






人工智能之父: 约翰 麦卡锡
机器学习之父: 亚瑟 塞缪尔
人工智能三大概念:AI ,ML,DL
-
AI - 用计算机模拟人脑,让计算机能够像人类一样 , 理性的思考和行动
-
三者关系 : 包含关系
-
机器学习是实现人工智能的一种途径
-
深度学习是机器学习的一种方法
机器学习(Machine Learning)
-
概念: the ability to learn without being explicitly programmed(显式编程)
机器自动学习, 不是人为规则编程
-
机器如何学习:
历史数据(经验) -> 训练(归纳) -> 得到模型(找规律,找公式) -> 输入新的数据(新的问题),预测新的问题
- 先训练,(再评估)再预测
-
深度学习(Deep Learning)
-
深度神经网络,大脑仿生,设计一层一层神经元模拟万事万物
-> 搭建自己的知识库
学习方式
-
基于规则的学习(垃圾邮件): 程序员根据经验经验, 手工的if-else 方式进行预测
但是, 图片和语音识别 自然语言处理: 无法明确的写下规律
-
基于模型的学习 (房价预测): 从数据中自动学出规律
-
训练集 : x_train -> 特征, y_train -> 标签, 一条数据为一个样本
-
测试集 : x_test , 一般求y_test
一元线性回归: y = kx + b
k: 斜率 - > Weight,权重
b: 截距 -> bias ,偏置
-
LM的应用领域 和发展史
-
发展三要素: 数据 + 算法 + 算力
-
CPU: I\O密集型的任务 (input/output)
-
GPU: 计算密集型, 并行计算能力突出
-
TPU(张量处理器): 大型网络训练
-
-
发展史:
-
符号主义: 专家系统占主导 (1950 - 图灵国际象棋) -> 第一次浪潮
-
1956年 - 人工智能元年: 达特茅斯会议 - 约翰 麦卡锡(人工智能之父), 克劳德 香农(信息论创始人), 马文·闵斯基...
-
统计主义(1980-2000): 主要用统计模型 - IBM深蓝 ->第二次浪潮
-
神经网络(2012年): 神经网络,深度学习流派 -> 2016AlphaGO ->第三次浪潮
-
大规模预训练(2017年): 自然语言处理NLP的Transformer框架出现
2022年 : chat GPT, AIGC的发展
-
机器学习常用术语(重点)
-
样本(sample) : 一行数据就是一个样本; 多个样本组成数据集
-
特征(feature) : 一列数据一个特征,有时也被称为属性
-
标签(target/label): 模型要预测的那一列数据
-
数据集划分两部分: 训练集 (training set)
测试集 (testing set)
比例: 一般7:3 或者 8:2
-
四个变量名:
-
x_train : 训练集的特征
-
y_train : 训练集的标签
-
x_test : 测试集的特征
-
y_test : 测试集的标签
-
LM算法分类(重点)
有监督学习 : 有特征, 有标签:
标签分类:
-
连续: 回归问题 - > (一元线性回归) y = wx + b
-
不连续(居多): 分类问题 - > 二分类,多分类
-
KNN-欧式距离: 对应维度差值 平方和,开根号
-
KNN : K近邻, K个临近的投票
-
切比雪夫距离
-
曼哈顿距离/城市街区距离
-
闵式距离
-
-
无监督学习:有特征, 没有标签:
-
找样本间的相似性, 对样本聚类, 发现事物内部结构及相互关系
半监督学习:
-
有特征, 部分有标签
-
工作原理 :
-
让专家标注少量数据(真实标记), 利用已经标记的数据 , 训练出一个模型
-
再利用该模型 去套用未标记的数据
-
通过 询问领域专家分类结果 与模型分类结果做对比(专家: 校验,审核)
-
-
好处: 大幅降低专家标记成本
强化学习
-
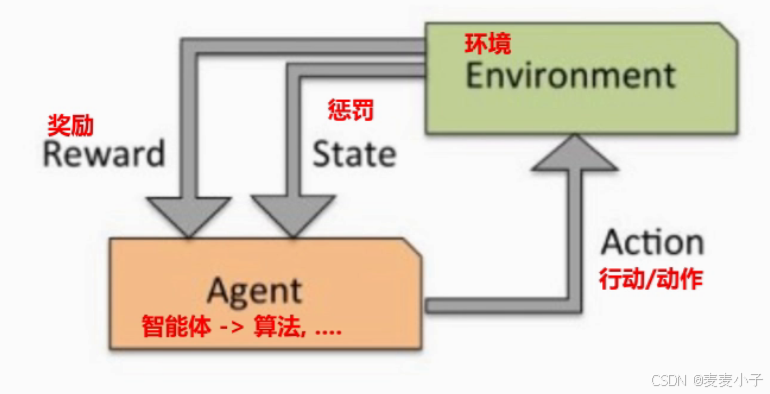
强化学习 = 寻找最短路径(最优解), 以便获取最多的 累积奖励.
