







 本文介绍了一个基于机器学习预测共享单车需求的项目。通过对历史数据的分析,包括时间、天气、节假日等因素,预测不同时间段内的单车使用情况,以优化单车投放策略。
本文介绍了一个基于机器学习预测共享单车需求的项目。通过对历史数据的分析,包括时间、天气、节假日等因素,预测不同时间段内的单车使用情况,以优化单车投放策略。
文章目录
问题描述:
- 在对一个应用使用机器学习算法之前我们应该要分析清楚问题是什么
- 本次项目所要解决的问题是:通过共享单车上的传感器采集的数据和系统上记录的用户的行为数据,用来预测一年中不同时间段某个地区单车的使用情况,从而确定单车在该区域的投放数目,保证单车租赁公司的利益最大化。
- 本项目中收集到的数据中包括:时间(年-月-日-时),季节(春夏秋冬),节日(是/否),工作日(是/否),天气(四个等级),温度,体感温度,湿度,风速,非注册人员租赁,注册人员租赁,租赁人数;
问题解决
分析问题:
- 从项目的描述来看,这是一个回归问题,希望我们通过采集的数据去预测未来某段时间内单车的需求量。
- 从采集的数据的属性上可以猜测一些:
- 工作日大家应该没有时间去骑单车出去玩,节假日应该偏多
- 温度太低或者风速太大都不适合骑单车出去
- 注册的人员使用单车的频率应该比非注册的人员使用单车频率高
解决问题
第一步:读取原始数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#从本地磁盘读取数据
df_train = pd.read_csv('kaggle_bike_competition_train.csv',header = 0)
df_train.head(10) #查看前10项内容
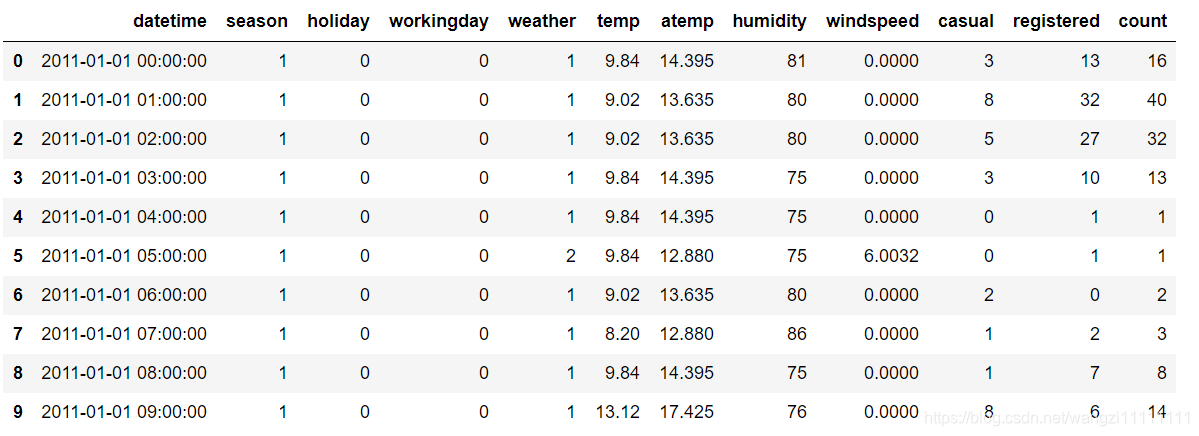
通过查看原始数据发现,datatime这一项数据包括了年月日时分秒,后续可以将其拆分开来。虽然将数据打印出来,但是这样的方式不太直观,我们可以通过调用df.info()和df.describe()函数查看数据的统计信息。
第二步:观察原始数据
df_train.dtypes #查看数据中每行的属性值
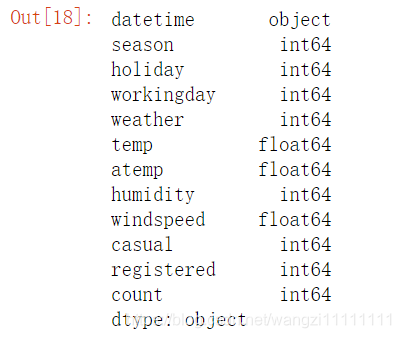
可以看出数据中大部分都是数值型的数据,只有datatime是类别型的数据。
df_train.info()
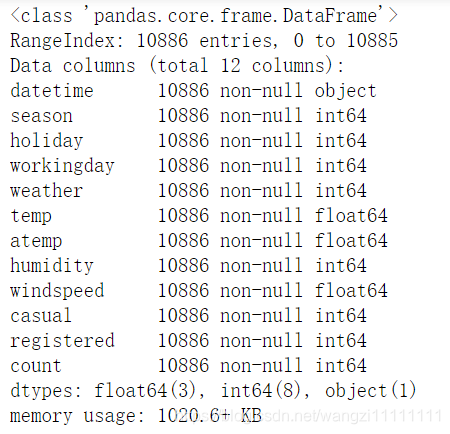
数据的完整性非常好。所有属性的数据都没有缺失值,那么接下我们看一下数值型数据的取值范围吧!
