






一、语音识别的原理
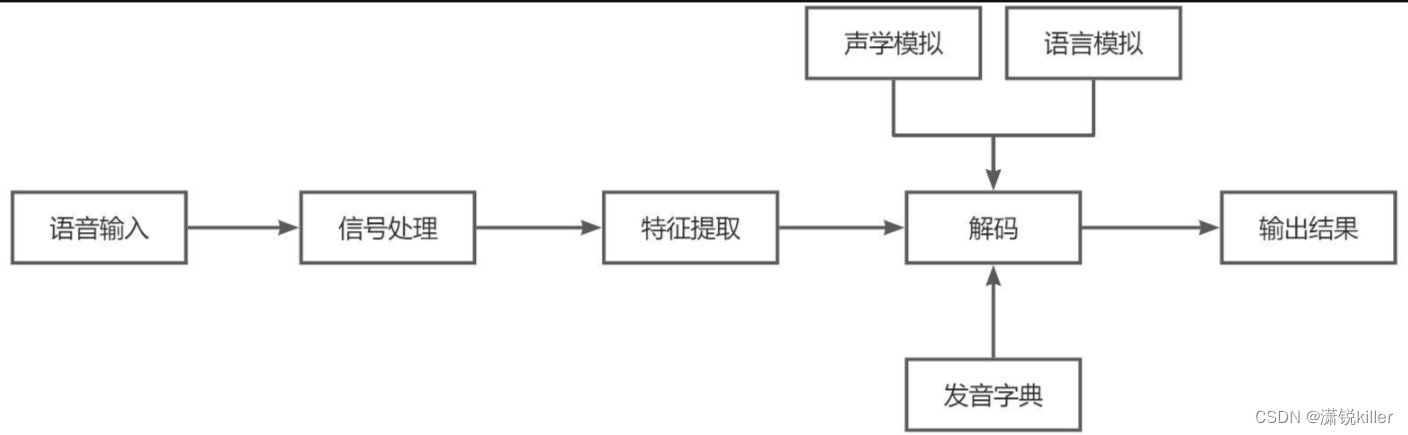
一个连续语音识别系统包含了特征提取、声学模型、语言模型和解码器这四个主要部分。
特征提取是指在除去语音信号中对于语音识别无用的信息后,保留能够反映语音本质特征的关键信息,对其进行处理,再用特定的形式表示出来,用于后续的进一步处理。
声学模型可以理解为是对声音进行建模,把语音输入转换为声学表示的输出。
语言模型是用来计算出一个句子出现概率的模型,简单来说,就是计算出这个句子在语法上是否正确的概率。
解码器就是指语音技术中的识别过程。
语音识别的本质就是一种模式识别的过程,将未知的语音模式与已知的语音模式进行对比,最佳匹配的参考模式就被视为识别结果。
实现基本原理图
整个语音识别的过程,先从本地获取音频,然后传到云端,最后识别出文本,就是一个声学信号转换成文本信息的过程。
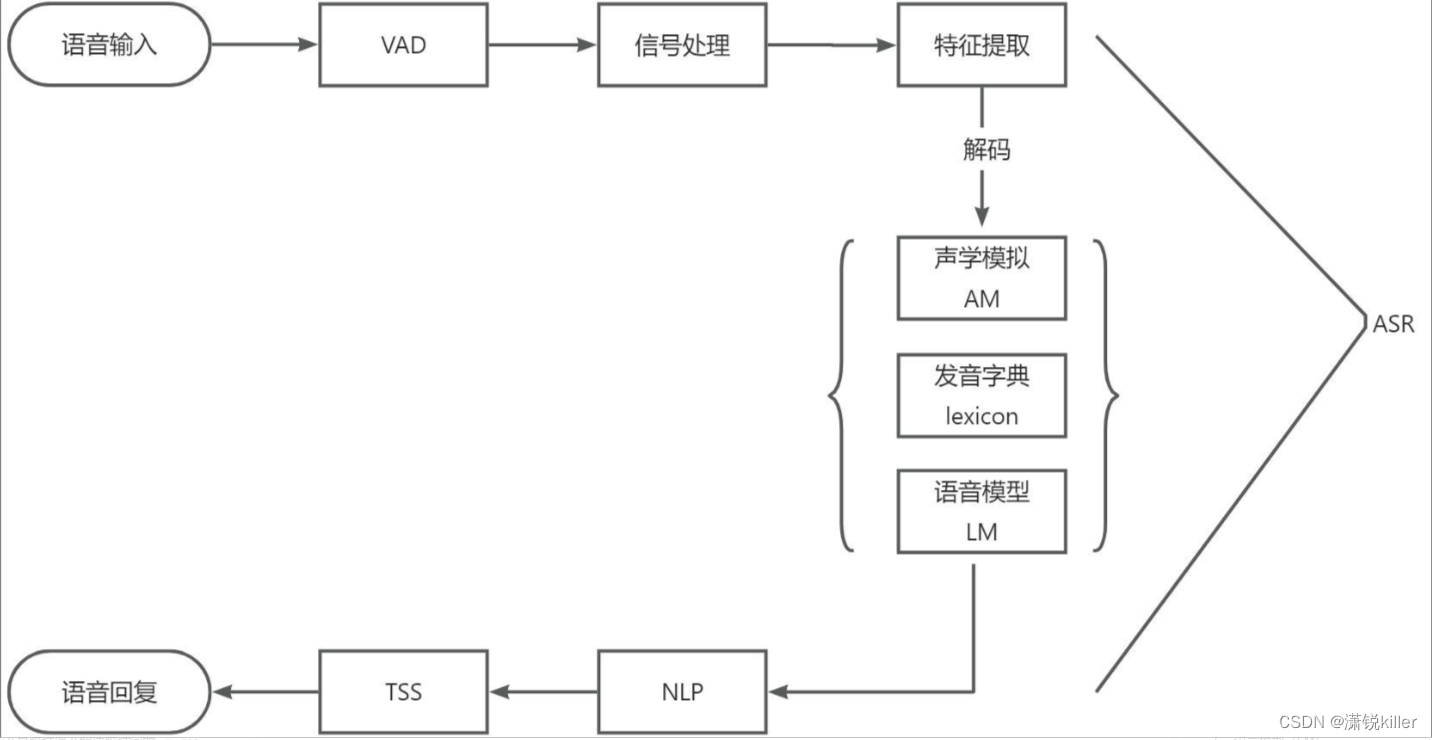
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成干扰,这个切除静音的操作一般称为VAD。
VAD(Voice Activity Detection),也叫语音激活检测,或者静音抑制,其目的是检测当前语音信号中是否包含话音信号存在,即对输入信号进行判断,将话音信号与各种背景噪声信号区分出来,分别对两种信号采用不同的处理方法。
算法方面,VAD算法主要用了2-3个模型来对语音建模,并且分成噪声类、语音类和静音类。目前大多数还是基于信噪比的算法,也有一些基于深度学习(DNN)的模型。
这里的信号处理一般指的是降噪,有些麦克风阵列本身的降噪算法受限于前端硬件的限制,会把一部分降噪的工作放在云端。
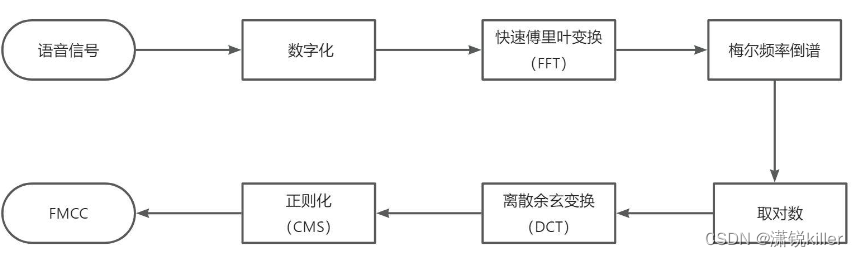
4、特征提取
特征提取是语音识别关键的一步,解压完音频文件后,就要先进行特征提取,提取出来的特征作为参数,为模型计算做准备。简单理解就是语音信息的数字化,然后再通过后面的模型对这些数字化信息进行计算。
特征提取首先要做的是采样,前面我们说过音频信息是以数据流的形式存在,是连续不断的,对连续时间进行离散化处理的过程就是采样率,单位是Hz。可以理解为从一条连续的曲线上面取点,取的点越密集,越能还原这条曲线的波动趋势,采样率也就越高。理论上越高越好,但是一般10kHz以下就够用了,所以大部分都会采取16kHz的采样率。
5、声学模型(AM)
把从声音中提取出来的特征,通过声学模型,计算出相应的音素。
6、语言模型(LM)
语言模型是将语法和字词的知识进行整合,计算文字在这句话下出现的概率。一般自然语言的统计单位是句子,所以也可以看做句子的概率模型。简单理解就是给你几个字词,然后计算这几个字词组成句子的概率。
7、词典
词典就是发音字典的意思,中文中就是拼音与汉字的对应,英文中就是音标与单词的对应,其目的是根据声学模型识别出来的音素,来找到对应的汉字(词)或者单词,用来在声学模型和语言模型建立桥梁,将两者联系起来。简单理解词典是连接声学模型和语言模型的月老。
二、Springboot + 百度短语音识别sdk 实践demo
1、在 百度智能云-登录
领取 语音识别的免费使用次数 (个人 15万)
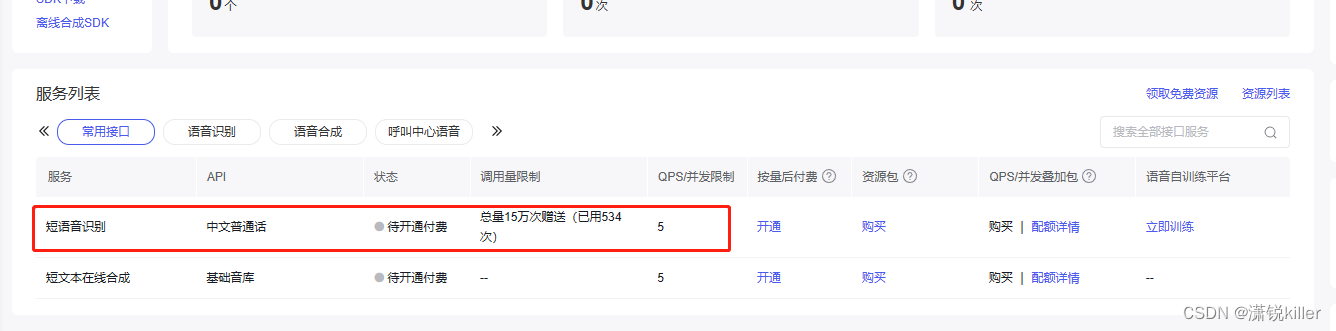
