







目录
视图(view )创建、删除、查询
1、视图是查询结果的一个封装,视图中的所有数据都来自它查询的表,视图本身不存储任何数据。
视图并不能提供性能,理论上直接查表性能更高。更不推荐通过视图修改数据。
2、视图能过封装复杂的查询结果,创建视图:create [or replace] view 视图名 as 查询语句 [with read only] [with check option];
| or replace:表示如果视图已经存在,则替换 with check option:表示只允许修改视图能看到的数据,如下所示,此时无法通过 emp10 视图新增 10号部门以外的数据,也无法修改部门号。 create or replace view emp10 as SELECT T.* FROM emp t where deptno =10 with check option; |
select * from emp;--查询员工表
create or replace view emp_view as select empno,ename,job from emp;--创建一个视图,此时它是可以修改的数据的
create or replace view emp_view_2 as select empno,ename,job from emp with read only;--创建一个视图,视图只读,无法修改数据
--查询视图,增删改查视图与表是一样的,视图就相当于封装后的表。此时只能查询指定的3列,起到了对 emp 表的封装作用
select * from emp_view;
select * from emp_view_2;
--因为视图是不存储数据的,这里对视图的修改就相当于对 emp 的修改。实际应用中应该避免视图来修改数据,让它尽量只读
update emp_view set ename='liSi' where empno = 7499;--可以修改数据
update emp_view_2 set ename='liSi2' where empno = 7499;--无法再修改数据,因为 emp_view2 只读,此时会报错。
--查询每个部门最高薪水的员工姓名,薪水,以及他所属的部门名称。
select e1.ename, e1.sal,d1.dname from emp e1,(select deptno,max(sal) as maxsal from emp group by deptno) t1,dept d1
where e1.deptno = t1.deptno and e1.sal = t1.maxsal and e1.deptno = d1.deptno;
--对于复杂的查询语句,封装成视图后,查询会看起来清爽很多
create or replace view emp_dept_v1 as
select e1.ename, e1.sal,d1.dname from emp e1,(select deptno,max(sal) as maxsal from emp group by deptno) t1,dept d1
where e1.deptno = t1.deptno and e1.sal = t1.maxsal and e1.deptno = d1.deptno
with read only;
select * from emp_dept_v1;--同样是检索各部门薪水最高的员工,通过视图转一层3、删除视图:drop view 视图名,如:drop view emp_view_2;--删除视图 emp_view_2
4、查询视图:
| select * from user_views; --查询当前用户下创建好所有视图 -- 查询某个表被当前用户下的哪些视图引用 |
5、表与视图设置注释
6、完整视图举例:人员信息同步视图.sql
序列(sequence)创建、修改、删除、查询
1、序列是一种数据库对象,用来自动生成一组唯一的序号。序列是一种共享式的对象,多个用户可以共同使用序列中的序号。一般将序列应用于表的主键列,确保主键不会重复。
2、Sequence 创建语法:create sequence sequence_name [increment by num] [start with num] [maxvalue num|nomaxvalue] [minvalue num|nominvalue] [cycle|nocycle] [cache num|nocache]
| ① start with num:设置序列开始的第一个整数。默认值为 1 。 ② increment by num:设置每次增长的数。正数表示升序,负数表示降序。默认值为 1 。 ③ maxvalue num | nomaxvalue :设置最大值 num,nomaxvalue 关键字表示默认值,升序是 10的27次方 ,降序是 1 。 ⑤ minvalue num| nominvalue :设置最小值 num,nominvalue 关键字表示默认值,升序是 1 ,降序是 10的26 次方。 4)cycle | nocycle:关键字表示序列达到最大值或者最小值,是否重新开始。如 cylce 表示升序达到最大值后从最小值重新开始,降序序列达到最小值后从最大值重新开始。nocycle 表示不重新开始,序列升序达到极限值后就报错。默认 nocycle 5)cache num:使用 cache 选项时,该序列会根据序列规则 预生成一组序列号 。保留在内存中,当使用下一个序列号时,可以更快的响应。当内存中的序列号用完时,系统再生成一组新的序列号,并保存在缓存中,这样可以提高生成序列 号的效率。 oracle 默认会生产 20 个序列号 。 6)nocache :不预先在内存中生成序列号。 |
3、序列创建之后,可以通过序列对象的 currval 和 nextval 两个“伪列” 分别访问该序列的当前值和下一个值。currval 必须在 nextval 调用之后才能使用。
--创建一个从 1 开始,默认最大值,每次增长 1 的序列,要求 NOCYCLE ,缓存中有 30 个预先分配好的序列号。
