






简述
之前的文章 5分钟搞定 MySQL 到 ClickHouse 实时数据同步 发布后,很多用户将 MySQL->ClickHouse 实时同步链路用了起来,但是我们很快发现,CollapsingMergeTree 在某些场景下可能并不能按预期进行数据折叠。
这个时候,我们参考了 ClickHouse 官方实现的 MaterializeMySQL 表引擎,将 ReplacingMergeTree 作为对端主力表引擎进行数据链路构建。
新方案优势包括
- 表不存在额外的字段
- 按 order by key 严格合并(单节点)
- 可以设置按时间间隔自动 optimize 表(autoOptimizeThresholdSec参数)
- 支持 DDL 同步
技术点
结构迁移
目前到 ClickHouse 的结构迁移中,默认选择 ReplacingMergeTree 作为表引擎,源主键作为 sortKey (无主键表则是 tuple),如下示例:
CREATE TABLE console.worker_stats
(
`id` Int64,
`gmt_create` DateTime,
`worker_id` Int64,
`cpu_stat` String,
`mem_stat` String,
`disk_stat` String
)
ENGINE = ReplacingMergeTree()
ORDER BY id
SETTINGS index_granularity = 8192
写数据
新方案全量仍然按照标准 batch 导入,增量和 CollapsingMergeTree 作为表引擎的区别在于
- 转换 Insert、Update 操作为 Insert
- Delete 操作单独通过 alter table delete 语句进行操作
所以 Delete 操作如果较多,增量同步性能会急剧下降,建议 delete RPS 不超过 50。
switch (rowChange.getEventType()) {
case INSERT:
case UPDATE: {
for (CanalRowData rowData : rowChange.getRowDatasList()) {
CkTableBatchData.RecordWithState addRecord = new CkTableBatchData.RecordWithState(CanalEventType.INSERT, rowData.getAfterColumnsList());
batchData.getRecords().add(addRecord);
}
break;
}
case DELETE: {
for (CanalRowData rowData : rowChange.getRowDatasList()) {
CkTableBatchData.RecordWithState delRecord = new CkTableBatchData.RecordWithState(CanalEventType.DELETE, rowData.getBeforePkColumnsList());
batchData.getRecords().add(delRecord);
batchData.setHasDelete(true);
}
break;
}
default:
throw new CanalException("not supported event type,eventType:" + rowChange.getEventType());
}
举个"栗子"
- 造 Insert、Update、Delete 负载,比例为 20:78:2