2、添加依赖
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.16.18</version>
</dependency>
3、开发Service
@Service
public class BaiduSpeechService {
public static final String APP_ID = "***";
public static final String API_KEY = "****";
public static final String SECRET_KEY = "****";
private AipSpeech client;
public BaiduSpeechService() {
// 设置APPID/API Key/Secret Key
client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
}
public Map<String, Object> recognize(String filePath) {
// 调用百度语音识别接口
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
HashMap<String, Object> options = new HashMap<>();
// options.put("dev_pid", 1537);
JSONObject res = client.asr(filePath, "wav", 16000, null);
Map<String, Object> resultMap = new HashMap<>();
if (res.has("result") && res.get("result") != null) {
resultMap.put("result", res.get("result"));
System.out.println(resultMap);
return resultMap;
}
return resultMap;
}
}4、获取appid等
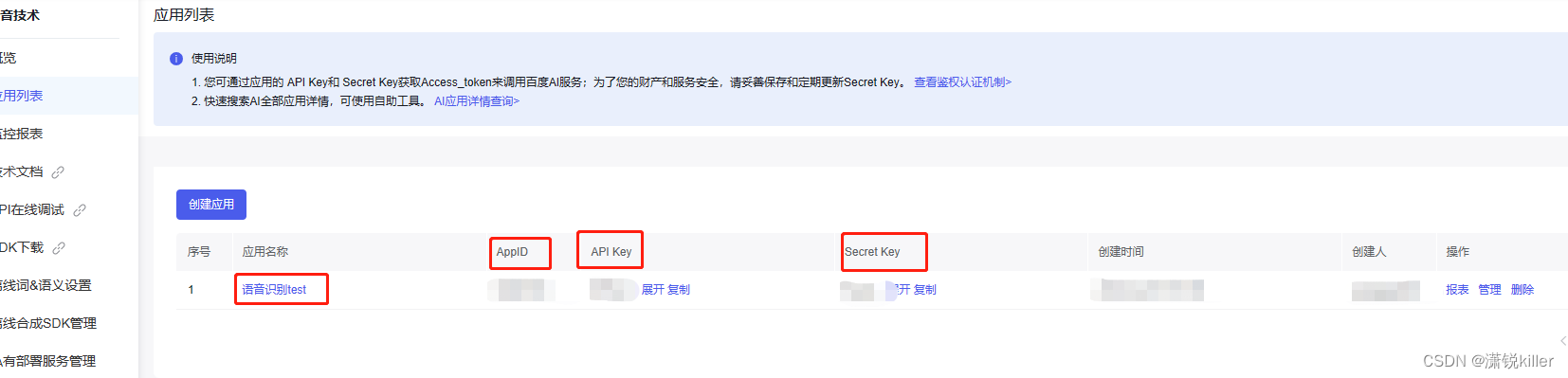
5、开发Controller
public class SpeechController {
@Autowired
private BaiduSpeechService speechService;
private static final String UPLOAD_DIR = "/tmp/upload/directory"; // 指定上传文件的保存目录
/*@GetMapping("/")
public String home() {
return "index";
}*/
@PostMapping("/speech/recognize")
public ReturnResult recognizeSpeech(@RequestParam("file") MultipartFile file) throws IOException {
// 将上传的文件保存到服务器,调用语音识别服务
String filePath = saveFile(file);
try {