df_train.describe()
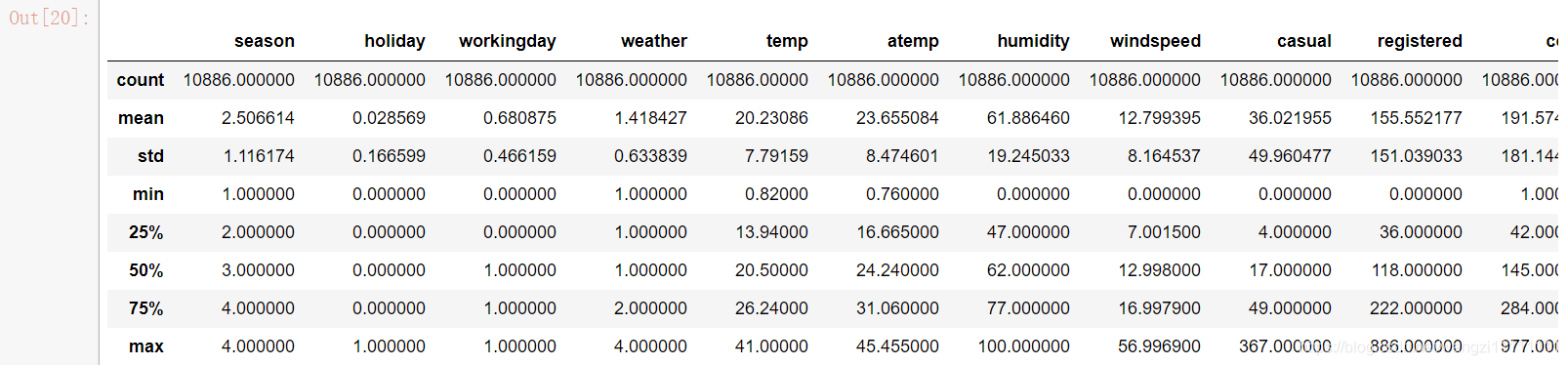
数据中的数值型数据的取值范围相差不大,每个属性内部的取值范围也不大,所以觉得对数据做缩放意义不大。接下来我们通过可视化看看每个属性与预测值之间的关系吧!
第三步:原始数据的可视化
# 风速
df_train_origin.groupby('windspeed').mean().plot(y='count', marker='o') #画出风速和租车次数的关系
plt.show()
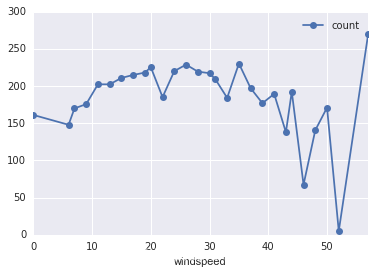
图中的结果似乎与我们一开始的猜测有些出入,尤其是图中风速大于50后,单车租赁次数反而剧增,这是一个比较特别的地方,后面可以着重考虑
# 湿度
df_train_origin.groupby('humidity').mean().plot(y='count', marker='o') #画出湿度值与租车次数的关系
plt.show()
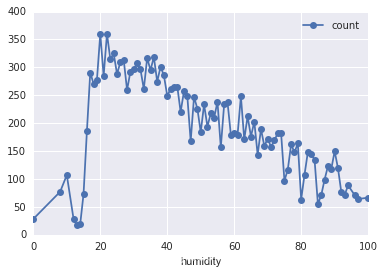
从图中可以看出过干和过湿都会导致单车租赁的减少。
# 温度
df_train_origin.groupby('temp').mean().plot(y='count', marker='o') #画出温度与租车次数的关系
plt.show()
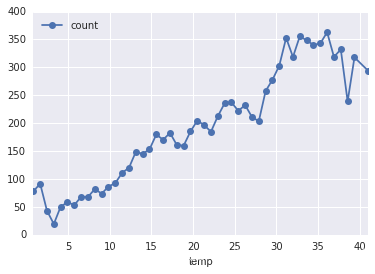
从图中的结构似乎可以看出随着温度的升高,单车租赁次数也越多,这是符合我们之前的猜测的。
#温度湿度变化
df_train_origin.plot(x='temp', y='humidity', kind='scatter')
plt.show()
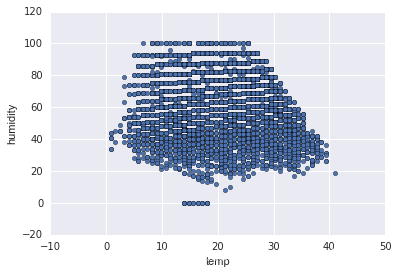
无法看出任何规律,只能说该地区的温度和湿度的一个分布范围。
# scatter一下各个维度
fig, axs = plt.subplots(2, 3, sharey=True)
df_train_origin.plot(kind='scatter', x='temp', y='count', ax=axs[0, 0], figsize=(16, 8), color='magenta')
df_train_origin.plot(kind='scatter', x='atemp', y='count', ax=axs[0, 1], color='cyan')
df_train_origin.plot(kind='scatter', x='humidity', y='count', ax=axs[0, 2], color='red')