create sequence seq1 minvalue 1 start with 1 nomaxvalue increment by 1 nocycle cache 30;
select seq1.nextval from dual;--获取序列下一个值
select seq1.currval from dual;--获取序列当前值,必须在使用 nextval 后有了值以后才能获取当前值
create sequence seq3 ;--实际中这种使用最多,其余全部使用默认值
--为 student 插入数据,主键从 seq3 序列中获取
insert into student values(seq3 .nextval,'李四','男',22,23,sysdate,'雨花区人民中路28号',1002);
5、使用 alter sequence 可以修改序列,修改只影响新产生的值,不影响已产生的值,在修改序列时有如下限制:
| 1. 不能修改序列的初始值。 2. 最小值不能大于当前值。 3. 最大值不能小于当前值。 |
| alter sequence seq1 cache 10; | 修改序列 |
| drop sequence seq2; | 使用 "drop sequence序列名" 命令可以删除一个序列对象,如删除序列 seq2 |
| select * from user_sequences; | --查询当前用户下创建的所有序列 |
| select * from all_sequences t where t.SEQUENCE_OWNER = 'SYS'; | --查询所有用户创建的所以序列,SEQUENCE_OWNER 字段是用户名称(必须大写) |
索引(index )创建、删除、查询
1、索引相当于一本书的目录,能提高检索的速度,如果某一列需要经常作为查询条件,则有必要为其创建索引,能显著提供效率。
2、创建索引语法:create [unique] index index_name on table_name(column_name[,column_name…])
3、索引一旦建立,Oracle 会对其进行自动维护,而且由 Oracle 决定何时使用索引,用户不用在查询语句中指定使用哪个索引。
4、索引被删除或损坏,不会对表产生影响,其影响的只是查询的速度。在删除一个表时,所有基于该表的索引会自动被删除。
5、在定义 PRIMARY KEY 或 UNIQUE 约束后系统自动在相应的列上创建唯一性索引。
| 1. unique:指定索引列上的值必须是唯一的,称为唯一索引,否则就是普通索引。 2. index_name :指定的索引名。 3. tabl_name :指定要为哪个表创建索引。 4. column_name :指定要对哪个列创建索引。(可以对多列创建索引,称为组合索引 ) |
| select * from user_indexes; -- 查询当前登陆用户下的所有索引 distinct_keys:比较一下唯一键的数量和表中的行数,就可以判断索引的选择性。选择性越高,索引返回的数据就越少。 |
| select * from all_indexes; -- 查询所有用户下的所有索引 SELECT T.* FROM dba_indexes t;-- 查询所有用户下的所有索引 |
| -- 查找表中的所有索引列(包括索引名,类型,构成列) select t.*, i.index_type from user_ind_columns t, user_indexes i where t.index_name = i.index_name and t.table_name = i.table_name and t.table_name = 'BAS_PERSON_INFO'; |
| drop index UK_ID_CART_ZZRY_XZ; --删除索引 UK_ID_CART_ZZRY_XZ |
3、Oracle 数据库会为 表的主键 和 包含唯一约束的列自动创建索引。
--准备表
create table person(
pid number(32) primary key,
pname varchar2(16) not null,
paddress varchar2(16) not null
);
--使用 PLSql 语法插入 500万条数据。plsql 是 Oracle 对原生sql的封装,是 oralce 自己独有的
declare
begin
for i in 1..5000000 loop
insert into person values(i,'姓名'||i,'地址'||i);
end loop;
commit;
end;
--在没有使用索引的情况下,查询 panme='姓名4000000' 的用户 。耗时:3-5 秒
select * from person where pname = '姓名4000000';
--实际中建表后就应该设置索引,这里已经有500万条数据后再创建索引花了32秒
create index index_pname on person(pname);--为 pname 列创建索引
--为 pname 列创建索引后再次查询,耗时:0.030 ,可见有没有索引完全是云泥之别
select * from person where pname = '姓名4000000';
--在没有复合索引的情况查询 panme='姓名4000000' 且 paddress='地址4000000' 的用户,耗时:0.032
select * from person where pname = '姓名4000000' and paddress = '地址4000000';
--为 panme 、paddress 创建复合索引后再次查询。耗时:0.25 与没建复合索引区别不是很明显
create index index_pname_paddress on person(pname,paddress);--花了 46秒
