










在设计或重构系统的过程中,特别是在设计分布式、大数据量系统里面,序列化选型是一个重要环节,因为序列化协议影响系统的通用性、健壮性、安全性,是否易于调试、是否便于扩展。
序列化分理论和实践部分,理论部分描述只序列化是什么、要做什么,不关心实现(因为不考虑具体实现,所以自然不会考虑优缺点、应用场景);实践部分描述如何完成序列化操作,对象用什么方法表示,即把序列化从理论世界带进现实世界。序列化理论部分相当于是设计,实践部分相当于实现。
理论
序列化理论包含的三个方面
- 序列化定义;
- 序列化在通信协议中的地位;
- 序列化组件
1. 序列化问题是怎么产生的(序列化的定义)
互联网的发展产生了机器之间互相通讯的需求,机器之间互相通讯需要约定通讯协议,通信协议又要考虑数据如何表示、如何传输等问题。序列化就是通信协议里与数据的表示相关的那一部分协议。OSI七层协议模型中的展现层(Presentation Layer)的主要功能是把对象转换成一段连续的二进制串,或把二进制串转换成对象–这就是序列化和反序列化。
所以,序列化和反序列化的定义就是:
- 序列化: 将数据结构或对象转换成二进制串
- 反序列化:将在序列化过程中所生成的二进制串转换成数据结构或对象
注:不一定非要转换成二进制,只要是能传输到通信另一端都可以,例如utf-8字符串。
2. 序列化在通信协议中的地位
- OSI七层协议模型,序列化位于展示层(Presentation Layer)
- 在TCP/IP协议中,序列化位于应用层。
3. 序列化和反序列化的组件
完整的序列化协议包含以下组件:
- IDL文件(Interface description language)。参与通讯的各方需要对通讯的内容做相关约定。为了与语言和平台无关,这个约定需要采用与编程语言、平台无关的语言来进行描述。这种语言被称为接口描述语言(IDL),采用IDL撰写的协议约定称为IDL文件。
- IDL Compiler:IDL文件中的约定需要一个编译器,将IDL文件转换成各编程语言的动态库。
- Stub/Skeleton Lib:负责序列化和反序列化工作的代码。Stub是一段部署在客户端的代码,一方面接收应用层的参数,并对其序列化后通过底层协议栈发送到服务端;另一方面接收服务端序列化后的结果数据,反序列化后交给应用层;Skeleton部署在服务端,其功能与Stub相反,从传输层接收序列化参数,反序列化后交给服务端应用层,并将应用层的执行结果序列化后最终传送给客户端。
序列化组件之间的交互关系:
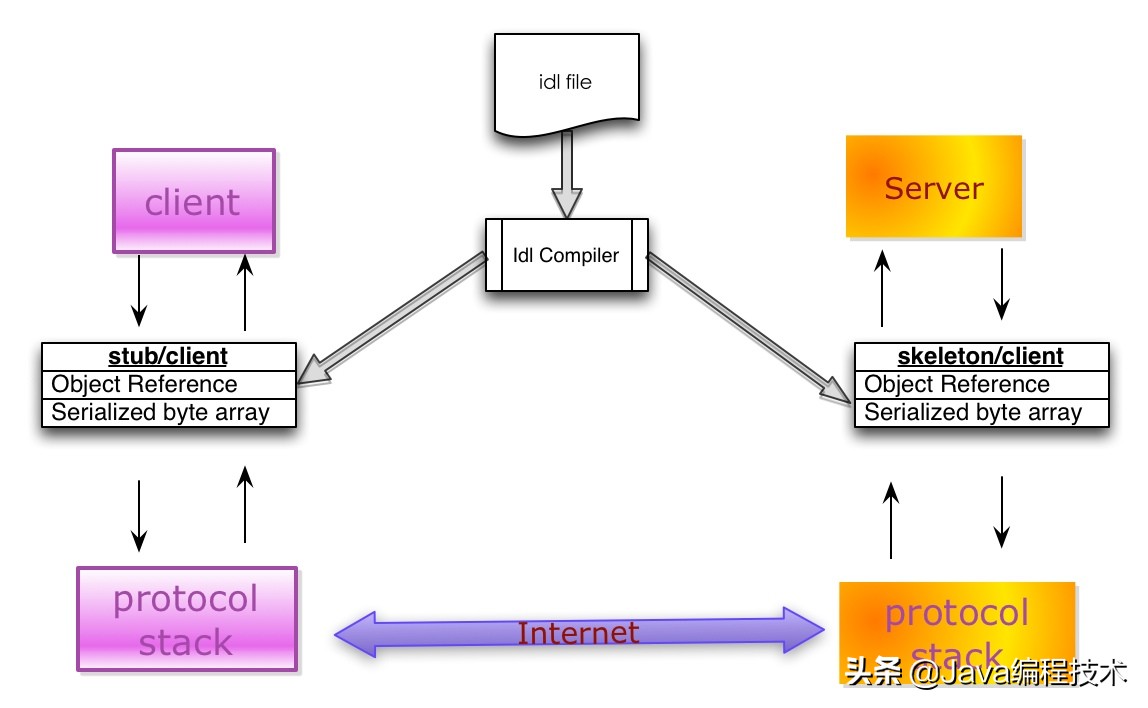
序列化组件之间的交互
序列化组件的概念与数据库的相关概念类似:
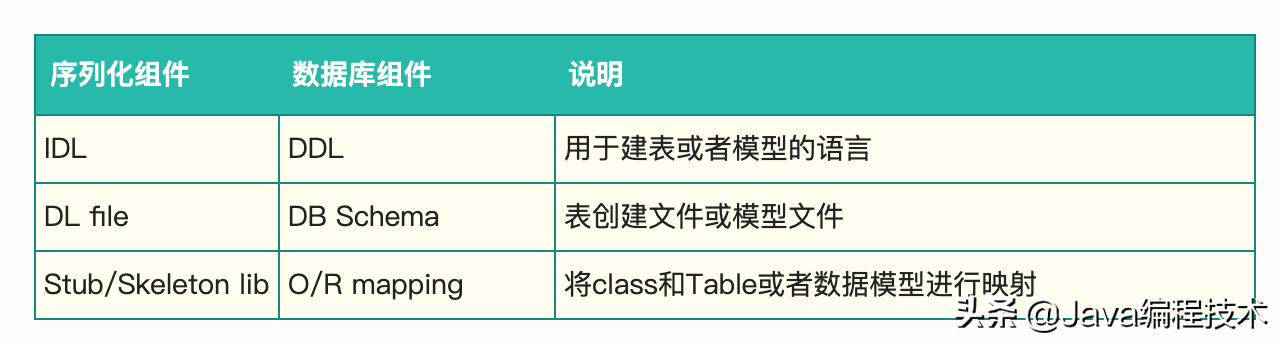
实践
序列化协议的考虑点
- 支持哪些编程语言,能否跨语言
- 支持哪些平台,是否跨平台(例如支持哪些硬件架构、操作系统)
- 流行程度(序列化涉及通信双方,冷门的序列化协议需要的学习成本很高)
- 健壮性/鲁棒性
- 成熟程度(这个协议是否经历大量全面的测试、真实世界系统的检验,长期稳定运行)
- 是否简单易用
