







 本文详细介绍了如何在虚拟机中安装和配置Hadoop,包括VMware的下载与安装、CentOS7虚拟机的建立、网络配置、免密登陆、JDK安装、Hadoop的下载与配置,以及最终的三节点配置,确保实现真分布式环境。
本文详细介绍了如何在虚拟机中安装和配置Hadoop,包括VMware的下载与安装、CentOS7虚拟机的建立、网络配置、免密登陆、JDK安装、Hadoop的下载与配置,以及最终的三节点配置,确保实现真分布式环境。
hadoop的安装和配置
1.虚拟机下载:
(1)首先我们先进入VMware官网,下载VMware fusion,VMware fusion如下图所示:

(2)根据操作系统选择合适的产品,在这里以max系统为例,如下图所示:

(3)打开.dmg文件,开始安装:

(4)安装位置默认在管理员文件夹下,安装路径尽量不要有中文
(5)安装成功后,第一次运行程序会要求输入密钥,这个可以自己百度,下面分享我搜集的密钥:
7HYY8-Z8WWY-F1MAN-ECKNY-LUXYX
FF590-2DX83-M81LZ-XDM7E-MKUT4
FF31K-AHZD1-H8ETZ-8WWEZ-WUUVA
CV7T2-6WY5Q-48EWP-ZXY7X-QGUWD
AALYG-20HVE-WHQ13-67MUP-XVMF3
2.虚拟机安装:
(1)下载centos7的iso镜像:

(2)点击自定虚拟机:

(3)选择想要安装的linux系统:

(4)设置虚拟机的名字:

(5)点击CD/DVD(IDE)设置:

(7)点击install CentOs 7:

(8)时间改成当前真实电脑的时间:

(9)软件选择GNOME桌面:

(10)设置root的密码:

(11)然后等待安装就好了:

3.虚拟机配置:
(1)先配置网络联通,在图形界面中,打开网络连接的有线设置->齿轮->ipv4->地址选择手动,填写网络信息,最后重启网络service network restart就可以了:


(2)使我所创建的普通用户获得管理员权限,操作方法如下: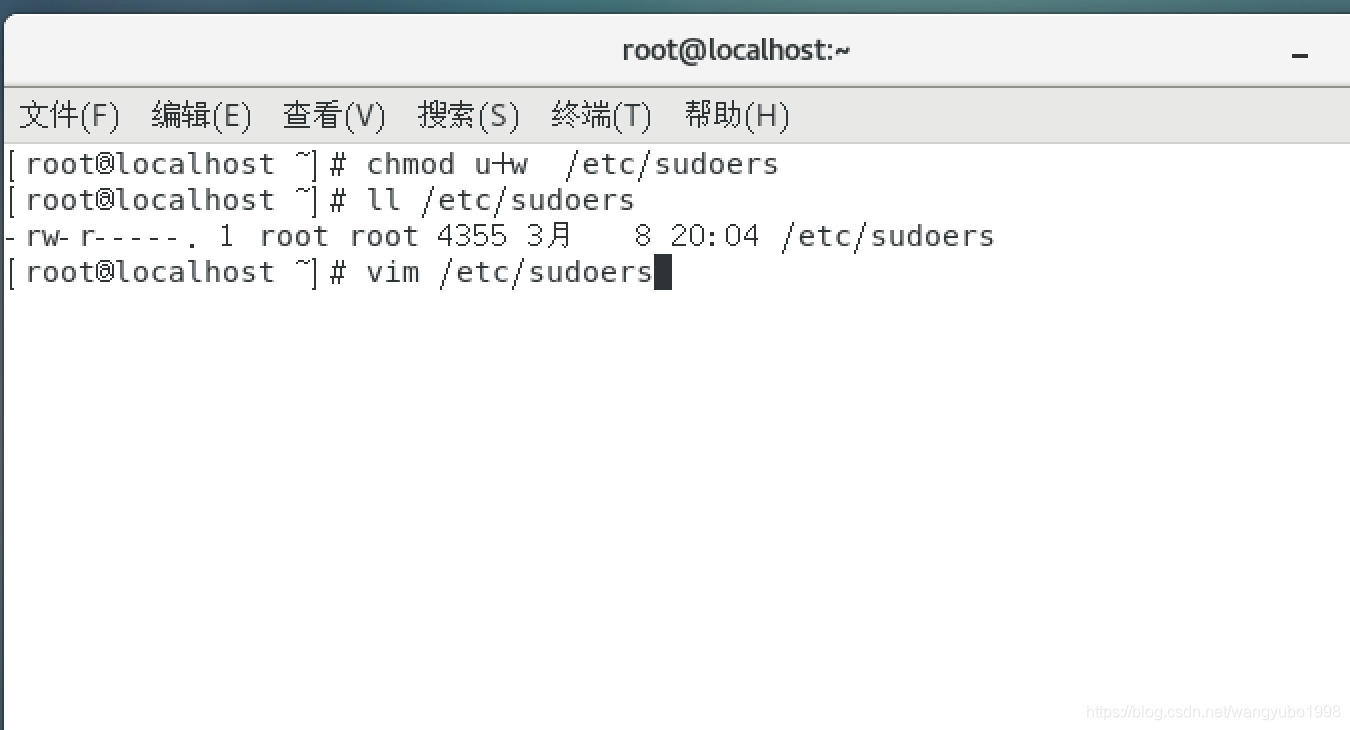
(1)首先先切换到管理员用户;
(2)修改sudoers文件的权限,通过指令chmod u+w /etc/sudoers,把其修改为管理员可读;
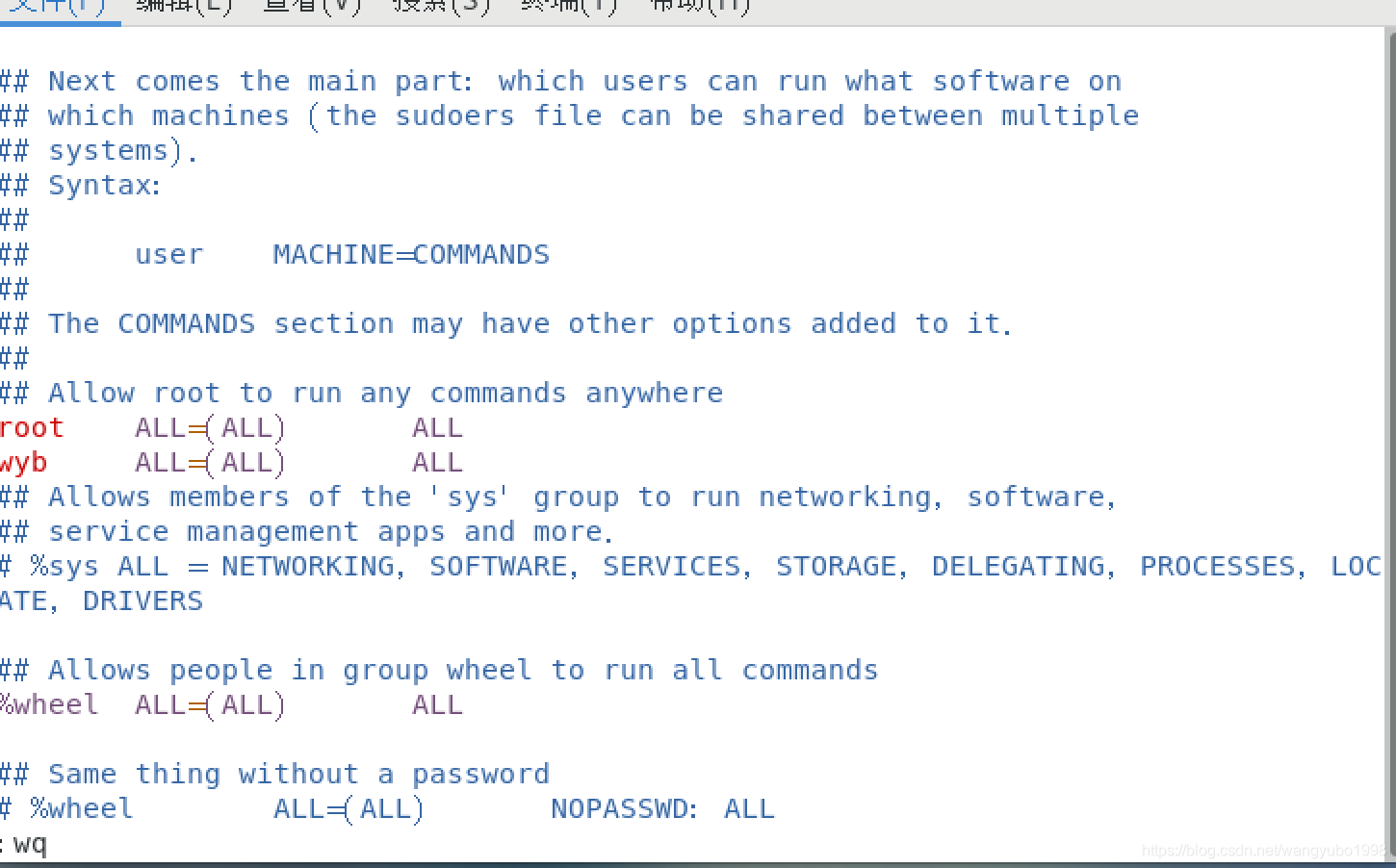
(3)查看vim /etc/sudoers并复制第98行:root ALL=(ALL) ALL 在第99行复制并更改用户名:wyb(改成自己的用户名) ALL=(ALL) ALL
(4)被认可的用户使用特权命令时,需要在特权命令前加上sudo
(3)关闭防火墙,这样我们就可以在多个节点之间传递信息和相互合作:
首先,先查看防火墙状态systemctl status firewalld.service,如果是active,就调用关闭防火墙指令来关闭systemctl strop firewalld.service,但需要注意的是下次开机,可能防火墙会再次打开,这是我们可以关闭服务启动项列表systemctl list-unit-files中的防火墙设置,使其不会开机自动启动systemctl disable firewalld.service。