Map<String, Object> text = speechService.recognize(filePath);
return ReturnResult.ok().data(text);
} finally {
// 确保即使识别过程中出现异常,文件也能被删除
// deleteFile(filePath);
}
}
private String saveFile(MultipartFile file) throws IOException {
String fileName = file.getOriginalFilename();
String filePath = UPLOAD_DIR + "/" + fileName; // 构建完整的文件路径
File dest = new File(filePath);
// 确保目录存在
if (!dest.getParentFile().exists()) {
dest.getParentFile().mkdirs();
}
try (FileOutputStream outputStream = new FileOutputStream(dest)) {
outputStream.write(file.getBytes());
}
return filePath;
}
private void deleteFile(String filePath) {
try {
Files.delete(Paths.get(filePath));
} catch (IOException e) {
// 记录日志或者处理删除失败的情况
System.err.println("Failed to delete file: " + filePath);
e.printStackTrace();
}
}
}6、前端代码
i、注意依赖的js
<script src="HZRecorder.js"></script>
ii、按钮 主要实现 按住录音 松开上传的功能
async function setupRecordAndUploadEvents() {
const recordAndUploadButton = document.getElementById('recordAndUploadButton');
const uploadProgress = document.getElementById('uploadProgress');
let isRecording = false;
let rec;
HZRecorder.get(function (recInstance) {
rec = recInstance;
recordAndUploadButton.addEventListener('mousedown', startRecording);
recordAndUploadButton.addEventListener('mouseup', stopAndUpload);
recordAndUploadButton.addEventListener('touchstart', startRecording);
recordAndUploadButton.addEventListener('touchend', stopAndUpload);
}, {sampleRate: 16000});
