免了需要用到集合中元素的对象特有方法时需要判断类型和类型转换的麻烦
c. Collection及子类,Iterator,Comparator都是带泛型的
(具体对泛型的介绍见"黑马程序员——Java泛型“)
a. Map中的子类对象是Collection接口子类对象的父类, Collection的底层的实现是通过Map
b. Map体系的特点是数值以键Key值Value对的形式存储, Key要保证唯一性,而Value不需要
c. Map体系结构:
c.1 HashTable: 底层数据结构是哈希表, 存入对象必须实现hashCode和equals,不可以存入Key=null,Value=null,线程同步,JDK 1.0
c.2 HashMap: 底层数据结构是哈希表, 存入对象必须实现hashCode和equals, 可以存入Key=null,Value=null,线程不同步, 效率高, JDK 1.2
c.3 TreeMap: 底层数据结构是二叉树, 需要使键有序(Comparable/Comparator), 不可以存入Key=null,可以存入Value=null, 线程不同步,效率高,JDK 1.2
8. Map接口中关于增删改查的共性方法有哪些,使用有什么特点?
a. 增
- V put(K key,V value); //没有add, ,Map的 //添加一个新值到一个键,此键的值被新值替换,方法返回旧值
- void putAll(Map)
b. 删
- clear();
- remove();
c. 改
- put(key,value); //没有add, ,Map的, put即是添加,也是修改
- putAll(Map);
d. 查
- V get(Object Key); // 根据Key获取Value,如果没有此映射返回 null
- size()
- Collection values(); // 返回一个包含此Map所有Value的集合
- Set entrySet(); //返回一个包含键值对的Set<Map.Entry<K,V>>; 遍历map用
- keySet(); // 返回一个包含所有Key的集合Set<K>; 遍历map用
e. 判断
- containsKey(obj);
- containsValue(obj);
- isEmpty();
9. 如何遍历集合?
a. Set<K> keySet方式
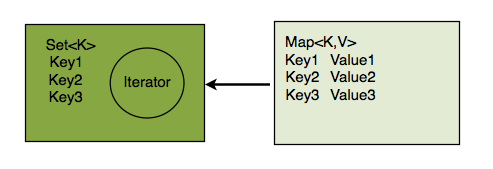
a.1 keySet()将map中所有的键值存入到Set集合.
a.2 取出迭代器Iterator, 迭代方式取出所有的Key,
a.3 再根据get(Object key)方法,获得每一个Key对应的Value
// a. keySet遍历方式
Map<Integer,String> myMap=new HashMap<Integer,String>;
myMap.put(0,"Value0");
myMap.put(1,"Value1");
myMap.put(2,"Value2");
Set<Integer> keys=myMap.keySet(); // --> a.1
for(Iterator<Integer> it=keys.iterator(); it.hasNext(); ){ // --> a.2
tempKey=it.next();
tempValue=myMap.get(tempKey); // --> a.3
// 其他操作代码
}b. Set<Map.Entry<K,V>> entrySet()方式
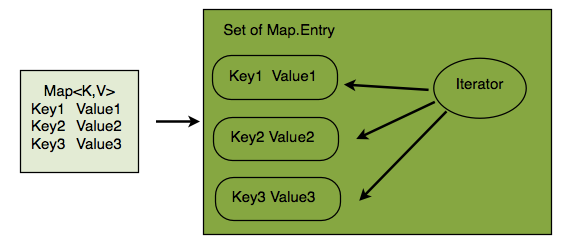
b.1 entrySet得到一个映射关系Map.Entry<K,V>的Set
b.2 Map.Entry<K,V> 是一个Map内部接口,其接口的实例对象包含了Key和Value的信息以及获取方法getKey(),getValue()
b.3 Set获得Iterator遍历所有Map.Entry
b.4 通过getKey,getValue方法可以得到所有关于MapEntry的Key和Value
//
// ... ... myMap =...<Integer,String>
// ... ... myMap.put(...)...