- 调试难度、可读性(序列化和反序列化的数据正确性和业务正确性的调试往往需要很长时间,良好的调试机制大大提高开发效率。序列化后的二进制串往往不具备人眼可读性,为了验证序列化结果的正确性,写入方不得不同时撰写反序列化程序,或提供一个查询平台–这比较费时;另一方面,如果读取方未能成功实现反序列化,难以确定是自身反序列化程序bug导致的还是写入方写入了错误序列化数据导致的。如果序列化后的数据人眼可读,这将大大提高调试效率, 例如XML和JSON就具有人眼可读的优点。)
- 空间性能(Verbosity),即序列化以后的数据所占用的空间大小。
- 时间性能(Complexity)。复杂的序列化协议会导致较长的解析时间,这可能使得序列化和反序列化成为系统瓶颈。
- 扩展性/兼容性。新增字段是否容易。业务系统需求的更新周期快,新需求不断涌现。如果序列化协议具有良好的可扩展性,支持自动增加新的业务字段,而不影响老的服务,这将大大提供系统的灵活度。
- 安全性/访问限制。例如阿里的fastjson经常有安全性问题。
- 文档。
已知的序列化协议
互联网早期序列化协议有COM和CORBA。
COM主要用于Windows平台,没有实现跨平台。COM序列化利用了编译器中的虚表,使得学习成本很高。序列化得到的数据与编译器紧耦合,扩展属性非常麻烦。
CORBA比较好的实现了跨平台,跨语言。COBRA的主要问题是参与方过多,导致版本过多,版本之间兼容性差,使用复杂晦涩。早期设计的不成熟问题导致COBRA渐渐消亡。J2SE 1.3之后的版本提供基于CORBA协议的RMI-IIOP技术,可以采用纯Java语言进行CORBA开发。
当前比较流行的序列化协议有 XML、JSON、Protobuf、Hessian、Thrift、Avro。如果你还想了解更多序列化协议,参考 https://en.wikipedia.org/wiki/Comparison_of_data-serialization_formats
XML序列化协议
XML是一种语言,一种描述性的语言,最初目标是对文档进行编码,而且要求编码数据既能供人阅读也便于计算机处理。XML在设计的时候就考虑到可读性,它还有跨机器、跨语言(这里指的是人类语言)等优点。XML历史悠久,其1.0版本早在1998年就形成标准,并被广泛使用至今,所以XML是足够成熟的。既然XML能把有复杂结构的文档编码,那么XML也可以用于对象序列化,所以把XML列为一种序列化协议(例如.NET框架和gSOAP框架就采用XML序列化)。但是XML用作序列化协议的时候,它就显得冗长复杂。
XML具有自我描述性,XML自身就作为IDL。XML中的IDL(即XML描述格式)有两种:DTD(Document Type Definition)和XSD(XML Schema Definition)。XML在某些编程语言里面具有非常简单易用的序列化API,无需IDL文件和第三方IDL编译器(例如Java XStream)。XML被广泛应用在各种配置文件中,例如O/R mapping、 Spring Bean Configuration File 等。
优点:跨平台、跨语言、成熟、可读性
缺点:复杂冗长(空间复杂度)
SOAP序列化协议
SOAP(Simple Object Access protocol)是一种广泛应用的,基于XML的结构化消息传递协议,XML被用于序列化和反序列化。SOAP支持多种传输协议,但是最常用的还是HTTP。SOAP协议的IDL是WSDL(Web Service Description Language)。
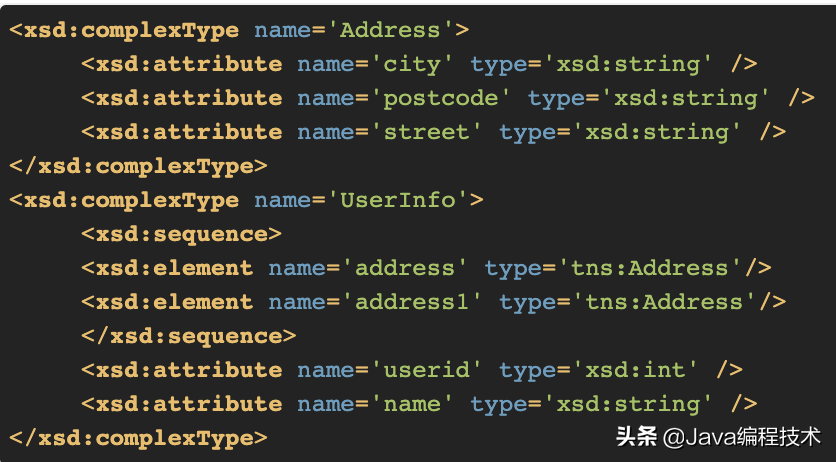