function startRecording(event) {
event.preventDefault();
if (!isRecording) {
isRecording = true;
recordAndUploadButton.textContent = '点击上传';
rec.start();
}
}
let audioBlob = null; // 用于保存最新的录音Blob
async function stopAndUpload() {
if (isRecording) {
isRecording = false;
recordAndUploadButton.textContent = '按住录音';
try {
rec.stop();
await handleRecording(rec.getBlob());
} catch (error) {
console.error('停止录音时出错:', error);
}
}
}
async function handleRecording(audioBlob) {
uploadProgress.style.display = 'block';
const formData = new FormData();
formData.append('file', audioBlob, 'recording.wav');
await uploadAudio(formData);
}
async function uploadAudio(formData) {
const token = await authenticate();
uploadProgress.style.display = 'block';
try {
const response = await fetch('/speech/recognize', {
method: 'POST',
headers: {'token': token},
body: formData,
onUploadProgress: updateUploadProgress
});
if (!response.ok) {
throw new Error(`HTTP error! Status: ${response.status}`);
}
const data = await response.json();
await processRecognitionResult(data);
} catch (error) {
alert('上传录音或识别过程中发生错误: ' + error.message);
} finally {
finishUploadProcess();
}
}
function updateUploadProgress(progressEvent) {
if (progressEvent.lengthComputable) {
uploadProgress.value = Math.round((progressEvent.loaded / progressEvent.total) * 100);
}
}
async function processRecognitionResult(data) {
if (data.data.result && data.data.result.length > 0) {
