







本文实际使用的是KaiwuDB的社区开源版本KWDB。
一、序列概括:
随着物联网技术在各行业的使用将越来越广,物联网与人工智能的深度结合,特别是在智能家居、智慧城市、工业4.0等领域有着广泛的应用,AIoT(Artificial Intelligence of Things)正成为企业实现智能化转型的关键路径。
不同于传统在Java、Python等技术红海的当下,AIoT融合AI技术和IoT技术,通过物联网产生、收集来自不同维度的、海量异构设备接入、跨模态数据融合、低延迟处理和智能分析等新需求不断涌现,对数据平台提出了更高、更快、更稳有了新的要求,那么,KWDB为 AIoT 而生的分布式多模数据库正是由此而生。
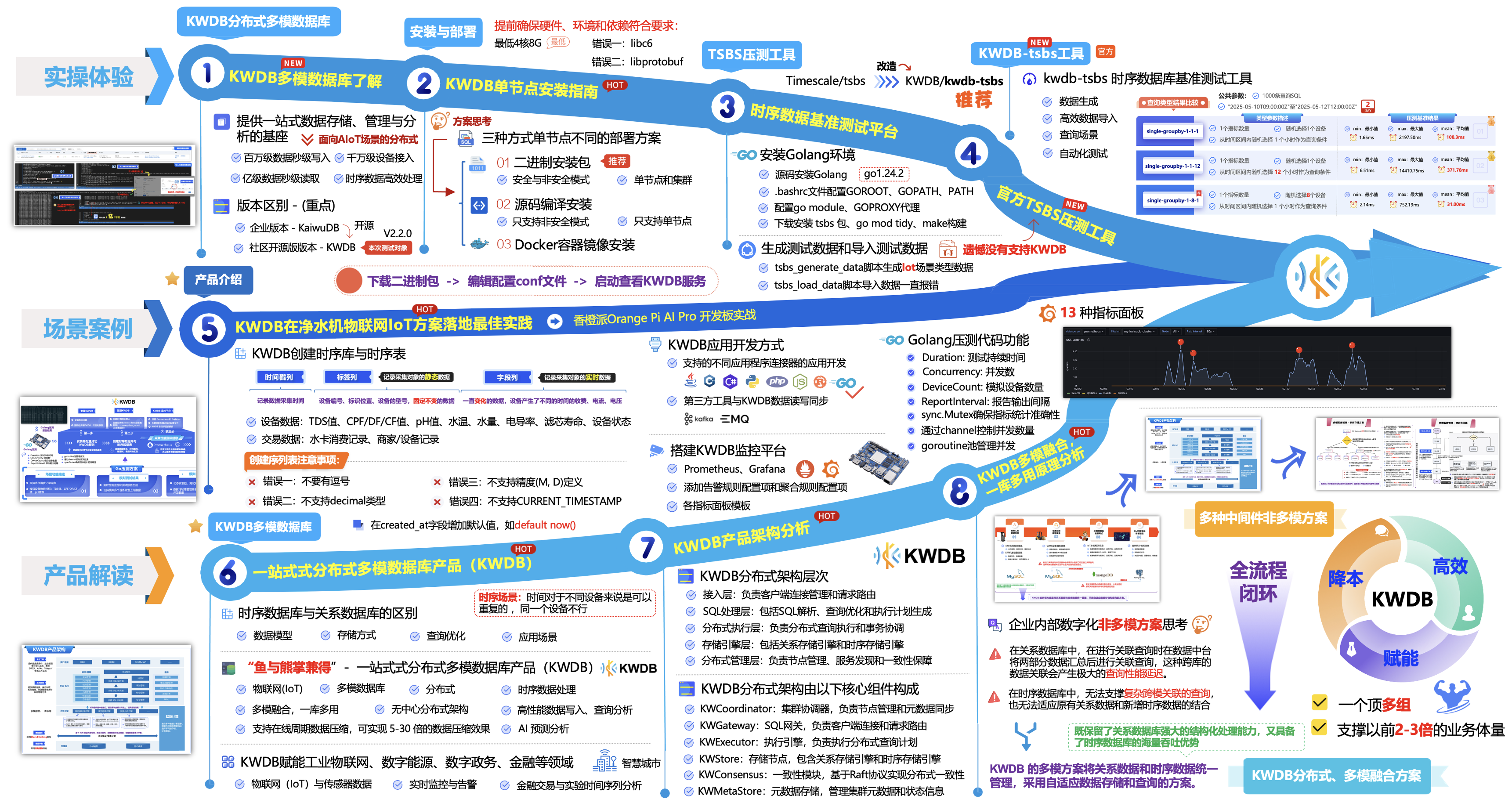
接下来,将从3个方向一起来由浅到深、由外到内的一起来探索今天的主角一款基于KWDB分布式多模数据库研发开源产品,废话不多说,让我们先做一个简单的了解,并且进行KWDB单节点安装,同时,使用KWDB-tsbs工具进行相关性能的压测。
二、正文前言:
海量时序数据的存储处理与复杂的数据查询分析任务,随着业务扩张带来的运输设备数据量增长,高扩展性的集群 IoTDB 架构可实现秒级扩容,这一特性能稳定、方便地管理庞大体量的运输时序数据。
作为一款运行稳定、性能高效、安全可靠的时序数据库产品,IoTDB 凭借其高效的时序数据管理和低延迟查询能力,有效应对交通运输行业中的数据爆发式增长,为列车、船舶、汽车等构建起稳定可靠的智能交通系统管理基础,为智能化和自动化提供了重要支撑。
今天带大家来了解一款基于浪潮 KaiwuDB 分布式多模数据库研发开源 – “KWDB”,KWDB 是由开放原子开源基金会孵化及运营的开源项目,是一款面向 AIoT 场景的分布式多模数据库产品,支持在同一实例同时建立时序库和关系库并融合处理多模数据,具备千万级设备接入、百万级数据秒级写入、亿级数据秒级读取等时序数据高效处理能力,具有稳定安全、高可用、易运维等特点。
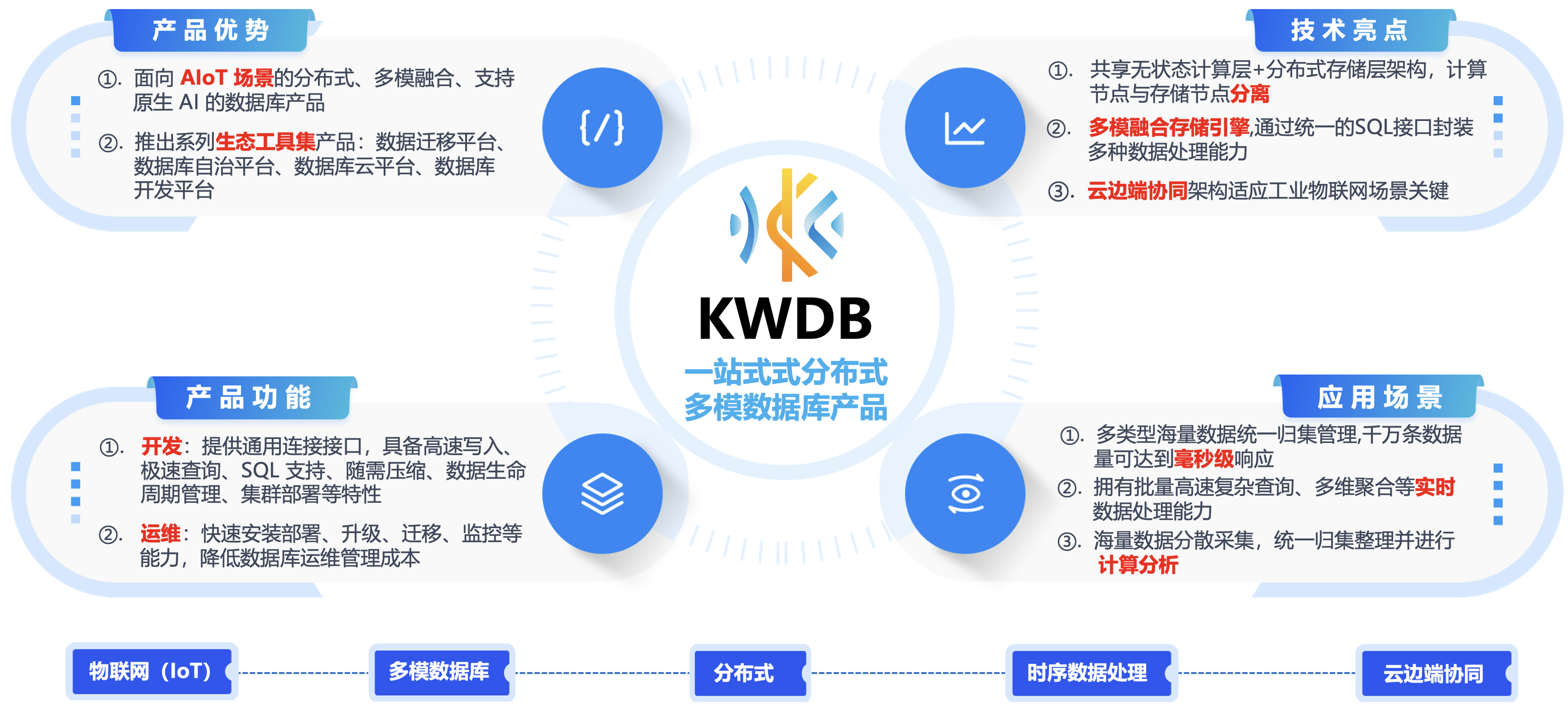
- ①. 为开发者提供通用连接接口,具备高速写入、极速查询、SQL 支持、随需压缩、数据生命周期管理、集群部署等特性,与第三方工具无缝集成,降低开发及学习难度,提升开发使用效率。
- ②. 为运维管理人员提供快速安装部署、升级、迁移、监控等能力,降低数据库运维管理成本。
三、KWDB单节点安装指南:
本文以Vagrant的“Ubuntu 22.04.5 LTS”版本为例,演示一下KWDB 三种方式单节点不同的部署方案。
3.1 硬件配置:
下表列出部署 KWDB 所需的硬件规格,实际部署时,用户可以根据实际的业务规模和性能要求规划硬件资源。
| 项目 | 要求 |
|---|---|
| CPU 和内存 | 单节点配置建议不低于 4 核 8G。对于数据量大、复杂的工作负载、高并发和高性能场景,建议配置更高的 CPU 和内存资源以确保系统的高效运行。 |
| 磁盘 | ①. 推荐使用 SSD 或者 NVMe 设备,尽量避免使用 NFS、CIFS、CEPH 等共享存储。 ②. 磁盘必须能够实现 500 IOPS 和 30 MB/s 处理效率。 |
