







一:介绍
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,是完全由java开发的一个开源的任务日程管理系统,“任务进度管理器”就是一个在预先确定(被纳入日程)的时间到达时,负责执行(或者通知)其他软件组件的系统。
Quartz用一个小Java库发布文件(.jar文件),这个库文件包含了所有Quartz核心功能。这些功能的主要接口(API)是Scheduler接口。它提供了简单的操作,例如:将任务纳入日程或者从日程中取消,开始/停止/暂停日程进度。
二:quartz核心概念
先来看一张图:
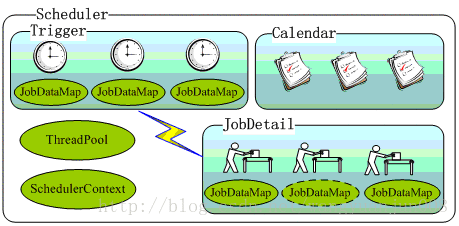
Job( 任务,即被调度的任务):要由表示要执行的“作业”的类实现的接口。只有一个方法 void execute(jobExecutionContext context) (jobExecutionContext 提供调度上下文各种信息,运行时数据保存在jobDataMap中) Job有个子接口StatefulJob ,代表有状态任务。
JobDetail:Quartz在每次执行Job时,都重新创建一个Job实例,所以它不直接接受一个Job的实例,相反它接收一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。因此需要通过一个类来描述Job的实现类及其它相关的静态信息,如Job名字、描述、关联监听器等信息,JobDetail承担了这一角色。
传递给定作业实例的详细信息属性。 JobDetails将使用JobBuilder创建/定义。Trigger(触发器):用于定义任务调度时间规则。是一个类,描述触发Job执行的时间触发规则。使用TriggerBuilder实例化实际触发器。主要有SimpleTrigger和CronTrigger这两个子类。当仅需触发一次或者以固定时间间隔周期执行,SimpleTrigger是最适合的选择;而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如每早晨9:00执行,周一、周三、周五下午5:00执行等;
Calendar:org.quartz.Calendar和java.util.Calendar不同,它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。一个Trigger可以和多个Calendar关联,以便排除或包含某些时间点。假设,我们安排每周星期一早上10:00执行任务,但是如果碰到法定的节日,任务则不执行,这时就需要在Trigger触发机制的基础上使用Calendar进行定点排除。
Scheduler(任务调度器):这是Quartz Scheduler的主要接口,代表一个Quartz的独立运行容器,Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义了多个接口方法,允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
一旦注册,调度程序负责执行作业,当他们的相关联的触发器触发(当他们的预定时间到达时)。QuartzSchedulerThread :负责执行向QuartzScheduler注册的触发Trigger的工作的线程。
ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提供运行效率。
QuartzSchedulerResources:包含创建QuartzScheduler实例所需的所有资源(JobStore,ThreadPool等)。
SchedulerFactory( 调度程序工厂) :提供用于获取调度程序实例的客户端可用句柄的机制。
JobStore: 通过类实现的接口,这些类要为org.quartz.core.QuartzScheduler的使用提供一个org.quartz.Job和org.quartz.Trigger存储机制。作业和触发器的存储应该以其名称和组的组合为唯一性。
QuartzScheduler :这是Quartz的核心,它是org.quartz.Scheduler接口的间接实现,包含调度org.quartz.Jobs,注册org.quartz.JobListener实例等的方法。
三:Quartz中的设计模式
- Builder模式
所有关键组件都有Builder模式来构建 如:JobBuilder、TriggerBuilder - Factory模式
最终由Scheduler的来进行组合各种组件 如SchedulerFactory - 组件模式
Quartz项目中大量使用组件模式,插件式设计,可插拔,耦合性低,易扩展,开发者可自行定义自己的Job、Trigger等组件 - 链式写法
Quartz中大量使用链式写法,与jQuery的写法有几分相似,实现也比较简单,如:
$(this).addClass(“divCurrColor”).next(“.divContent”).css(“display”,”block”);
newTrigger().withIdentity( “trigger3”, “group1”).startAt( startTime)
.withSchedule(simpleSchedule().withIntervalInSeconds(10).withRepeatCount(10)).build();
四:Quartz体系结构
三大核心
- 调度器
- 任务
- 触发器
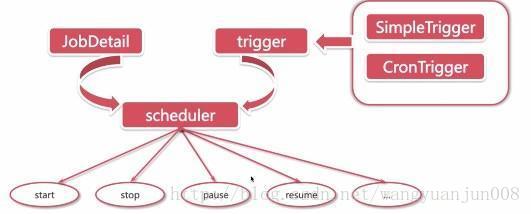
重要组成
1)任务:
- Job:表示一个工作,要执行的具体内容。此接口中只有一个方法。要创建一个任务,必须得实现这个接口。该接口只有一个execute方法,任务每次被调用的时候都会执行这个execute方法的逻辑,类似TimerTask的run方法,在里面编写业务逻辑。
public class TestJob implements Job {
/**把要执行的操作,写在execute方法中 */
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
System.out.println("I can do something...");
System.out.println(sdf.format(new Date()));
}
}生命周期:在每次调度器执行job时,它在调用execute方法前会创建一个新的job实例,当调用完成之后,关联的job对象实例会被释放,释放的实例会被垃圾回收机制回收。
- JobBuilder:可向任务传递数据,通常情况下,我们使用它就可向任务类发送数据了,如有特别复杂的传递参数,它提供了一个传递递:JobDataMap对象的方法
JobDetail jobDetail = JobBuilder.newJob(TestJob.class).withIdentity("testJob","group1").build();
- JobDetail:用来保存我们任务的详细信息。一个JobDetail可以有多个Trigger,但是一个Trigger只能对应一个JobDetail。下面是JobDetail的一些常用的属性和含义:
JobStore:负责跟踪所有你给scheduler的“工作数据”:jobs, triggers, calendars, 等。
- RAMJobStore:是使用最简单的也是最高效(依据CPU时间)的JobStore 。RAMJobStore 正如它名字描述的一样,它保存数据在RAM。缺点是你的应用结束之后所有的数据也丢失了–这意味着RAMJobStore 不具有保持job和trigger持久的能力。对于一些程序是可以接受的,甚至是期望的,但对于其他的程序可能是灾难性的。使用RAMJobStore配置Quartz:配置如下

org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore:是使用最简单的也是最高效2. JDBCJobStore:以JDBC的方式保存数据在数据库中。它比RAMJobStore的配置复杂一点,也没有RAMJobStore快。然而,性能缺点不是糟透了,特别是如果你在数据库表主键上建立了索引。在机器之间的LAN(在scheduler 和数据库之间)合理的情况下,检索和更新一个被触发的Trigger花费的时间少于10毫秒。几乎适用于所有的数据库,广泛用于 Oracle。PostgreSQL, MySQL, MS SQLServer, HSQLDB, 和DB2。使用JDBCJobStore之前你必须首先创建一系列Quartz要使用的表。你可以发现表创建语句在Quartz发布目录的 “docs/dbTables”下面。你需要确定你的应用要使用的事务类型。如果你不想绑定调度命令(例如增加和移除Trigger)到其他的事务,你可以使用JobStoreTX (最常用的选择)作为你的Jobstore。如果你需要Quartz和其他的事务(例如在J2EE应用服务器中)一起工作,你应该使用JobStoreCMT ,Quartz 将让应用服务器容器管理这个事务。使用JobStoreTx配置Quartz:
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#配置表的前缀
org.quartz.jobStore.tablePrefix = QRTZ_
#使用JNDI数据源的时候,数据源的名字
org.quartz.jobStore.dataSource = myDS3. TerracottaJobStore:提供了一个方法:在不使用数据库的情况下使它具有收缩性和强壮性。可以是集群的也可以是非集群的,在这两种情况下为你的job数据提供了一个存储机制用于应用程序重启之间持久,因为数据是存储在Terracotta服务器。它的性能比使用数据库访问JDBCJobStore好一点儿(大约是一个数量级),但是明显比RAMJobStore慢。使用TerracottaJobStore配置Quartz:
org.quartz.jobStore.class = org.terracotta.quartz.TerracottaJobStore
org.quartz.jobStore.tcConfigUrl = localhost:9510- JobDataMap:中可以包含不限量的(序列化的)数据对象,在job实例执行的时候,可以使用其中的数据;JobDataMap是Java Map接口的一个实现,额外增加了一些便于存取基本类型的数据的方法。
- 存:
JobDetail jobDetail = JobBuilder.newJob(TestJob.class).withIdentity("testJob","group1").usingJobData("date1","存内容").build();2. 取:
public class TestJob implements Job {
/**把要执行的操作,写在execute方法中 */
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
JobKey key = jobExecutionContext.getJobDetail().getKey();
JobDataMap jobDataMap = jobExecutionContext.getJobDetail().getJobDataMap();