4.免密登陆:
首先,我们需要设置公私钥,相当于生成两把钥匙,一把公钥匙,一把私钥匙,使外界可以给本机发送信息等,且可以保证其安全,这样,我们就需要想通过命令cp id_rsa.pub authorized_keys使其生成,但是需要注意,我们的ssh协议不认识id_rsa.pub这个名字,我们需要复制她,并给他重起名,这样我们就可以远程登录了,这里我用的是苹果系统自跟的远程连接:





5.jdk安装:
首先,我们需要在官网上下载jdk文件,并复制到用户目录wyb下,在此目录下新建java目录,并通过mv命令将安装包移动到该目录下并通过命令tar -xzvf file.tar.gz解压,解压后为了方便后期操作,将解压后目录名重命名为jdk(使用mv改名),接着我们打开并编辑用户目录下的.\bashrc文件vim ~/.bashrc
在正文的后面添加以下内容
Export JAVA_HOME=/home/wyb/java/jdk
Export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
然后保存退出,让该文件立即生效source ~/.bashrc,然后我们可以卸载已有jdk
通过命令rpm -qa |grep jdk查询已安装包名中包含jdk版本,然后rpm -e 包名 --nodeps,使用java -version命令验证,如果显示版本号与安装版本号相同,则证明安装成功了