| 文件系统 | 建议使用 ext4 文件系统。 |
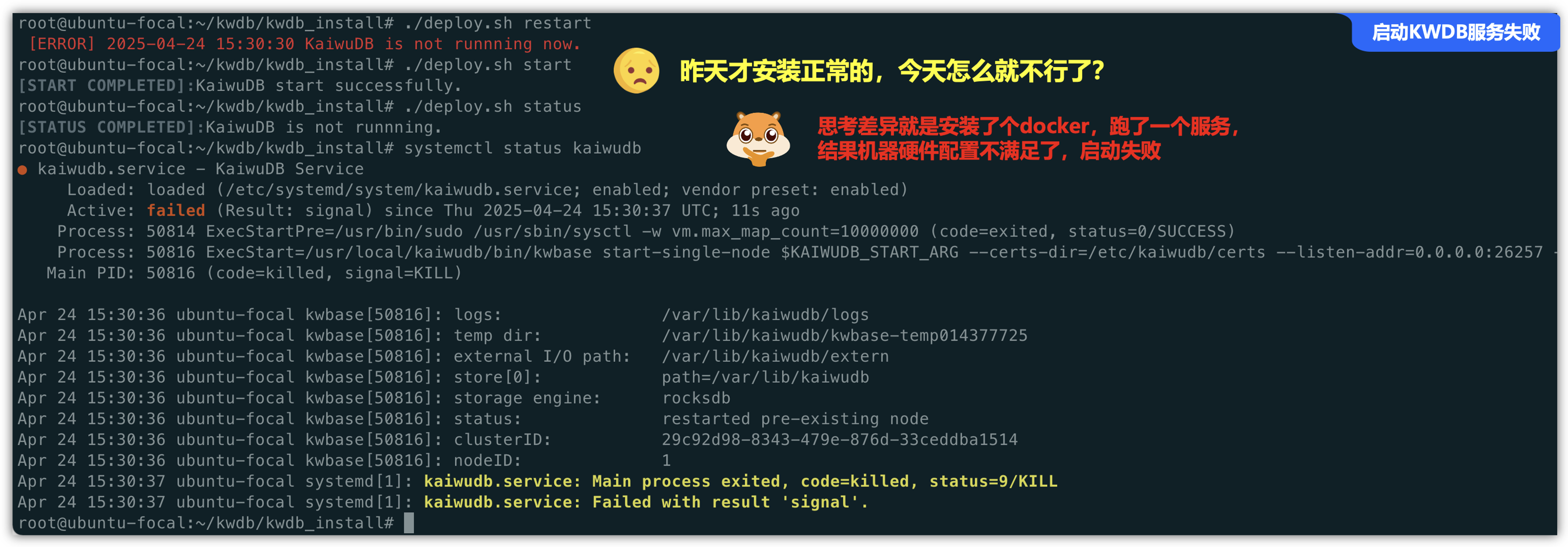
真实案例:
以下为在测试环境中昨天安装正常可以运行的KWDB服务,第二天测试就启动失败,将服务卸载重新安装也是依旧,排查了老半天,仔细回想这2天的差异就是因为安装了docker跑了一个服务,结果机器硬件配置不满足,导致一直启动失败。
3.2 软件依赖:
安装时,KWDB 会对依赖进行检查,如果缺少依赖会退出安装并提示依赖缺失。不同操作系统及安装包的依赖略有不同,请根据实际安装包类型及操作系统,在部署前安装好相应的依赖。下表列出需要在目标机器安装的依赖:
| 依赖 | 版本 |
|---|---|
| OpenSSL | v1.1.1+ N/A |
| libprotobuf | v3.6.1+ 注:Ubuntu 18.04 默认的 libprotobuf 版本不满足要求,用户需要提前安装所需版本(推荐 3.6.1 和 3.12.4)。 |
| GEOS | v3.3.8+ 可选依赖 |
| xz-libs | v5.2.0+ N/A |
| squashfs-tools | any N/A |
| libgcc | v7.3.0+ N/A |
| mount | any N/A |
| squashfuse | any 可选依赖 |
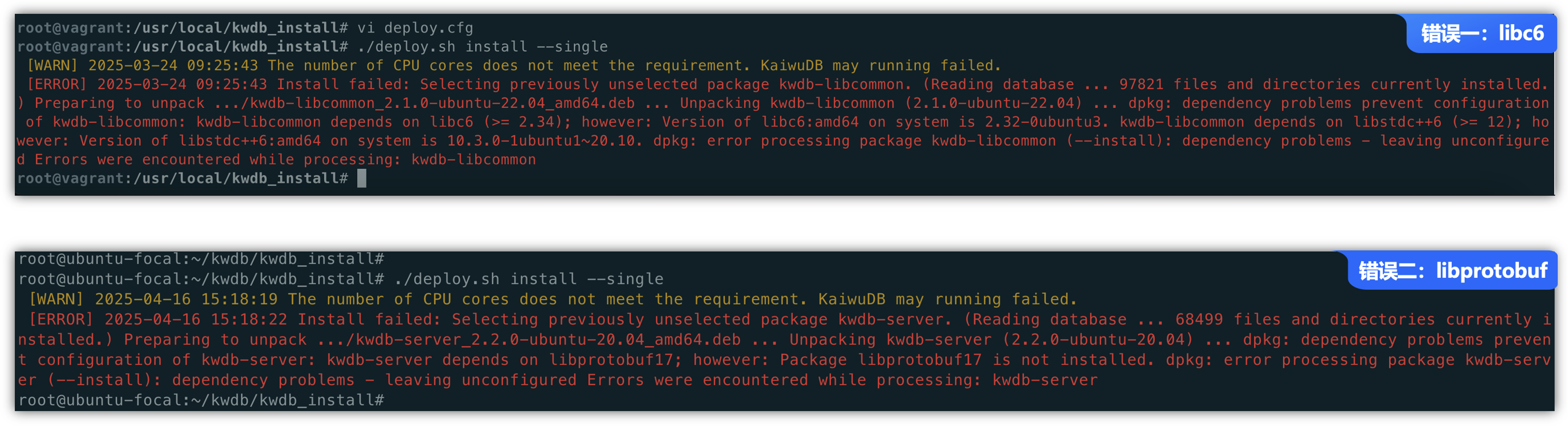
真实案例:
如果没有提前安装相关依赖,就会在安装包KWDB时,可以看到以下报错提示,表示缺少哪些依赖文件:
Install failed: Selecting previously unselected package kwdb-libcommon. (Reading database ... 97821 files and directories currently installed) Preparing to unpack .../kwdb-libcommon_2.1.0-ubuntu-22.04_amd64.deb ... Unpacking kwdb-libcommon(2.1.0-ubuntu-22.04)... dpkg: dependency problems prevent configuration of kwdb-libcommon: kwdb-libcommon depends on libc6(>= 2.34); however: Version of libc6:amd64 on system is 2.32-0ubuntu3.kwdb-libcommon depends on libstdc++6 (>= 12); ho wever: Version of libstdc++6:amd64 on system is 10.3.0-1ubuntu1~20.10. dpkg: error processing package kwdb-libcommon (--install): dependency problems - leaving unconfigure d Errors were encountered while processing:kwdb-libcommon