Set<Map.Entry<Integer,String>> mapEntries=myMap.entrySet(); // --> b.1
for(Iterator<Map.Entry<Integer,String>> it=mapEntries.iterator();it.hasNext();){ // --> b.3
tempMapEntry=it.next();
tempKey=tempMapEntry.getKey(); // --> b.4
tempValue=tempMapEntry.getValue(); // --> b.5
//其他操作代码
}10. Map.Entry为什么要定义成内部接口,具体是什么作用?
a. Map.Entry 表示的是一种键值对关系,是Map内部的一个特性,所以定义在内部是最合理的
b. Map是一个接口,其内部只能定义内部接口而不能定义成内部类
c. 在Map的子类中, 内部实现了Entry这个内部接口, 而且这个接口是暴露出来以方便大家实用的(注意暴露出来的引用是Map.Entry接口)
d. 得到了这个Map.Entry, 就可以对调用其中的方法获取Key,Value
e. Map.Entry还定义了setValue这个方法, 可选择性使用
11. 自定义类需要存入Set/Map就要考虑比较性, 需要注意一些什么?
a. 如果要存入HashSet/Table/Map, 那么要复写hashCode和equals方法
b. 注意 equals(Object obj) 是Object的方法,没有泛型限定,所以即使HashSet/Table/Map限定了泛型,复写equals方法时需要考虑判断instanceof和 cast类型转换
c. 如果存入TreeSet/Map, 要么根据自然比较顺序实现Comparable<T>, 要么根据自定义比较顺序给集合传入临时比较器Comparator<T>
d. 注意, Comparable和Comparator都可以添加泛型限定,而且compareTo(T obj); compare(T obj1,T obj2); 都应用了这种限定,所以复写时不需要判断instanceof和cast类型转换
e. 自定义类型时, 最好把以上这些都考虑到, 以备后期存入不同容器
12. Collections Arrays 工具类有什么特点,内部有那些常用的方法?
a. Collections工具类是一个专门为集合提供多种操作的静态方法工具类
a.1 List无比较性, 为List排序: sort(List<T> ls); 注意, 自定义类型元素T实现comparable 才可以; 而且只能对List排序
a.2 不想用List<T>, 元素自然顺序排序: sort(List<T>,Comparator<T>); 传入一个比较器来比较
a.3 max(Collection<T>); max(Collection<T>,Comparator<T>); //得到最大值
a.4 binarySearch(List<T>, T key); binarySearch(List<T>,Comparator<T>, T key); //对有序List二分查找
a.4 fill(List<T>,T key); 将List所有元素全都替换成同一个元素 key
a.5 replaceAll(List, oldValue, newValue); 将List里面的所以oldValue替换成newValue;
a.6 void reverse(List); //反转List里面元素的顺序
a.7 Comparator<T> reverseOrder(); //返回一个强行逆转元素自然顺序的比较器, 通常配合其他方法使用(sort(list, Collections.reverseOrder());)
a.8 Comparator<T> reverseOrder(Comparator<T>); // 返回一个和传入比较器顺序相反的比较器
a.9 synchronizedCollection/Map/List/Set(xxx);// 返回一个线程同步的Collection/Map/List/Set; 底层就是用把所有的操作都加了同一个锁的同步
a.10 shuffle(List); shuffle(List,Random) // 随机排列List中的元素(可选择添加随机源);
a.11 将集合变数组: T[] toArray(T [])
- 指定类型的数组长度是一个预留转化长度的表示
- 如果预留长度小于等于集合的size,那么结果和集合size一致
- 如果预留长度大于集合的size,那么结果中多预留的位置用null占位
- 好处: 限定对元素操作, 当返回元素时, 返回数组就只能查询元素而不可以对其中的元素增删
b. Arrays对数组操作的静态方法工具类
b.1 sort
b.2 binarySearch
b.3 toString(arr); //打印出arr 打印形式 [x,x,x]
b.4 asList(arr); // 将一个array转换成List
- 如果array内是引用数据类型String[],可以将其中的元素自动存入List<String>;
- 如果array内是基本数据类型int[], 可以转换是将其作为一个整体传入List<int[]>, List中只有一个元素;
- 数组变集合的好处是, 可以调用集合中现成的方法来对”数组中的数据”进行各种操作(很多方法的返回值都是 Xxx[]);
- 注意: 如果使用了asList得到一个List对象, 不可以对其实用add,remove方法,否则会报不支持的操作异常
13. 增强for,iterator,ListIterator 都能对集合进行遍历, 它们的区别是什么?
a. 增强for遍历集合局限性:只能取出,不能对集合更多操作
b. iterator出了遍历还可以进行remove,对原集合进行删除元素动作,
c. ListIterator对List操作,还可以在遍历过程中对集合进行增删改查
参考资料: 传智博客毕老师Java基础视频——集合/Map部分















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