6.hadoop安装:
首先我们需要上hadoop官网,下载以tar.gz结尾 的hadoop安装包,然后将hadoop安装包复制到用户目录下,如csdn目录下,接着我们新建一个名为hadoop的目录,将此压缩安装包移动到该目录下用命令tar -xzvf进行解压(注意在命令后面加上文件名,若不是在当前文件夹下,需写清楚完整路径名),我们将解压完成后的目录(hadoop-2.6.5)改名为hadoop(为了方便),然后将hadoop根目录下的bin目录和sbin目录路径加入到PATH中,具体为如下更改,在用户目录中的隐藏文件.bashrc中,添加如下内容
export HADOOP_HOME=/home/wyb/hadoop/hadoop
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin: H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin,首先先添加hadoop的home 目录,然后通过简介引用其home路径,吧其下bin和sbin加入path中,但请注意,我们修改的仅仅是用户目录的配置,真正的全局变量我们并未修改,这样是为了安全考虑,改完之后,执行source命令令其立即生效,然后输入hadoop version命令,验证是否安装成功:






7.hadoop配置:
首先我们在$HADOOP_HOME/etc/hadoop/目录下找到以下文件并修改其中的内容,进行hadoop配置
export JAVA_HOME=/home/wyb/java/jdk
(2)yarn-env.sh
export JAVA_HOME=/home/wyb/java/jdk
(3)core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wyb/hadoop/hadoop/tmp</value>
</property>
(4)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yumoyao/hadoop/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/yumoyao/hadoop/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(5)mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<configuration>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</configuration>
(6)yarn-site.xml
<property>
<name>yarn.resourcemanager.address</name>
<value>node-1:8032</value>
</property>
8.hadoop三节点配置:
首先我们需要先通过链接克隆,得到两个新的虚拟机,分别为node-1和node-2,然后我们再通过相关的配置,来得到真分布的hadoop:
(1)首先,我们把node-2和node-3的 /etc/hostname文件的内容,分别将其主机名改为n改为node-2和node-3,通过这步操作,我们就可以在控制台很好的区分这三个节点,而不是默认的localhost。
(2)设置node-1,node-2和node-3的 /etc/hosts文件的内容,全部都加上三个node对应的IP与机器名的映射关系,这样以后,就可以用三个节点的机器名来代替IP进行使用了。
比如,以我的电脑为例:
172.16.236.210 node-1
172.16.236.220 node-2
172.16.236.230 node-3
(3)在node-1,node-2和node-3的 /home/wyb/hadoop/hadoop/etc/hadoop/slaves 文件中记录集群中数据节点的IP,每行一个IP,可用IP映射的机器名替代。
node-2
node-3
(4)为了支持hadoop,我们创建公私钥对,存于平台中,供整个集群共享,让node-1,node-2和node-3之间可以相互免密登陆,这样NameNode可以使用SSH无密码登陆并启动DataName进程,同样,DataNode上也能使用SSH无密码登陆NameNode。
首先,我们先把node-2和node-3里原有的 ~/.ssh文件删除,然后在当前的node-1和node-2目录下通过命令生成公私钥。
ssh-keygen -t rsa
接着,我们分别进入node-2和node-3的 ~/.ssh 文件夹,然后把node-2和node-3的公钥复制一份给node-1,然后可以另外起名为n2和n3。
scp id_rsa.pub node-1://home/wyb/.ssh
然后我们吧这三个公钥合成一个公钥,并更名为authorized_keys
cat id_rsa.pub n2 n3 > authorized_keys
最后,我们把这个文件分别和node-2和node-3各复制一份.
scp authorized_keys node-2://home/wyb/.ssh
scp authorized_keys node-3://home/wyb/.ssh
(5)最后,我们可以先格式化hadoop,接着再开启它,并且在node-1中启动集群,并查看节点id,检查是否成功,如果在node-1中观察到

在node-2和node-3中看到

以下内容,则证明成功。
格式化:
hadoop namenode -format
启动
start-all.sh
查看
jps















 6227
6227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