-
四要素: Agent(智能体), 环境 ,行动, 奖励
-
-
机器学习的重要分支, 里程碑AlphaGo, 各类游戏对抗比赛, 无人驾驶场景
机器学习建模流程(重点)
-
1.数据加载 2. 数据基本处理 3. 特征工程 4.机器学习(模型训练) 5.模型评估 6.模型预测
-
数据基本处理, 特征工程 一般是耗时 耗精力最多的
-
获取数据
-
数据基本处理: 缺失值(dropna, fillna) , 异常值处理 ,
-
特征工程:
-
特征提取 (feature extractor - 特征提取器)
-
特征的预处理 : 防止量纲(单位)不同
-
特征降维(二向箔)
-
特征的选取
-
特征的组合
-
-
机器学习(模型训练): 根据不同需求, 选取合适算法
-
线性回归, 逻辑回归, 决策树, GBDT
-
-
模型评估 :
-
回归/ 分类/ 聚类 评测指标
-
-
特征工程概念
-
概念: 利用专业背景知识和技巧处理数据,让机器学习算法效果最好
-
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
-
步骤:
-
特征提取 (feature extractor ): 原始数据中, 提取与任务相关特征, 会改变源数据
-
特征的预处理 : 防止因为量纲(单位)问题, 导致鲁棒性 较差(特征 对模型影响大小不同)
-
归一化 : X' = (当前值- 最小值) / (最大值 - 最小值)
X'' = X' (mx - min) + min
-
标准化 : 转换为均值为0标准差为1的标准正态分布的数据
X' = (x - mean) / 该列特征的标准差
-
-
特征降维 : 二向箔- 会影响修改元数据
-
特征的选取 : 选择与任务直接相关的特征子集(10列数据选3列) , 不会改变原数据
-
特征的组合 : 多个特征 合并成一个特征, 利用乘法或者加法(如BMI计算)
-
模型拟合问题
拟合- fitting
1. 模型在 训练集 和 测试集上表现情况
-
分类情况:
-
正好拟合 just - fitting :
-
欠拟合 under- fitting : 模型在训练集, 测试集 表现 都不好
-
产生原因: 模型过于简单
-
欠拟合可以通过增加特征来解决
-
-
过拟合 over- fitting : 在训练集表现好, 测试集表现不好
-
产生原因: 模型过于复杂, 数据不纯, 训练数据太少
-
过拟合可以通过正则化、异常值检测、特征降维等方法来解决
-
-
泛化 : 具体的、个别的扩大为一般的能力
即 : 模型的拟合情况 = 泛化能力, 模型在测试集上 表现好坏的能力
-
奥卡姆剃刀原则: 两个具有相同泛化误差的模型, 较简单的模型 更可取
机器学习开发环境
pip install scikit-learn
scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation
-
Classification(分类问题) : 逻辑回归,KNN,朴素贝叶斯
-
Regression (回归问题) : 线性回归, 岭回归
-
Clustering(聚类问题) : Kmeans


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