- 添加数据源

- 创建任务,选择数据源和库,并连接成功
- ClickHouse 侧点开高级选项,确保 表引擎为 ReplacingMergeTree
- 点击下一步

- 选择数据同步,建议规格至少选择 1 GB。
- 目前已经支持 MySQL->ClickHouse DDL 同步, 可默认选中。
- 点击下一步

- 选择表、列、创建确认默认下一步。
- 等待任务自动结构迁移、全量迁移、数据同步追上
- 打开自动表优化开关,默认设置 30 秒间隔

- 延迟追平状态,停止负载
- 等待自动优化间隔时间,创建一个校验任务,跑完结果一致。
- 也可以等待 ClickHouse 自动优化,但时间不定

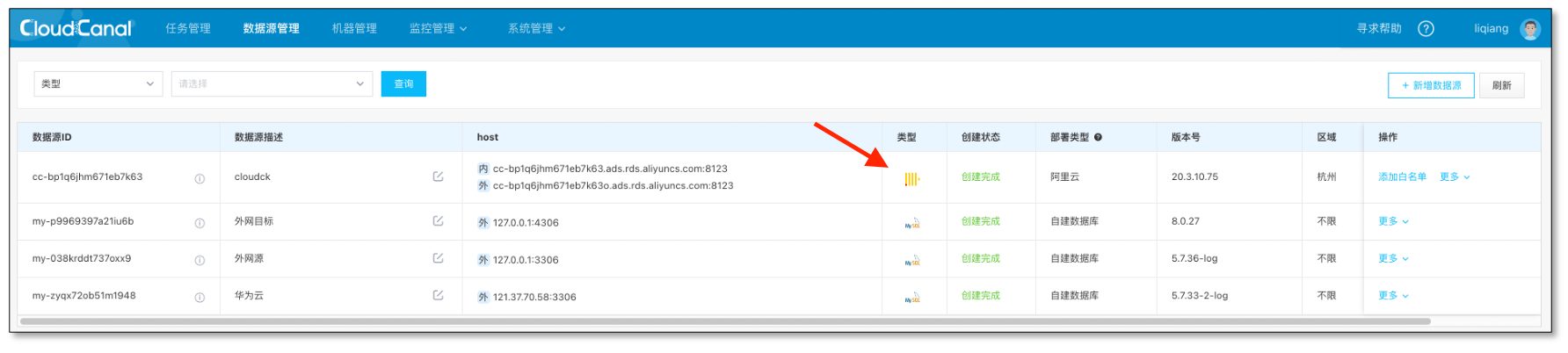
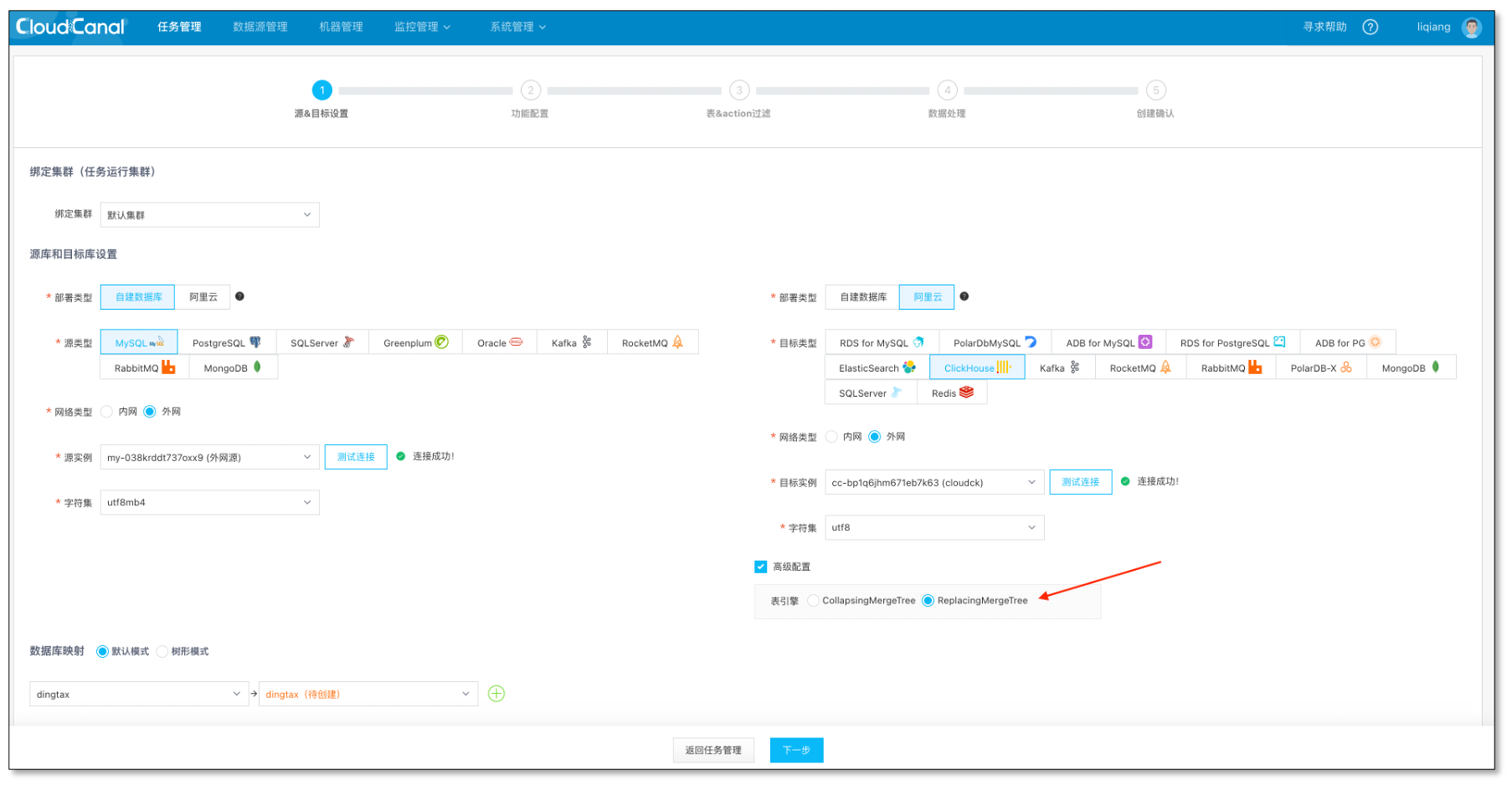

