






本文翻译自xmlpull,SAX,android,JSON官方文档(http://www.saxproject.org/quickstart.html,http://www.json.org/),经测试整理如下。
网络传输数据
一般我们会在网络上传输一些格式化的数据,这些数据有自己的语义。当另一方收到数据时,以相同的语义进行解析,获取真正想要的数据。
在网络中传输数据时最常用的方法是:XML和JSON,本文先介绍XML解析。
XML,可扩展标记语言(Extensible Markup Language)是一个以文本来描述数据的文档,可以实现客户端与服务器之间的数据传输。如下一个xml文档示例:
<?xml version="1.0" encoding="UTF-8"?>
<person>
<teacher id = "1">
<name>wyg</name>
</teacher>
<teacher id = "2">
<name>wyg</name>
</teacher>
</person>
<?xml version="1.0" encoding="UTF-8"?>是xml头部分,标记该文档为xml文档,同时指出了版本号和编码格式。<person>为开始标签(或称为:标记,元素),</person>为结束标签。在本文档中<person>是根标签,包含了两个子标签:<teacher>,在该标签内有一个id属性。<teacher>又有一个<name>子标签,该标签的值为wyg。
一个基本的xml文件就是由上述部分构成。xml有以下用途:
- 显示数据
- 存储数据
- 在服务器与客户端传输
下面我们集中讨论一下如何解析xml,即在接收方怎么处理该xml文档。主要介绍两种:PULL解析和SAX解析。
首先来看一下PULL解析
PULL解析
概述
XmlPullParser是一个接口,通过XMLPULL V1 API定义了解析方法。
根据特性不同可以有下列几种不同的解析:
- 非通用型
当设置FEATURE_PROCESS_DOCDECL为true时,则是XML1.0规范中定义的解析。 - 通用型
当设置FEATURE_VALIDATION为true时,是XML1.0规范中定义的解析(这也表明FEATURE_PROCESS_DOCDECL为true)。 - 当
FEATURE_PROCESS_DOCDECL为false时(这是默认情况),那么解析器的行为像XML1.0兼容的非通用型解析器,在没有DOCDECL出现的情况下(内部实例仍然能够通过defineEntityReplacementText()定义)。这种适合有约束条件环境下的操作,如J2ME。
XmlPullParser有两个关键的方法:next()和nextToken()。next()方法提供访问高级事件,nextToken()提供访问低级标记。
可以通过getEventType()获取解析器中的当前事件状态。最初解析器的事件状态为:START_DOCUMENT。
next()方法可以进入到下一个事件状态。该方法的返回值(int值)决定了当前解析器的状态。该值等于此刻调用getEventType()方法的返回值。
事件类型有如下几种:
START DOCUMENT
开始读文档,现在还没读任何信息START_TAG
读到XML中的一个标签。TEXT
读到文本内容,可以通过getText()方法获得。当在通用型模式时,next()方法将会读取空白,使用nextToken()方法可以忽略。END_TAG
读到结束标签END_DOCUMENT
事件结束,完成XML解析。
可以通过下列方式获取下一个事件:
next()
获得下一个事件。nextTag()
调用next(),若事件是START_TAG或END_TAG则会返回,否则抛出异常。<tag/>这样的标签则会解析成两个事件:START_TAG和END_TAGnextText()
返回下一个事件的内容。若当前事件是START_TAG,且下一个事件是TEXT,那么调用该方法将会返回标签内的内容,或者下一个事件是END_TAG则会返回空字符串。
对于TEXT事件,我们也可以通过getText()获取标签内的内容,nextToken()
这个方法和next()类似,也能返回事件。但是该方法将会返回额外的事件类型(COMMENT,CDSECT,DOCDECL,ENTITY_REF, PROCESSING_INSTRUCTION,IGNORABLE_WHITESPACE),前提xml中有这些信息。
若当前标签有属性的话可以通过getAttributeName(int)获取属性名,参数为属性的索引,从0开始。getAttributeValue(int)获取属性值,参数为属性的索引,从0开始。
在第一次使用nextXXX()方法时,通过下列方式能够获得XML的版本,standalone和编码方式:
- version
getProperty("http://xmlpull.org/v1/doc/properties.html#xmldecl-version")将返回”1.0”或者null(如果XML声明没有被读取的话,或者不支持该属性) - standalone
