



一、函数式编程
1、了解
-
Scala中的函数是Java中完全没有的概念。
因为Java是完全面向对象的编程语言,没有任何面向过程编程语言的特性,因此Java中的一等公民是类和对象,而且只有方法的概念,即寄存和依赖于类和对象中的方法。
Java中的方法是绝对不可能脱离类和对象独立存在的。 -
而Scala是一门既面向对象,又面向过程的语言。
因此在Scala中有非常好的面向对象的特性,可以使用Scala来基于面向对象的思想开发大型复杂的系统和工程;而且Scala也面向过程,因此Scala中有函数的概念。
在Scala中,函数与类、对象等一样,都是一等公民。
Scala中的函数可以独立存在,不需要依赖任何类和对象。 -
Scala的函数式编程,就是Scala面向过程的最好的佐证。
也正是因为函数式编程,才让Scala具备了Java所不具备的更强大的功能和特性。 -
之所以Scala一直没有替代Java,是因为Scala之前一直没有开发过太多知名的应用;而Java则不一样,Java诞生的非常早,上个世界90年代就诞生了,基于Java开发了大量知名的工程。
而且最重要的一点在于,Java现在不只是一门编程语言,还是一个庞大的,涵盖了软件开发,甚至大数据、云计算的技术生态,Java生态中的重要框架和系统就太多了:Spring、Lucene、Activiti、Hadoop等等。
2、将函数赋值给变量
- Scala中的函数是一等公民,可以独立定义,独立存在,而且可以直接将函数作为值赋值给变量
- Scala的语法规定,将函数赋值给变量时,必须在函数后面加上空格和下划线
package com.doit.scala.class14
object TestClass14 {
def main(args: Array[String]): Unit = {
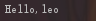
def sayHello_14_3(name: String){println("Hello," + name)}
val sayHelloFunc_14_3 = sayHello_14_3 _
sayHelloFunc_14_3("leo")
}
}
3、匿名函数
- Scala中,函数也可以不需要命名,此时函数被称为匿名函数。// 可以直接定义函数之后,将函数赋值给某个变量;也可以将直接定义的匿名函数传入其他函数之中
- Scala定义匿名函数的语法规则就是,(参数名: 参数类型) => 函数体
- 这种匿名函数的语法必须深刻理解和掌握,在spark的中有大量这样的语法,如果没有掌握,是看不懂spark源码的
object TestClass14 {
def main(args: Array[String]): Unit = {
val sayHelloFunc_14_4 = (name: String) => println("Hello," + name)
sayHelloFunc_14_4("wang")
}
}
4、高阶函数
- Scala中,由于函数是一等公民,因此可以直接将某个函数传入其他函数,作为参数。这个功能是极其强大的,也是Java这种面向对象的编程语言所不具备的。
- 接收其他函数作为参数的函数,也被称作高阶函数(higher-order function)
object TestClass14 {
def main(args: Array[String]): Unit = {
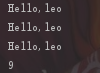
val sayHelloFunc_14_5 = (name: String) => println("Hello," + name)
def greeting(func: (String) => Unit, name: String) {func(name)}
greeting(sayHelloFunc_14_5, "leo")
//结果:Hello,leo
Array(1,2,3,4,5).map((num: Int) => num * num).foreach((num: Int) => print(num + " "))
//结果:1 4 9 16 25
// 高阶函数的另外一个功能是将函数作为返回值
def getGreetingFunc_14_5(msg: String) = (name: String) => println(msg + "," + name)
val greetingFunc = getGreetingFunc_14_5("hello,")
//结果:Hello,leo
}
}
5、高阶函数的类型推断
- 高阶函数可以自动推断出参数类型,而不需要写明类型;而且对于只有一个参数的函数,还可以省去其小括号;如果仅有的一个参数在右侧的函数体内只使用一次,则还可以将接收参数省略,并且将参数用_来替代
- 诸如3 * _的这种语法,必须掌握!!spark源码中大量使用了这种语法!
object TestClass14 {
def main(args: Array[String]): Unit = {
def greeting_14_6(func: (String) => Unit,name: String) {func(name)}
greeting_14_6((name: String) => println("Hello," + name), "leo")