假如java应用层对象是:

用WSDL描述上述对象:
SOAP具有安全、可扩展、跨语言、跨平台、支持多种传输协议,有广泛的群众基础,基于HTTP的传输协议使得SOAP在穿越防火墙时具有良好安全性,XML的人眼可读特性使得其具有出众的可调试性,互联网带宽的发展逐渐弥补了其空间开销大的缺点。对于在公司之间传输少量数据或实时性要求相对低(例如秒级别),SOAP是一个好的选择。
XML空间开销大,数据量大、需要持久化应用场景不适合用XML。XML的序列化和反序列化的空间和时间开销都比较大,对于对性能要求达到ms级别的服务,不推荐XML。WSDL虽然具备对象描述能力,但是SOAP的使用不简单。对于习惯于面向对象编程的用户,WSDL文件不直观。
JSON序列化协议
权威网站:http://json.com/
JSON起源于JavaScript中的”Associative array”的概念,本质就是采用”Attribute-value”方式描述对象。实际上在Javascript和PHP等弱类型语言中,类的描述方式就是Associative array。JSON有如下优点,使得它快速成为最广泛使用的序列化协议之一:
1、这种Associative array格式匹配工程师对对象的理解。
2、它也有XML的人眼可读(Human-readable)优点。
3、序列化后的数据简洁。
4、JavaScript先天支持,所以广泛应用于Web browser的应用常景,是Ajax的事实标准协议。
5、与XML相比,其协议比较简单,解析速度比较快。
6、松散的Associative array使得其具有良好的可扩展性和兼容性。
因为json其实是associative array,与弱类型编程语言中的class在概念上对应,所以JSON序列化也不需要IDL。原因:IDL的目的是撰写IDL文件,而IDL文件被IDL Compiler编译后产生一些代码(Stub/Skeleton),而这些代码真正负责相应的序列化和反序列化工作。 但是由于Associative array和一般语言里面的class太相似,他们之间形成了一一对应关系,这就使得我们可以采用一套标准代码进行相应的转化。对于自身支持Associative array的弱类型语言,语言自身就具备操作JSON序列化后的数据的能力;对于Java这强类型语言,可以用反射解决。
JSON在很多应用场景中可以替代XML,更简洁且解析速度更快。典型应用场景包括:
- 公司之间传输数据量相对小,实时性要求相对低(例如秒级别)的服务。
- 基于Web browser的Ajax请求。
- 由于JSON具有非常强的前后兼容性,所以它适用于:接口经常发生变化,对可调式性要求高的场景,例如Mobile app与服务端的通讯(移动APP为什么要用JSON协议与服务端交互)。
- JSON的典型应用场景是JSON+HTTP,适合跨防火墙访问。
总体看,JSON序列化的额外空间开销也比较大(但是比XML小多了),不适合数据量大或需要持久化的场景。没有统一的IDL降低了对参与方的约束,实际操作中往往只能采用文档方式来进行约定,这可能会给调试带来一些不便,延长开发周期。由于JSON在一些语言中的序列化和反序列化需要反射机制,所以性能要求ms级别的系统不建议使用。
Thrift序列化协议
