







前言
最近在看到不少框架里面使用到了LongAdder这个类,而并非AtomicLong,很是困惑,于是专门看了LongAdder的源码,总结一下这两个的区别。
AtomicLong原理
就像我们所知道的那样,AtomicLong的原理是依靠底层的cas来保障原子性的更新数据,在要添加或者减少的时候,会使用死循环不断地cas到特定的值,从而达到更新数据的目的。那么LongAdder又是使用到了什么原理?难道有比cas更加快速的方式?
LongAdder原理
首先我们来看一下LongAdder有哪些方法?
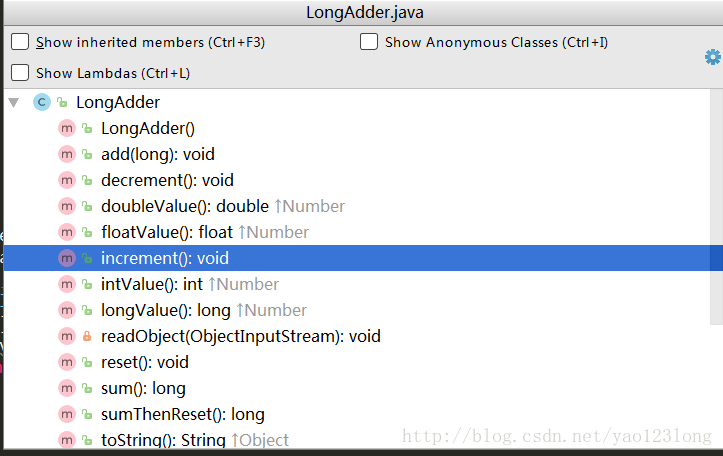
可以看到和AtomicLong基本类似,同样有增加、减少等操作,那么如何实现原子的增加呢?
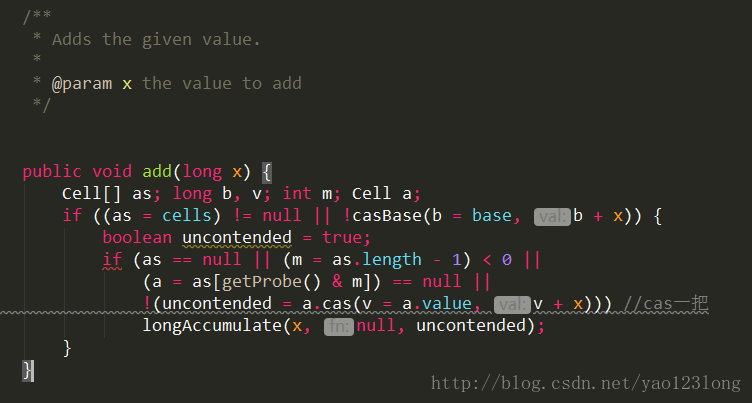
我们可以看到一个Cell的类,那这个类是用来干什么的呢?
