









本文是对《利用python进行数据分析》第四章,“Numpy基础:数组和矢量计算”的一个回顾性阅读笔记,对于代码已经加上自己的部分注释。 Numpy这章主要是将数据的整理和清理、子集构造和过滤、转换等快速的矢量化数组运算。 Numpy的大多数功能都在Pandas中已覆盖,且pandas比numpy应用更方便,所以重点是pandas而非numpy,numpy只做选择性记录。
目录
ndarray:一种多维数组对象
定义:
ndarray是一个通用的同构数据多维容器,其中的所有元素必须是相同类型,也成为数组
创建Numpy数组ndarry:
常见的是用np.array函数 。 注意np.array数组里的数据类型要用dtype 而不是type。如果里面只要有一个float就认为是float类型, 如
data1=[6,7.5,8,0,1]
arr1=np.array(data1)
print(arr1)
print(arr1.dtype)
#输出
[6. 7.5 8. 0. 1. ]
float64常见数组创建函数
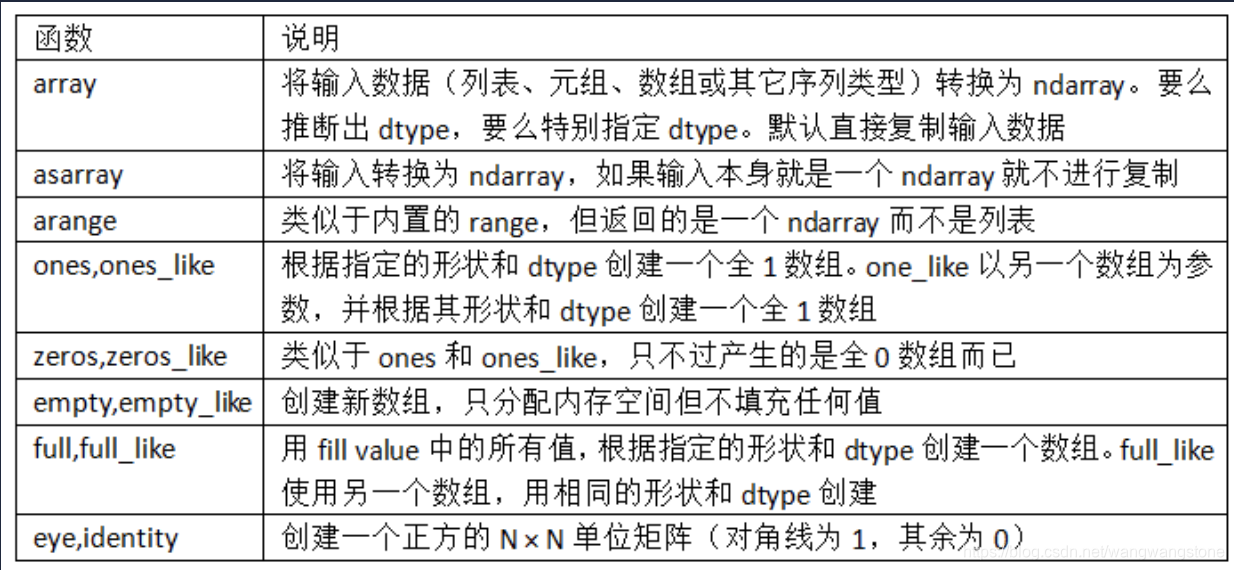
上面如果没有特别指定,数据类型基本都float64类型。
数据类型转换
使用.astype()函数。
注意numpy的array里数据类型字符串表示后面要到下划线_ ,为string_
numeric_strings = np.array(['1.25', '-9.6', '42'], dtype=np.string_)
numeric_strings=numeric_strings.astype(float) # 转换为float
print(numeric_strings.dtype) 数组和标量之间的运算
注意 会广播
arr=np.array([[1,2,3.],[4.,5.,6.]])1/arr # 会去除以每个元素 矢量的概念:
ndarry数组之所以重要是因为它可以不用编写循环就可对数据执行批量运算。这种操作通常就叫矢量化。
基本的索引和切片
切片索引,如: arr[1:6]
布尔型索引,例子
names=np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])
s=names=='Bob' # 这个返回的是布尔型ndarray
print(s)
data=randn(7,4) # 七行四列的随机数据
print(data[names=='Bob'])# 返回的是布尔为true对应数据index位置的结果,为Flse ,即只返回了data第1行和第3行位置的数据
#输出:
[ True False False True False False False]
第二个对应的返回的是布尔为true对应数据index位置的结果,为Flse ,即只返回了data第1行和第3行位置的数据花式索引,用到的很少,需要时再看
快速的元素级函数
此处是指会对数组中元素这个级别进行操作的函数
了解常见的元素级函数,记住多数常见数据函数名称,python中相关的包如numpy里都有实现,要用的时候,查下文档即可
一元函数

