







简介
Ambari作为Apache的顶级项目,是一个基于Web的工具,主要用来创建、管理、监控Hadoop集群。
HDP(Hortonworks Data Platform)是Hortonworks开源的数据平台,几乎包含了Hadoop生态系统中的所有项目,如HDFS、MapReduce、Hive、HBase、Pig、Oozie等等。
本文总结Ambari的基本原理,并在本地安装HDP Hadoop集群。
原理
Ambari采用的是Client/Server模式(C/S模式)。由一个Ambari-server和多个Ambari-agent组成。
Ambari-server(Ambari服务节点):向agent发送指令
Ambari-agent(Ambari代理节点):接收server的指令并执行操作;向server发送心跳汇报所在节点状态等。
注:
1、Ambari-agent不需要手动安装,在安装Ambari-server后,可在WebUI界面配置安装。
2、Ambari-server需要在root用户下安装、配置、启动,并且Ambari-server需要能免密登录到其他节点。
安装HDP Hadoop集群
1、环境准备
(1)节点规划
| HOST | Ambari角色 |
|---|---|
| node1 | ambari-agent |
| node2 | ambari-agent |
| node3 | ambari-agent |
| node4 | ambari-agent 和ambari-server |
注:通过WebUI来安装Hadoop、Spark时,ambari会自动分配,因此,这里可先不指定。
(2)配置HOST映射
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.222.101 node1
192.168.222.102 node2
192.168.222.103 node3
192.168.222.104 node4
(3)关闭防火墙
临时生效:service iptables stop
service iptables status
永久生效:chkconfig iptables off
chkconfig --list | grep iptables (2 3 4 5为off即可)
(4)时间同步
配置系统时间、硬件时间,自动和时间服务器同步
yum –y install ntp
临时生效:service ntpd start
ntpdate -u cn.pool.ntp.org
永久生效:chkconfig ntpd on
chkconfig --list | grep ntpd (2 3 4 5为on即可)
硬件时间和系统时间同步:clock -w