df_train_origin.plot(kind='scatter', x='windspeed', y='count', ax=axs[1, 0], color='yellow')
df_train_origin.plot(kind='scatter', x='month', y='count', ax=axs[1, 1], color='blue')
df_train_origin.plot(kind='scatter', x='hour', y='count', ax=axs[1, 2], color='green')
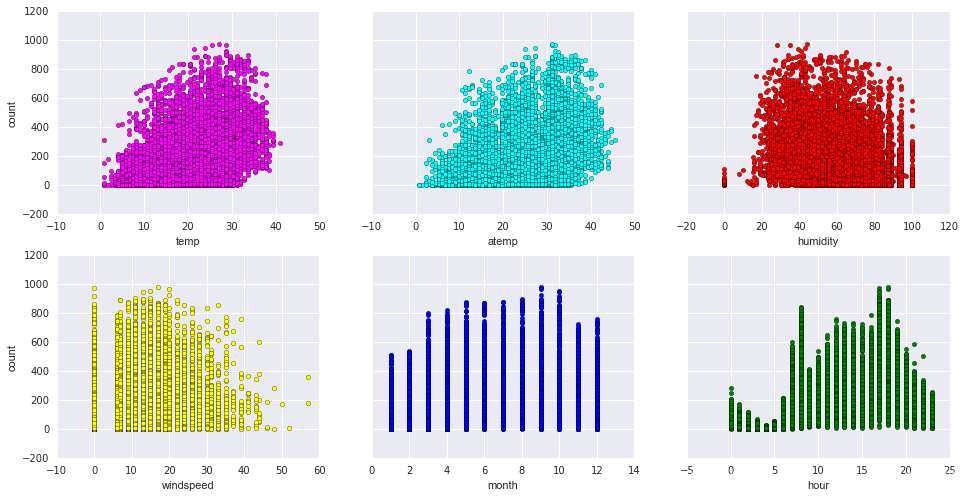
从图中结果似乎只能看出温度,体感温度和租车次数呈现一定的正相关,风速与租车次数是负相关
# scatter一下各个维度
sns.pairplot(df_train_origin[["temp", "month", "humidity", "count"]], hue="count")
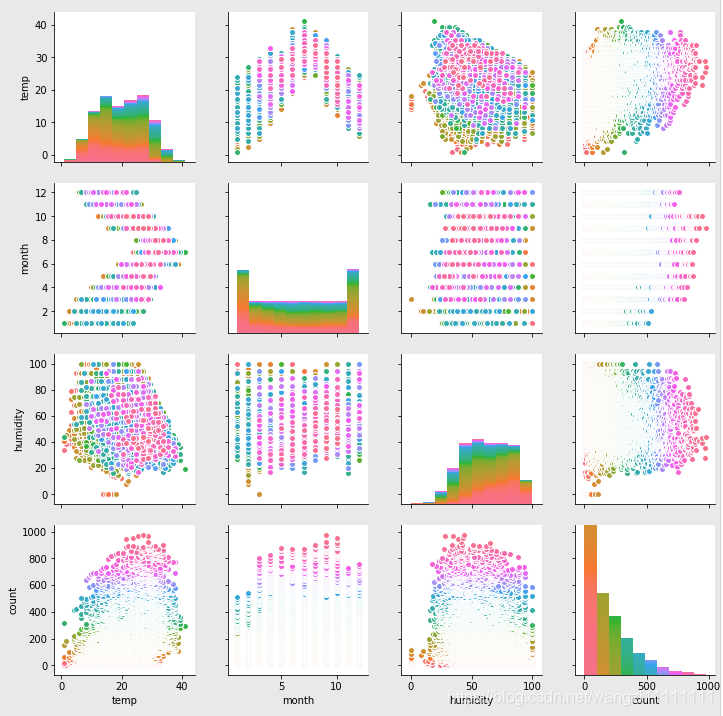
各个属性之间的相关性不是很强。
# 来看看相关度咯
corr = df_train_origin[['temp','weather','windspeed','day', 'month', 'hour','count']].corr()
corr
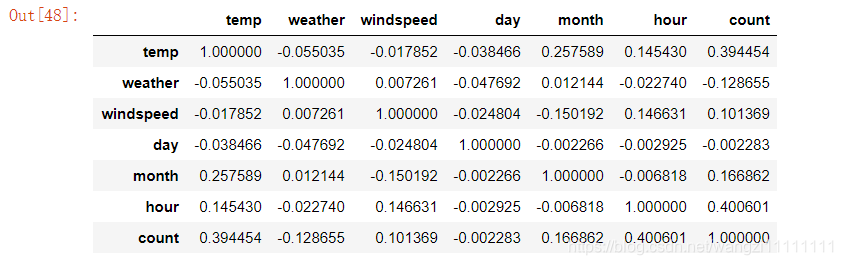
似乎这样比上面的图像的结果理解起来更加方便,从表格的结果可知:温度和小时与汽车租赁的相关性最大。
第四步:数据的预处理
由于原始数据不存在缺失值,类别属性特征也较少,数值型数据比较规范,所以不需要太多的数据预处理,只需要对时间属性进行处理进行。
时间属性的分解
# 把月、日、和 小时单独拎出来,放到3列中
df_train['month'] = pd.DatetimeIndex(df_train.datetime).month
df_train['day'] = pd.DatetimeIndex(df_train.datetime).dayofweek
df_train['hour'] = pd.DatetimeIndex(df_train.datetime).hour
# 再看
df_train.head(10)
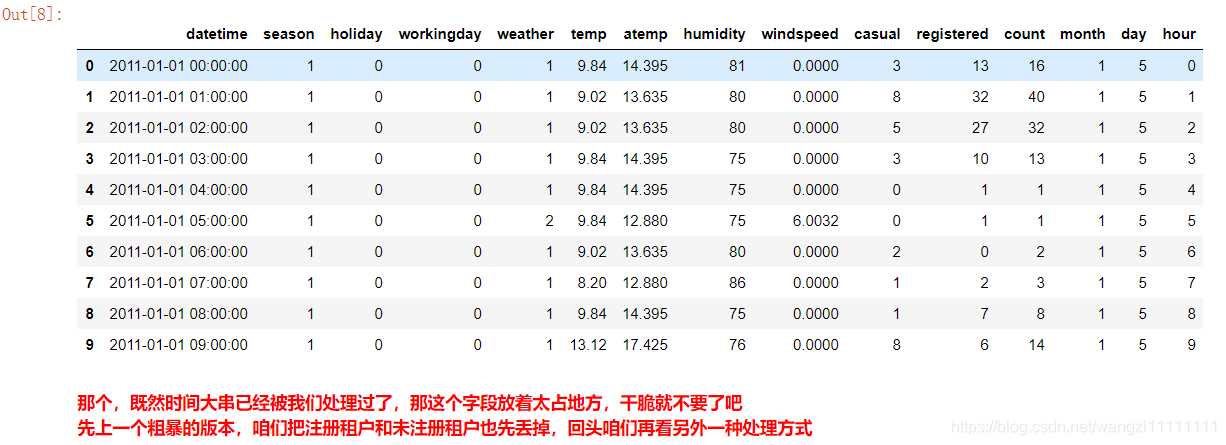
# 那个,保险起见,咱们还是先存一下吧
df_train_origin = df_train
