









- 用python抓取美联储数据
近日,笔者选择了一个任务,用爬虫抓取美联储演讲数据,并分析相关金融政策。
首先必须做的,是抓取数据。
打开美联储的网站Federal Reserve Board - Home。然后,找到美联储关键人物的演讲的网站:Federal Reserve Board - Speeches of Federal Reserve Officials。
打开一个演讲,如Introductory remarks by Chair Powell at "Fed Listens: Perspectives on the Pandemic Recovery" - Federal Reserve Board。再多打开几个,发现最后的格式为“姓名+年月日+a.htm”。
但有两个问题:
- 不知道都有哪些关键人物的演讲;
- 不知道都在哪些时间段进行了演讲。
第一个问题,需要找当时美联储的任职人员。非常好的是:美联储公布了自己的Borad成员,在网页Federal Reserve Board - Board Members 上找到了,然后把姓名尤其上Family Name加上了。
第二个问题,需要找哪天演讲。这样就更简单了:让程序自己连接,如果URL存在,则存在演讲;否则,则不存在演讲。反正机器比人快得多,也不需要人帮忙。
还有个问题,仅仅用爬虫,是抓下来数据,但并不获得数据。这就需要用到另一个技术:提取数据,对文本进行去除无用数据,让数据格式化,进行数据清洗。
然后,另外几个技术框架就上手了。第一个框架为BeautifulSoup,用于提取数据;第二个是正则表达式,用于去除无用数据。
整个程序如下所示:
#coding=utf-8
import requests
from bs4 import BeautifulSoup
import time
import re
import datetime
import os
import logging
import urllib3
from lxml import etree
import traceback
# 名字有缩减
NAME = [
'powell',
'clarida',
'quarles',
'madigan',
'yellen',
]
# print(NAME)
# print(NAME.sort())
#
print(sorted(NAME))
NAME_ARR = sorted(NAME)
print(NAME_ARR)
# headers 用chrom浏览器——F12——切换到network 栏,刷新下要访问的目标网站,就能找到`User-Agent` 复制下来就好。用于伪装浏览器,便于爬虫稳定性
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
# 获得信息,基础是爬虫程序
def get_info(url):
try:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
r = requests.get(url, headers=headers, timeout=120, verify=False)
r.raise_for_status()
except Exception as ex:
time.sleep(8)
Logger.error(traceback.print_exc())
return
if r.status_code != 200:
Logger.error("Website Error: "+ url + str(r))
else:
Logger.info("Website Good: "+ url + str(r))
soup = BeautifulSoup(r.text, 'html.parser') #对返回的结果进行解析
if is_wrong_content(str(soup)):
return
# 选择某种能发现文本的类
all_content = soup.find_all('div', class_='***')
str_content = get_right_content(str(all_content))
file_name = url.split('/')[-1]
with open('downloads/' + file_name, 'w') as fp:
fp.write(str_content)
# 错误信息屏蔽
def is_wrong_content(str_content):
html = etree.HTML(str_content)
html_data = html.xpath('/html/body/div/div/title/text()')
if(type(html_data) != 'str'):
return False
if html_data.lower().find('not found'):
return True
return False
