








 超级会员免费看
超级会员免费看


前言
前面在《谈谈谷歌word2vec的原理》文章中已经把word2vec的来龙去脉说得很清楚了,接下去这篇文章将尝试根据word2vec的原理并使用TensorFlow来训练词向量,这里选择使用skip-gram模型。
语料库的准备
这里仅仅收集了网上关于房产新闻的文章,并且将全部文章拼凑到一起形成一个语料库。
skip-gram简要说明
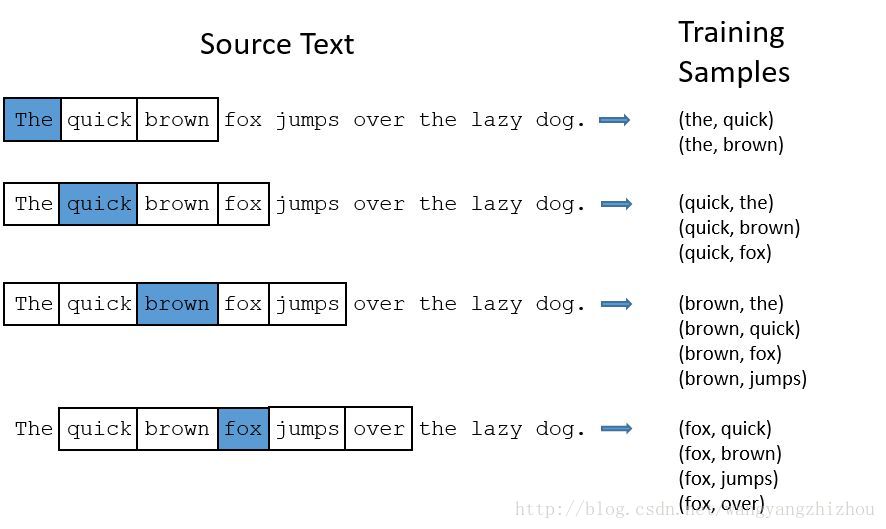
skip-gram核心思想可以通过下图来看,假设我们的窗口大小为2,则对于文本”The quick brown fox jumps over the lazy dog.”,随着窗口的滑动将产生训练样本。比如刚开始是(the,quick)(the,brown)两个样本,右移一步后训练样本为(quick,the)(quick,brown)(quick,fox),继续右移后训练样本为(brown,the)(brown,quick)(brown,fox)(brown,jumps),接着不断右移产生训练样本。skip-gram模型的核心思想即是上面所说。

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 3140
3140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