# 抛掉不要的字段
df_train = df_train.drop(['datetime','casual','registered'], axis = 1) #删除'datetime','casual','registered'等列的数据
# 看一眼
df_train.head(5)
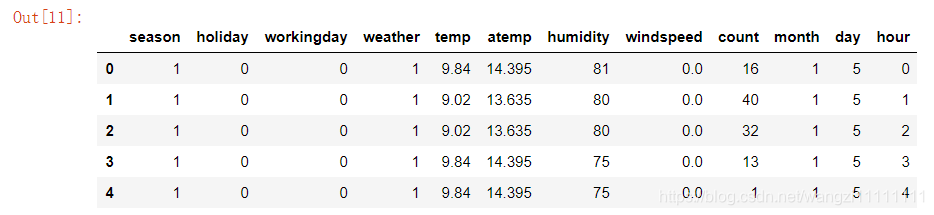
# 得到X和Y
df_train_target = df_train['count'].values
df_train_data = df_train.drop(['count'],axis = 1).values
print 'df_train_data shape is ', df_train_data.shape
print 'df_train_target shape is ', df_train_target.shape
df_train_data shape is (10886L, 11L)
df_train_target shape is (10886L,)
第五步:数据的特征提取
特征生成
由于原始户数比较规范,暂时先不做特征生成
特征选择
由于数据比较规范,暂时不做特征选择
第六步:训练baseline
from sklearn import linear_model
from sklearn import cross_validation
from sklearn import svm
from sklearn.ensemble import RandomForestRegressor
from sklearn.learning_curve import learning_curve
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import explained_variance_score
# 总得切分一下数据咯(训练集和测试集)
cv = cross_validation.ShuffleSplit(len(df_train_data), n_iter=3, test_size=0.2,
random_state=0) #使用3折交叉验证的方法
# 各种模型来一圈
print "岭回归"
for train, test in cv:
svc = linear_model.Ridge().fit(df_train_data[train], df_train_target[train])
print("train score: {0:.3f}, test score: {1:.3f}\n".format(
svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))
print "支持向量回归/SVR(kernel='rbf',C=10,gamma=.001)"