getProperty("http://xmlpull.org/v1/doc/properties.html#xmldecl-standalone")。如果没有standalone声明的话,或者不支持该属性的话,方法返回null。若standalone="yes"则返回Boolean类型的true,standalone="no"将返回fasle。 - encoding
通过getInputEncoding()获得,若没有在设置(在setInputStream中设置)并且没有在文档中声明,将会返回null。
PULL解析步骤
为了通过PULL解析XML格式内容,我们需要完成以下内容
- 首先我们需要创建解析器实例,可以通过下面三步完成:
- 获得XMLPULL工厂实例;
- (可选步骤)默认情况下创建解析器的工厂实例不知道命名空间,可以通过
setNamespaceAware(true)方法设置。 - 通过工厂实例创建解析器。
- 设置解析器的输入内容,可以通过
setInput(Reader)或setInput(InputStream, String)
简单介绍一下命名空间:XML命名空间提供避免元素命名冲突的方法。XML命名空间属性被放置于元素的开始标签之中,并使用以下的语法:xmlns:namespace-prefix="namespaceURI",当命名空间被定义在元素的开始标签中时,使用时可以选择加上命名空间前缀(也可以不加)。例如:
<wyg:person xmlns:wyg="http://www.sywyg.com">
<wyg:teacher id = "1"/>
</wyg:person>
所有带有相同前缀的子元素都会与同一个命名空间相关联。上述内容来自:http://www.w3school.com.cn/xml/xml_namespaces.asp。
通过上述两步,我们就可以开始解析xml文档了。典型的XMLPULL程序会反复调用nextXXX()方法检索下一个事件,并进行相应的处理,直到遇到END_DOCUMENT事件。
一套完整的解析代码如下:
/**
* XML解析:PULL解析
* @author sywyg
* @since 2015.7.27
*/
public class MainActivity extends Activity {
private final String TAG = "result";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
public void btnClick(View view){
String xmlData =
"<?xml version=\"1.0\" encoding=\"UTF-8\"?>" +
"<person>" +
" <teacher id=\"1\" >" +
" <name>wyg</name>" +
" </teacher>" +
" <teacher id=\"2\" name=\"sywyg\"></teacher>" +
"</person>";
parseXMLWithPULL(xmlData);
}
// 解析数据
public void parseXMLWithPULL(String xmlData) {
ArrayList<Teacher> listTeacher = new ArrayList<Teacher>();
XmlPullParserFactory factory = null;
XmlPullParser xpp = null;
//事件类型
int eventType = 0;
// xml文件位置
// String xmlName = "person.xml";
// 1. 创建PULL解析器
try {
// 1.1 获得XMLPULL工厂实例
factory = XmlPullParserFactory.newInstance();
// 1.2 通过工厂实例创建解析器
xpp = factory.newPullParser();
// 2. 设置xml文档数据
xpp.setInput(new StringReader(xmlData));
// 3. 开始解析数据
eventType = xpp.getEventType();
Teacher teacher = null;
while (eventType != XmlPullParser.END_DOCUMENT) {
String nodeName = xpp.getName();
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
Log.d(TAG,"Start document");
case XmlPullParser.START_TAG:
// 读取标签
if ("teacher".equals(nodeName)) {
teacher = new Teacher();
String id = xpp.getAttributeValue(0);
teacher.setId(Integer.parseInt(id));
} else if ("name".equals(nodeName)) {
teacher.setName(xpp.getText());
}
break;
case XmlPullParser.TEXT:
Log.d(TAG,"getText:" + xpp.getText());
break;
case XmlPullParser.END_TAG:
// 解析完某个节点
if("teacher".equals(nodeName)){
Log.d(TAG,teacher.toString());
}
break;
default:
Log.d(TAG,"end document ");
break;
}
eventType = xpp.next(); // 可能抛出IO异常
}
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
更过相关内容请参考Android API,如require(),nextText(),nextToken()等。
SAX解析
看完PULL方式解析,我们来看一下SAX方式解析。
SAX(Simple API for XML),可以方便的读取和操作XML数据。SAX解析方式也是基于事件处理数据流,在遇到相应的事件时,调用对应的方法处理事件。
SAX解析中主要有四种处理事件的接口:EntityResolver,DTDHandler,ContentHandler,ErrorHandler,而我们一般只需要继承DefaultHandler类即可,该类实现了上述四个接口。
在继承DefaultHandler类时,我们需要重写父类的几个监听事件的方法,如下:
public class MyXMLSAXHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {}
@Override
@Override
public void characters(char[] ch, int start, int length) throws SAXException {}
public void endElement(String uri, String localName, String qName) throws SAXException {}
@Override
public void endDocument() throws SAXException {}
}
根据方法名我们也能大体猜到每个方法的作用了:
startDocument()
在开始解析XML文档时被调用。startElement(String uri, String localName, String qName, Attributes attributes)
在开始解析某个标签时被调用。
参数分别为:1. uri:命名空间 2. localName:不带前缀的标签名(前缀一般是命名空间指定的) 3. qName:带前缀的标签名 4. attributes:保存属性集合,以此来获取属性值(有一系列的`getXXX()`方法可以获取相关信息)characters(char[] ch, int start, int length)
在获取标签内容时调用。
参数分别为:1. ch:读取到的标签内容字符数组 2. start:数组的起始位置 3. length:数组的长度endElement(String uri, String localName, String qName)
在结束标签时被调用。
参数和startElement()方法的前三个一样。endDocument()
文档解析完毕时调用。
解析步骤
为了通过SAX解析XML格式内容,我们需要完成以下内容:
- 创建XMLReader对象
- 创建XML事件处理器
- 通过XMLReader的
setContentHandler()和setErrorHandler()(该方法是可选方法)方法注册事件处理器,这样解析器就能够处理信息。 - 通过XMLReader的
parse()方法开始解析
代码如下:
public class MyXMLSAXHandler extends DefaultHandler {
private static String xmlData = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>"
+ "<person>"
+ "<teacher id=\"1\">"
+ "<name>wyg</name>wyg2"
+ "</teacher>"
+ "</person>";
private String id;
private StringBuilder name;
private String nodeName;
public static void main(String[] args) {
XMLReader reader = null;
try {
// 1. 创建XMLReader对象
// 这种方式是通过XMLReaderFactory的静态方法获取的动态对象。
reader = XMLReaderFactory.createXMLReader();
// 2. 创建XML事件处理器
ContentHandler handler = new MyXMLSAXHandler();
// 3. 注册事件处理器
reader.setContentHandler(handler);
//reader.setErrorHandler((ErrorHandler) handler);
// 4. 开始执行解析
reader.parse(new InputSource(new StringReader(xmlData)));
