







livepatch是什么?
livepatch是linux内核引入的一个用于支持内核函数热修复的内核特性。通过kpatch-build工具制作的hotfix是可以使用livepatch特性的。通过livepatch机制,可以运行内核在运行过程中动态替换运行的函数,减少因修复系统漏洞而导致的停机时间,从而达到修复问题函数的能力,提高系统的安全性的稳定性。
livepatch与kpatch有什么关系?
其实livepatch与kpatch我认为是一脉相承的。最简单的我们可以看到livepatch的maintainer与kpatch-build的maintainer其实是同一拨人。原本使用的是kpatch.ko的模块加载的方式,但是livepatch提供了一套完整的内核机制,是一个内核特性,与内核兼容性更好,实现的功能更多,性能更好以及安全性有更好的保障。
为什么要使用livepatch?
首先,kpatch core module在linux 5.7+以后就无法编译了。livepatch作为内核特性,这个问题当然就是不存在的。
其次,使用kpatch core module的话,如果修复补丁使用了jump labels或者一些特殊section得话,在模块初始化阶段的顺序问题可能会导致一些很细微的bug。而且,使用livepatch内核特性可以修复更多的内核函数(虽然目前我还没有遇到过,但是这是我跟社区的同行们讨论的结果),一些内核函数基于livepatch特性可以进行修改,但是基于kpatch core module则无法完成。
从性能层面,使用livepatch重定向内核函数要比kpatch.ko要快,如果针对一些小函数的修改,这个对性能的影响可能就会非常的明显。
而一个非常重要的原因就是,kpatch.ko使用了内核的stop_machine机制,而livepatch使用的是modern upstream’s consistency model(这个我还要再研究一下)。对于前者而言,使用的stop_machine是存在明显的延迟的,但是livepatch则是通过一个一个进程来修改修复状态,这不仅仅解决了性能上的延迟问题,而且还是安全的。livepatch的做法对低延迟要求的机器更友好。
livepatch与kpatch在代码中的关系体现
上面我们介绍了livepatch与kpatch其实是一脉相承的,他们其实是同源的,这个我们从代码上也能看出点蛛丝马迹。在kpatch-build的项目中,kmod文件夹下有core以及patch两个文件夹(这两个文件夹是干啥的可以看我上一篇文章)。patch里面有个livepatch-patch-hook.c以及kpatch-patch-hook.c,这两个文件分别是在livepatch以及kpatch场景下用于构建patch使用的。对比两个文件,可以看出,所有的klp_*开头的结构体都是为livepatch服务的,而kpatch_patch_*开头的都是为kpatch_core_module服务的。lfunc是对livepatch服务的,kfunc则是为了kpatch core module服务的。
而在本地的一些数据结构或者函数,往往直接采用patch_*以及直接的函数名(func)。这样的前缀描述的结构体或者没有前缀的函数名就是本地数据结构。
所以,根据变量名以及函数名,我们可以直观地看出来这个函数或者变量是为那种机制服务的了。
livepatch由什么组成
针对livepatch由什么组成的这个问题,我们可以从内核的livepatch的Makefile看起:
# SPDX-License-Identifier: GPL-2.0-only
obj-$(CONFIG_LIVEPATCH) += livepatch.o
livepatch-objs := core.o patch.o shadow.o state.o transition.o
上面这个是内核livepatch模块下的Makefile文件,第一行我们看到obj-$(CONFIG_LIVEPATCH)。这个涉及到Kbuild的预发。$(CONFIG_LIVEPATCH)是从内核config file中读取的值,是对livepatch的配置。当CONFIG_LIVEPATCH=y的时候,这里是obj-y,也就是说livepatch会被编译进内核映像。obj-y,obj-m,obj-n和obj-等是kbuild系统用来决定是否编译某个对象文件的变量。obj-y表示总是编译,obj-m表示作为模块编译,obj-n和obj-表示不编译。obj-m是一个变量,它用来指定当前的对象需要按照模块来编译。
obj-*
针对obj-n以及obj-,我们没啥好说的,就是不编译。但是obj-y以及obj-m是需要讲讲的。obj-y表示总是编译,需要把当前对象编译进内核映像中,当一个对象被编译进内核映像以后,它会成为内核二进制文件中的一部分也就是说,它在系统启动时就被加载。这意味着这部分代码不能被卸载,除非重新编译和安装内核。这种方式适合那些必须在系统启动时就加载的代码,例如文件系统、网络协议栈等。
对于obj-m的对象文件,这部分对象将会按照模块的方式编译,当一个对象文件被编译成内核模块时,他会产生一个ko文件这个文件可以在系统运行时动态地加载和卸载。这种方式提供了更大的灵活性,因为你可以在不重启系统的情况下添加或删除功能。这种方式适合那些不需要常驻内存,或者只在需要时才加载的代码,例如设备驱动、文件系统等。
所以,当前文件需要按照那种方式编译,可以根据这个对象使用的方法以及使用的场景时机来进行设置。
livepatch包含什么?