select * from person where pname = '姓名4000000' and paddress = '地址3500000';
--经实测发现,pname 建了复合索引之后,select * from person where pname = '姓名4000000'; 速度更慢了Pl/SQL 工具中可以选中查询语句然后按 F5 进行查看优化目标
4、索引的原理底层使用的是平衡二叉树。数据库中索引(Index )的概念与目录的概念非常类似。如果某列出现在查询的条件中
而该列的数据是无序的,查询时只能从第一行开始一行一行的匹配。 创建索引就是对某些特定列中的数据排序,生成独立的索引表。 在某列上创建索引后,如果该列出现在查询条件中,Oracle 会自动的引用该索引,先从索引表中 查询出符合条件记录的 rowid,由于 rowid 是记录的物理地址,因此可以根据 rowid 快速的定位到具体的记录,表中的数据非常多时,引用索引带来的查询效率非常可观。
5、如果表中的某些字段经常被查询并作为查询的条件出现时,就应该考虑为该 列创建索引。有一条基本的准则是:当任何单个查询要检索的行少于或者等于整个表行数的 10%时,索引就非常有用。
6、索引可以提高查询的效率,但是在数据增删改时需要更新索引,因此索引对增删改时会有负面影响。
唯一索引
1、唯一索引和唯一约束一样,约束的列可以为 null,比如 dept_name 列添加了唯一索引,但是多行数据上的 dept_name 为 null,此时是允许的,因为 null 和 null 是不相等的。
2、常规用法:即对某一列或者多列添加唯一索引,即整个表中不允许重复。
CREATE UNIQUE INDEX index_name ON table_name(column_name[,column_name…]);3、高级用法:产品设计时,通常会设计逻辑删除,即 is_deleted 表示是否删除,1是2否,用于保留历史数据备查,或者将来恢复。比如一个人员表中,无论同一个人如何的反复添加与删除,在表里面必须保证有效的(is_deleted=2)数据只有一条。此时上面的常规用法已经难以满足要求,因为此时需要在未删除数据上建立唯一约束,已删除数据不约束。
-- decode(表达式,值1,结果1,[值2,结果2...][,否则]:select 中实现 if else 功能。
-- 注意结果的类型必须相同,值的类型必须相同。
-- 人员信息表添加唯一索引
-- 同一区划(mof_div_code)、单位(agency_code)、年度(fiscal_year)、版本(version)、人员类型(ui_code)下有效身份证(iden_no)只允许有一条
-- per_id 主键
-- is_deleted 是否删除,1是2否,必录项.
-- is_deleted=2时,约束有效数据只允许有一条;否则 is_deleted=1 时 per_id 本身是主键,即已删除数据不约束。
CREATE UNIQUE INDEX uni_indx_bas_person_info ON bas_person_info
(mof_div_code, agency_code, fiscal_year, version, ui_code, iden_no, DECODE(TO_CHAR(is_deleted), '2', '2', per_id));-- biz_key 允许为null,所以需要加 nvl 处理,当它为null时,使用主键.
CREATE UNIQUE INDEX "支出标准业务唯一标识(BIZ_KEY)应该唯一标识一条记录。" ON BAS_EXP_CRI (mof_div_code, nvl(BIZ_KEY,exp_cri_id), DECODE(TO_CHAR(is_deleted), '2', '2', exp_cri_id));
基于函数的索引
1、上一节唯一索引中使用的 decode 是 Oracle 自带的函数,这种用法就是'基于函数的索引',可以满足在复杂的业务场景中使用。除了使用 Oracle 自带的函数,也可以自己创建函数创建索引。
2、下面自定义含义来实现 decode 函数类似的功能。
--准备表
create table DEPT(
DEPTNO NUMBER(2) not null constraint DEPT_PK primary key,
DNAME VARCHAR2(14),
LOC VARCHAR2(13),
DELETED NUMBER(1) not null check ( DELETED in (1, 2) )
);
--需求:
--1、每个地区的部门名称(dname)必须唯一,即有效数据(deleted=2)只能有1条;
--2、其中波士顿(loc=BOSTON)地区允许名称(dname)随意重复;
/**
* 创建函数
* 参数 v_dept_no:部门主键ID,表中有非空约束,主键永不重复;
* 参数 v_dept_loc:位置,可为空;
* 参数 v_deleted:是否删除(1是2否),表中有非空约束;
*/
CREATE OR REPLACE FUNCTION GET_DEPT_UNI01(v_dept_no in Dept.DEPTNO%type,
v_dept_loc in Dept.LOC%type,
v_deleted in Dept.DELETED%type)
--必须添加关键字'deterministic-不可逆转的',否则创建基于函数的索引时会报错:ORA-30553: The function is not deterministic
--如果返回的是随机值或者序列,删除(delete)操作会报错未找到索引键:ORA-08102: index key not found
return varchar2 deterministic is
begin
if v_dept_loc is not null and upper(trim(v_dept_loc)) = 'BOSTON' then
--是波士顿地区时,允许随意重复;主键永不重复,所以返回主键即可;
--防止类型不一致,统一转成字符串再返回.