greeting_14_6((name) => println("Hello," + name), "leo")
greeting_14_6(name => println("Hello," + name), "leo")
def triple_14_6(func:(Int) => Int) = {func(3)}
println(triple_14_6(3*_))
}
}
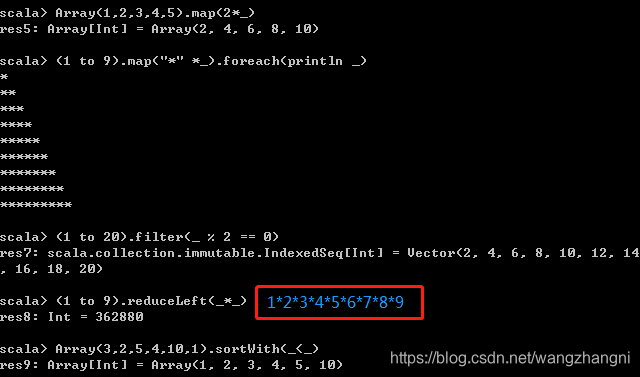
6、Scala的常用高阶函数
map 对传入的每个元素都进行映射,返回一个处理后的元素
foreach 对传入的每个元素都进行处理,但是没有返回值
filter 对传入的每个元素都进行条件判断,如果对元素返回true,则保留该元素,否则过滤掉该元素
reduceLeft 从左侧元素开始,进行reduce操作,即先对元素1和元素2进行处理,然后将结果与元素3处理,再将结果与元素4处理,依次类推,即为reduce;reduce操作必须掌握!spark编程的重点!!!
sortWith 对元素进行两两相比,进行排序
7、闭包
- 闭包最简洁的解释:函数在变量不处于其有效作用域时,还能够对变量进行访问,即为闭包
object TestClass14 {
def main(args: Array[String]): Unit = {
def getGreetingFunc_14_8(msg: String) = (name: String) => println(msg + "," + name)
val greetingFuncHello = getGreetingFunc_14_8("hello")
val greetingFuncHi = getGreetingFunc_14_8("hi")
}
}
-
两次调用getGreetingFunc函数,传入不同的msg,并创建不同的函数返回
-
然而,msg只是一个局部变量,却在getGreetingFunc执行完之后,还可以继续存在创建的函数之中;greetingFuncHello(“leo”),调用时,值为"hello"的msg被保留在了函数体内部,可以反复的使用
-
这种变量超出了其作用域,还可以使用的情况,即为闭包
-
Scala通过为每个函数创建对象来实现闭包,实际上对于getGreetingFunc函数创建的函数,msg是作为函数对象的变量存在的,因此每个函数才可以拥有不同的msg
-
Scala编译器会确保上述闭包机制
8、SAM转换
-
在Java中,不支持直接将函数传入一个方法作为参数,通常来说,唯一的办法就是定义一个实现了某个接口的类的实例对象,该对象只有一个方法;而这些接口都只有单个的抽象方法,也就是single abstract method,简称为SAM
-
由于Scala是可以调用Java的代码的,因此当我们调用Java的某个方法时,可能就不得不创建SAM传递给方法,非常麻烦;但是Scala又是支持直接传递函数的。此时就可以使用Scala提供的,在调用Java方法时,使用的功能,SAM转换,即将SAM转换为Scala函数
-
要使用SAM转换,需要使用Scala提供的特性,隐式转换
import javax.swing._
import java.awt.event._
object TestClass14 {
def main(args: Array[String]): Unit = {
val button_14_10 = new JButton("Click")
button_14_10.addActionListener(new ActionListener {
override def actionPerformed(event: ActionEvent): Unit = {
println("Click Me!!!")
}
})
implicit def getActionListener_14_10(a: ActionEvent => Unit) = new ActionListener {
override def actionPerformed(e: ActionEvent): Unit = {
a(e)
}
}
button_14_10.addActionListener((event: ActionEvent) => println("Click Me!!!"))
}
}
9、Currying函数
- Curring函数,指的是,将原来接收两个参数的一个函数,转换为两个函数,第一个函数接收原先的第一个参数,然后返回接收原先第二个参数的第二个函数。
- 在函数调用的过程中,就变为了两个函数连续调用的形式
- 在Spark的源码中,也有体现,所以对()()这种形式的Curring函数,必须掌握!
object TestClass14 {
def main(args: Array[String]): Unit = {
def sum_14_11_1(a: Int, b: Int) = a + b
println(sum_14_11_1(1, 1))
def sum_14_11_2(a: Int) = (b: Int) => a + b
println(sum_14_11_2(1)(1))
def sum_14_11_3(a: Int)(b: Int) = a + b
println(sum_14_11_3(1)(2))
}
}