在安装KWDB 的过程中,安装脚本对针对硬件配置、运行环境、软件依赖、配置文件等方面进行检查:
- ①. 如果相应硬件未能满足要求,系统将继续安装,并提示硬件规格不满足要求。
- ②. 如果软件依赖未能满足要求,系统将中止安装,并提供相应的提示信息。
3.3 安装三种模式:
KWDB可以支持用户根据自己的需求,选择二进制安装包、容器和源码的方式,进行安装与试用 KWDB 数据库,本次体验KWDB的版本号为“V2.2.0”,下载安装前勿必匹配对应的版本,避免出现版本不匹配导致的安装失败。

- ①. 二进制安装包:支持单机和集群以及安全和非安全部署模式(个人比较推荐)。
- ②. 容器镜像:KWDB 技术支持人员提供可供下载的容器镜像,如需以容器方式部署 KWDB。
- ③. 源码:源码编译目前支持单节点非安全模式部署,而且make安装时间较长。
3.4 KWDB二进制安装包单节点部署:
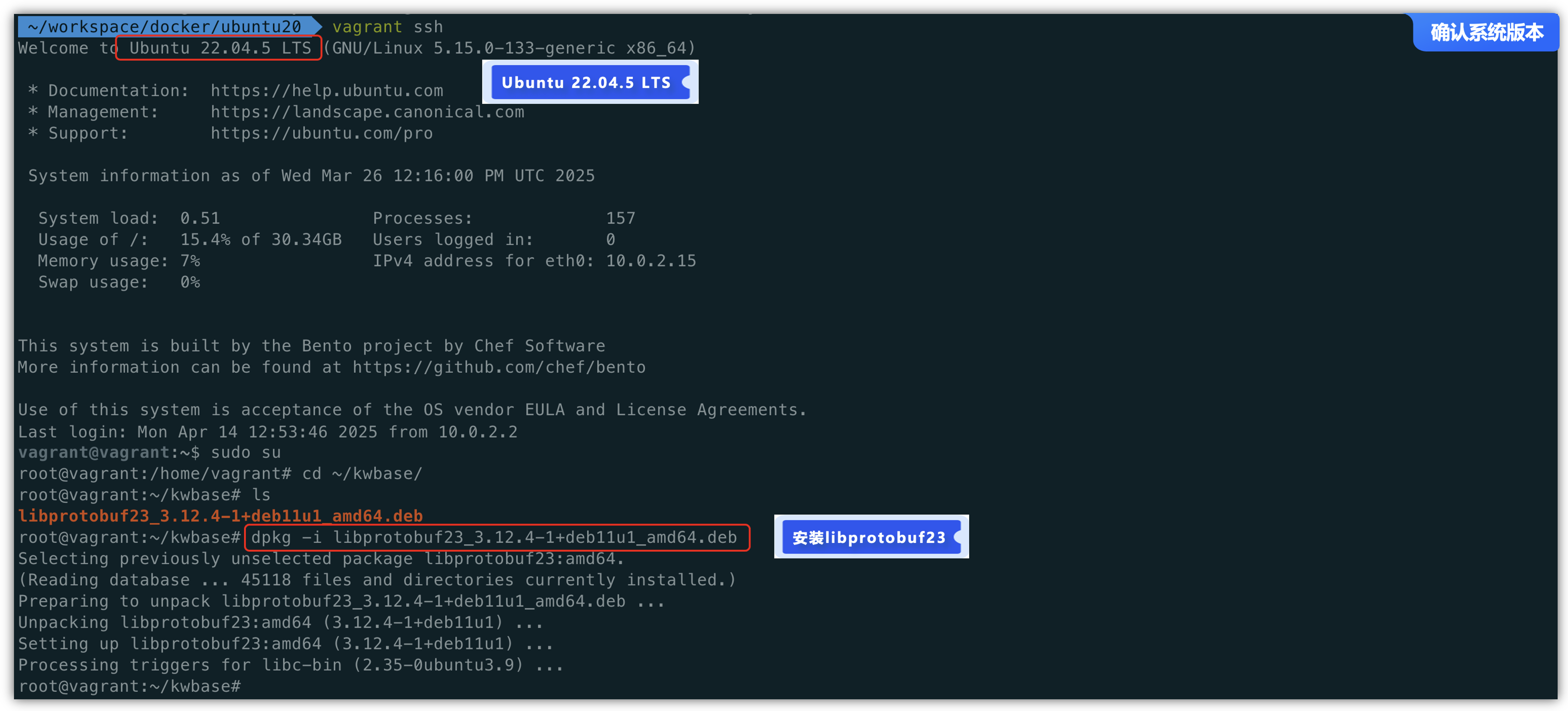
首先我们使用的服务器版本是Ubuntu 22.04.5 LTS的版本,为了更贴近实验效果,可以选择与我的版本一致,安装“libprotobuf23”依赖,安装时,请注意版本“3.12.4”。
dpkg -i libprotobuf23_3.12.4-1+deb11u1_amd64.deb
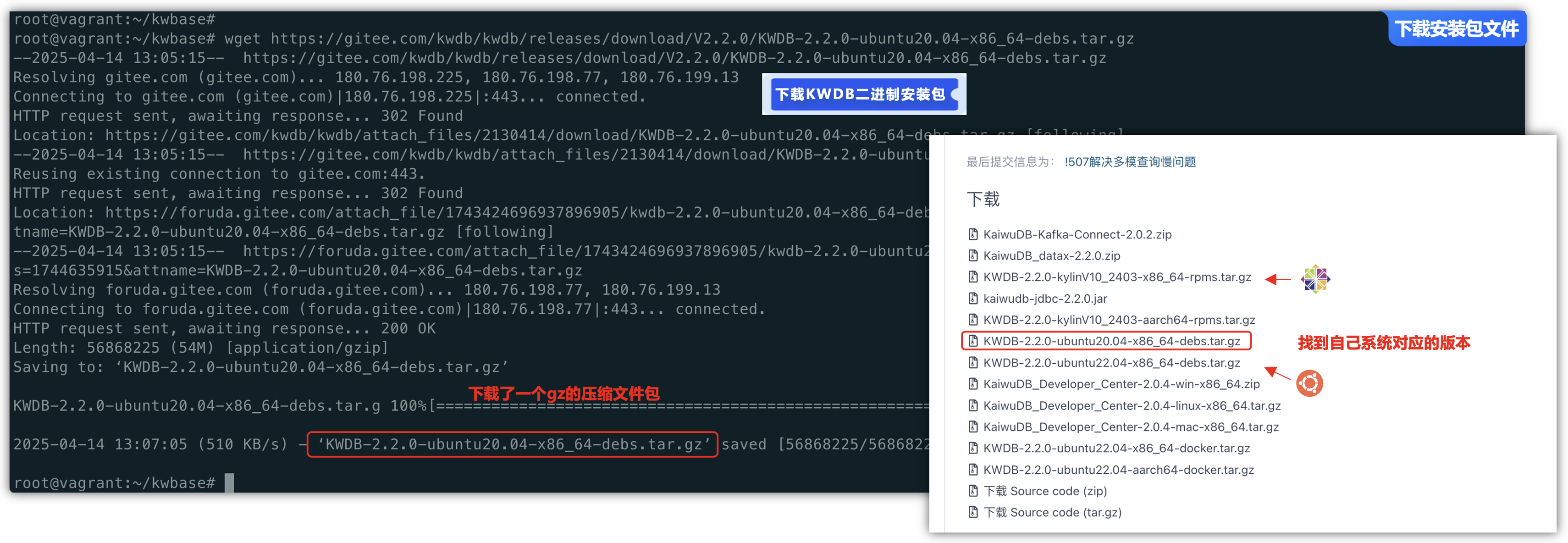
打开kwdb发行版本页面可以进行获取系统环境对应的 DEB 或 RPM 安装包,将安装包复制到待安装 KWDB 的目标机器上,然后解压缩安装包:
wget https://gitee.com/kwdb/kwdb/releases/download/V2.2.0/KWDB-2.2.0-ubuntu20.04-x86_64-debs.tar.gz
接着将下载的gz二进制KWDB安装包进行解压缩:
tar -zxvf ./KWDB-2.2.0-ubuntu20.04-x86_64-debs.tar.gz
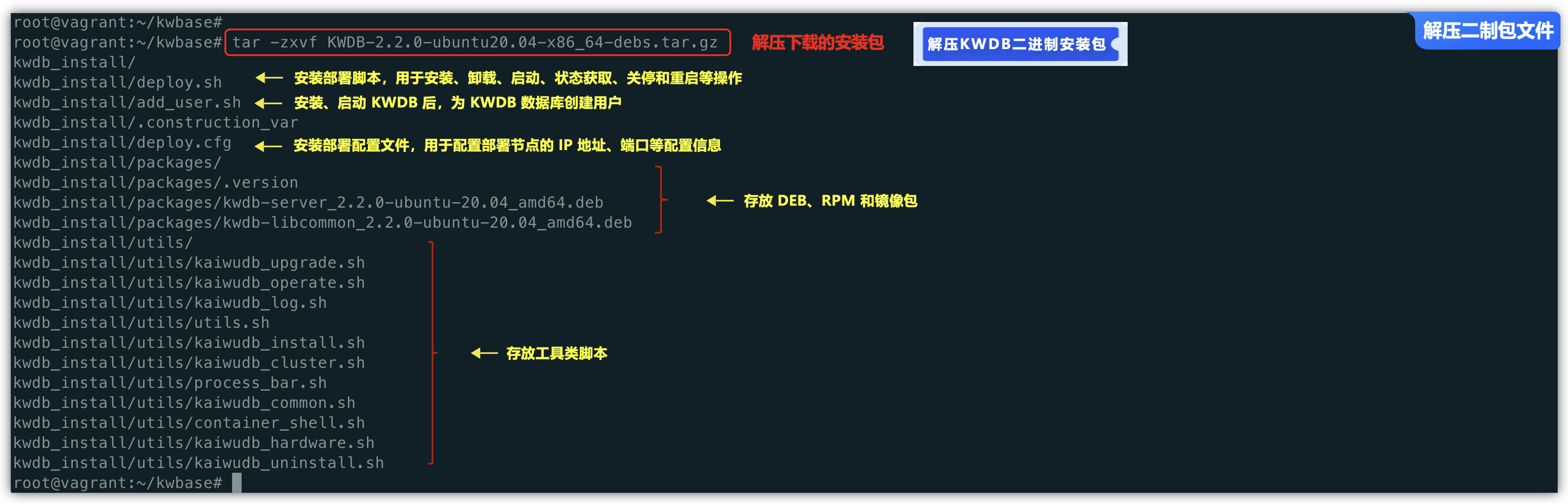
解压后生成的目录包含以下文件:
| 文件 | 说明 |
|---|---|
| add_user.sh | 安装、启动 KWDB 后,为 KWDB 数据库创建用户 |
| deploy.cfg | 安装部署配置文件,用于配置部署节点的 IP 地址、端口等配置信息 |
| deploy.sh | 安装部署脚本,用于安装、卸载、启动、状态获取、关停和重启等操作 |
| packages | 存放 DEB、RPM 和镜像包 |
| utils | 存放工具类脚本 |
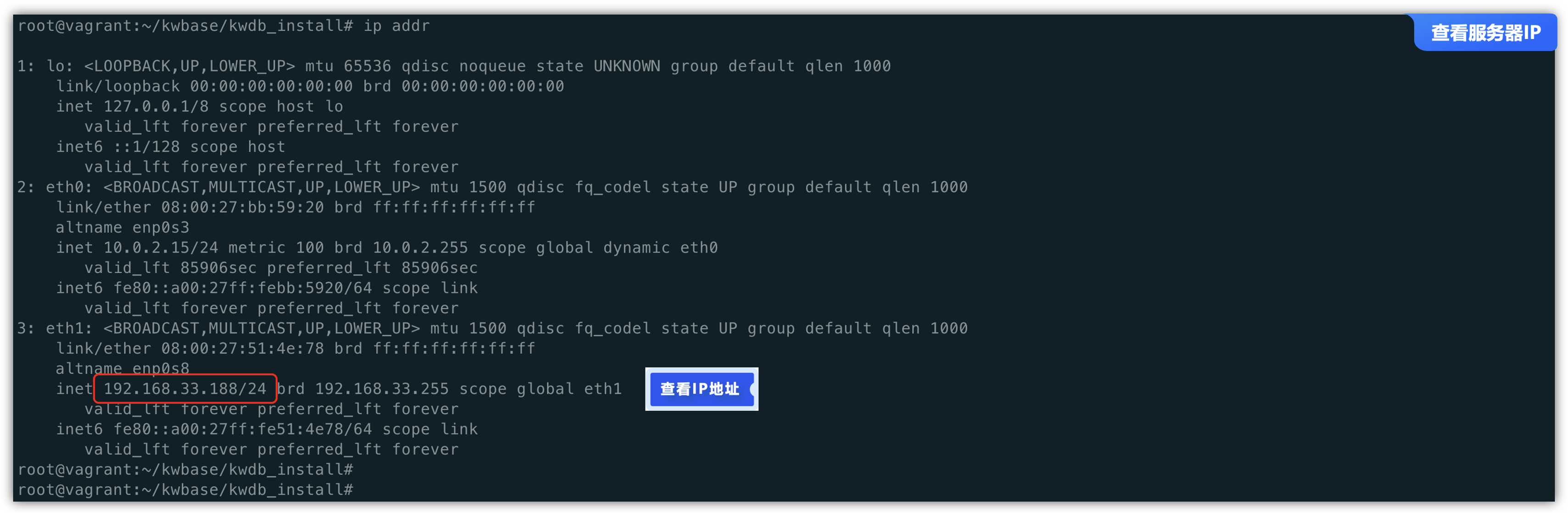
查看服务器的IP地址,将用于配置本地节点对外提供服务的 IP 地址:
ip addr
修改kwbase_install/deploy.cfg安装部署配置文件,用于配置部署节点的 IP 地址、端口等配置信息:
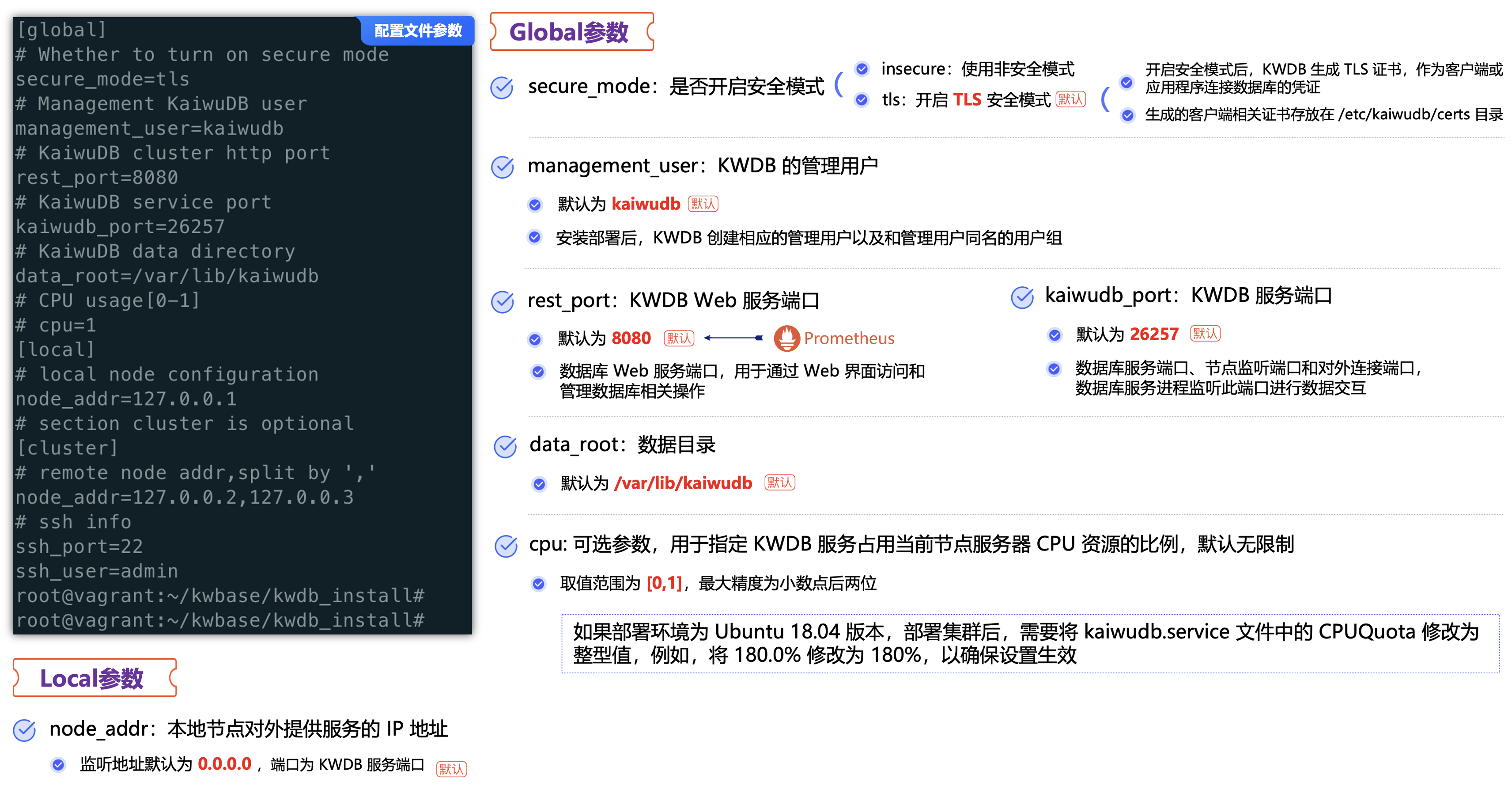