return to_char(v_dept_no);
else
if v_deleted = 1 then
--如果是删除数据,则同样允许有多条,因为同一个部门可以反复新增删除;
return to_char(v_dept_no);
else
--有效数据只允许有1条,所以原样返回2即可。
return to_char(v_deleted);
end if;
end if;
end;
/
--创建基于函数的索引
CREATE UNIQUE INDEX uni_dept1 ON dept (DNAME, GET_DEPT_UNI01(DEPTNO, LOC, DELETED));
--等价于 decode
CREATE UNIQUE INDEX uni_dept2 ON dept (DNAME, decode(upper(trim(LOC)), 'BOSTON', DEPTNO, decode(DELETED, 1, DEPTNO, 2)));游标(cursor ) 与 fetch into
1、游标:用于操作查询的结果集,类似 JDBC 的 ResultSet。
2、select . into . 查询并赋值数据只能对单个结果进行处理,如果 select 查询的结果是多条,则可以借助游标进行遍历。
普通游标语法:cursor 游标名[(参数名 参数类型)] is 查询结果集
游标开发步骤:
| 1)声明游标 —— cursor 游标名(参数) is 查询结果集 2)打开游标 —— open 游标名 3)从游标中读取数据 —— fetch 游标名 into 变量 游标名%isopen :判断游标是否打开 游标名%rowcount :当前为止 fetch 得到的数据行总条数 游标名%found :表示找到数据 游标名%notfound :表示没有找到数据 4)关闭游标 —— close 游标名 |
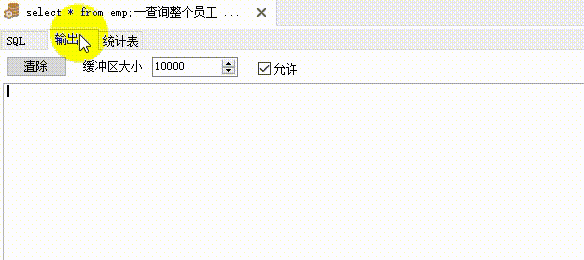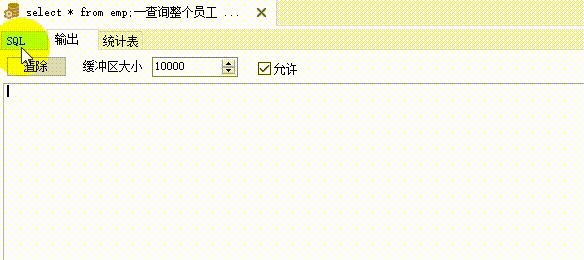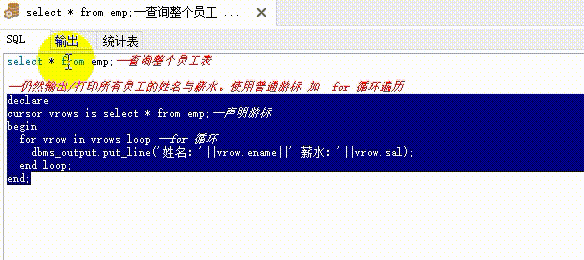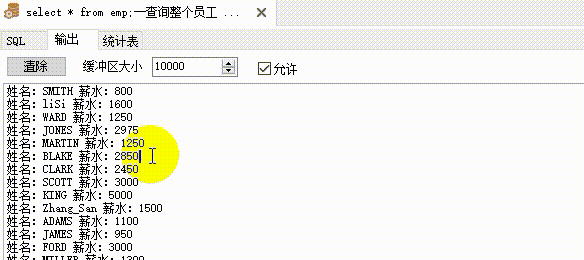
普通游标示例1:最基本的用法
--输出/打印所有员工的姓名与薪水。
--declare - begin - end 为 PLSQL 固定结构。declare 中定义变量,begin 中执行业务/逻辑操作,end 表示结束
declare
cursor vrows is select * from emp;--1、声明游标
vrow emp%rowtype;--2、声明变量 vrow,变量类型为 emp 中的一行
begin
open vrows; --3、打开游标
loop--4、使用 loop 循环遍历游标
fetch vrows into vrow;--5、遍历游标 v rows 的每一行结果给(into)遍历 vrow
exit when vrows%notfound;--6、当游标 vrows 没有再读取到值时,则退出循环
--dbms_output.put_line():plsql 的输出语句
dbms_output.put_line('姓名:'||vrow.ename || ' 工资:'|| vrow.sal);
end loop;
close vrows; -- 结束时必须关闭游标
end;
普通游标示例2:定义带参数的游标
--输出/打印指定部门(deptno)下员工的姓名与薪水
declare
--1、声明带参数的游标,参数名为 dno,参数类型为 number
cursor vrows(dno number) is select * from emp where deptno = dno;