10、return
- Scala中,不需要使用return来返回函数的值,函数最后一行语句的值,就是函数的返回值。在Scala中,return用于在匿名函数中返回值给包含匿名函数的带名函数,并作为带名函数的返回值。
- 使用return的匿名函数,是必须给出返回类型的,否则无法通过编译
object TestClass14 {
def main(args: Array[String]): Unit = {
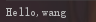
def greeting_14_12(name: String) = {
def sayHello_14_12(name: String): String = {
return "Hello," + name
}
sayHello_14_12(name)
}
println(greeting_14_12("wang"))
}
}
object TestClass14 {
def main(args: Array[String]): Unit = {
}
}
11、集合操作
1)Scala的集合体系结构
-
Scala中的集合体系主要包括:Iterable、Seq、Set、Map。其中Iterable是所有集合trait的根trait。这个结构与Java的集合体系非常相似。
-
Scala中的集合是分成可变和不可变两类集合的,其中可变集合就是说,集合的元素可以动态修改,而不可变集合的元素在初始化之后,就无法修改了。分别对应scala.collection.mutable和scala.collection.immutable两个包。
-
Seq下包含了Range、ArrayBuffer、List等子trait。其中Range就代表了一个序列,通常可以使用“1 to 10”这种语法来产生一个Range。 ArrayBuffer就类似于Java中的ArrayList。
2)List
- List代表一个不可变的列表 cmd
- List的创建:val list = List(1, 2, 3, 4) cmd
- List有head和tail,head代表List的第一个元素,tail代表第一个元素之后的所有元素
如果一个List只有一个元素,那么它的head就是这个元素,它的tail是Nil - List有特殊的::操作符,可以用于将head和tail合并成一个List,0 :: list
// 案例:用递归函数来给List中每个元素都加上指定前缀,并打印加上前缀的元素
object TestClass15 {
def main(args: Array[String]): Unit = {
def decorator_15_3(l: List[Int], prefix: String) {
if(l != Nil) {
print(prefix + l.head + " ")
decorator_15_3(l.tail, prefix)
}
}
val l = List(1,2,3,4)
decorator_15_3(l,"list")
}
}

3) LinkedList
- LinkedList代表一个可变的列表,使用elem可以引用其头部,使用next可以引用其尾部
object TestClass15 {
def main(args: Array[String]): Unit = {
val l = scala.collection.mutable.LinkedList(1, 2, 3, 4, 5)
println(l.elem)
println(l.next)
}
}

- 案例:使用while循环将LinkedList中的每个元素都乘以2
object TestClass15 {
def main(args: Array[String]): Unit = {
val list = scala.collection.mutable.LinkedList(1,2,3,4,5)
var currentList = list
while (currentList != Nil) {
currentList.elem = currentList.elem * 2
currentList = currentList.next
}
println(list.toString())
}
}