配置自动同步:/etc/crontab写入 */1 * * * * root ntpdate -u cn.pool.ntp.org >> /dev/null 2>&1
(5)安装JDK
rpm -ivh jdk-8u11-linux-x64.rpm
/etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_11
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
(6)配置SSH root互相免密
如在node1节点
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node3
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node4
注:这里node4既是ambari-server节点,也是ambari-agent节点,因此,node4和node4之间也需要配置公钥免密。
2、Ambari-server安装
(1)、下载Ambari yum源配置文件repo
[root@node4 ~]# wget -nv http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.6.1.0/ambari.repo -O /etc/yum.repos.d/ambari
.repo
(2)、安装Ambari-server
[root@node4 ~]# yum install ambari-server
注:安装的时候也会默认安装PostgreSQL。
(3)、配置Ambari-server
[root@node4 ~]# ambari-server setup
Checking JDK... 选择[3] Custom JDK 自定义JDK,然后输入本机JDK HOME路径
(4)、启动Ambari-server
[root@node4 ~]# ambari-server start
(5)、访问Ambari WebUI
http://node4:8080/#/login
3、安装HDP Hadoop集群
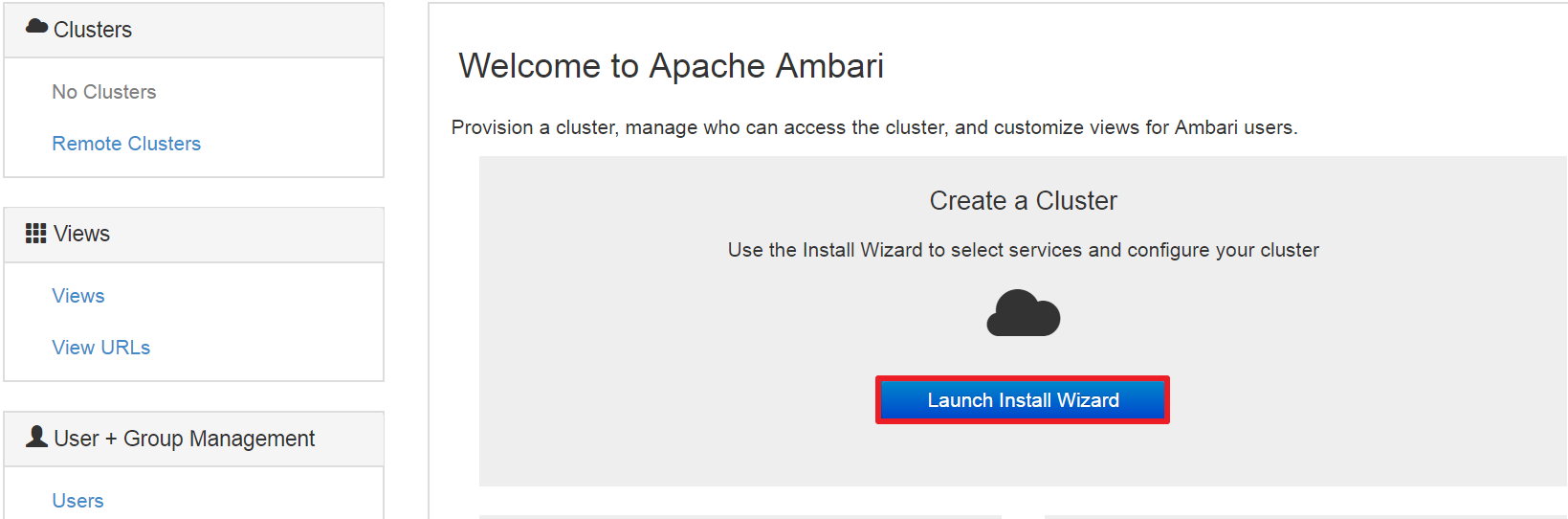
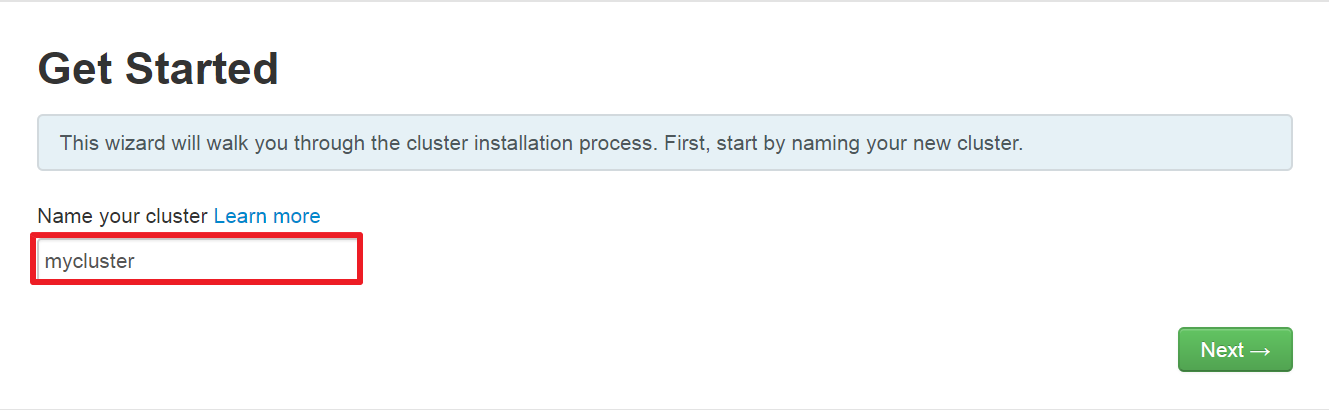
(1)、登录Ambari WebUI设置集群名称
(2)、选择版本和仓库
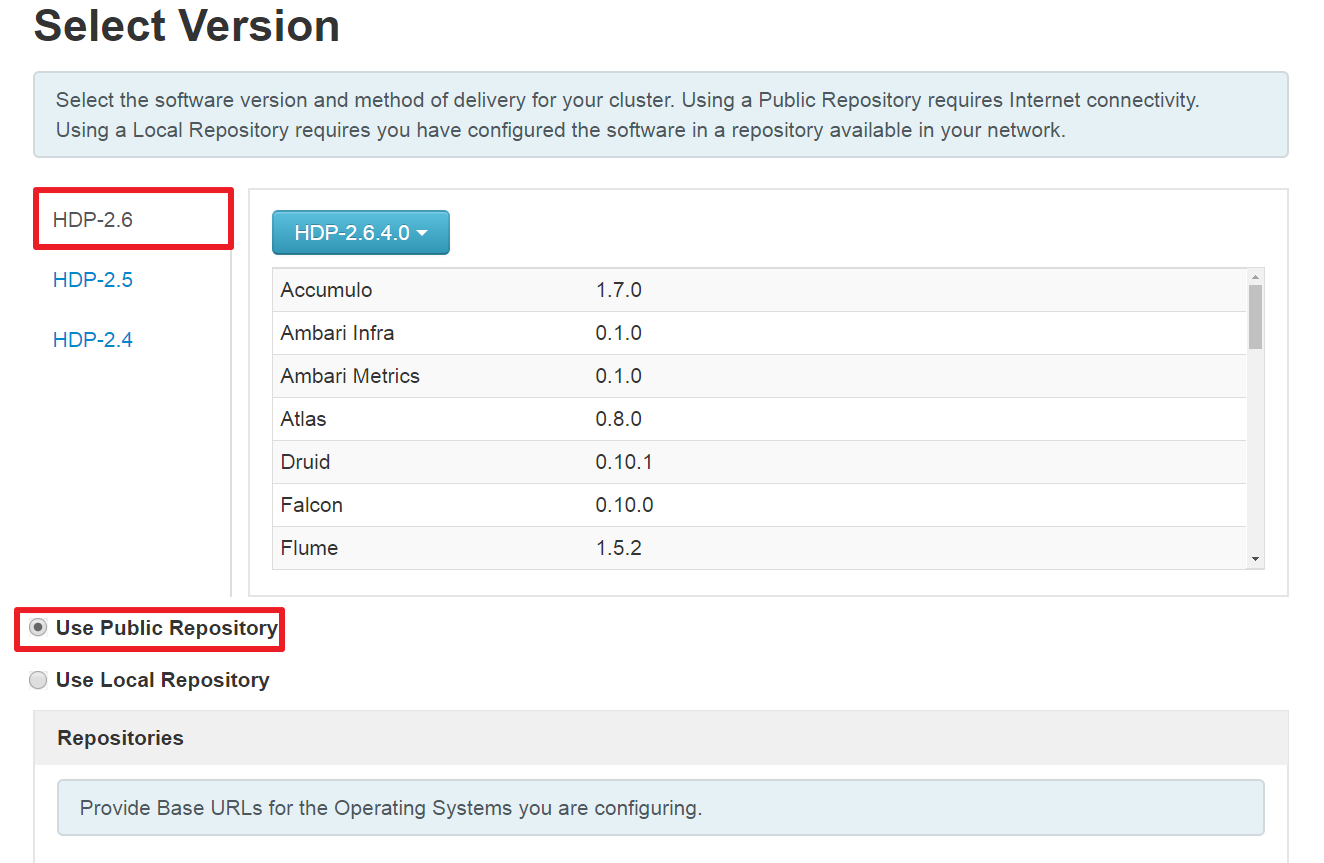
注:在这里可以选择要安装的HDP版本,同时能看到对应的HDFS、YARN、Spark、Kafka、Storm、Hive、HBase等版本信息。这里选择HDP 2.6.4版本,由于没有配置HDP本地仓库,选择公共仓库。