Thrift是Facebook开发的一个RPC框架,满足了大数据量、分布式、跨语言、跨平台数据通讯的需求。Thrift内部有一个自定义的序列化协议,即Thrift序列化协议。
优点:相对于JSON和XML,Thrift在空间开销和解析性能上有较大提升,适用于性能要求高的系统;它支持多种编程语言,数据类型丰富,对于数据字段的增删有较强的兼容性。
缺点:thrift序列化被嵌入到thrift框架内部,然而Thrift框架没有对外提供thrift序列化和反序列化的接口,文档匮乏,用起来比较困难。Thrift序列化之后得到的数据是Binary数组,不具有可读性,调试相对困难。Thrift的序列化和框架紧耦合,无法支持向持久层直接读写数据,不适合用于数据持久化的场景。

Protobuf序列化协议
权威网站:https://developers.google.com/protocol-buffers
Protobuf具备序列化协议的众多优秀特征:
- 提供了标准的IDL和IDL编译器,对工程师非常友好。
- 序列化数据简洁紧凑,其序列化之后的数据量约为XML的1/3到1/10。
- 解析速度非常快,比XML快约20-100倍。
- 提供了友好的动态库,使用非常简洁,反序列化只需要一行代码。
- Protobuf IDL文件对于各个参与方业务产生了强力的约束
- Protobuf与传输层无关,采用HTTP,具有良好的跨防火墙访问属性。
Protobuf是一个纯展示层协议,可以用于多种传输层协议;Protobuf文档也非常完善。目前仅支持Java、C++、Python三种编程语言。另外Protobuf支持的数据类型较少,不支持常量。
所以Protobuf适用于跨公司、性能要求高的RPC调用应用场景。基于相同的原因,Protobuf也适合用于对象的持久化。
缺点:支持语言较少,没有绑定标准传输层协议,跨公司进行传输层协议调试相对麻烦。
Google gPRC框架已采用Protobuf序列化协议,可以参考。

Hessian序列化协议
hessian也是一种常见的序列化协议,经常在RPC框架中使用,例如Dubbo、Pigeon等框架都支持Hessian,甚至经常被RPC框架用作默认序列化方案。
Avro序列化协议
Avro是Apache Hadoop的子项目,解决了JSON的冗长和没有IDL的问题。Avro提供两种序列化格式:JSON格式和Binary格式。Binary格式在空间开销和解析性能方面可以和Protobuf媲美,JSON格式方便调试。Avro支持的数据类型非常丰富,包括C++语言里面的union类型。Avro支持JSON格式的IDL和类似于Thrift和Protobuf的IDL(实验阶段),这两者之间可以互转。Schema可以在传输数据的同时发送,加上JSON的自我描述属性,使得Avro非常适合动态类型语言。Avro在做文件持久化的时候,一般会和Schema一起存储,所以Avro序列化文件自身具有自我描述属性,所以适合做Hive、Pig和MapReduce的持久化数据格式。对于不同版本的Schema,在进行RPC调用的时候,服务端和客户端可以在握手阶段对Schema进行互相确认,提高了数据解析的速度。Avro解析性能高且序列化数据简洁,适合高性能序列化服务。

序列化协议Benchmark
数据 https://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking
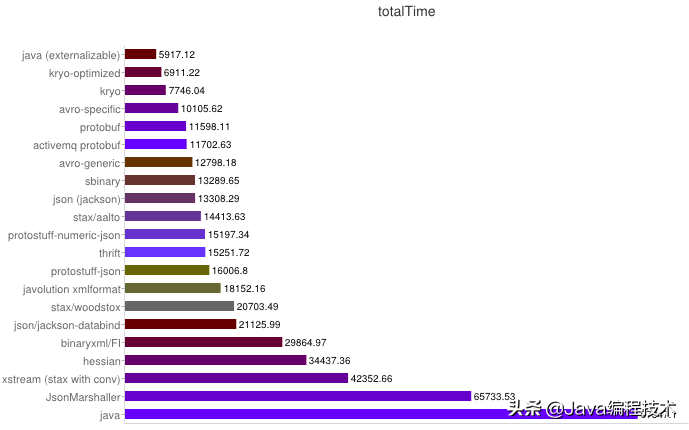
解析性能
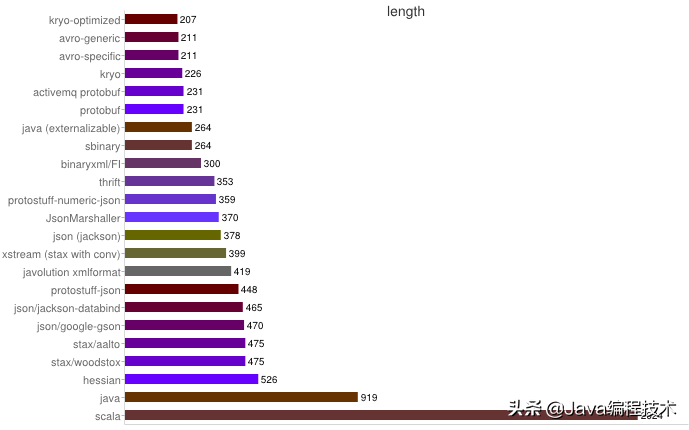
序列化之空间开销
1、XML序列化(Xstream)无论在性能和简洁性上都比较差。
2、Thrift与Protobuf相比在时空开销方面都有一定劣势。
3、Protobuf和Avro在两方面表现都非常优越。
序列化协议的选型
以上几种序列化协议各自具有特点,适用于不同场景:
1、公司之间系统调用,性能要求100ms,基于XML的SOAP协议是一个值得考虑的方案。
2、基于Web browser的Ajax,以及移动app与服务端之间的通讯,JSON是首选。对于性能要求不高或者以动态类型语言为主,传输数据小的场景,JSON是非常不错的选择。
3、对于调试环境比较恶劣的场景,JSON或XML能够极大的提高调试效率,降低开发成本。
4、当对性能和简洁性有极高要求的场景,可以考虑Protobuf、Thrift、Avro。
5、对于T级别的数据的持久化应用场景,Protobuf和Avro是首选。如果持久化后的数据存储在Hadoop子项目里,Avro是更好的选择。
6、Avro的设计理念偏向于动态类型语言,对于动态语言为主的应用场景,Avro是更好的选择。
7、持久层非Hadoop项目,以静态类型语言为主的场景,Protobuf更符合开发习惯。
8、如果需要提供一个完整的RPC解决方案,Thrift是一个好的选择。
9、如果序列化之后需要支持不同传输协议,或需要跨防火墙访问,Protobuf可以优先考虑。
参考资料
- https://en.wikipedia.org/wiki/Serialization
- http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity
- https://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking
- http://en.wikipedia.org/wiki/Serialization
- http://en.wikipedia.org/wiki/Soap
- http://en.wikipedia.org/wiki/XML
- http://en.wikipedia.org/wiki/JSON
- http://avro.apache.org/
- http://www.oracle.com/technetwork/java/rmi-iiop-139743.html
- http://json.com/
- http://hessian.caucho.com/
- https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/hessian/
- https://en.wikipedia.org/wiki/Comparison_of_data-serialization_formats
- https://code.google.com/archive/p/thrift-protobuf-compare/wikis/Benchmarking.wiki















 3782
3782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