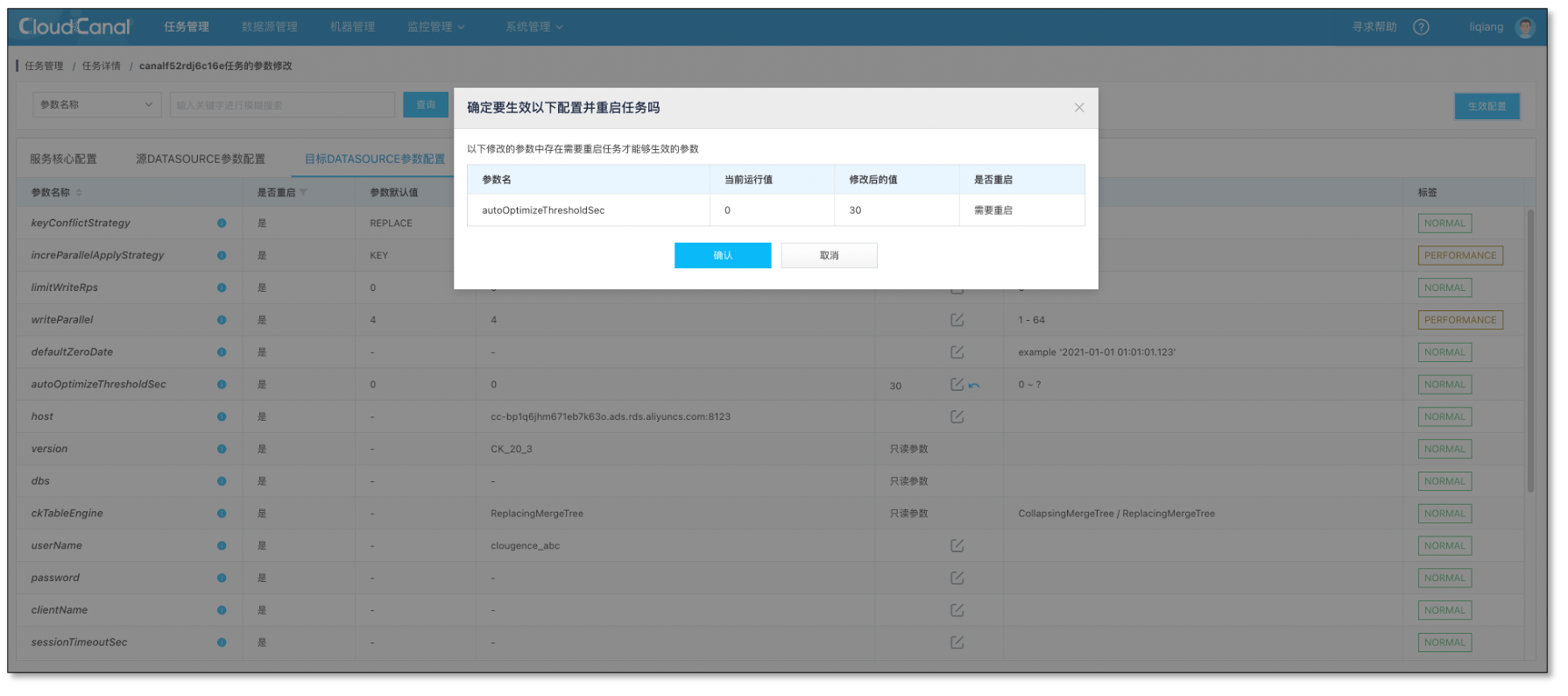

常见问题
新方案还存在什么问题
目前并未支持集群(distribute 表),所以如果 ClickHouse 是一个集群,还需要进一步增强。
另外结构迁移和增量对于 partition key 设置的支持,以及其他个性化表结构定义支持,还没有做到位。
还支持其他数据源么
我们目前收到比较多Kafka、SqlServer、MongoDB、Oracle 到 ClickHouse 的需求,目前 SqlServer 我们目前正在支持中,Kafka 、MongoDB 、Oracle 源端已经支持,打通 ClickHouse 链路我们会在合适的时间同时打开。
总结
本文简要介绍了 CloudCanal 实现 MySQL到 ClickHouse 数据迁移同步的进阶能力,相比于老方案,优势明显。如果各位有需求,可以尝试使用下我们的社区版免费体验。最后,如果各位觉得这篇文章还不错,请点赞、评论加转发吧。
更多精彩
- 5分钟搞定 MySQL 到 MySQL 异构在线数据迁移同步-CloudCanal 实战
- 5分钟搞定 MySQL 到 ElasticSearch 迁移同步-CloudCanal 实战
- 5分钟搞定 MySQL 到 TiDB 迁移同步-CloudCanal 实战
- 构建基于Kafka中转的混合云在线数据生态-cloudcanal实战
- 异地多活基础之数据双向同步进阶篇-CloudCanal实战
- MySQL 到 ElasticSearch 实时同步构建数据检索服务的选型与思考
社区快讯
- 我们创建 CloudCanal 微信粉丝群啦,在里面,你可以得到最新版本发布信息和资源链接,你能看到其他用户一手评测、使用情况,你更能得到热情的问题解答,当然你还可以给我们提需求和问题。快快加入吧。
- 扫描下方二维码,添加我们小助手微信拉您进群,接头语(“加 CloudCanal 社区群”)

加入CloudCanal粉丝群掌握一手消息和获取更多福利,请添加我们小助手微信:suhuayue001
CloudCanal-免费好用的企业级数据同步工具,欢迎品鉴。
了解更多产品可以查看官方网站: http://www.clougence.com
CloudCanal社区:https://www.askcug.com/















 3863
3863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









