







参数化方法
假定数据D= { xt }t 服从某个分布xt ~ p (x)
参数化方法
- 假定样本从某个已知模型中抽取,该模型由的一些参数确定,例如 p (x |q ) 服从N ( μ, σ2) ,统计量q = { μ, σ2}
- 通过估计这些统计量,得出分布
- 将估计出的分布p(x),p(ci),p(ci|x)用于决策
先验概率与后验概率
从原因到结果的论证称为“先验”; 从结果到原因的论证称为“先验”。
设A代表结果,B为发生A的原因,则
- 先验概率:P(A)
- 后验概率:P(B|A)
如何估计q ?
- 极大似然估计MLE:不考虑q 的先验知识
- 最大后验估计MAP:考虑q 的先验知识
- 贝叶斯估计:将q 视为随机变量,求后验期望
样本服从伯努利分布
伯努利分布:伯努利分布是一个离散型机率分布,是二项分布,N=1时的特殊情况。也即01分布。
,
, 即
若x服从伯努利分布,则 ,
MLE估计
由,N次实验的结果为 x^t t=1,.....,N ,
求得MLE:
高斯/正态分布
样本方差/总方差
注意样本方差: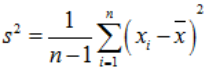
总方差:
MLE估计
贝叶斯定理
在贝叶斯决策中,x为样本,c为类别
若有多个属性,即x=[x1,x2...]^T,则要求各属性条件独立假设:
推得当给定样本x,要判断所属类别时,我们需要计算出x属于每个类别的概率,取最大值,即
- 先验概率:样本空间中各类样本所占的比例。可通过各类样本出现的频率估计(大数定理)
Example

- 明确这题是用给出的训练数据学习得到一个朴素贝叶斯分类器,来预测数据x=(2,s)^T的类标记。
- 要预测x=(2,s)^T的类标记,我们就得算出P(Y=-1 | x)与P(Y=1 | x),取最大值对应的Y作为结果,而
,分母一样,所以我们只用算出分子即可比较大小,即就是要计算
- 计算得P(Y=-1)=6/15=2/5 , P(x(1)=2 | Y=-1)=2/6=1/3 , P(x(2)=s | Y=-1)=3/6=1/2 , 所以P(Y=-1)P(x(1)=2 | Y=-1)P(x(2)=s | Y=-1)=1/15
- 计算得P(Y=1)=3/5 , P(x(1)=2 | Y=1)=1/3 , P(x(2)=s | Y=1)=1/9 , 所以P(Y=1)P(x(1)=2 | Y=1)P(x(2)=s | Y=1)=1/45
- 比较得P(Y=-1)P(x(1)=2 | Y=-1)P(x(2)=s | Y=-1),所以预测数据x=(2,s)^T的类标记为Y^=-1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