# 正则去除无用信息
def get_right_content(str_content):
# 多个正则表达式,暂不全部列出
str_content = re.sub(r'<strong>.*</strong>', '', str_content)
str_content = re.sub(r'<p>', '', str_content)
return str_content
# URL格式,用于生成访问URL
def url_format():
url_format = 'https://www.federalreserve.gov/newsevents/speech/{}{}a.htm'
return url_format
# 根据开始日期、结束日期返回这段时间里所有天的集合
def getDatesByTimes(sDateStr, eDateStr):
list = []
datestart = datetime.datetime.strptime(sDateStr, '%Y%m%d')
dateend = datetime.datetime.strptime(eDateStr, '%Y%m%d')
list.append(datestart.strftime('%Y%m%d'))
while datestart < dateend:
datestart += datetime.timedelta(days=1)
list.append(datestart.strftime('%Y%m%d'))
return list
# 获得日期和项目的URL
def get_url_lst(lst_date):
lst_url = []
for name in NAME_ARR:
for date in lst_date:
http_url = url_format().format(name, date)
lst_url.append(http_url)
return lst_url
if __name__ == '__main__':
lst_date = getDatesByTimes('20210101', '20210920')
lst_url = get_url_lst(lst_date)
for url in lst_url:
get_info(url)
time.sleep(3) #防止被认为是爬虫
- 分析算法
分析算法选择就更值得斟酌了。首先,必须选择的是监督学习和无监督学习。经分析,必须是监督学习;因为,货币政策的选择,需要人来判断的,而不是让文本自己选择差异性。
第二步,如何用机器学习模型进行分类。想到这件事的目的,是用机器学习的算法区分货币政策。真正需要做的事情是:由原始文本库,获得货币政策的真正含义;现实的操作步骤是:由文本转为一定的信息,然后,依据某种特定模型,对文本信息进行判断货币政策的有效性(可以参考图1,该图来自沈艳 、陈赟、黄卓的《文本大数据分析在经济学和金融学中的应用:一个文献综述》)。该模型获得需要进行训练,但首先确定模型的结果。这就要通过一定方法确定文本的信息的含义,从而确定文本信息的意义。
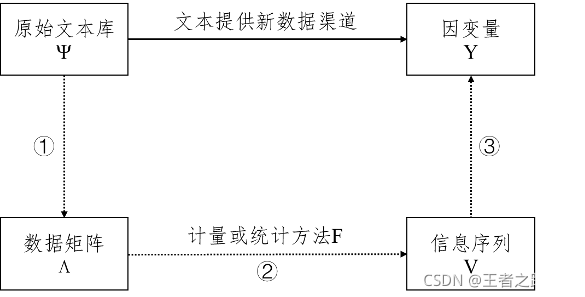
图一 由文本信息分析货币政策思路
笔者的方法是:用人工方法确定演讲人的货币政策的具体含义(很多大公司其实有专人进行文本语义分析)。笔者打开相关网页,然后,把相关网页转为中文,然后,对文本的货币政策含义进行了判断,得出了相关信息。
下一步的选择是:选择何种机器学习模型进行训练。对于大部分人来说,可以把机器学习模型预设为某个黑箱子,然后选择适合自己的机器学习模型。
笔者首先想到的是SVM。因为,SVM是最简单的模型。把模型和结果扔进去即可,SVM本身会在内部进行纬度转换,获得相关结果。但笔者预想到SVM分析精度应该不高;当然,程序结果和笔者预想的一样,只有0.4。
在笔者进行文本分析的过程中,发现货币政策其实仅仅是一小段话。于是,想到了贝叶斯原理。贝叶斯的基本公式是: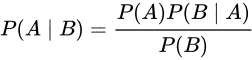 。关于贝叶斯的公式,很多人有很多解释,但基本原理无非是假设某些事件有某些概略,现实发生的事件会印证这个概率或减少这个概率。显然,贝叶斯原来会更好一点。
。关于贝叶斯的公式,很多人有很多解释,但基本原理无非是假设某些事件有某些概略,现实发生的事件会印证这个概率或减少这个概率。显然,贝叶斯原来会更好一点。
然后,用贝叶斯公式分析,发现算法精度果然提高了不少,有0.84。
于是,暂时选择贝叶斯公式作为分析模型。笔者会继续选择其他模型进行分析;如有其他模型分析,会继续写下阶段性结论。
- 附加说明
本文的程序,原理很简单;部分程序是搜索自网络并进行合理调整。但由于程序本身要用,故只公布了一定的爬虫程序,且故意留下了一点瑕疵。机器学习模型暂时不公布了。
2021年9月24日


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