(3)、设置Ambari-agent HOST和Ambari-server SSH私钥文件
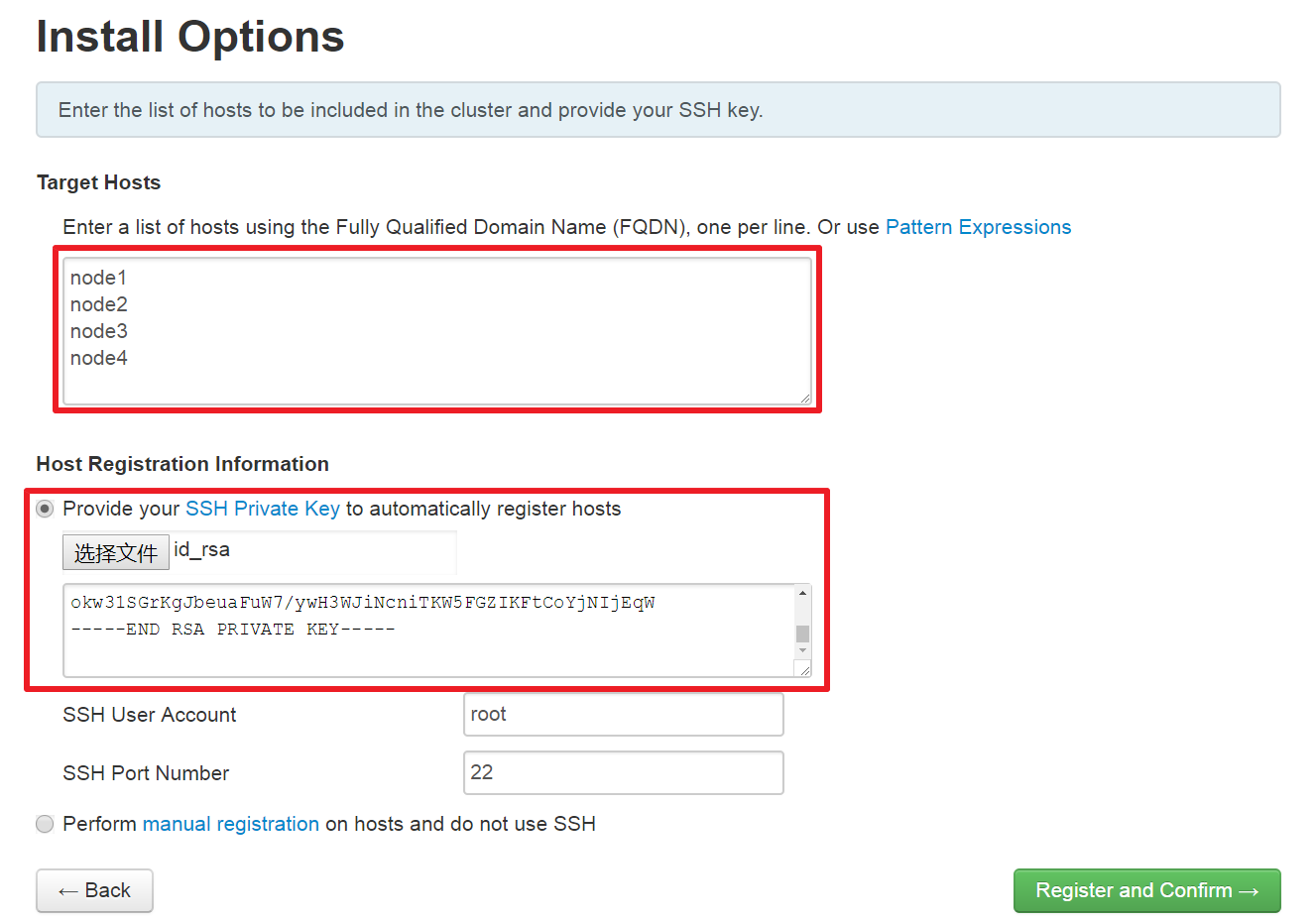
注:这里node4既是server节点也是agent节点。Ambari-server SSH私钥文件默认位置:Ambari-server节点 /root/.ssh/id_rsa
(4)、安装Ambari-agent
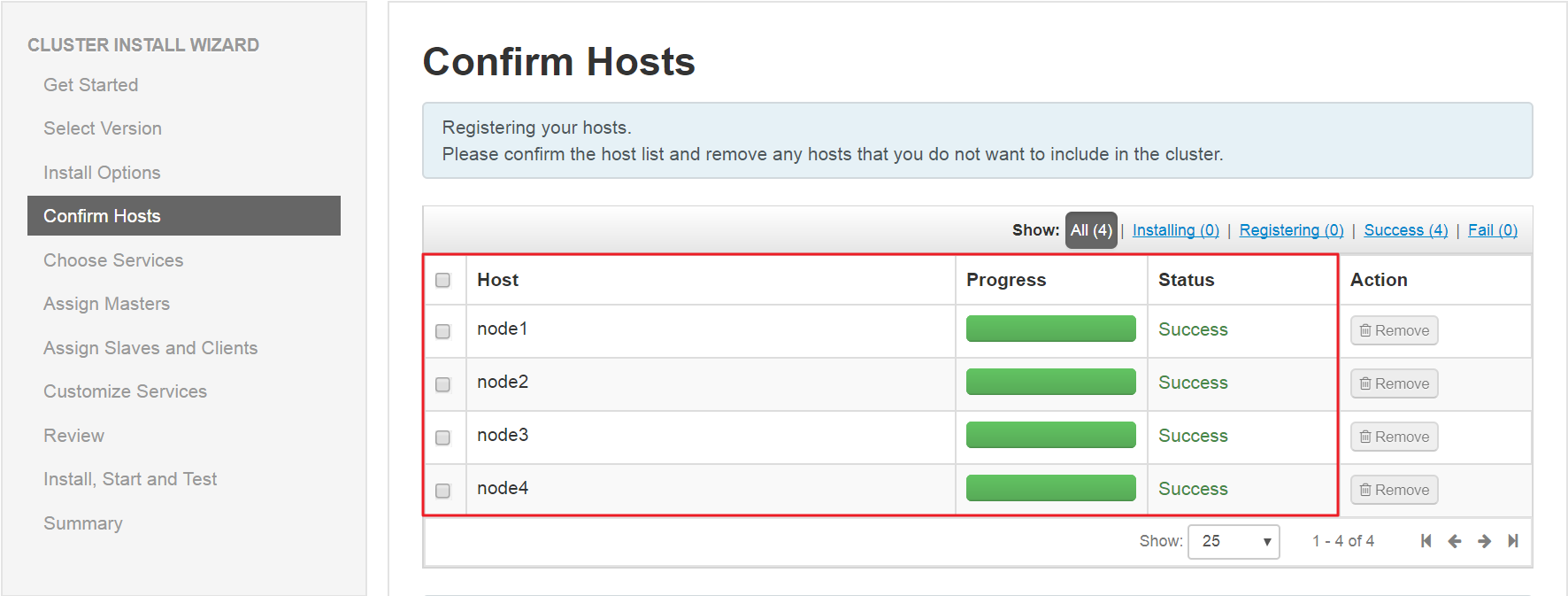
Ambari-agent安装需注意
某节点Agent安装失败,可单独在此节点手动安装agent并启动,如下:
yum install ambari-agent
vi /etc/ambari-agent/conf/ambari-agent.ini
[server]
hostname=node4
url_port=8440
secured_url_port=8441
ambari-agent start
(5)、选择要安装的组件
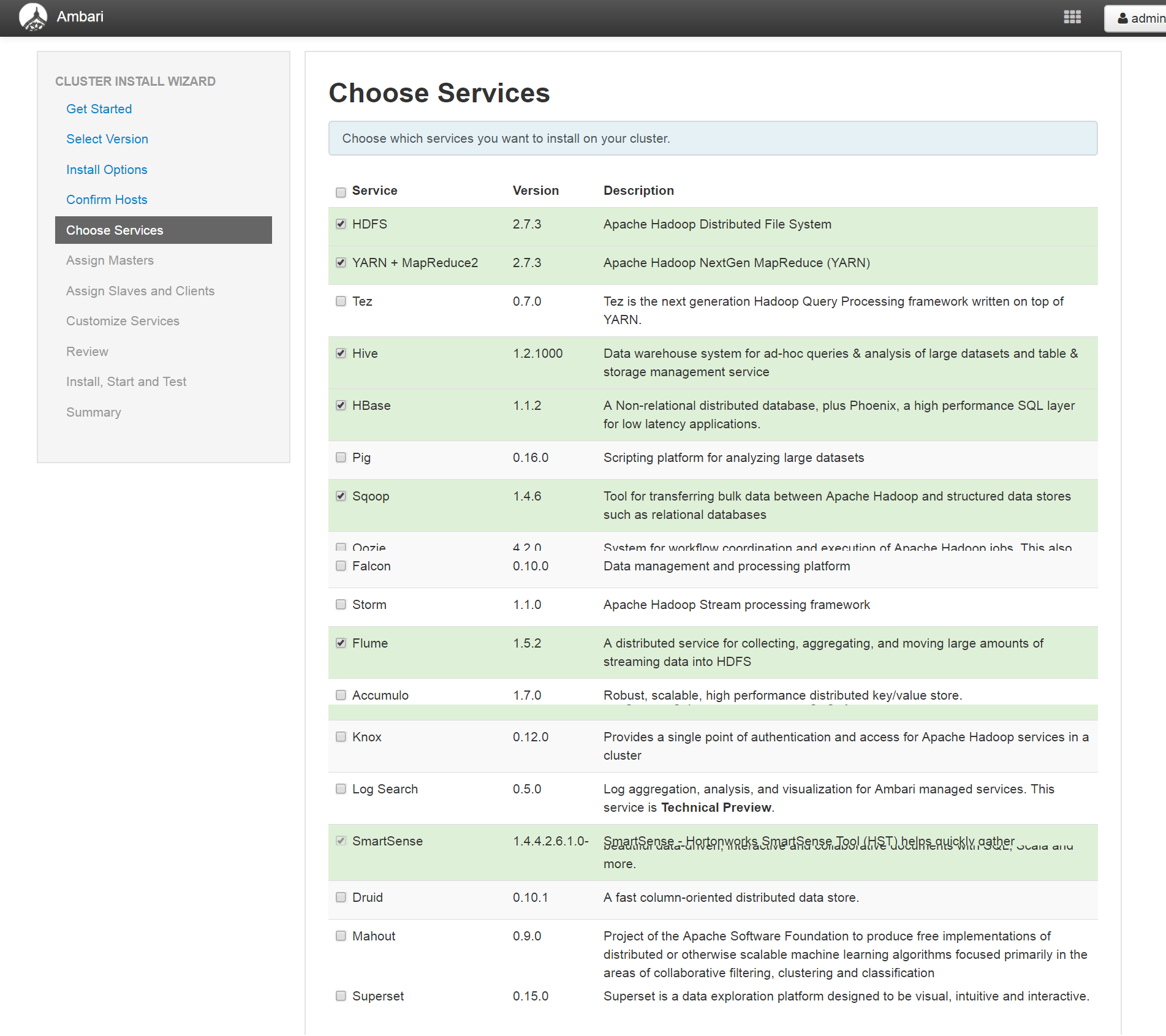
(6)、指定Hadoop组件Master节点
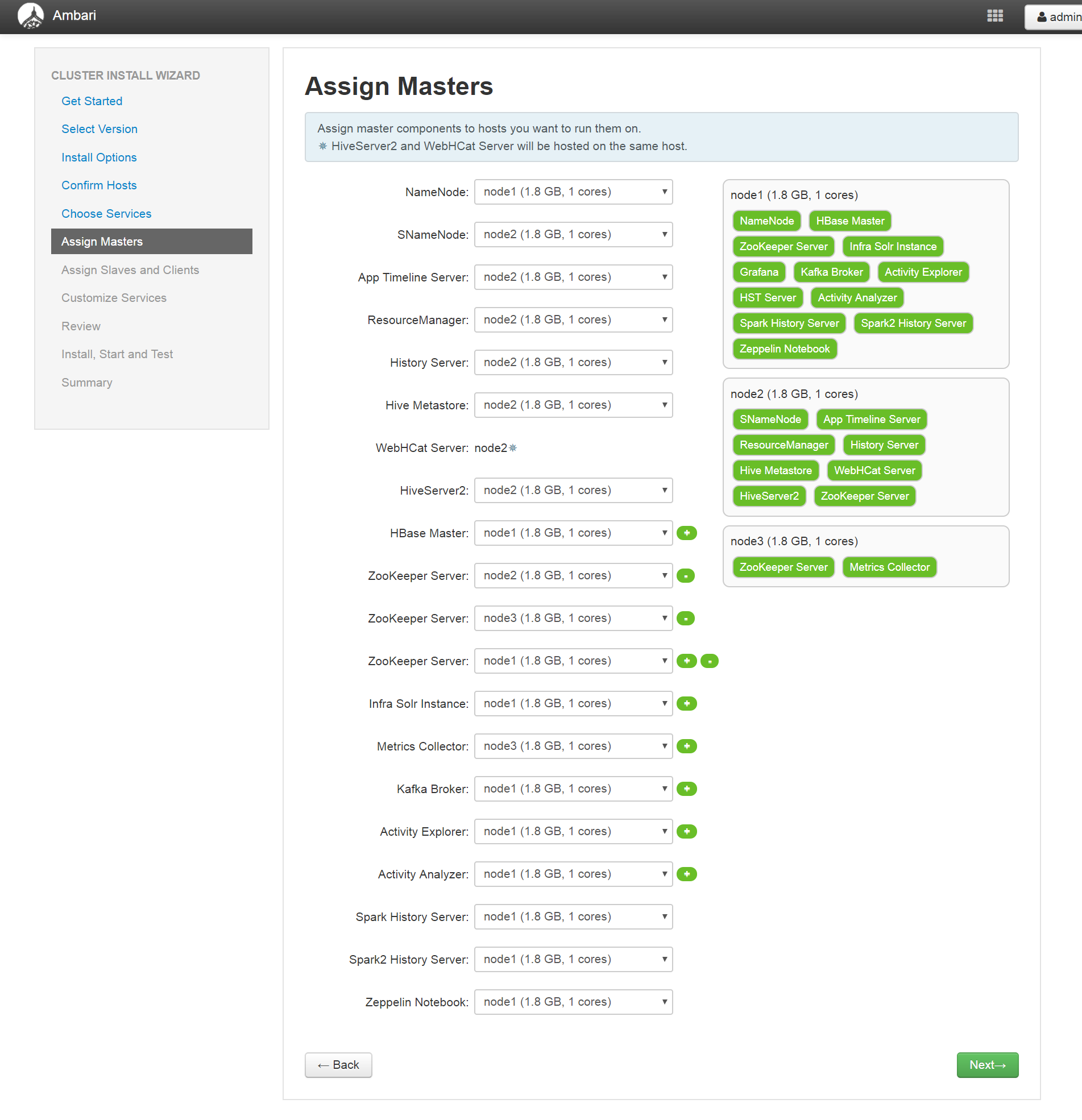
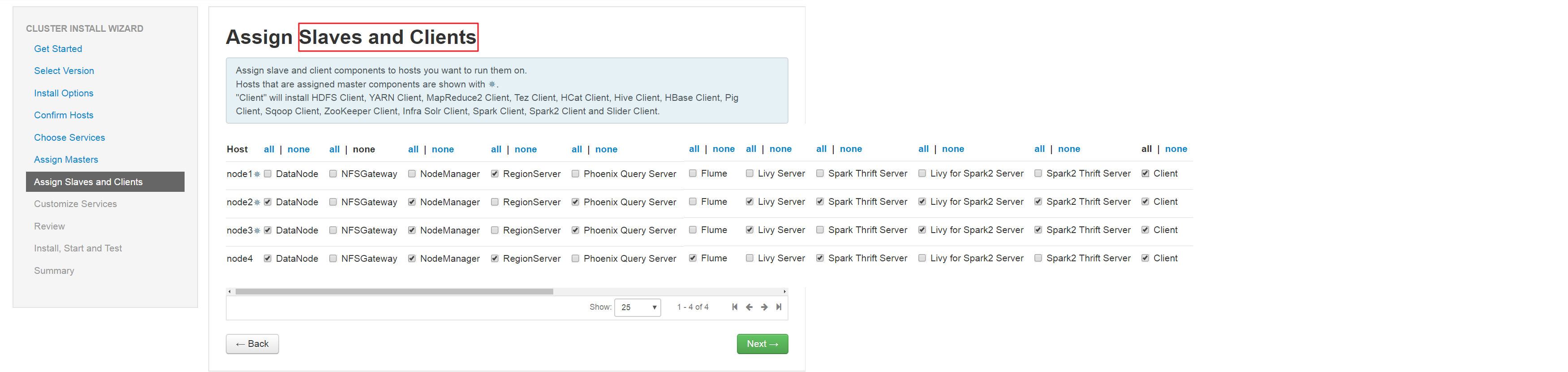