因为目前只是为了演示单节点配置,所以将cluster以下相关代码进行注释,修改node_addr的地址为本机的IP地址192.168.33.188。
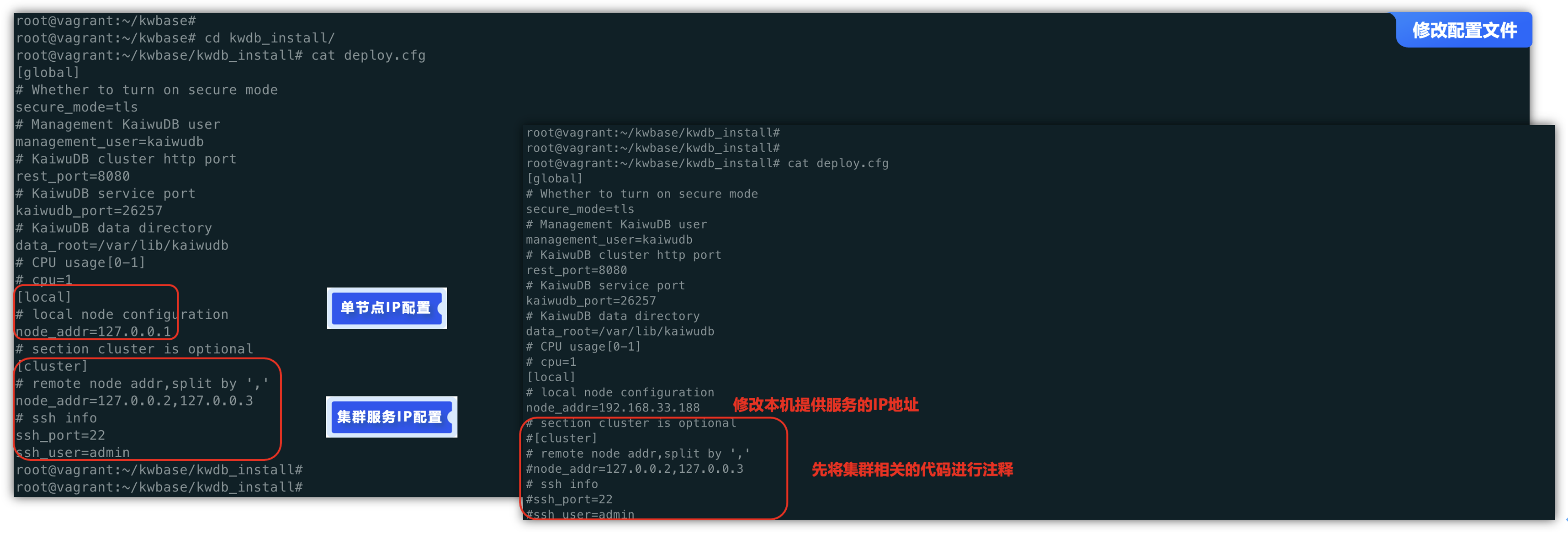
修改完配置文件后,执行安装命令,期间会提示输入一个数据库的管理员密码,请注意进行保管,在安装提示“INSTALL COMPLETED: KaiwuDB has been installed successfuly! …”就是表示安装成功了。
# 执行单机部署安装命令
./deploy.sh install --single
# 根据系统提示重新加载 systemd 守护进程的配置文件。
systemctl daemon-reload
# 查看服务的状态
systemctl status kaiwudb
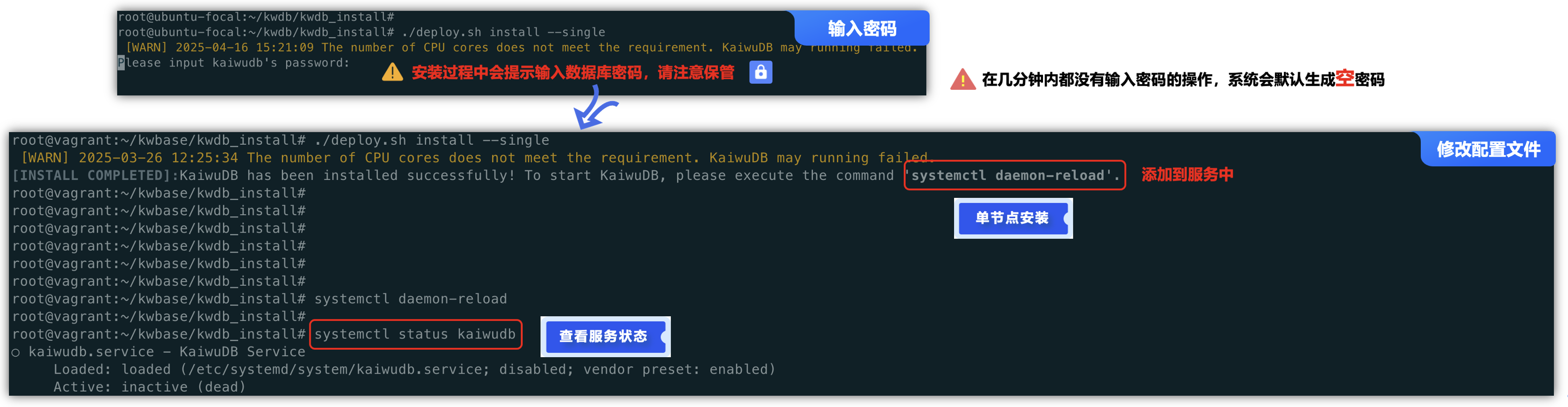
查看服务的状态时,发现是没有进行启动的,这里有2种方式可以启动与查看KWDB节点的状态:
- ①. 使用自带的./deploy.sh脚本来启动数据库服务。
- ②. 使用服务管理器命令行工具systemctl start kaiwudb来启动数据库服务(推荐)。

# 启动数据库服务
systemctl start kaiwudb
# 查看数据库服务启动后的状态
systemctl status kaiwudb
# 配置 KWDB 开机自启动
systemctl enable kaiwudb
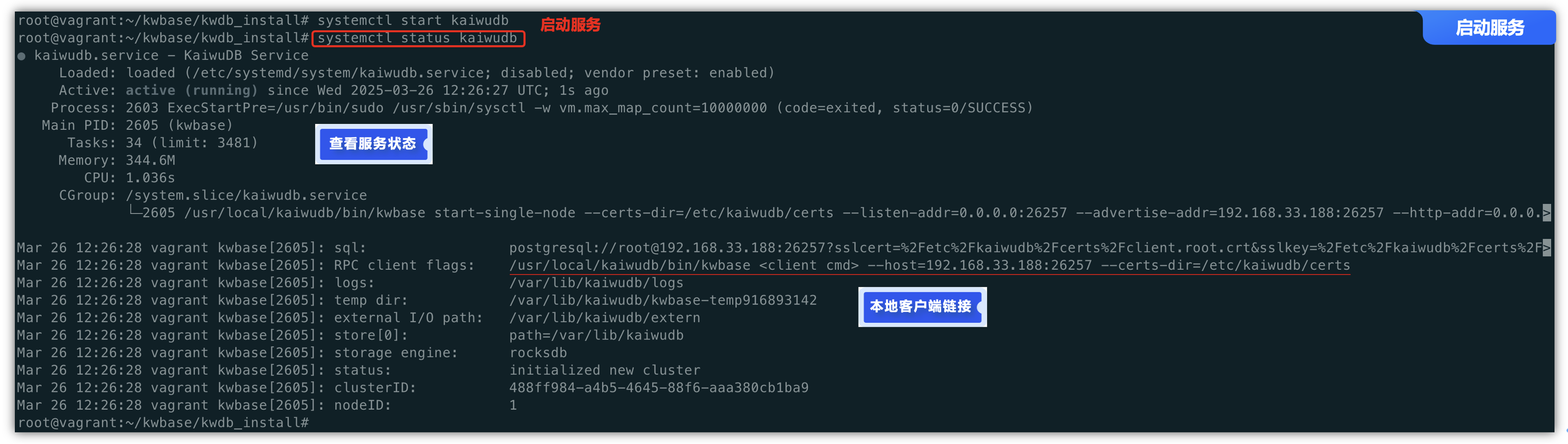
通过查看 KWDB 节点状态,我们可以看到一个RPC客服端链接的示例代码,可以进行KWDB SQL的shell链接到数据库,接下来就可以进行数据库的访问管理操作,比如下面执行查看所有数据库的命令。
/usr/local/kaiwudb/bin/kwbase sql --host=192.168.33.188:26257 --certs-dir=/etc/kaiwudb/certs
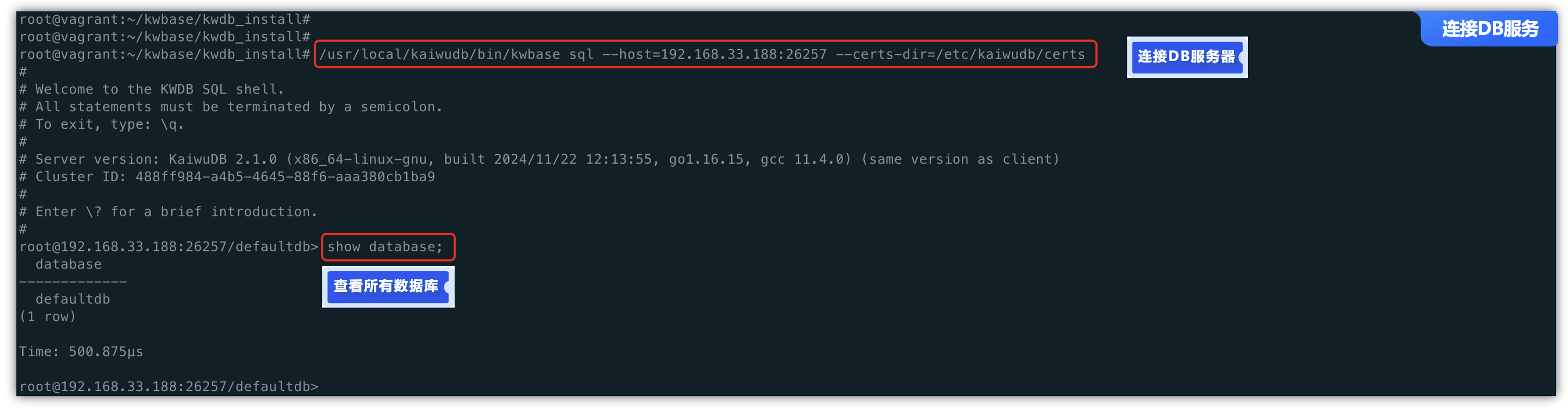
至此,KWDB单机时序数据库就已安装完成,过程也是比较简单,在安装之前确认一下必要的依赖安装到即可,不过,连接数据库的方式倒是第一次接触使用证书来连接,之前接触mysql直接输入用户名和密码即可连接,KWDB的方式在安全性方面更高一点。
3.5 卸载KWDB服务:
如果需要进行卸载 KWDB 单机版本,先进入 kaiwudb_install 目录,输入卸载命令,在提示“先确认是否删除数据目录”,在输入 y 之后将删除数据目录,即可取消 KWDB 数据目录下的 loop 设备挂载。
./deploy.sh uninstall
When uninstalling KaiwuDB, you can either delete or keep all user data. Please confirm your choice: Do you want to delete the data? (y/n):
[UNINSTALL COMPLETED]: KaiwuDB has been uninstalled successfully.