vrow emp%rowtype;--2、定义变量 vrow,为 emp 行类型
begin
open vrows(10);--3、打开游标。查询 10 号部门
loop --4、遍历游标,读取数据进行处理
fetch vrows into vrow;
if vrows%notfound then --5、当游标中没有再读取到数据时,退出循环
exit;
end if;
dbms_output.put_line('姓名:'|| vrow.ename || ' 薪水:'|| vrow.sal);
end loop;
close vrows; --6、必须关闭游标
end;--结尾必须要有分号系统引用游标:与上面的普通游标写法上就是第一、二步稍有不同,使用步骤:
| 1)声明游标:游标名 sys_refcursor 2)打开游标:open 游标名 for 查询结果集 3)从游标中读取数据 —— fetch 游标名 into 变量 游标名%isopen :判断游标是否打开 游标名%rowcount :当前为止 fetch 得到的数据行总条数 游标名%found :表示找到数据 游标名%notfound :表示没有找到数据 4)关闭游标 —— close 游标名 |
引用游标示例1:
--仍然输出/打印所有员工的姓名与薪水
declare
vrows sys_refcursor;--1、声明系统引用游标
vrow emp%rowtype;--2、声明接收变量
begin
open vrows for select * from emp;--3、打开游标
loop--4、遍历游标
fetch vrows into vrow;
exit when vrows%notfound; -- 5、游标读取不到值时,退出循环
dbms_output.put_line('姓名:'|| vrow.ename || ' 薪水:'|| vrow.sal);
end loop;
close vrows;-- 6、必须关闭游标
end;for 循环遍历游标(推荐方式):for 方式遍历游标时,不需要额外声明每次遍历接收的变量,也不再需要手动开/关游标,for 循环会自动进行处理(PL/sql 流程控制)。
--给所有员工加薪,总裁加 1000,经理加600,其它人加 400
declare
cursor vrows is select * from emp;--1、声明游标(使用普通游标)
begin
for vrow in vrows loop-- 2、for 循环遍历游标,无需手动开关游标
-- 3、根据不同的职位(job)加薪,使用 PLSQL 的 if else 判断语法
if vrow.job = 'PRESIDENT' then
update emp set sal = sal + 1000 where empno = vrow.empno;
elsif vrow.job = 'MANAGER' then
update emp set sal = sal + 600 where empno = vrow.empno;
else
update emp set sal = sal + 400 where empno = vrow.empno;
end if;
end loop;
commit;--4、提交事务
end;
多重循环
游标嵌套遍历示例:
| declare |
多重循环示例:https://blog.csdn.net/wangmx1993328/article/details/102514681#多重循环。
引用游标读取存储过程返回的结果集
1、存储过程如果返回的只是单个结果,如返回整数 3、字符串 ok 等,则使用普通的变量作为输出参数即可接收。当存储过程返回的结果有多条时,比如分页查询,区间查询,in 查询等等,此时可以借助引用游标来进行取值(普通游标不行)。
--创建存储过程,用于分页查询