(7)、指定Hadoop组件Slave节点和Client节点
(8)、自定义配置
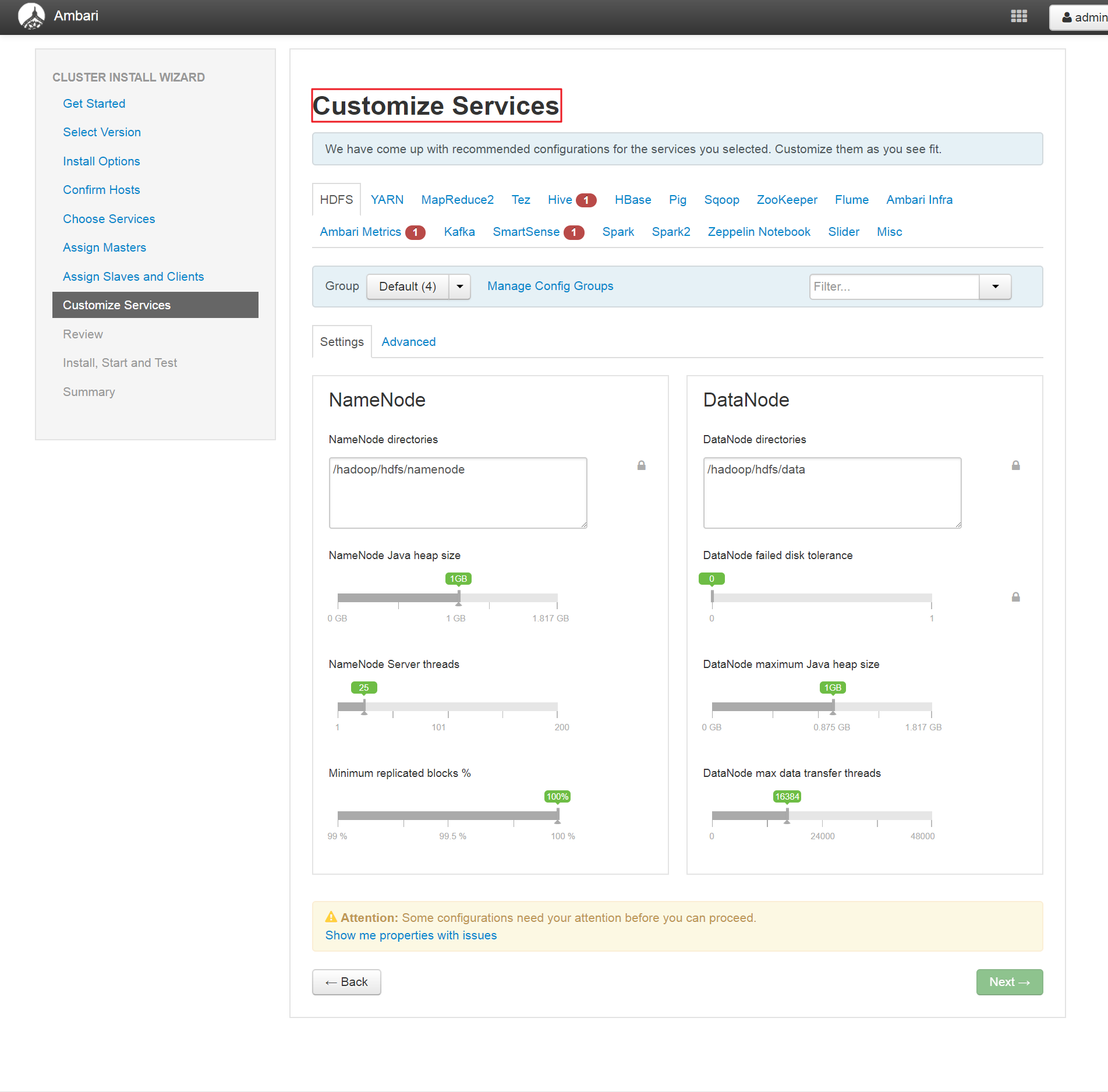
注:这里会设置Hive MetaStore Mysql等的密码,按提示操作即可。
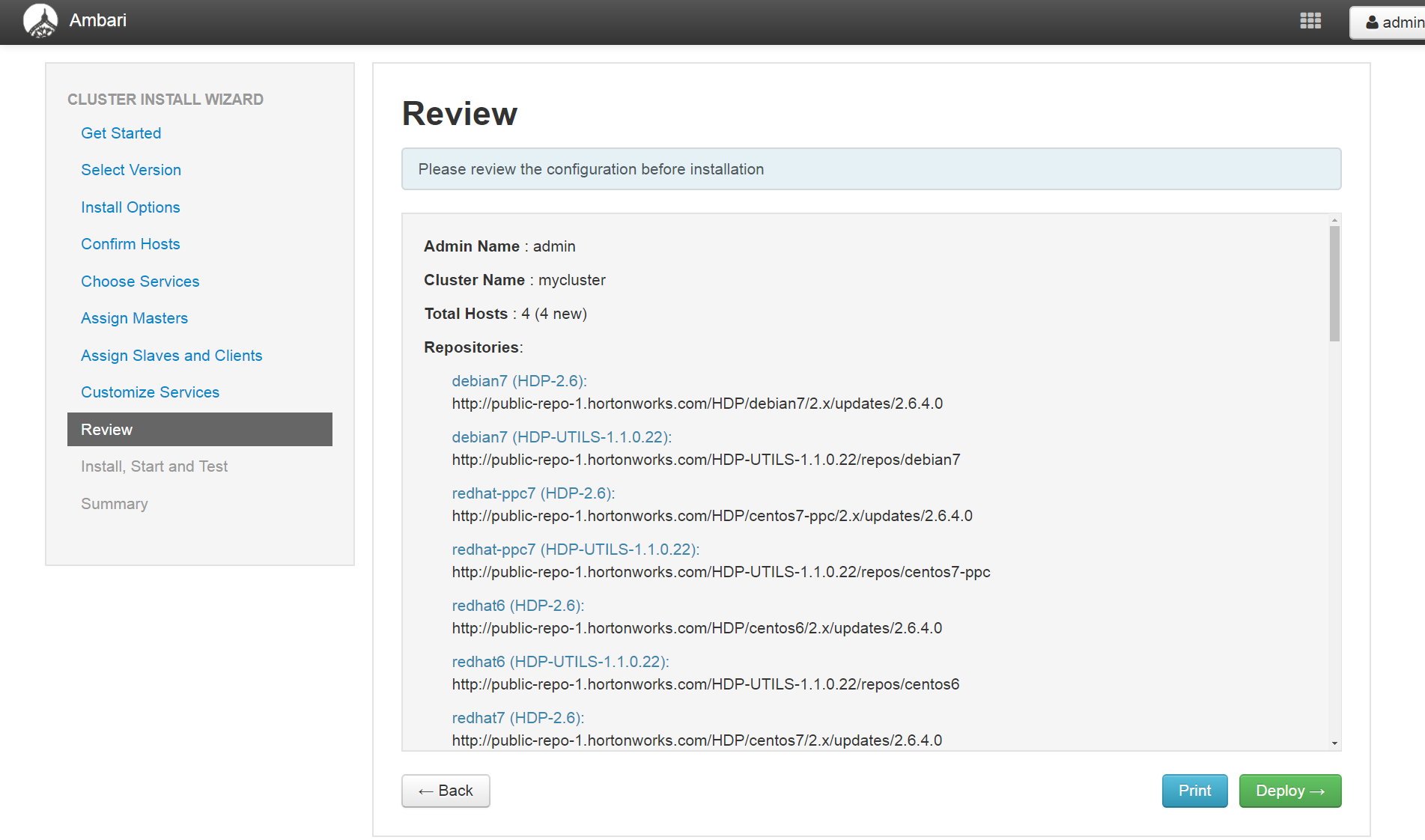
(9)、确认仓库
(10)、安装启动Hadoop组件
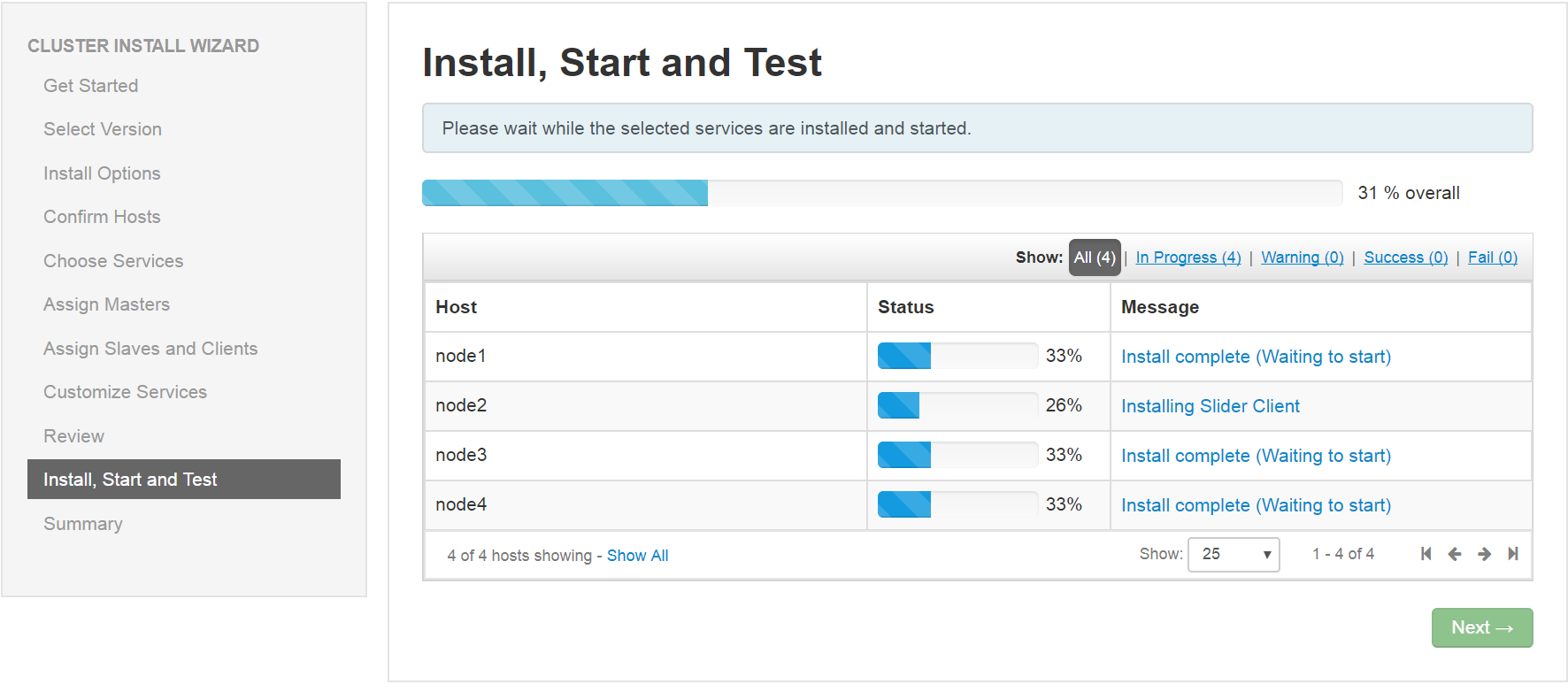
Hadoop组件安装需注意:
A、可以配置本地仓库安装。
B、默认使用公共仓库安装,主要会因为网络等因素导致安装不成功。如在node2节点安装slider-client报No more mirrors to try错误,解决方法如下:
在node2节点yum clean all && yum makecache 然后重新安装
C、类似错误Cannot match package for regexp name livy2_${stack_version} 可尝试如下解决方式:
yum list installed |grep livy2_*
yum remove livy2_*
然后在Ambari WebUI 上Retry
D、安装好了之后,会自动启动所有服务,但有些服务启动不起来,不用管,稍后在Ambari 监控页面手动启动即可。