最后,卸载完成后,控制台输出信息:KaiwuDB has been uninstalled successfully,就表示卸载KWDB服务成功了。

四、Linux平台安装TSBS压测工具:
TSBS(Time Series Benchmark Suite) 是一个时序数据处理(数据库)系统的性能基准测试平台,提供了 IoT、DevOps 两个典型应用场景,广泛应用于物联网(IoT)、工业互联网、IT运维、电力监测等领域,它由 Timescale 开源并负责维护。
TSBS作为一个性能基准测试平台,TSBS 具有便捷、易用、扩展灵活等特点,通常可以模拟处理海量、高频率、实时性强的时间序列数据,可以很好的针对数据库的性能和可靠性进行测试。涵盖了时序数据的生成、写入(加载)、多种类别的典型查询等功能,并能够自动汇总最终结果。
因为TSBS工具是使用 Golang 语言开发的,所以,可以通过 go get 命令快捷获取并进行安装。
4.1 安装Golang环境:
首先,可以打开Golang的官网,来查看一下现在最新的版本是多少?我们这里使用go1.24.2最新的版本,如果您有Go相关的环境,可以跳过这一步骤。
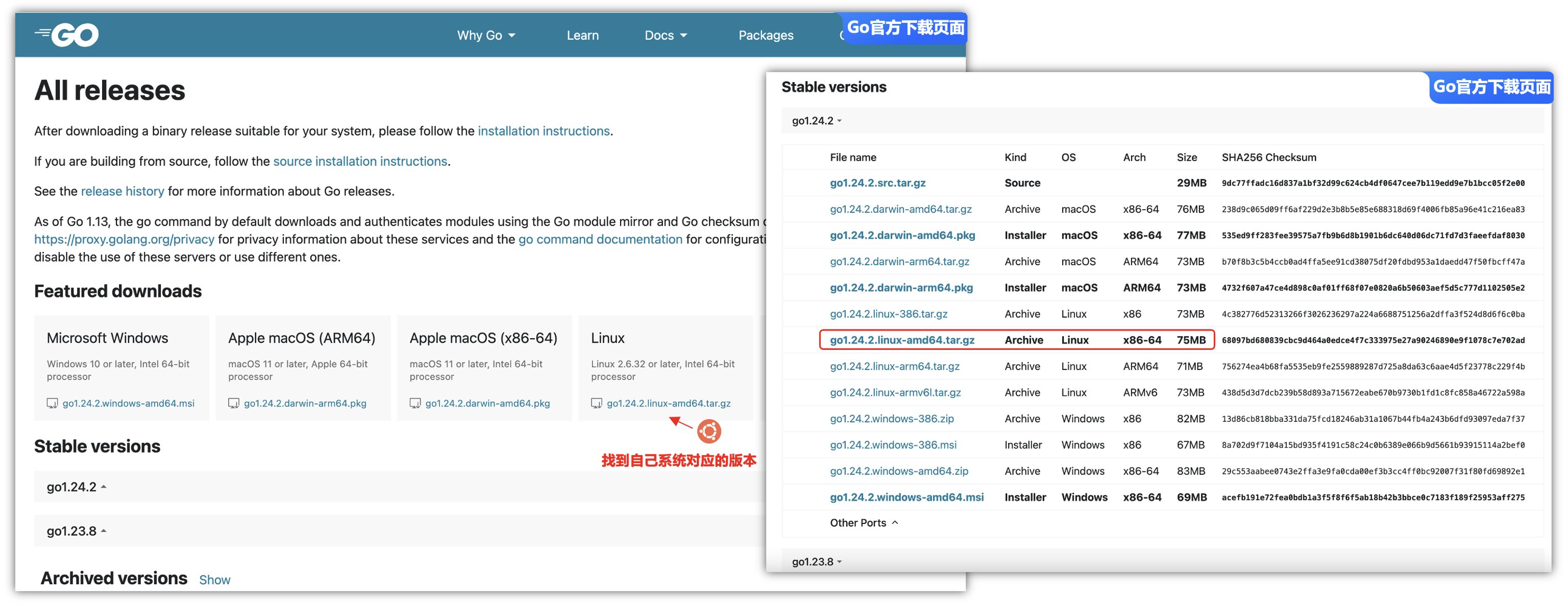
这里有三种不同的安装方式,有macOS、Linux、Windows不同的环境,我们这里使用的是Linux环境的安装方式,大家可以根据自己的环境安装对应的版本。
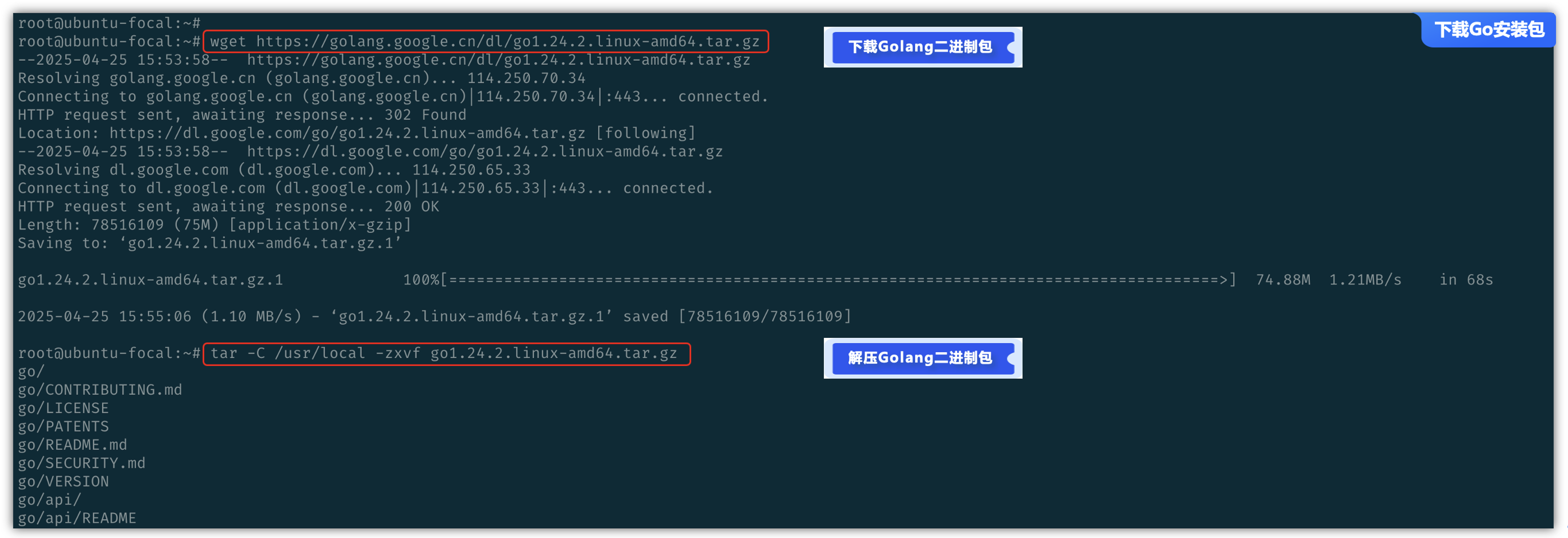
# 将linux安装包下载到本地
wget https://golang.google.cn/dl/go1.24.2.linux-amd64.tar.gz
# 解压下载的安装包
tar -C /usr/local -zxvf go1.24.2.linux-amd64.tar.gz
解压完成后,我们需要在~/.bashrc文件中,配置go相关的环境变量,比如go默认安装路径、工作空间目录、可执行bin目录等信息,最后通过source命令将设置的配置文件重新加载一下。
接下来通过go version可以来查看一下版本信息,输出“go version go1.24.2 linux/amd64”表示安装成功。
# GOROOT表示设置为go安装默认的路径,会自动安装到这个目录下
export GOROOT=/usr/local/go
# GOPATH表示默认的 Golang 项目的工作空间,有多个使用分号分隔
export GOPATH=$HOME/go-work
# PATH表示可执行文件路径
export PATH=$PATH:$GOROOT/bin
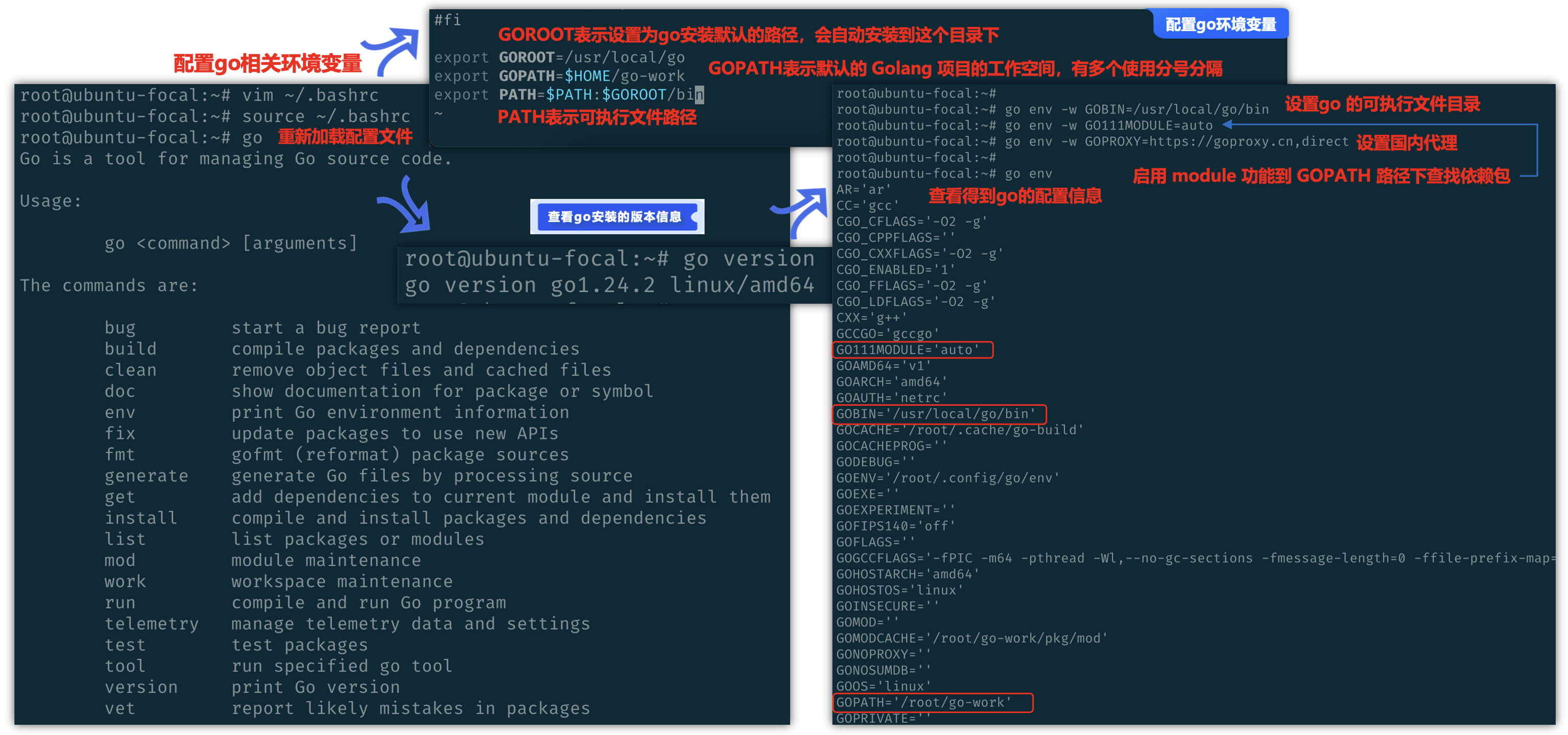
接下来,因为我们要使用到go mod 包管理工,go modules 是 golang 1.11 新加的特性。go命令直接支持使用modules,包括记录和解析对其他模块的依赖性,但是如果需要使用 go mod,需要修改 go 的配置信息如下
# 设置go 的可执行文件目录
go env -w GOBIN=/usr/local/go/bin
# 启用 module 功能到 GOPATH 路径下查找依赖包
go env -w GO111MODULE=auto
# 设置国内代理
go env -w GOPROXY=https://goproxy.cn,direct
4.2 安装TSBS工具(可跳过直接观看后面官方工具的支持):
这一步需要注意,因为在测试的当时官方的kwdb-tsbs工具还没出来,所以,自己做了一些尝试,不过,可以有想给其它的数据库进行测试的可以进行参考。
通过go mod初始化一个项目,并且使用go get安装tsbs包,然后再到tsbs包下面,进行更新 go.mod文件,最后使用make自动化构建工具进行构建。
# 初始化一个项目
mkdir kwdbtsbs && cd kwdbtsbs
# 初始化一个 module
go mod init kwdbtsbs
# 删除错误或者不使用的 modules
go mod tidy
# 下载安装 tsbs 包
go get github.com/timescale/tsbs
# 进入 tsbs 包文件夹中
cd $GOPATH/src/github.com/timescale/tsbs
# 更新 go.mod 和 go.sum 文件
go mod tidy
# 自动化构建工具
make