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void startDocument() throws SAXException {
name = new StringBuilder();
System.out.println("start Document");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
nodeName = localName;
if("teacher".equals(nodeName)){
// 清空换行符或回车
id = attributes.getValue(0).trim();
}
System.out.println("start Element");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if("name".equals(nodeName)){
name.append(ch, start, length);
//System.out.println(name);
}
System.out.println("start characters");
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if("teacher".equals(localName)){
System.out.println("id = " + id);
System.out.println("name = " + name);
// 将name值清空,方便再读取
name.setLength(0);
id = null;
}
// 避免characters()方法读取换行符
nodeName = null;
System.out.println("end Element");
}
@Override
public void endDocument() throws SAXException {
System.out.println("end Document");
}
}
注意:characters()该方法可能会在startElement()和endElement()之后都被调用,如:
<teacher id="1">
<name>wyg</name>wyg2
</teacher>
对于上面的xml,则读取完结束标签</name>之后因为后面还有字符串(对于换行符也是),因此还会调用characters()。调用过程可能会存在下列顺序startDocument()--->startElement()--->characters()--->endElement()--->characters()--->startElement()......--->endDocument()。因此,在我们读取数据时,需要判断好是开始标签还是结束标签,对于结束标签其调用characters()的话就不做任何处理(可以在endDocument()将标签设置为null,如上)。
下面我们看以下JSON数据。内容翻译自http://www.json.org/
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。
它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。
JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。
这些特性使JSON成为理想的数据交换语言。
JSON建构于两种结构:
- “名称/值”对的集合(A collection of name/value pairs)。
不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。对于java就是对象。 - 值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
这些都是常见的数据结构。事实上大部分现代计算机语言都以某种形式支持它们。这使得一种数据格式在同样基于这些结构的编程语言之间交换成为可能。
JSON具有以下这些形式:
对象是一个无序的“‘名称/值’对”集合。一个对象以“{”(左括号)开始,“}”(右括号)结束。每个“名称”后跟一个“:”(冒号);“‘名称/值’ 对”之间使用“,”(逗号)分隔。

例如:{"id":"5","name":"sywyg"}。
数组是值(value)的有序集合。一个数组以“[”(左中括号)开始,“]”(右中括号)结束。值之间使用“,”(逗号)分隔。

值(value)可以是双引号括起来的字符串(string)、数值(number)、true、false、 null、对象(object)或者数组(array),这些结构可以嵌套。
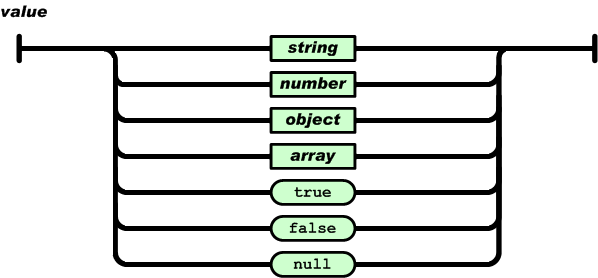
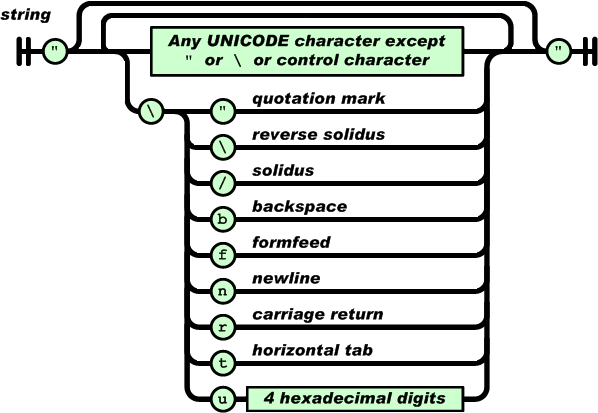
字符串(string)是由双引号包围的任意数量Unicode字符的集合,使用反斜线转义。一个字符(character)即一个单独的字符串(character string)。
字符串(string)与C或者Java的字符串非常相似。