--传入参数:pageNo 查询的页码,pageSize 每页的条数;输出参数:vrows 使用一个引用游标用于接收多条结果集。普通游标无法做到,只能使用引用游标
create or replace procedure pro_query_emp_limit(pageNo in number,pageSize in number,vrows out sys_refcursor) is
begin
--存储过程中只进行打开游标,将 select 查询出的所有数据放置到 vrows 游标中,让调用着进行获取
open vrows for select t.empno,t.ename,t.job,t.mgr,t.hiredate,t.sal,t.comm,t.deptno from (select rownum r,t1.* from emp t1) t
where t.r between ((pageNo-1) * pageSize+1) and pageNo * pageSize;
end;
--使用引用游标读取上面的存储过程返回的值
declare
vrows sys_refcursor ;--声明引用游标
vrow emp%rowtype; --定义变量接收遍历到的每一行数据
begin
pro_query_emp_limit(4,3,vrows);--调用存储过程
loop
fetch vrows into vrow; -- fetch into 获取游标的值
exit when vrows%notfound; -- 如果没有获取到值,则退出循环
dbms_output.put_line('姓名:'|| vrow.ename || ' 薪水:'|| vrow.sal);
end loop;
close vrows;--关闭游标
end;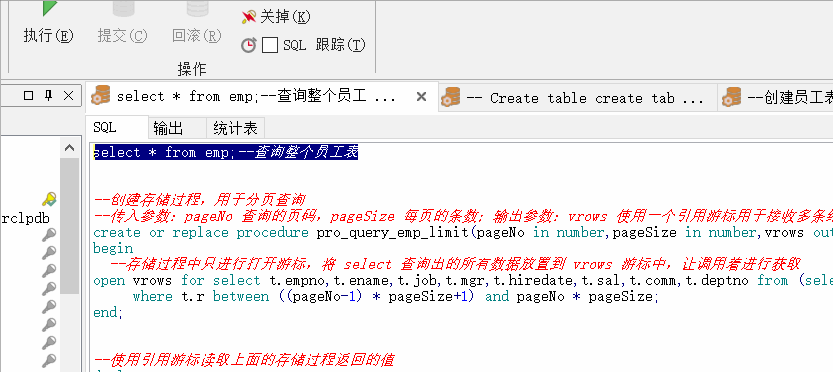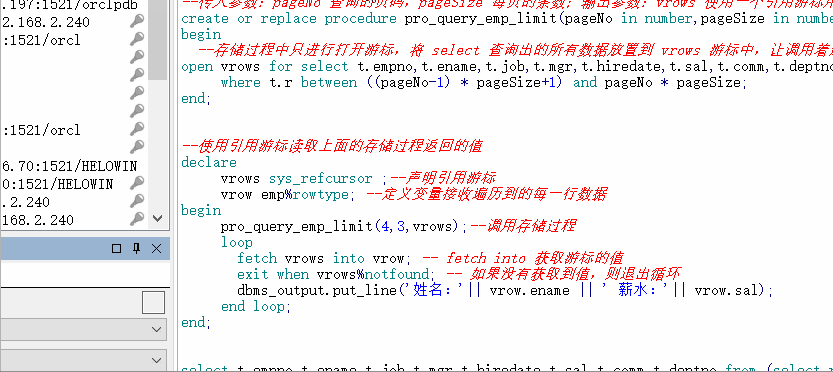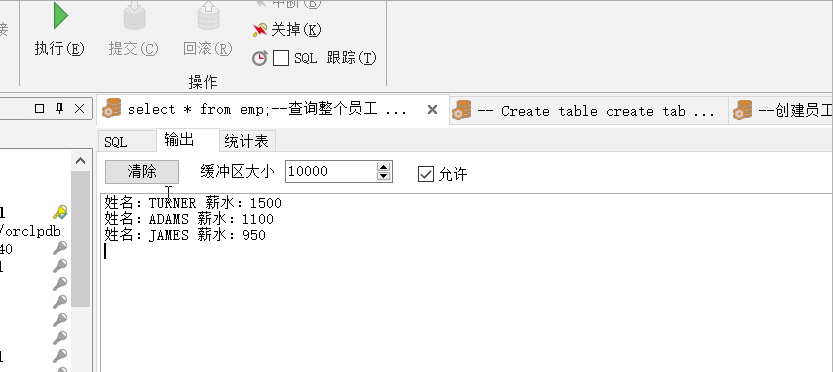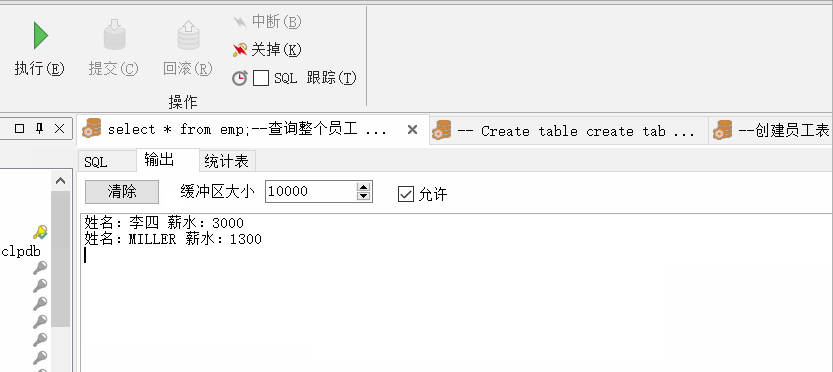
在 JDBC 代码中调用存储过程时也是如此。
触发器(trigger创建、删除、查询)
1、触发器是一个与表关联的、存储的 PL/SQL 程序,当用户执行了 insert、update、delete 操作之前/后,Oracle 自动地执行触发器中定义的语句序列。
2、触发器类型:
| 语句级触发器 | 在SQL(比如insert、update、delete等)语句操作之前或者之后触发一次,不管这条语句影响了多少行,无法获取具体行的数据。 |
| 行级触发器 | 针对SQL语句影响的每一行进行触发,可以使用 :old 和 :new 伪记录变量获取数据前后的值, insert 操作(无论before还是after)可以用 :new 获取插入的新值,而 :old 获取的值恒为 null. delete 操作(无论before还是after)可以用 :old 获取被删除的旧值,而 :new 获取的值恒为 null. update 操作(无论before还是after)可以用 :new、:old 可以获取到修改前后的值。 |
3、触发器创建语法:
| create [or replace] trigger 触发器名 before/after insert/update/delete [of 列名] on 表名 --before:表示在 insert/update/delete 操作之前触发 --[of 列名]:表示只对指定的列进行触发,默认是所有列。 --[when (条件)]:行级触发器时,表示对指定条件的数据行进行触发。 |
| drop trigger 触发器名 | 删除触发器 |