E、网络不行,首次安装就不要安装太多组件,可以去除不必须的组件如Zeppelin等,以后用到的时候再安装。
(11)、Ambari Dashboard页面
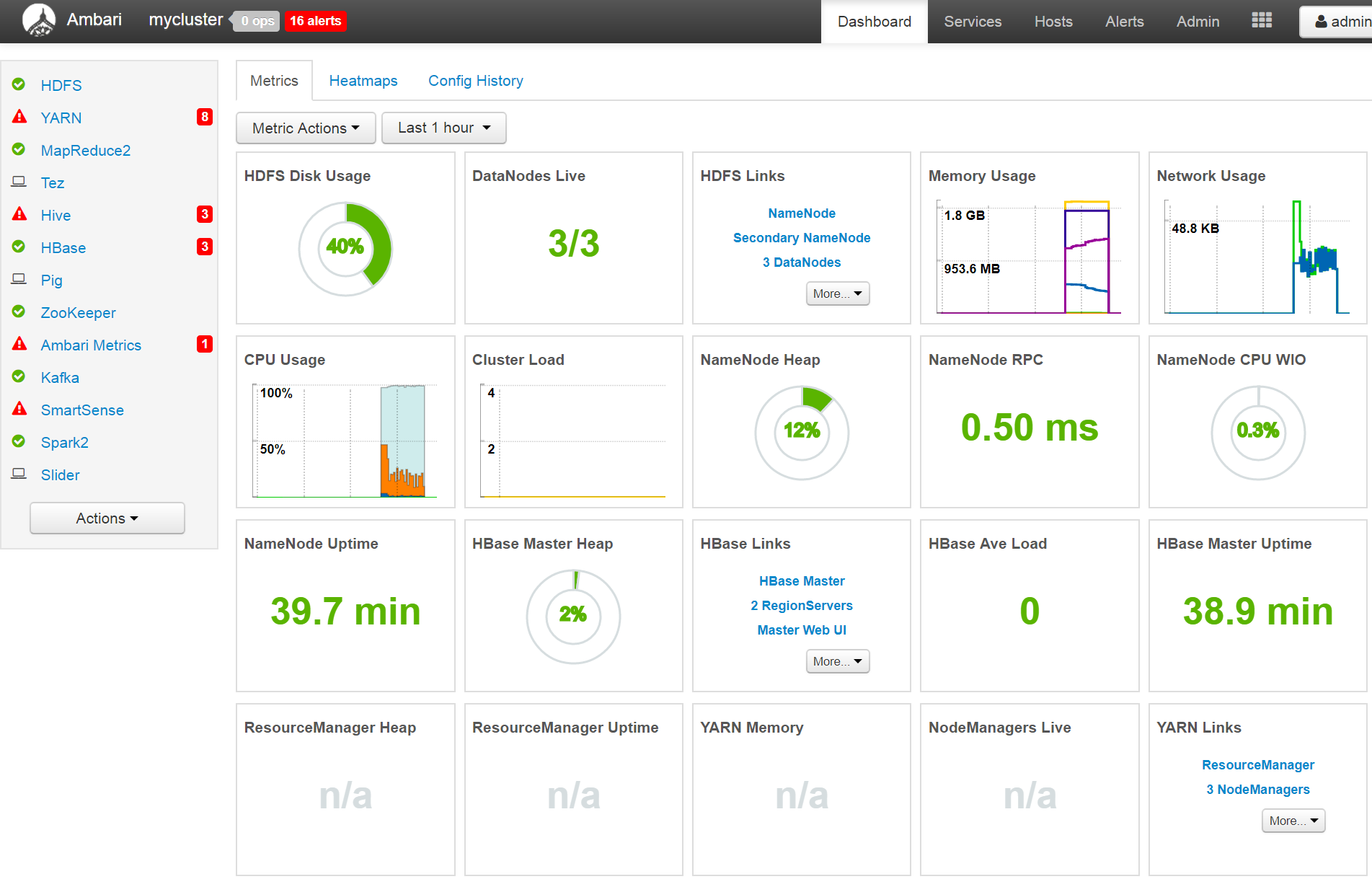
(12)、Ambari上给Root用户增加HDFS写权限
Ambari WebUI Dashboard/HDFS/Configs/Advanced/Advanced hdfs-site/设置dfs.permissions.enabled=false,然后重启受到影响的服务。
(13)、验证集群
A、HDFS Namenode:http://node1:50070/dfshealth.html#tab-overview
B、YARN:http://node2:8088/cluster
C、测试MapReduce
[root@node3 ~]# hdfs dfs -mkdir /data/
[root@node3 ~]# cat mr_test_data.txt
hadoop
hadoop
spark
hbase
hbase
hbase
[root@node3 ~]# hdfs dfs -put mr_test_data.txt /data/
[root@node3 hadoop-mapreduce]# hadoop jar /usr/hdp/2.6.4.0-91/hadoop-mapreduce/hadoop-mapreduce-examples-2.7.3.2.6.4.0-91.jar wordcount /data/mr_test_data.txt /result/
D、测试Spark yarn-client
[root@node1 ~]# cd /usr/hdp/2.6.4.0-91/spark2/ && bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 540M --num-executors 1 examples/jars/spark-examples_2.11-2.2.0.2.6.4.0-91.jar 100
E、测试Spark yarn-cluster
[root@node1 ~]# cd /usr/hdp/2.6.4.0-91/spark2/ && bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster
--executor-memory 750M --num-executors 1 examples/jars/spark-examples_2.11-2.2.0.2.6.4.0-91.jar 10


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