for train, test in cv:
svc = svm.SVR(kernel ='rbf', C = 10, gamma = .001).fit(df_train_data[train], df_train_target[train])
print("train score: {0:.3f}, test score: {1:.3f}\n".format(
svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))
print "随机森林回归/Random Forest(n_estimators = 100)"
for train, test in cv:
svc = RandomForestRegressor(n_estimators = 100).fit(df_train_data[train], df_train_target[train])
print("train score: {0:.3f}, test score: {1:.3f}\n".format(
svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))
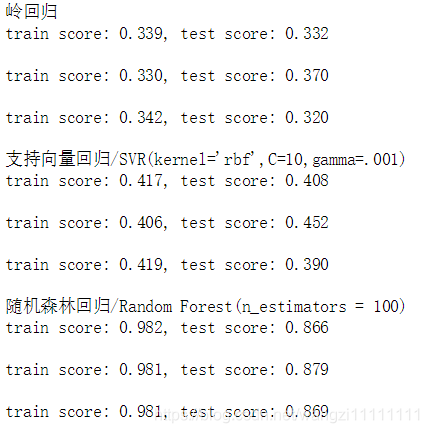
上面简单的比较了几种常用的回归算法在数据集上的表现,从实验的结果可以看出,随机森林的结果是最佳的。
第七步:模型的状态估计(通过学习曲线)
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
title = "Learning Curves (Random Forest, n_estimators = 100)"
cv = cross_validation.ShuffleSplit(df_train_data.shape[0], n_iter=10,test_size=0.2, random_state=0)
estimator = RandomForestRegressor(n_estimators = 100)
plot_learning_curve(estimator, title, X, y, (0.0, 1.01), cv=cv, n_jobs=4)
plt.show()
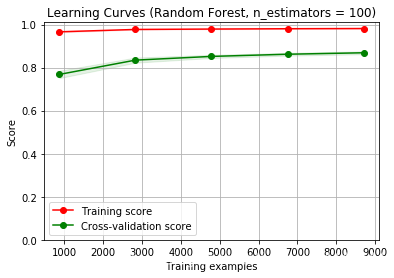
从图中的结果可以看出,模型处于过拟合状态
第八步:模型优化
从上面的记过可以看出,模型处于过拟合状态,可以从模型的参数,特征两方面来解决。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