| --注意:如果触发器名称含有特殊字符,则必须使用双引号包裹,否则报错 drop trigger "BIN$wsVXhP2Omf7gU90eEwpAUg==$0"; | |
| alter trigger 触发器名 enable | disable; | 禁用与启用触发器,如:alter trigger trig_dept_del_backup disable; |
| alter table 表名 disable | enable all triggers; | 禁用与启用指定表上的所有触发器,不会影响其它表 |
| select * from all_triggers; | 查询所有用户创建好的所有触发器 |
| select * from user_triggers; | 查看当前用户下的所有触发器 |
| 查询触发器(TRIGGER)、存储过程(PROCEDURE)、函数(FUNCTION),类型(Type) 等对象的源代码。 SELECT * FROM user_source T where t.NAME='xxx' order by t.LINE; | |
触发器示例1:删除部门(dept )时,使用行级触发器级联删除关联的员工数据。
--删除部门 dept 时,使用行级触发器级联删除关联的员工的数据。
--因为需要获取删除的部门id,所以需要使用行级触发器,因为需要在删除部门前先删除员工,所以使用 before
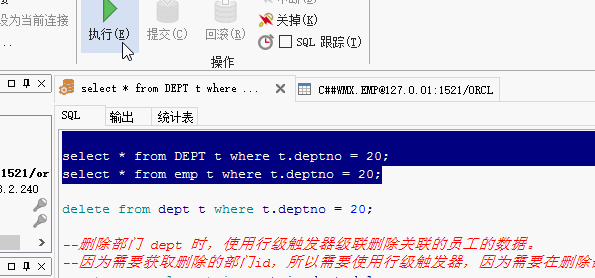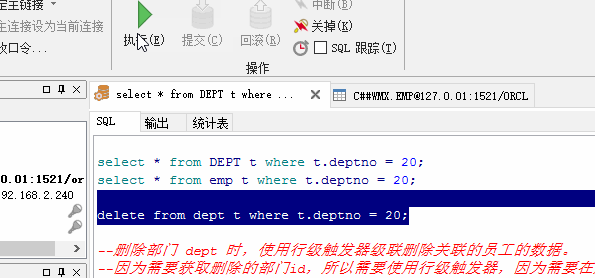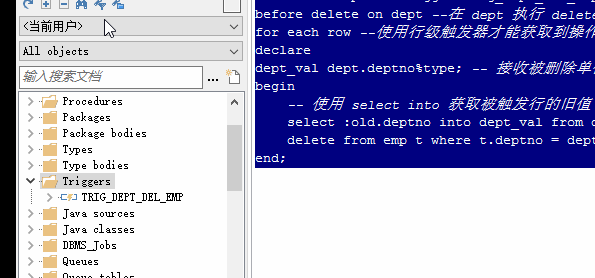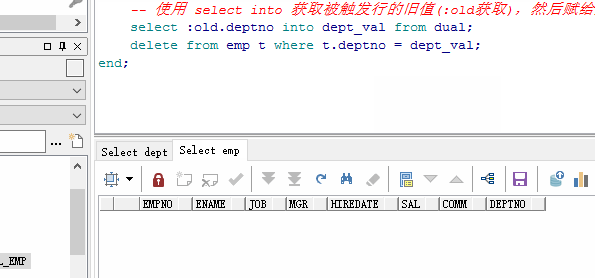
create or replace trigger trig_dept_del_emp
before delete on dept --在 dept 执行 delete 操作前触发
for each row --使用行级触发器才能获取到操作行的值
declare
dept_val dept.deptno%type; -- 接收被删除单位 id
begin
-- 使用 select into 获取被触发行的旧值(:old获取),然后赋给变量 dept_val
select :old.deptno into dept_val from dual;
delete from emp t where t.deptno = dept_val;
end;
触发器示例2:删除部门数据时,使用行级触发器将被删除的数据自动备份到备份表中
--为 dept 部门表创建备份表
create table dept_backup as select * from dept where 1=2;
--创建触发器:删除部门 dept 数据时,将被删除的数据备份到 dept_backup 表中
create or replace trigger trig_dept_del_backup
before delete on dept -- 1、在 dept 执行 delete 操作前触发
for each row -- 2、使用行级触发器才能获取到操作行的值
declare
dept_row dept%rowtype; -- 3、定义参数,类型为 dept 行类型,接收行参数
begin
-- 4、使用 select into 获取被触发行的旧值(:old获取),然后赋给变量 dept_row
select :old.deptno,:old.dname,:old.loc into dept_row.deptno,dept_row.dname,dept_row.loc from dual;
-- 5、往备份表插入数据,值从 dept_row 行变量中获取.