String date1 = jobDataMap.getString("date1");
}
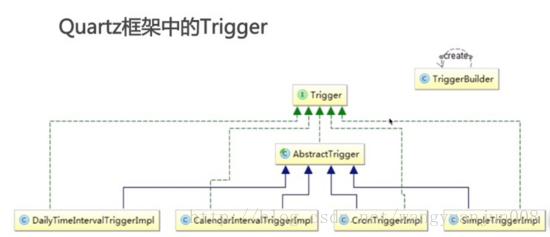
}2)触发器:用来触发执行Job
2.1)触发器通用属性:
- Jobkey:表示job实例的标识,触发器被触发时,该指定的job实例会被执行
- StartTime:表示触发器的时间表首次被触发的时间,它的值类型为:java.util.Date
- EndTime:指定触发器的不再被触发的时间,它的值类型为:java.util.Date
2.2)触发器类型:
- SimpleTrigger: 主要是针对一些相对简单的时间触发进行配置使用,比如在指定的时间开始然后在一定的时间间隔之内重复执行一个Job,同时可以任意指定重复的次数。用来触发只需执行一次或者在给定时间触发并且重复N次且每次执行延迟一定时间的任务。 下面就是使用一个SimpleTrigger的例子:
//创建触发器 每3秒钟执行一次(无开始时间和结束时间)
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group3")
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(3).repeatForever()).build();
//创建触发器 每3秒钟执行一次(有开始时间和结束时间)
long now = new Date().getTime();
Date start = new Date(now+6000);
Date end = new Date(now+12000);
//创建触发器 每3秒钟执行一次
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group3")
.startAt(start)
.endAt(end)
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(3).repeatForever()).build();SimpleTrigger具有丰富的构造函数,根据业务需求构造不同的构造函数。
- CronTrigger: 可以配置更复杂的触发时刻表,基于日历的作业触发器,而不像SimpleTrigger那样精确指定间隔时间,按照日历触发,例如“每个周五”,每个月10日中午或者10:15分。比SimpleTrigger更加常用。
Cron表达式:用于配置CronTrigger实例,是由7个表达式组成的字符串,描述了时间表的详细信息。
格式为:[秒][分][时][日][月][周][年]
Cron表达式特殊字符意义对应表:
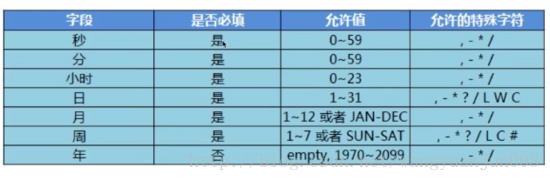
通配符说明:
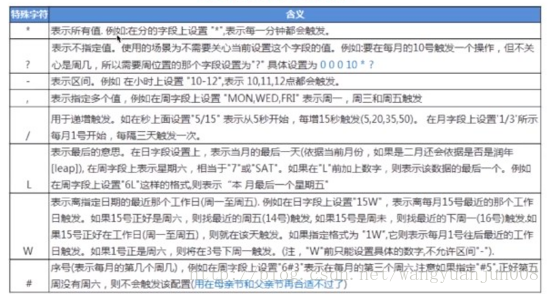
Cron表达式例子:
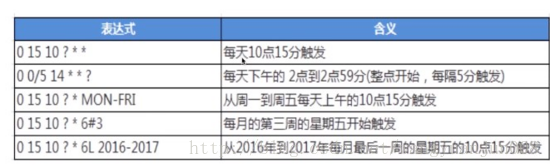
TriggerBuilder.newTrigger().withIdentity("trigger2","group2").withSchedule(CronScheduleBuilder.cronSchedule("0 0 9 ? * 6L *")).build();
Cron表达式小技巧:
‘L’和‘W’可以一起组合使用
周字段英文字母不区分大小写即MOM与mom相同
利用工具,在线生成cron表达式:cron.qqe2.com/
NthIncludedDayTrigger:是 Quartz 开发团队最新加入到框架中的一个 Trigger。它设计用于在每一间隔类型的第几天执行 Job。例如,你要在每个月的 15 号执行开票的 Job,用 NthIncludedDayTrigger就再合适不过了。
NthIncludedDayTrigger trigger = new NthIncludedDayTrigger("NthIncludedDayTrigger",Scheduler.DEFAULT_GROUP);
trigger.setN(15);
trigger.setIntervalType(NthIncludedDayTrigger.INTERVAL_TYPE_MONTHLY);3)调度器Scheduler
代表一个Quartz的独立运行容器,Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义了多个接口方法,允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
Scheduler可以将Trigger绑定到某一JobDetail中,这样当Trigger触发时,对应的Job就被执行。一个Job可以对应多个Trigger,但一个Trigger只能对应一个Job。
可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内的信息。SchedulerContext内部通过一个Map,以键值对的方式维护这些上下文数据,SchedulerContext为保存和获取数据提供了多个put()和getXxx()的方法。可以通过Scheduler# getContext()获取对应的SchedulerContext实例;
SchedulerFactory schedulerfactory=new StdSchedulerFactory();
Scheduler scheduler = schedulerfactory.getScheduler();
DirectSchedulerFactory factory = DirectSchedulerFactory.getInstance();