二元函数

利用数组进行数据处理
将条件逻辑表述为数组运算 np.where
np.where函数
np.where函数直接进行条件逻辑的筛选确认,例子
print(np.where(arr>0,2,-2)) # np.where的第二个和第三个参数不必是数组,他们都可以是标量值,
np.where(arr>0,2,arb)# 将其中大于0的给值2,不大于0的为arb中对应为位置的值
数学和统计方法
基本数组统计方法
如sum,mean,std,cumsum,cumprod
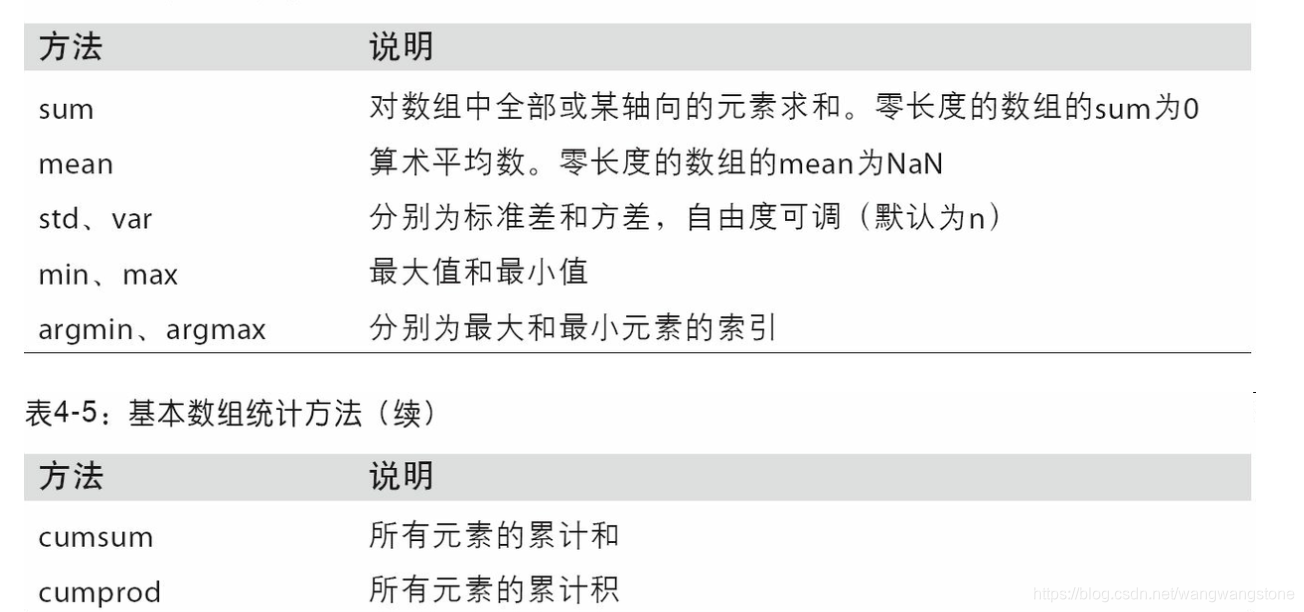
参数注意
如ndarrydata1.mean() ,注意mean里面的参数0表示结果中变得是行数,如果是1则表示结果中变得是列数。而当什么都不指定时,则是所有的数求平均数,
进一步熟悉的函数
arr=np.array([[0,1,2],[3,4,5],[6,7,8]])
print(arr.cumsum(0)) # 元素的累计和
print(arr.cumprod(1)) # 元素的累计积
print(np.modf(arr)) # modf 是分解数字的整数部分和小数部分用于布尔型数组的方法
bools.any()
any用于测试数组中是否存在一个或者多个True
bools.all()
all 用于检查数组中所有值是否都是True
bools=np.array([False,False,True,False])
print(bools.any()) # any用于测试数组中是否存在一个或者多个True
print(bools.all()) # all 用于检查数组中所有值是否都是True
#输出:
True
False
#例子2
arr=np.array([[0,1,2],[3,4,5],[6,7,8]])
print((arr>5).sum() )
#输出 3
# 求大于5的元素的个数! 注意! 此前面的得到的是布尔值,布尔值用数学方法的时候会被强制转换为1或者0,sum()经常用来对布尔值进行计数 !!
sorting排序
ndarrayData.sort和np.sort
#data.sort注意改变了原数组。这个不等同于np.sort,np.sort不会改变原数组!因为np.sort返回的是数组的已排序的副本
import numpy as np
arr=np.random.randint(10,size=10).reshape(2,5)
print(arr)
print(arr.sort(1)) # 输出None,但是原来的arr 改变了
#注意参数 1按列的方向变动,即值所处的行号不会变动,但是列号会变动。即保证各行的元素内是有序的
print(arr)
# 输出
# [[9 3 6 1 9]
# [6 5 0 0 3]]
# None
# [[1 3 6 9 9]
# [0 0 3 5 6]]随机数生成
np.randn(a,b)
生成一个随机形状为(a,b)的随机小数数组
numpy.random.randint(low, high=None, size=None, dtype='l')
参数:
low: int生成的数值最低要大于等于low。(hign = None时,生成的数值要在[0, low)区间内)
high: int (可选) ,如果使用这个值,则生成的数值在[low, high)区间。
size: int or tuple of ints(可选)
输出随机数的尺寸,比如size = (m * n* k)则输出同规模即m * n* k个随机数。默认是None的,仅仅返回满足要求的单一随机数。
dtype: dtype(可选):想要输出的格式。如int64、int等等
out: int or ndarray of ints
返回一个随机整数或随机整数数组
datas=np.random.randint(2,10) # 在2-10内生成一个随机整数!
np.random.normal(size=(a,b))
样例
samples= np.random.normal(size=(4,4)) # 用normal 来得到一个服从标准正态分布的4*4的数组
结果:
array([[-0.1995, -1.542 , -0.9707, -1.307 ],
[ 0.2863, 0.378 , -0.7539, 0.3313],
[ 1.3497, 0.0699, 0.2467, -0.0119],
[ 1.0048, 1.3272, -0.9193, -1.5491]])代码与思维导图
本文与书本对应章节的代码脚本见本人资源
鸣谢与参考:
《利用python进行数据分析》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