从上面的makefile中我们可以看到,livepatch-objs 是由core.o patch.o shadow.o state.o transition.o这五个对象链接而成的,说明了livepatch包含了这些对象所提供的功能。根据以前的历史经验,我们不妨猜测一下这几个对象文件都提供些什么功能:
core:提供的是livepatch的核心流程
patch:提供hotfix加载卸载过程中与patch相关的流程机制功能
shadow:提供的是shadow变量的使用代码
state:提供livepatch使用过程中的状态代码
transition:提供livepatch运行过程中各个事务迁移的方式的相关功能
结合这些猜想,接下来我们将一个个去揭开livepatch的神秘面纱!
这里主要包含了livepatch的几个核心的过程:1、核心流程;2、livepatch状态改变机制;3、livepatch同步机制;4、livepatch的补丁应用机制。但是本文目前会先只介绍livepatch的流程。
为了维护整体的完成性,本文的内容将会很多,请系好你的安全带,我们马上出发!!
klp hotfix插入流程
在逐个文件揭开livepatch的神秘面纱之前,我们不如先从大局上看看,当我们插入一个klp hotfix的时候,是怎么一个流程的呢?
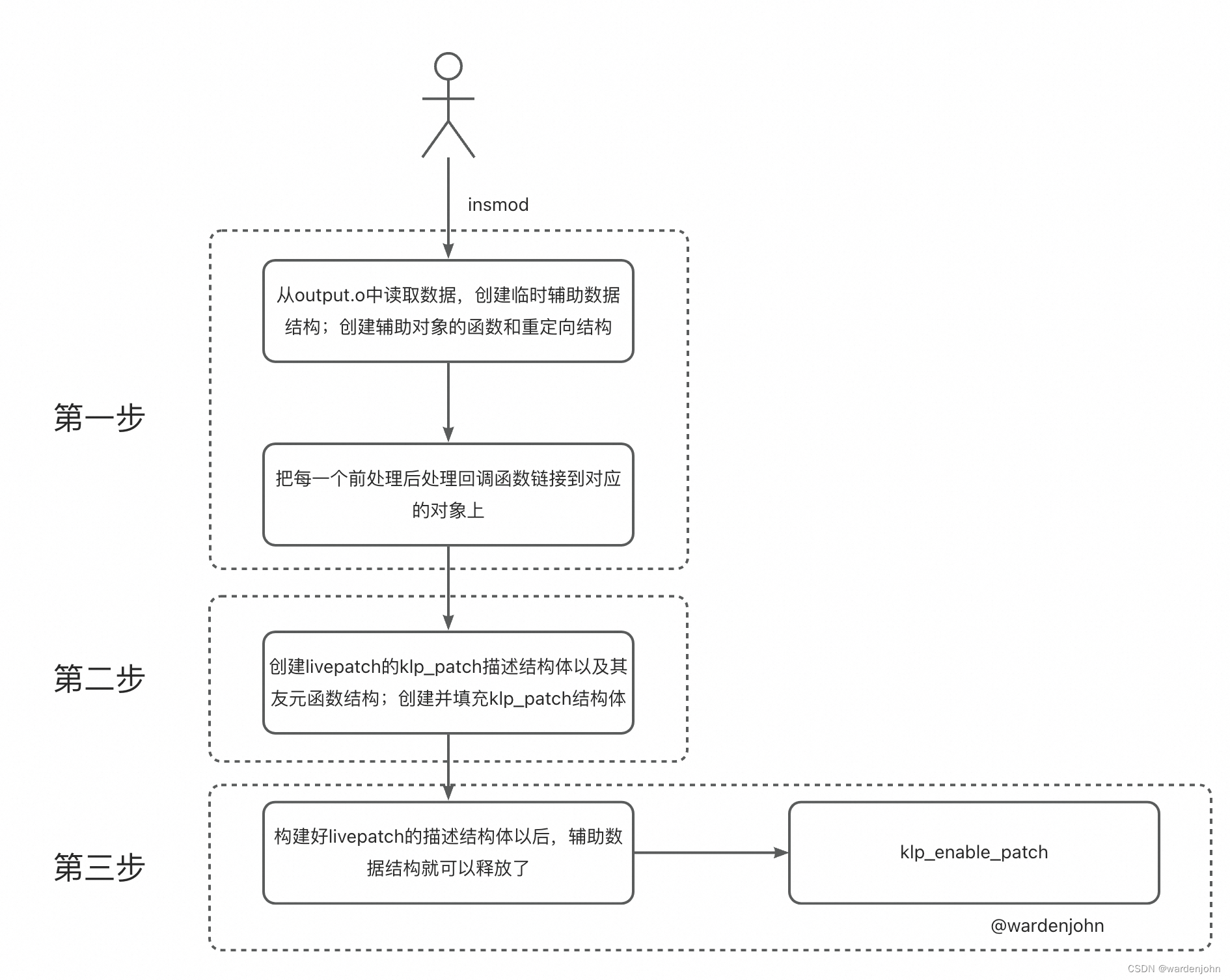
第一步,创建辅助对象函数与重定向结构
第一步的开始,livepatch构建的函数在ELF文件中存储的数据是按照结构体kpatch_patch_func来组织的。
kpatch_patch_func结构体用于描述一个函数在kpatch中的数据结构,里面包含了这个函数符号对应的符号、新旧函数地址等信息,可以认为是kpatch用于管理函数的单位。在这一步中,livepatch-patch-hook需要把这个数据结构转成patch_func结构体。patch_func的定义为:
/**
1. struct patch_func - scaffolding structure for kpatch_patch_func
2. @list: list of patch_func (threaded onto patch_object.funcs)
3. @kfunc: array of kpatch_patch_func
*/
struct patch_func {
struct list_head list;
struct kpatch_patch_func *kfunc;
};
这个其实可以认为是一个链表节点,patch_func是Node,链接起来以后,里面包含的就是kpatch_patch_func的结构体。结合之前的描述,我们可以知道,这么做的其中一个原因应该是kpatch的设计,patch_开头的,说明是这个文件中引用的变量。因为这里设计到了kpatch与livepatch的数据结构之间的转换,所以用到了这种方式。
klp如何获得每一个修复函数的地址呢?
for (kfunc = __kpatch_funcs;
kfunc != __kpatch_funcs_end;
kfunc++) {
ret = patch_add_func_to_object(kfunc);
if (ret)
goto out;
}
__kpatch_funcs是kpatch_patch_func的结构体数组。
extern struct kpatch_patch_func __kpatch_funcs[], __kpatch_funcs_end[];
kfunc是kpatch_patch_func的结构体类型。这个__kpatch_func
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9360
9360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