try {
Scheduler scheduler = factory.getScheduler();
} catch (SchedulerException e) {
e.printStackTrace();
}4)SchedulerFactory:
- 使用一组参数(java.util.Properties)来创建和出书啊Quartz调度器
- 配置参数一般存储在quartz.properties中
- 调用getScheduler方法就能创建和初始化调度器
5)quartz.properties:
Quartz-Job的quartz.properties配置文件说明,此文件在quartz的jar包有,可直接拿过来使用不过只有基本的几个配置 自己可根据需要进行扩充;另外如果项目中没有对该配置文件重写,则Quartz会加载自己jar包中的quartz.properties文件。
# Default Properties file for use by StdSchedulerFactory
# to create a Quartz Scheduler Instance, if a different
# properties file is not explicitly specified.
#
# ===========================================================================
# Configure Main Scheduler Properties 调度器属性
# ===========================================================================
org.quartz.scheduler.instanceName: DefaultQuartzScheduler
#org.quartz.scheduler.instanceid:AUTO
org.quartz.scheduler.rmi.export: false
org.quartz.scheduler.rmi.proxy: false
org.quartz.scheduler.wrapJobExecutionInUserTransaction: false
# ===========================================================================
# Configure ThreadPool 线程池属性
# ===========================================================================
#线程池的实现类(一般使用SimpleThreadPool即可满足几乎所有用户的需求)
org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
#指定线程数,至少为1(无默认值)(一般设置为1-100直接的整数合适)
org.quartz.threadPool.threadCount: 10
#设置线程的优先级(最大为java.lang.Thread.MAX_PRIORITY 10,最小为Thread.MIN_PRIORITY 1,默认为5)
org.quartz.threadPool.threadPriority: 5
#设置SimpleThreadPool的一些属性
#设置是否为守护线程
#org.quartz.threadpool.makethreadsdaemons = false
#org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
#org.quartz.threadpool.threadsinheritgroupofinitializingthread=false
#线程前缀默认值是:[Scheduler Name]_Worker
#org.quartz.threadpool.threadnameprefix=swhJobThead;
# 配置全局监听(TriggerListener,JobListener) 则应用程序可以接收和执行 预定的事件通知
# ===========================================================================
# Configuring a Global TriggerListener 配置全局的Trigger监听器
# MyTriggerListenerClass 类必须有一个无参数的构造函数,和 属性的set方法,目前2.2.x只支持原始数据类型的值(包括字符串)
# ===========================================================================
#org.quartz.triggerListener.NAME.class = com.swh.MyTriggerListenerClass
#org.quartz.triggerListener.NAME.propName = propValue
#org.quartz.triggerListener.NAME.prop2Name = prop2Value
# ===========================================================================
# Configuring a Global JobListener 配置全局的Job监听器
# MyJobListenerClass 类必须有一个无参数的构造函数,和 属性的set方法,目前2.2.x只支持原始数据类型的值(包括字符串)
# ===========================================================================
#org.quartz.jobListener.NAME.class = com.swh.MyJobListenerClass