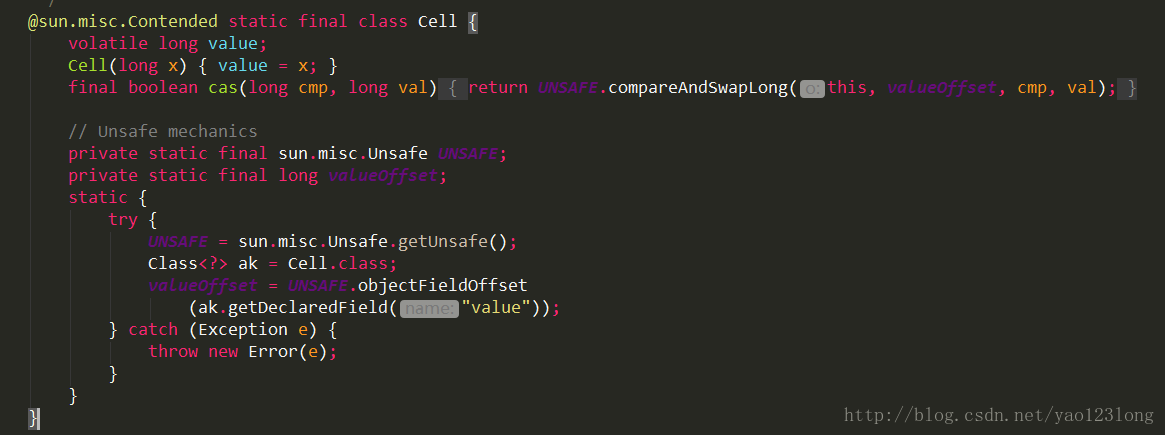
我们可以看到Cell类的内部是一个volatile的变量,然后更改这个变量唯一的方式通过cas。我们可以猜测到LongAdder的高明之处可能在于将之前单个节点的并发分散到各个节点的,这样从而提高在高并发时候的效率。
下面我们来验证我们的观点,我们接着看上图的add方法,如果cell数组不为空,那么就尝试更新base元素,如果更新成功,那么就直接返回。base元素在这里起到了一个什么作用呢?可以保障的是在低并发的时候和AtomicLong一样的直接对基础元素进行更新。
而如果cell为空或者更新base失败,我们看接下来的那个if判断,即如果as不为空并且成功更新对应节点的数据,则返回,否则就会进入longAccumulate()方法。
图有点大,无法截图,直接贴源码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
上面的代码主要有三个分支:
1. 如果数组不为空
2. 数据为空,则初始化
3. 前面都更新失败了,尝试更新base数据
cellBusy是一个标示元素,只有当修改cell数组大小或者插入元素的时候才会修改。分支二、分支三都很简单,我们来重点分析一下分支一。
当要更新的位置没有元素的时候,首先cas标志位,防止扩容以及插入元素,然后插入数据。如果成功直接返回,否则标示发生了冲突,然后重试。如果对应的位置有元素则更新,如果更新失败,进行判断是否数组的大小已经超过了cpu的核数,如果大于的话,则意味着扩容没有意义。直接重试。否则进行扩容,扩容完成后,重新设置要更新的位置,尽可能保证下一次更新成功。
我们来看一下如何统计计数。
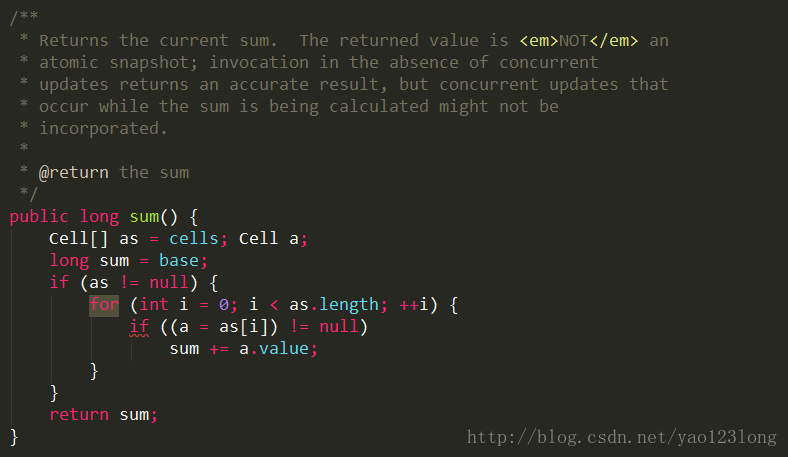
当计数的时候,将base和各个cell元素里面的值进行叠加,从而得到计算总数的目的。这里的问题是在计数的同时如果修改cell元素,有可能导致计数的结果不准确。
总结:
LongAdder在AtomicLong的基础上将单点的更新压力分散到各个节点,在低并发的时候通过对base的直接更新可以很好的保障和AtomicLong的性能基本保持一致,而在高并发的时候通过分散提高了性能。
缺点是LongAdder在统计的时候如果有并发更新,可能导致统计的数据有误差。















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