const recognizedText = data.data.result[0];
sseOneTurn(recognizedText);
} else {
alert('语音识别结果为空');
}
}
function finishUploadProcess() {
uploadProgress.value = 0;
uploadProgress.style.display = 'none';
// 更新rec 保证只上传最新的录音
HZRecorder.get(function (recInstance) {
rec = recInstance;
recordAndUploadButton.addEventListener('mousedown', startRecording);
recordAndUploadButton.addEventListener('mouseup', stopAndUpload);
recordAndUploadButton.addEventListener('touchstart', startRecording);
recordAndUploadButton.addEventListener('touchend', stopAndUpload);
}, {sampleRate: 16000});
}
}7、上传后的文件

8、主要的问题
navigator.mediaDevices.getUserMedia
浏览器的安全策略规定,navigator.mediaDevices.getUserMedia方法只能在https协议或者localhost域名下才有效。
解决:SpringBoot项目配置HTTPS接口的安全访问
参考:https://blog.csdn.net/wangqiaowq/article/details/138522859?spm=1001.2014.3001.5502
i、使用openssl工具生成自签发的数字证书
HTTPS网站所用的证书可向可信CA机构申请,不过这一类基本上都是商业机构,申请证书需要缴费,如果只是APP与后台服务器进行HTTPS通信,可以使用openssl工具生成自签发的数字证书。
需要把自己先扮演成CA机构,根据非对称加密的概念,我们需要有一对密钥,对应一把公钥和一把私钥,私钥放在自己身边,公钥提供出去,这边需要注意的是不能把他看成是服务端,CA机构是在客户端和服务端两者之间的一个存在,这边理解了后,我们先来创建一把私钥,可以使用openssl来生成。
安装 openssl 并生成证书
ii、spring boot配置ssl证书实现https

iii、 添加到springboot项目中
9、最后呈现的效果
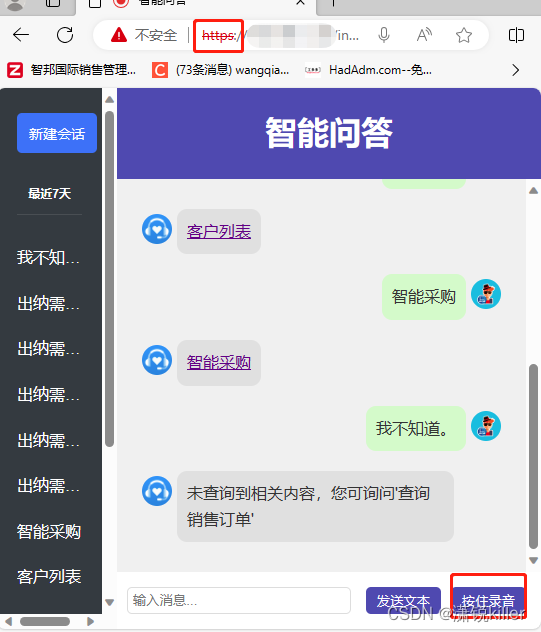
其他:语音识别技术工作原理和流程 - 飞桨AI Studio星河社区 (baidu.com)
语音识别技术,也被称为自动语音识别(Automatic Speech Recognition,ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。















 559
559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