#org.quartz.jobListener.NAME.propName = propValue
#org.quartz.jobListener.NAME.prop2Name = prop2Value
# ===========================================================================
# Configure JobStore 存储调度信息(工作,触发器和日历等)
# ===========================================================================
# 信息保存时间 默认值60秒
org.quartz.jobStore.misfireThreshold: 60000
#保存job和Trigger的状态信息到内存中的类
org.quartz.jobStore.class: org.quartz.simpl.RAMJobStore
# ===========================================================================
# Configure SchedulerPlugins 插件属性 配置
# ===========================================================================
# 自定义插件
#org.quartz.plugin.NAME.class = com.swh.MyPluginClass
#org.quartz.plugin.NAME.propName = propValue
#org.quartz.plugin.NAME.prop2Name = prop2Value
#配置trigger执行历史日志(可以看到类的文档和参数列表)
org.quartz.plugin.triggHistory.class = org.quartz.plugins.history.LoggingTriggerHistoryPlugin
org.quartz.plugin.triggHistory.triggerFiredMessage = Trigger {1}.{0} fired job {6}.{5} at: {4, date, HH:mm:ss MM/dd/yyyy}
org.quartz.plugin.triggHistory.triggerCompleteMessage = Trigger {1}.{0} completed firing job {6}.{5} at {4, date, HH:mm:ss MM/dd/yyyy} with resulting trigger instruction code: {9}
#配置job调度插件 quartz_jobs(jobs and triggers内容)的XML文档
#加载 Job 和 Trigger 信息的类 (1.8之前用:org.quartz.plugins.xml.JobInitializationPlugin)
org.quartz.plugin.jobInitializer.class = org.quartz.plugins.xml.XMLSchedulingDataProcessorPlugin
#指定存放调度器(Job 和 Trigger)信息的xml文件,默认是classpath下quartz_jobs.xml
org.quartz.plugin.jobInitializer.fileNames = my_quartz_job2.xml
#org.quartz.plugin.jobInitializer.overWriteExistingJobs = false
org.quartz.plugin.jobInitializer.failOnFileNotFound = true
#自动扫描任务单并发现改动的时间间隔,单位为秒
org.quartz.plugin.jobInitializer.scanInterval = 10
#覆盖任务调度器中同名的jobDetail,避免只修改了CronExpression所造成的不能重新生效情况
org.quartz.plugin.jobInitializer.wrapInUserTransaction = false
# ===========================================================================
# Sample configuration of ShutdownHookPlugin ShutdownHookPlugin插件的配置样例
# ===========================================================================
#org.quartz.plugin.shutdownhook.class = \org.quartz.plugins.management.ShutdownHookPlugin
#org.quartz.plugin.shutdownhook.cleanShutdown = true
#
# Configure RMI Settings 远程服务调用配置
#
#如果你想quartz-scheduler出口本身通过RMI作为服务器,然后设置“出口”标志true(默认值为false)。