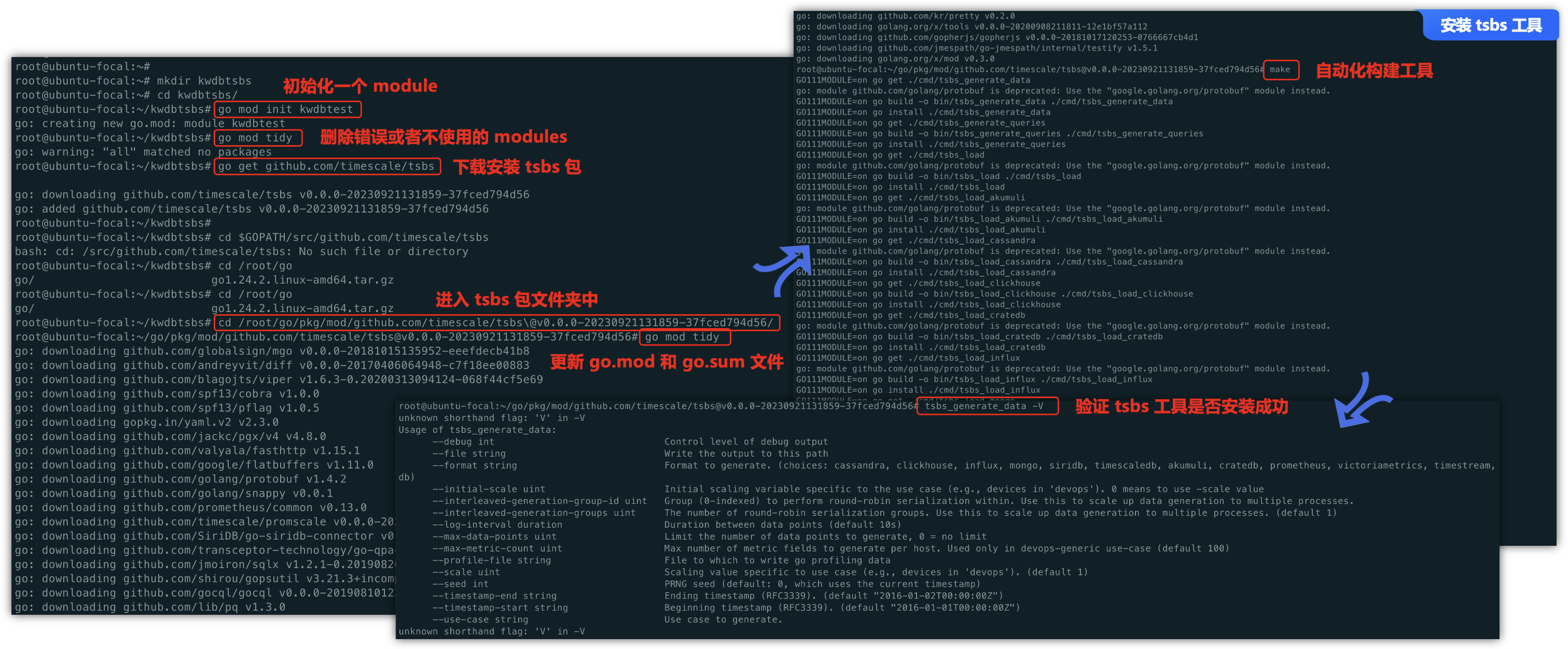
make构建完成后,我们可以使用tsbs_generate_data 执行一下,如果能看到输出信息,就表示安装tsbs成功了。
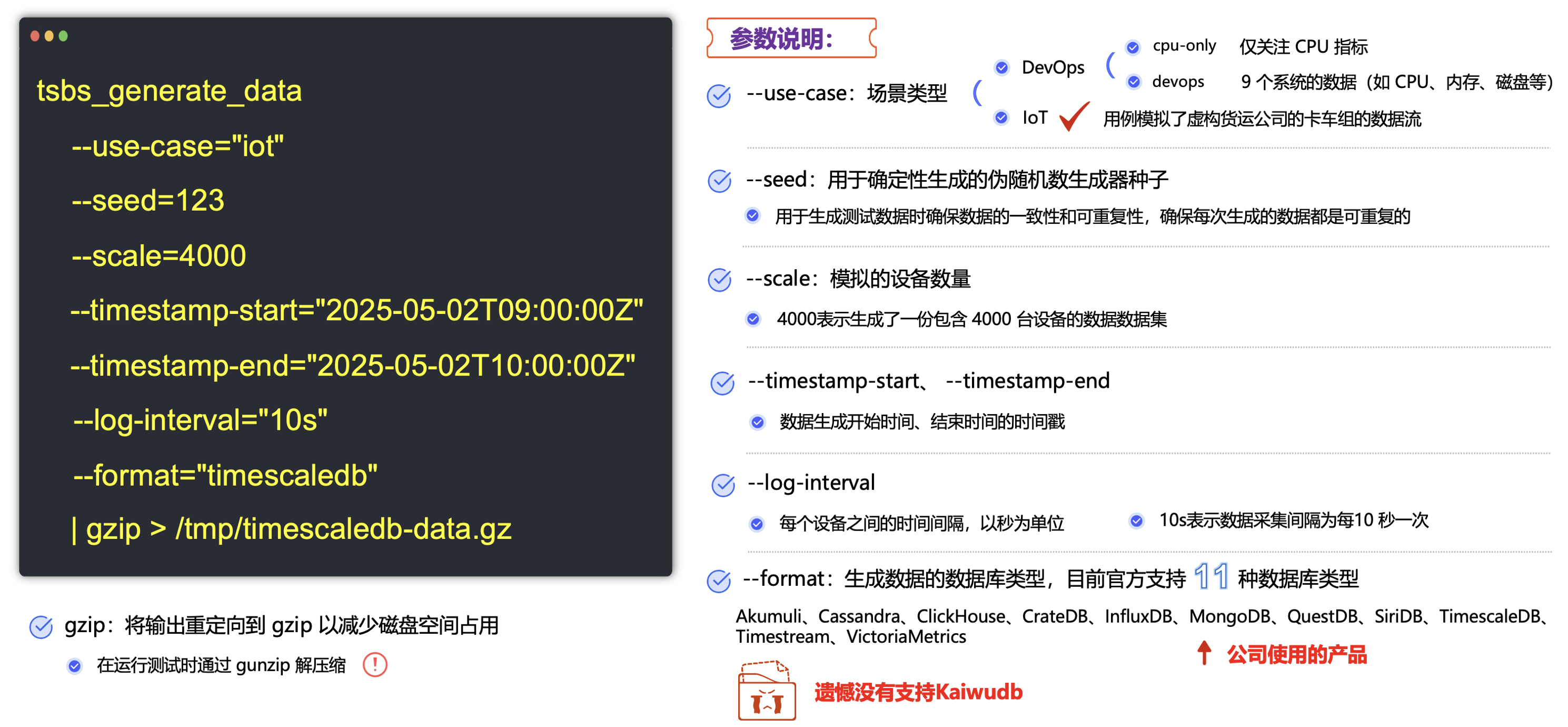
tsbs_generate_data是用于生成测试数据的启动文件,参数包括数据规模、时间范围等。使用 tsbs_generate_data 工具生成测试数据,如下例子中生成 cpu 相关的时序数据,时段为 2025-05-02T09:00:00 到 2025-05-02T10:00:00Z 这一天内每隔 10 秒一条数据,这些数据通过管道传输到指定的 gzip 文件中。
在实际操作中,这里在导入数据时,一直会发生报错“DROP TABLE IF EXISTS tags报错,提示语法错误”,在5.1假期查看源码、求助等多种方式均未成功,无赖只能向官方请求支持,官方也在一周时间给出了自己开源的工具 - kwdb-tsbs。

4.3 官方kwdb-tsbs高性能时序数据库基准测试工具:
kwdb-tsbs 是一个基于 Timescale/tsbs 改造的开源高性能时序数据库基准测试工具,完整支持 KWDB 的数据生成、导入和查询测试功能。接下来,我们可以来进行kwdb-tsbs的代码安装,这里我尝试了有两种安装方式:
- ①. 直接下载gitee源码在本地进行make安装即可在GOPATH目录下自动安装成功。
- ②. 类似Timescale/tsbs的方式,使用go get安装包进行下载,再进行安装,不过,这里需要设置一下gitee的GOPROXY即可(可自动搜索一下)。
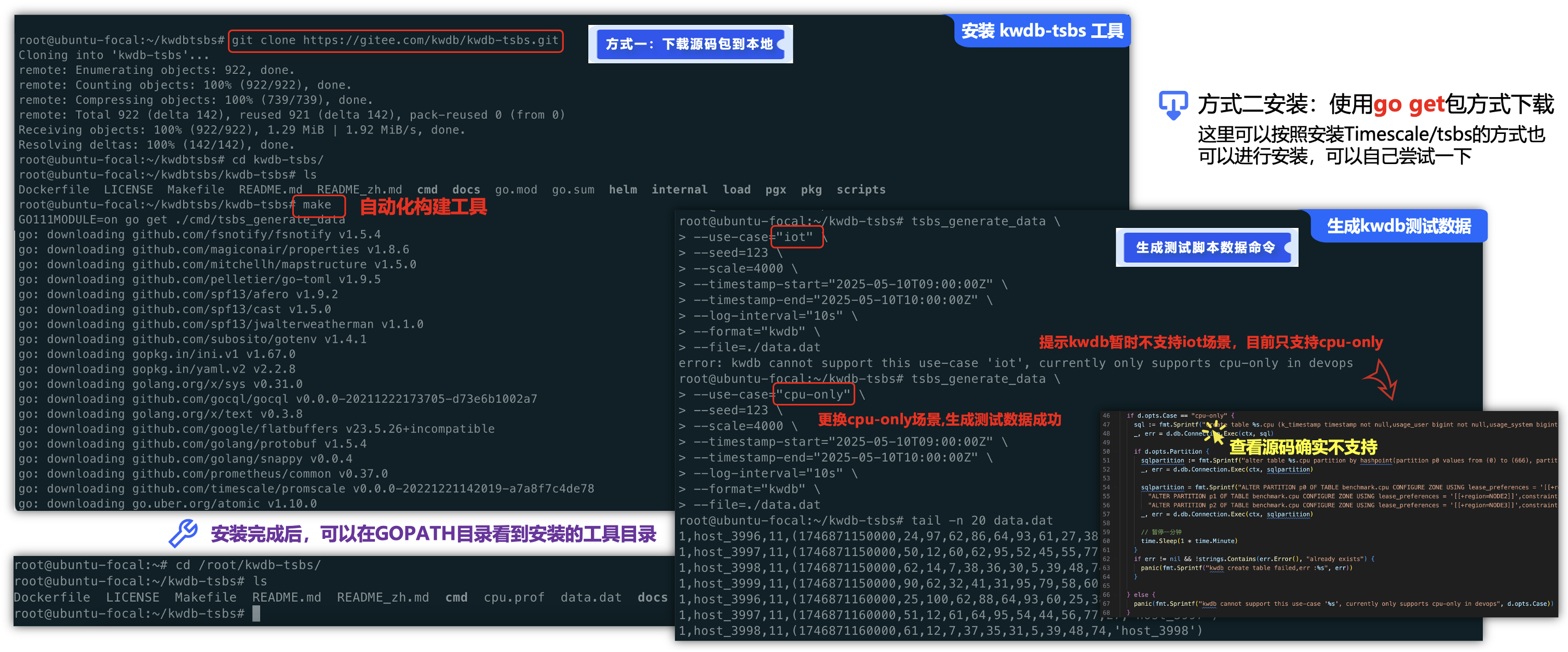
不过,这里测试了一下,目录kwdb-tsbs暂时不支持iot场景类型的压测基准数据集生成,我们去查看一下源码也确实发现不支持(希望官方也是能够尽快支持),那么只能更换修改cpu-only场景生成压测基准数据集。

为了更贴近生产压测效果,这里我们使用ECS云实例进行部署KWDB单节点数据库实例,这里选型的配置为4核8G的云实例,操作系统是Ubuntu20.04,在安装完KWDB数据库实例、KWDB-tsbs压测脚本,接下来进行测试:
4.3.1 生成压测基准数据集:
tsbs_generate_data \
--use-case="cpu-only" \
--seed=123 \
--scale=4000 \
--timestamp-start="2025-05-10T09:00:00Z" \
--timestamp-end="2025-05-15T10:00:00Z" \
--log-interval="10s" \
--format="kwdb" \
--file=./data.dat
上面的例子将生成一个可用于批量加载 KWDB 的文件,每个数据库都有自己的数据存储格式,使其对应的数据加载器最容易写入数据。上述配置将生成大约 1 亿7千万行(近20亿个指标),这里也可以看到数据集的文件大小有近12G,可以模拟一下大数据量写入的测试。
4.3.2 导入压测基准数据集:
tsbs_load_kwdb \
--host=47.97.155.7 --port=26257 --user=root --pass="123456" \
--db-name=benchmark \
--file=./data.dat \
--workers=10 \
--batch-size=10000 \
--reporting-period=10s \
--partition=false \
--insert-type=insert \
--case="cpu-only"
这里如果是在ECS这种云实例上,需要注意一下安全组的端口有没有开限制权限,比如防火墙之类的,如果开了的话,需要把端口的限制给取消掉,这里可以看到因为数据量比较大,我花费了近4个小时才把数据导入到KWDB中,最终查看数据库的记录是1亿7千万条数据。
4.3.3压测基准数据集结果分析:
// 给定的数据字符串
const data = `
1746972549,109999.92,1.908522E+09,122184.51,9999.99,1.735020E+08,11107.68
......
`;
// 按行分割数据
const lines = data.trim().split('\n');