- 案例:使用while循环将LinkedList中,从第一个元素开始,每隔一个元素,乘以2
object TestClass15 {
def main(args: Array[String]): Unit = {
val list = scala.collection.mutable.LinkedList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
var currentList = list
var first = true
while (currentList != Nil && currentList.next != Nil) {
if (first) { currentList.elem = currentList.elem * 2; first = false }
currentList = currentList.next.next
if (currentList != Nil) currentList.elem = currentList.elem * 2
}
println(list.toString())
}
}

4)Set
- Set代表一个没有重复元素的集合,将重复元素加入Set是没有用的
object TestClass15 {
def main(args: Array[String]): Unit = {
var s = Set(1, 2, 3);
s += 1; s += 4
println(s)
}
}

- Set是不保证插入顺序的,也就是说,Set中的元素是乱序的
object TestClass15 {
def main(args: Array[String]): Unit = {
val s = new scala.collection.mutable.HashSet[Int]()
s += 1; s += 2; s += 5
print(s)
}
}

- LinkedHashSet会用一个链表维护插入顺序
object TestClass15 {
def main(args: Array[String]): Unit = {
val s = scala.collection.mutable.LinkedHashSet[Int]()
s += 1; s += 5; s += 2
println(s)
}
}
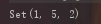
- SrotedSet会自动根据key来进行排序
object TestClass15 {
def main(args: Array[String]): Unit = {
val s = scala.collection.mutable.SortedSet("orange","apple","banana")
println(s)
}
}

5)集合的函数式编程
- 必须完全掌握和理解Scala的高阶函数是什么意思,Scala的集合类的map、flatMap、reduce、reduceLeft、foreach等这些函数,就是高阶函数,因为可以接收其他函数作为参数
- 高阶函数的使用,也是Scala与Java最大的一点不同!!!因为Java里面是没有函数式编程的,也肯定没有高阶函数,也肯定无法直接将函数传入一个方法,或者让一个方法返回一个函数
- 对Scala高阶函数的理解、掌握和使用,可以大大增强你的技术,而且也是Scala最有诱惑力、最有优势的一个功能!!!
- 此外,在Spark源码中,有大量的函数式编程,以及基于集合的高阶函数的使用!!!所以必须掌握,才能看懂spark源码
// map案例实战:为List中每个元素都添加一个前缀
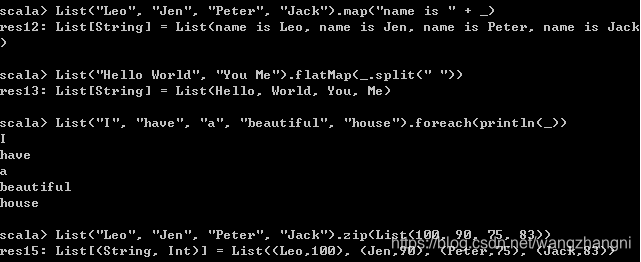
List("Leo", "Jen", "Peter", "Jack").map("name is " + _)
// faltMap案例实战:将List中的多行句子拆分成单词
List("Hello World", "You Me").flatMap(_.split(" "))
// foreach案例实战:打印List中的每个单词
List("I", "have", "a", "beautiful", "house").foreach(println(_))
// zip案例实战:对学生姓名和学生成绩进行关联
List("Leo", "Jen", "Peter", "Jack").zip(List(100, 90, 75, 83))
6)函数式编程综合案例:统计多个文本内的单词总数
object TestClass15 {
def main(args: Array[String]): Unit = {
// 使用scala的io包将文本文件内的数据读取出来
val lines01 = scala.io.Source.fromFile("E:\\ziliao\\Scala\\node\\test01.txt").mkString
val lines02 = scala.io.Source.fromFile("E:\\ziliao\\Scala\\node\\test02.txt").mkString
// 使用List的伴生对象,将多个文件内的内容创建为一个List
val lines = List(lines01, lines02)
//函数式编程(核心重点)
println(lines.flatMap(_.split(" ")).map((_,1)).map(_._2).reduceLeft(_+_))
}
}

















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