#org.quartz.scheduler.rmi.export = false
#主机上rmi注册表(默认值localhost)
#org.quartz.scheduler.rmi.registryhost = localhost
#注册监听端口号(默认值1099)
#org.quartz.scheduler.rmi.registryport = 1099
#创建rmi注册,false/never:如果你已经有一个在运行或不想进行创建注册
# true/as_needed:第一次尝试使用现有的注册,然后再回来进行创建
# always:先进行创建一个注册,然后再使用回来使用注册
#org.quartz.scheduler.rmi.createregistry = never
#Quartz Scheduler服务端端口,默认是随机分配RMI注册表
#org.quartz.scheduler.rmi.serverport = 1098
#true:链接远程服务调度(客户端),这个也要指定registryhost和registryport,默认为false
# 如果export和proxy同时指定为true,则export的设置将被忽略
#org.quartz.scheduler.rmi.proxy = false 五:存储方式
RAMJobStore:
优点:不要外部数据库,配置容易,运行速度快
缺点:因为调度程序信息是存储在被分配给JVM的内存里面,所以,当应用程序停止运行时,所有调度信息将被丢失。另外因为存储到JVM内存里面,所以可以存储多少个Job和Trigger将会受到限制
JDBCJobStore:
优点:支持集群,因为所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务
缺点:运行速度的快慢取决与连接数据库的快慢
表关系和解释
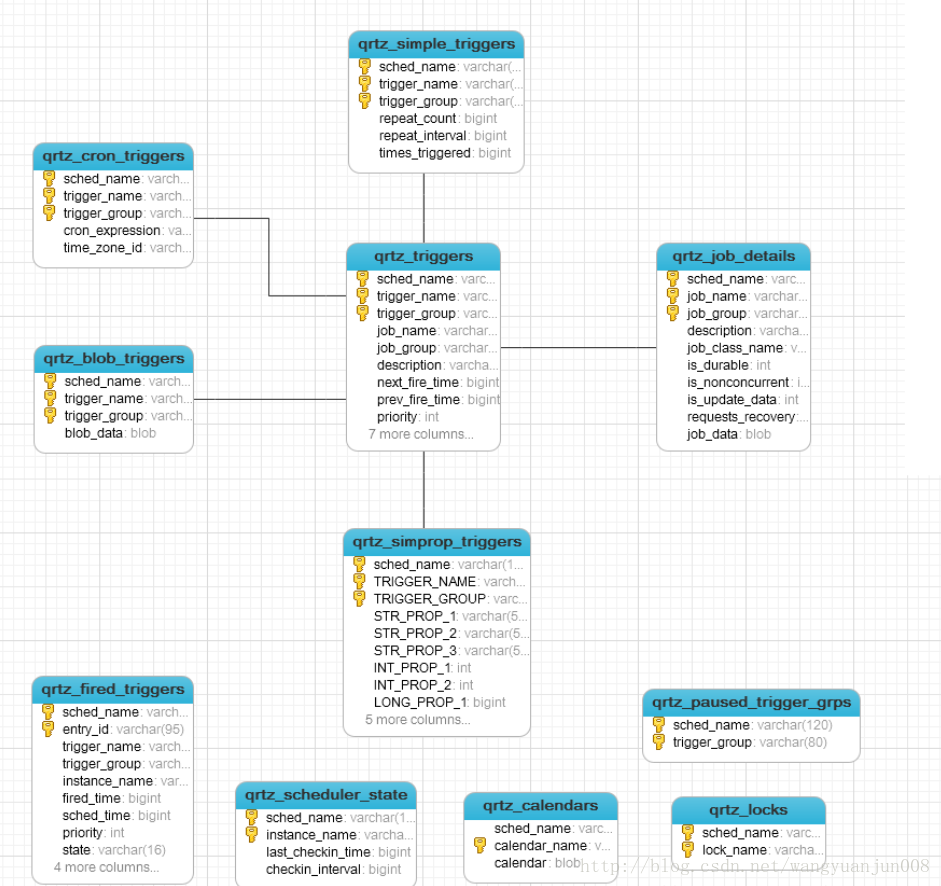
| Tables | Means |
|---|---|
| qrtz_blob_triggers | Trigger作为Blob类型存储(用于Quartz用户用JDBC创建他们自己定制的Trigger类型,JobStore 并不知道如何存储实例的时候) |
| qrtz_calendars | 以Blob类型存储Quartz的Calendar日历信息, quartz可配置一个日历来指定一个时间范围 |
| qrtz_cron_triggers | 存储Cron Trigger,包括Cron表达式和时区信息。 |
| qrtz_fired_triggers | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| qrtz_job_details | 存储每一个已配置的Job的详细信息 |
| qrtz_locks | 存储程序的非观锁的信息(假如使用了悲观锁) |
| qrtz_paused_trigger_graps | 存储已暂停的Trigger组的信息 |
| qrtz_scheduler_state | 存储少量的有关 Scheduler的状态信息,和别的 Scheduler 实例(假如是用于一个集群中) |
| qrtz_simple_triggers | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| qrtz_triggers | 存储已配置的 Trigger的信息 |
| qrzt_simprop_triggers |
思想
// 1、工厂模式 构建Scheduler的Factory,其中STD为Quartz默认的Factory
// 开发者亦可自行实现自己的Factory;Job、Trigger等组件
SchedulerFactory sf = new StdSchedulerFactory();
// 2、通过SchedulerFactory构建Scheduler对象
Scheduler sched = sf.getScheduler();
// 3、org.quartz.DateBuilder.evenMinuteDate -- 通过DateBuilder构建Date
Date runTime = evenMinuteDate( new Date());
// 4、org.quartz.JobBuilder.newJob <下一分钟> --通过JobBuilder构建Job
JobDetail job = newJob(HelloJob.class).withIdentity("job1","group1").build();
// 5、通过TriggerBuilder进行构建Trigger
Trigger trigger = newTrigger().withIdentity("trigger1","group1")
.startAt(runTime).build();
// 6、工厂模式,组装各个组件<JOB,Trigger>
sched.scheduleJob (job, trigger);
// 7、start
sched.start();
try {
Thread.sleep(65L * 1000L);
} catch (Exception e) {
}
// 8、通过Scheduler销毁内置的Trigger和Job
sched.shutdown(true);
一句话看懂Quartz
- 创建调度工厂(); //工厂模式
- 根据工厂取得调度器实例(); //工厂模式
- Builder模式构建子组件















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