// 初始化7个空数组来存储分割后的数据
const arrays = new Array(7).fill(null).map(() => []);
// 遍历每一行数据
lines.forEach(line => {
// 按逗号分割每一行数据
const values = line.split(',');
// 将分割后的数据分配到7个数组中
values.forEach((value, index) => {
arrays[index].push(value);
});
});
// 输出结果
arrays.forEach((array, index) => {
console.log(`数组 ${index + 1}:`, array);
});
// 时间戳格式化
function getTime(time) {var datetime=new Date(time * 1000)
var year = datetime.getFullYear();
var month = datetime.getMonth()+1;//js从0开始取
var date = datetime.getDate();
var hour = datetime.getHours();
var m = datetime.getMinutes();
var s = datetime.getSeconds();
month = month < 10 ? "0" + month : month ;
date = date<10 ? "0" + date : date;
hour = hour <10 ? "0" + hour : hour;
m = m <10 ? "0" + m : m;
s = s <10 ? "0" + s : s;
test=year + "-" + month + "-" + date + ' ' + hour + ':' + m ,'time'
console.log( year + "-" + month + "-" + date + ' ' + hour + ':' + m +":"+s,'time')
return year + "-" + month + "-" + date + ' ' + hour + ':' + m +":"+s;
}
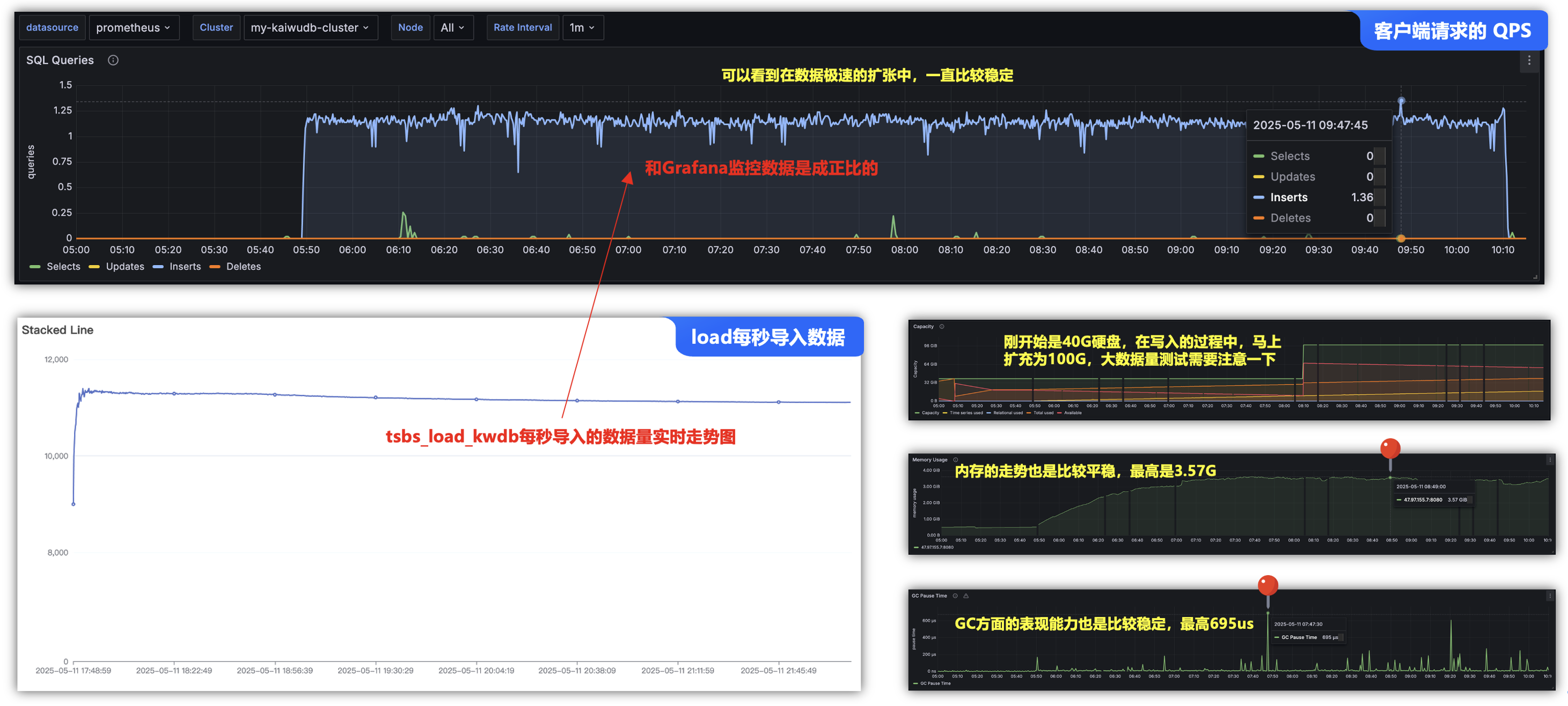
将tsbs_load_kwdb生成的结果数据,刷选出每秒导入的数据量,可以看到实时的走势图,经过与Grafana 查看指标数据SQL Queries的走势是可以成正比的,另外,也可以参考其它的一些指标数据,这里温馨提示一下,如果使用大数据量测试时,先把硬盘扩冲一下,不过,ECS上扩容云硬盘也比较方便。
4.3.4 生成查询性能压测基准SQL数据:
导入数据后,我们可以来进行TSBS工具生成查询测试用例来进行测试,查询吞吐和查询延迟是综合评估时序数据库的查询能力的重要指标,官方提供了cpu-only场景有15种查询类型:

比如:选用时序场景代表性的single-groupby-1-1-1查询类型进行评测,single-groupby-1-1-1 查询类型的含义是选取 1 个设备的 1 个测量值,在随机的 1 小时内以 1 分钟为间隔进行分段聚合计算。
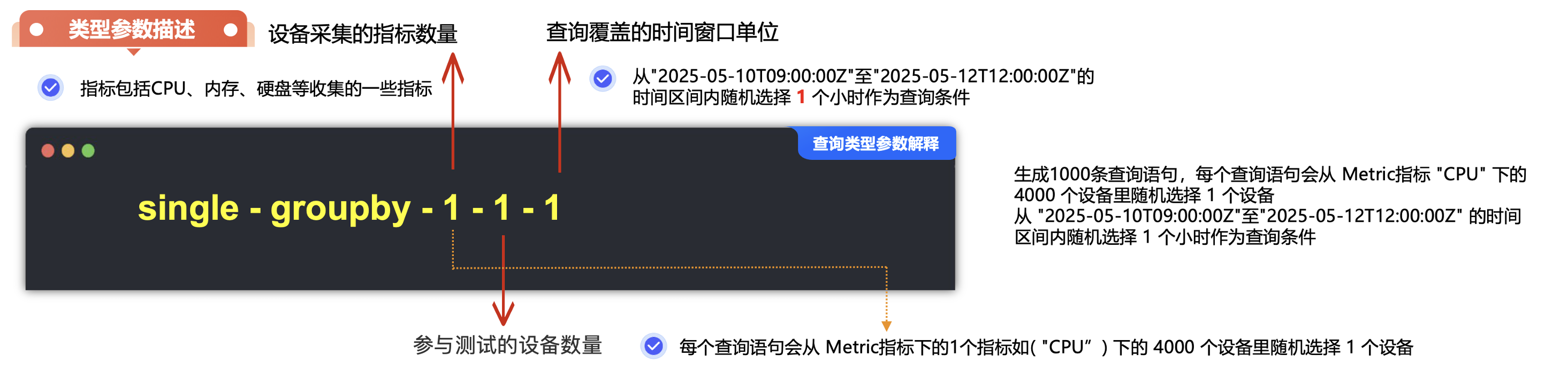
因为官方的一键测试报告没有执行成功,所以,这里我自己就依托于官方的代码,自己做了一个shell脚本,里面的变量信息可以根据自己的情况进行适当的修改。
QUERY_TYPES_ALL="\
single-groupby-1-1-1 \
single-groupby-1-1-12 \
single-groupby-1-8-1 \
single-groupby-5-1-1 \
single-groupby-5-1-12 \
single-groupby-5-8-1 \
cpu-max-all-1 \
cpu-max-all-8 \
double-groupby-1 \
double-groupby-5 \
double-groupby-all \
high-cpu-all \
high-cpu-1 \
lastpoint \
groupby-orderby-limit"
format="kwdb"
tsbs_case="cpu-only"
scale=4000
query_times=1000