insert into dept_backup values(dept_row.deptno,dept_row.dname,dept_row.loc);
end;
注意事项:上面的触发器中第5步不能使用此种方式:insert into dept_backup select * from dept t where t.deptno = :old.deptno;
否则触发器被触发时会报错如下,即无法在触发器中操作被触发的表中的数据,即使是查询也不行。

触发器示例3:语句级触发器。不满足要求时,主动抛出异常,让脚本无法再继续执行。
--语句级触发器:
--a)工作日(星期六、星期天)不能操作 emp 表中的员工数据
--b)下班时间(9-18以外的时间),不能操作 emp 表中的员工数据
create or replace trigger trig_delete_emp_check
-- 在 demp 执行 增删改 操作前触发
before insert or update or delete on emp
declare
begin
if to_char(sysdate, 'day') in ('星期六', '星期日') or
to_number(to_char(sysdate, 'hh24')) not between 9 and 18 then
--抛出异常,比如 java 程序调用时抛出此异常,则 java 程序中就能看到此异常信息.
raise_application_error(-20001, '禁止在非工作时间操作员工数据');
end if;
end;触发器示例4:当往 ele_agency 表新增或者更新数据时,如果 level_num 字段值为 null,则使用 level_no 字段的值赋给 level_num。
-- 创建触发器,当往 ele_agency 表新增数据时
-- 如果 level_num 字段的值为 null,则使用 level_no 字段的值赋给 level_num
-- 如果 isdept 字段的值为 null ,则默认设置为 1
create or replace trigger trig_ele_agency_before_insert
before insert or update on ele_agency
for each row
declare
begin
if :new.level_num is null then
dbms_output.put_line('ele_agency 插入新数据,其中 level_num 为 null,将 level_no 的值【' || :new.level_no || '】赋给 level_num');
:new.level_num := :new.level_no;
end if;
if :new.isdept is null then
dbms_output.put_line('ele_agency 插入新数据,其中 isdept 为 null,强制将其值设置为 1!');
:new.isdept := 1;
end if;
end;触发器示例5:当往 dept 表中插入(insert)数据后(after),同时将数据备份到 dept_backup 表中:
--为 dept 部门表创建备份表
create table dept_backup as select * from dept where 1=2;
-- 创建触发器:当往 dept 表中插入数据后,同时将数据备份到 dept_backup 表中
create or replace trigger trig_dept_add_log
after insert on dept
for each row
declare
begin
insert into dept_backup(deptno,dname,loc) values(:new.deptno,:new.dname,:new.loc);
end;
序列+触发器实现主键自增
--模拟 mysql 中主键 id 的自增属性 auto_increment
--Oralce 中可以使用 序列 sequence 结合 触发器 trigger 达到同样的效果
--先建一张表
create table person2 (
pid number(32) primary key,
pname varchar2(16)
);
--创建一个序列。默认从1开始,每次递增1,没有最大值
create sequence sequ_person2_id;
--创建触发器
create or replace trigger trig_person2_add_pid
before insert on person2
for each row
declare
begin
--正式插入前修改新记录的 pid 字段值
--两种赋值方式都可以
--select sequ_person2_id.nextval into :new.pid from dual;
:new.pid := sequ_person2_id.nextval;
end;
--插入用户
--插入前触发器会自动通过序列修改 pid 的 null 值为具体的数字
insert into person2 values(null,'华安');
--此时自己设置 pid 也是无效的
insert into person2 values(2,'华安');
select * from person2;
数据库事务、提交、回滚
1、事务特性:
| 1)原子性( Atomicity):原子意为最小的粒子,或者说不能再分的事物。数据库事务的不可再分的原则即为原子性,要么全部成功,要么全部无效。 2)一致性( Consistency):指数据的规则在事务前/后应保持一致。 3)隔离性( Isolation):简单来说是某个事务的操作对其他事务不可见 4)持久性( Durability):当事务完成后,其影响应该保留下来,不能撤消。 |
2、Oracle 中事物默认是开启的,即执行任意 dml(数据库操纵语句,如 Insert、update、delete等),事物默认是打开的.
3、事物常见操作有:
| 1)提交、回滚:commit、rollback 2)设置保存点:savepoint 保存点 3)回滚到保存点:rollback to 保存点 |
4、事务可以显式的提交,也可以隐式提交(即自动提交事务):
| 显式提交:commit 隐式提交:遇到 DDL(数据定义语言),如 create 、alter 、drop 命令等会自动提交事务;遇到 DCL (数据控制语言),如 grant (授权)命令、 revoke (撤销)命令等。以及关闭会话,断开连接时也会自动提交。 |

PL/Sql 执行 DML 语句
https://wangmaoxiong.blog.csdn.net/article/details/102514681















 5468
5468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