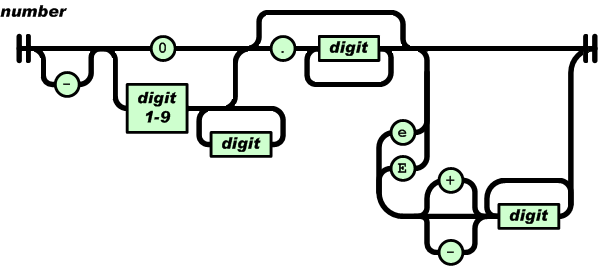
数值(number)也与C或者Java的数值非常相似。除去未曾使用的八进制与十六进制格式。除去一些编码细节。
下面介绍一下Android中解析JSON,主要介绍两种:JSONObject,和谷歌的开源库GSON。
首先介绍了一下JSONObject
JSONObject
使用JSONObject会涉及到以下几个类:
- JSONArray
- JSONObject
- JSONStringer
- JSONTokener
注意这四个类都是线程不安全的,且其它类不应该继承这些类。
JSONArray
一组有序的值,值可能是:JSONObject/JSONArray/String/Integer/Long/Double/NULL/null
注意:在两种情况下可能是null:java中的null值和获取失败时的。JSONObject.NULL不是。
在该类中,提供了很多getXXX(int index)/optXXX(int index)可以通过索引获得到该对象中的各种值(可以先通过isNull(int)判断是否存在值再获得)。
putXXX()方法用来添加或者替换其中的值(构建JSON数据),该方法返回自己的对象。
JSONObject
该类是用来处理json中对象的,对象名是唯一并且非空的字符串。值可能是:JSONObject/JSONArray/String/Integer/Long/Double/NULL。
该类可以将值强制转换成另外的类型:
- 当请求类型是boolean时,字符串会转换成“true”/“false”;
- 当请求类型为double时,字符串将通过Double的
valueOf(String)转换成double。 - 当请求类型为int/long时,字符串将通过Double的
valueOf(String)转换成double,然后再转换成int/long。 - 当请求类型是String时,其它非null值将会通过String的
valueOf(Object)转换成String类型,null也会被转换成“null”。
JSONStringer
实现了JSONObject和JSONArray的toString(),可以通过该类构建JSON字符串,即
JSONObject和JSONArray的toString()源码实现是由JSONStringer实现的。
该类只能解析标准格式的JSON字符串,特别是下面要求:
- 必须有一个顶层的数组或对象。
- 对应的方法调用必须配对,
array()必须和endArray(),object()必须和endObject()。 - 数组可能不包含keys。
- 对象必须包含可选的keys和值。
注意调用非格式JSON字符串将会抛出JSONException异常,该类没有提供缩进输出,需要缩进输出的话
使用JSONObject和JSONArray的toString()。
JSONTokener
JSON文本解析类,大部分应用只是用下列方式:
String json = "{"
+ " \"query\": \"Pizza\", "
+ " \"locations\": [ 94043, 90210 ] "
+ "}";
JSONObject object = (JSONObject) new JSONTokener(json).nextValue();
String query = object.getString("query");
JSONArray locations = object.getJSONArray("locations");
对于下面的语法错误将会忽略:
\/\/或#开始,换行符。\/\*。- 不正确的字符串。
- 前缀是0x或0X。
- 前缀是0。
- 数组元素使用
:分割。 - 使用
=,=>,;分割属性。
下面介绍一下Gson
Gson
Gson是Google提供的用来在java对象和JSON数据之间进行映射的java类库。可以将一个JSON字符串转成一个java对象,
也可以将java对象转换成JSON字符串。
java数组/对象转换成JSON字符串
从java数组/对象转换成JSON字符串可以通过Gson的toJson()方法,例如:
Gson gson = new Gson();
String[] strings = {"sywyg", "wyg"};
String JsonStrings = gson.toJson(strings);
其中,toJson()的参数可以为数组/list/set,在list/set中就可以设置相应的对象。
JSON字符串转换成java数组/对象
Gson提供了fromJson()方法来实现从JSON字符串到java数组/对象。该方法接收两个参数
第一个参数为JSON字符串,第二个参数为对象类/数组/list/set。
json和xml比较
1.JSON和XML的数据可读性基本相同
2.JSON和XML同样拥有丰富的解析手段
3.JSON相对于XML来讲,数据的体积小,网络传输节省流量
4.JSON与JavaScript的交互更加方便
5.JSON对数据的描述性比XML较差
6.JSON的速度要远远快于XML















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