query_ts_start="2025-05-10T09:00:00Z"
query_ts_end="2025-05-12T12:00:00Z"
db_name="benchmark"
query_workers=8
echo "start to generate query data"
for QUERY_TYPE in ${QUERY_TYPES_ALL}; do
tsbs_generate_queries \
--format=${format} \
--use-case=${tsbs_case} \
--seed=123 \
--scale=${scale} \
--query-type=${QUERY_TYPE} \
--queries=${query_times} \
--timestamp-start=${query_ts_start} \
--timestamp-end=${query_ts_end} \
--db-name=${db_name} > ./${QUERY_TYPE}_query_times.dat
done
echo "start to run queries worker"
for QUERY_TYPE in ${QUERY_TYPES_ALL}; do
echo "************* ${QUERY_TYPE} **************"
tsbs_run_queries_kwdb \
--file=${QUERY_TYPE}_query_times.dat \
--host=47.97.155.7 --port=26257 --user=root --pass="123456" \
--workers=${query_workers} > ./${QUERY_TYPE}_query_worker1.log
echo "************* ${QUERY_TYPE} **************"
sleep 10
echo "run query ${QUERY_TYPE} worker 1 success"
done
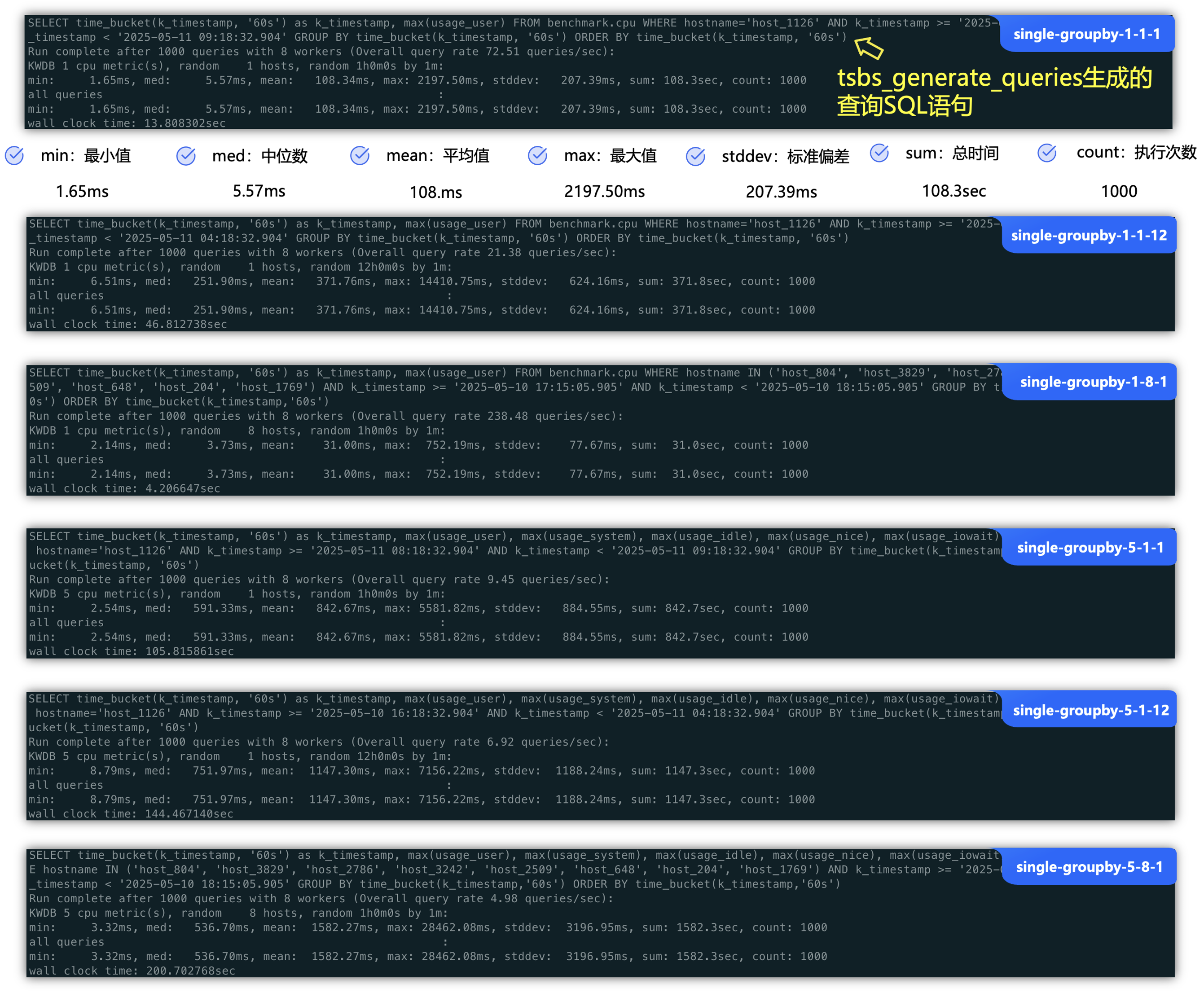
4.3.5 生成查询性能压测基准SQL数据:
上面使用 tsbs评估时间序列数据库性能的工具的 tsbs_run_querie 命令,常用于测试和比较不同的时间序列数据库的性能。要在TSBS中测量查询执行性能,下面是使用 tsbs_run_querie运行查询并获取结果:
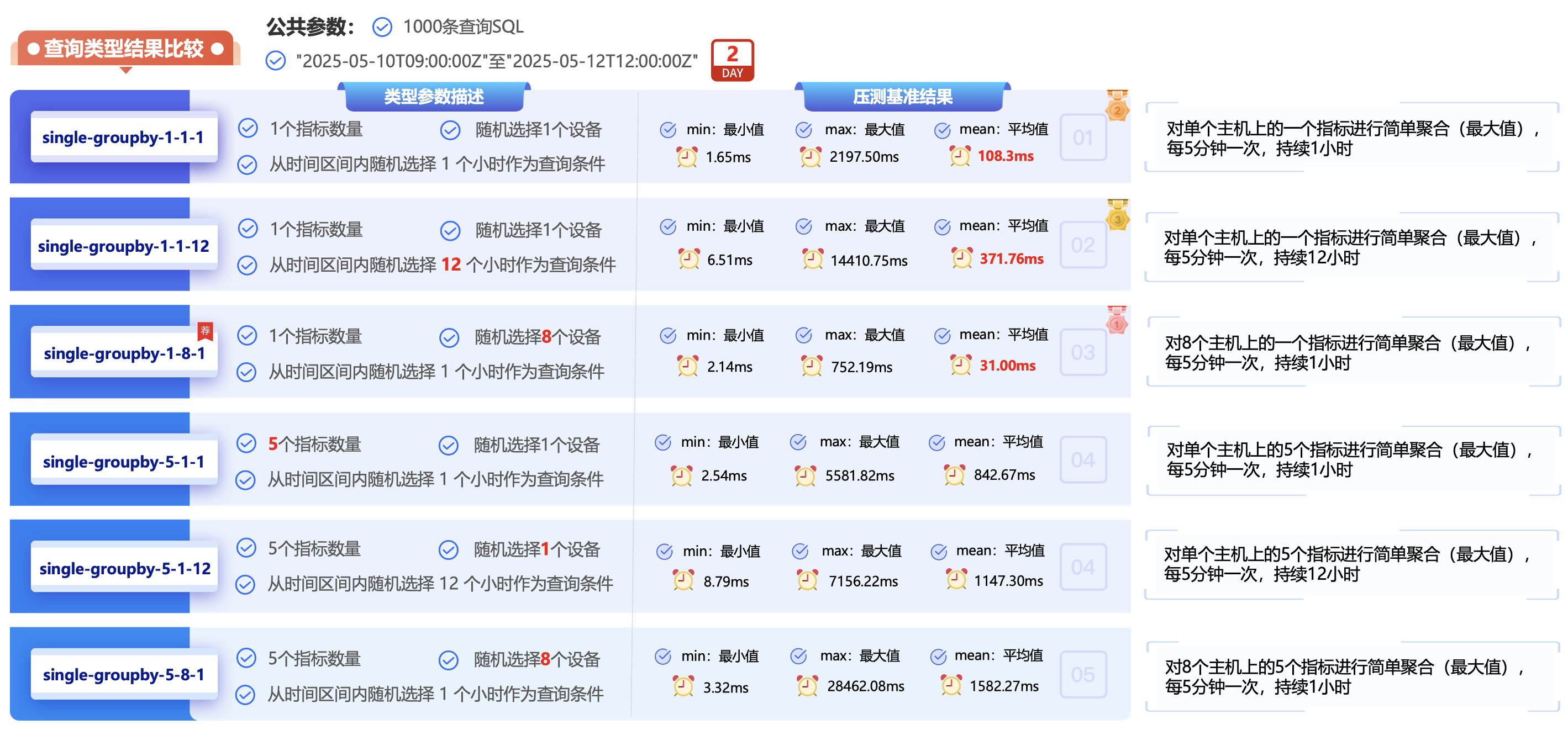
可以看到使用近2亿的数据量,在查询效率可以看到最少的31ms,最高的1.5s,性能来说已经非常的不错。
总结:
时间序列基准套件(TSBS) 是一系列 Go 程序,用于生成数据集并基准测试各种数据库的读写性能。目的是使 TSBS 可扩展,以便包括多种用例(如 DevOps、IoT、金融等)、查询类型和数据库进行基准测试,可以帮助潜在的数据库管理员找到满足他们需求和工作负载的最佳数据库。
五、总结:
本文详细介绍了KWDB分布式多模数据库的安装过程及其与TSBS压测工具的结合使用。
KWDB作为一款面向AIoT场景的分布式多模数据库,支持在同一实例中同时建立时序库和关系库,并融合处理多模数据,具备高效处理大规模数据的能力。安装过程中,用户可以根据自身需求选择二进制安装包、容器或源码等多种部署方式,且安装步骤简洁明了,只需确保硬件配置和软件依赖满足要求即可顺利完成。
此外,文章还通过实际案例展示了在安装和压测过程中可能遇到的问题及解决方案,如硬件配置不足导致服务启动失败、软件依赖缺失导致安装失败等,为用户提供了宝贵的参考经验。
在性能评估方面,KWDB_tsbs作为时序数据处理系统的性能基准测试平台,能够模拟处理海量、高频率、实时性强的时间序列数据,对KWDB数据库的性能和可靠性进行全面测试。通过生成压测基准数据集、导入数据、执行查询操作并分析查询结果,用户可以深入了解KWDB在处理大规模数据时的表现,从而为其在AIoT场景中的应用提供有力支持。
综上所述,KWDB分布式多模数据库以其强大的数据处理能力和灵活的部署方式,在AIoT领域展现出广阔的应用前景。而TSBS压测工具则为用户提供了全面、准确的性能评估手段,有助于用户更好地了解KWDB的性能特点,为其在实际应用中的优化和调整提供有力支持。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









