






/*部门表*/
create table DEPT(
DEPTND int(2) not null,
DNAME VARCHAR(14),
LOC VARCHAR(16)
);
alter table DEPT add constraint PK_DEPT primary key(DEPTND);
/*员工表*/
create table EMP(
EMPND int(8) primary key,
ENAME VARCHAR(16),
JOB VARCHAR(16),
MGR int(4), /*上级领导编号*/
MIREDATE DATE, /*入职日期*/
SAL double(7,2), /*工资*/
COMM double(7,2), /*当月补助*/
DEPTNO int(8)
);
alter table EMP add constraint FK_DEPTNO foreign key (DEPTNO) references DEPT (DEPTND);
/*工资等级表*/
create table SALGRADE(
GRADE int primary key,
LOSAL double(7,2),
HISAL double(7,2)
);
/**/
create table BONUS(
ENAME VARCHAR(16),
JOB VARCHAR(8),
SAL double(7,2),
COMM double(7,2)
);----表字段期别名
select empno 员工编号,ename 姓名 from emp;
select empno as 员工编号,ename as 姓名 from emp;
--->对job字段进行去重操作,每个job只显示一个
select distinct job from emp;
--->对job,deptno组合去重复
select distinct job,deptno from emp;
排序
/*按照sal升序排序*/
select * from emp order by sal;
/*指定sal升序排序*/
select * from emp order by sal asc;
/*按照sal降序排序*/
select * from emp order by sal desc;
/*按sal升序排序同时按deptno降序排序*/
select * from emp order by sal asc,deptno desc;
where字句区分大小写查询
/*不区分大小写查询job等于CLERK的数据*/
select * from emp where job = 'CLERK';
/*区分大小写查询字段job等于小写clerk的数据*/
select * from emp where binary job = 'clerk';
/*查询deptno是10和20的数据*/
select * from emp where deptno in (10,20);
模糊查询
%代表任意多个字符
select * from emp where ename like '%A%';
_代表任意一个字符(查询第2个字符是A的数据)
select * from emp where ename like '_A%';
/*查询comm字段为null的数据*/
select * from emp where comm is null;
/*查询comm字段为不为null的数据*/
select * from emp where comm is not null;
mysql函数
select max(sal),min(sal),count(sal),sum(sal),avg(sal) from emp;
--->单行函数
--->多行函数
除了max,min,count,sum,avg以外的,都是单行函数
单行函数-字符函数
select ename,length(ename),substring(ename,2,3) from emp;
单行函数-数值函数
select abs(-5) as 绝对值,ceil(5.3) as 向上取整,floor(5.9), as 向下取整 round(3.14) as 四舍五入 from dual; --dual实际就是一个伪表(不存在的表)
select ceil(sal) from emp;
单行函数-日期与时间函数
-->查询当前时间
curdate() 年月日 curtime 时分秒
select curdate(),curtime() from dual;
now()年月日时分秒
单行函数-流程函数
select empno,ename,sal,if(sal >=2500,'高薪','低薪') as 薪资等级 from emp;
ifnull(comm,0)如果comm等于null,则comm取值为0
select empno,ename,job,
case job
when 'CLERK' then '店员'
when 'SALESAN' then '销售'
when 'MANAGER' then '经理'
end '岗位',
sal from emp;
单行函数-json函数
单行函数-其它函数
select database(),user(),version() from dual;
分组查询
--查询每个部门的平均sal
select avg(sal) from emp group by deptno;
--查询每个岗位的平均sal
select avg(sal) from emp group by job;
select deptno,avg(sal) from emp group by deptno having avg(sal) > 2000;
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资>2000;
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资>2000 order by deptno desc;
总结(sql固定顺序)
select column,group_function(column) from table [where condition] [group by group_by_expression] [having group_condition] [order by column];
多表查询
自然连接
优点:自动匹配所有的同名列,同名列只展示一次。
缺点:没有指定字段所属表,效率低
select empno,ename,sal,dname,loc from emp(表) natural join dept(表);
内关联指定字段所属表查询,效率高。
select emp.empno,emp.ename,emp.sal,dept.dname,dept.loc,dept.deptno from emp natural join dept;表名太长怎么办?
表名起别名解决
select e.empno,e.ename,e.sal,d.dname,d.loc,d.deptno,from emp(表名) e(别名) natural join dept(表名) d(别名);
内连接using字句
natural join缺点:自动匹配表中所有的同名列,但是有时候我们系统只匹配部分同名列,
使用using字句。
select * from emp e inner join dept d using(deptno);--inner可以不写
内链接on字句
--using缺点:关联的字段,必须是同名的。如果不同名,用on字句。
select * from emp e inner join dept d on (e.deptno=d.deptNO)
外连接
除了显示匹配的数据外,还可以显示不匹配的数据
左外连接
left outer join --左面的那个表的信息,即使不匹配也可以查看出效果
select * from emp e left outer join dept d --outer可以省略 on e.deptno = d.deptno;
右外连接
right outer join -- 右面的那个表的信息,即使不匹配也可以查看出效果。
select * from emp e right outer join dept d --outer可以省略 on e.deptno = d.deptno;
全外连接
full outer join -- mysql不支持,oracle中支持
并集
union --可解决mysql不支持全外连接的方式
select * from emp e left outer join dept d --outer可以省略 on e.dept = d.deptno union --并集 去重 select from emp e right outer join dept d --outer可以省略 on e.deptno = d.deptno;select * from emp e left outer join dept d --outer可以省略 on e.deptno = d.deptno union all --并集 不去重 select * from emp e left outer join dept d --outer可以省略 on e.deptno = d.deptno;--mysql中对集合操作支持比较弱,只支持并集操作,不支持交集
自关联
员工编号
员工姓名
员工公司
员工部门
上级领导编号
select e1.empno,e1.ename 员工姓名,e1.mgr,e2.ename 员工领导姓名 from emp e1 inner join emp e2 on e1.mgr = e2.empno;select e1.empno,e1.ename,e1.mgr,e2.ename from emp e1 left outer join emp e2 --outer可省略 on e1.mgr = e2.empno;
子查询
先执行子查询
在执行外层查询
不相关子查询
- 单行子查询
- 多行子查询
不相关子查询-单行子查询
select ename,sal
from emp where sal > (
select sal
from emp
where ename='clark');select ename,sal
from emp
where sal > (
select avg(sal) from emp
);select ename,sal
from emp
where deptno = (select deptno from emp where ename='clark')
and
sal <(select sal from emp where ename = 'clark');select *
from emp
where job = (select job from emp where ename = 'scott')
and
hiredate < (select hiredate from emp where ename = 'scott');不相关子查询-多行子查询(in Or any)
select * from emp where deptno=20 and job in (select job from emp where deptno = 10); select * from emp where deptno=20 and job any (select job from emp where deptno = 10);select * from emp where sal < any(select sal from emp where ename='clerk') and job != 'clerk';
相关子查询
select * from emp e where sal = (select max(sal) from emp where deptno = e.deptno);select * from emp e where sal > (select avg(sal) from emp where job=e.job)
事务
start transaction --开启事务
rollback --事务回滚
commit --事务提交
--创建账户表 create table account( id int primary key auto_increment, uname varchar(10) not null, balance double ); insert into account values(null,'丽丽',2000),(null,'小刚',2000); start transaction; --开启事务 update account set blance = blance - 200 where uname='丽丽'; update account set blance = blance + 200 where uname='小刚'; rollback; --事务回滚 commit; --事务提交Ps:
在回滚和提交之前,数据库中的数据都是操作的缓存中的数据,而不是数据库中真实数据。
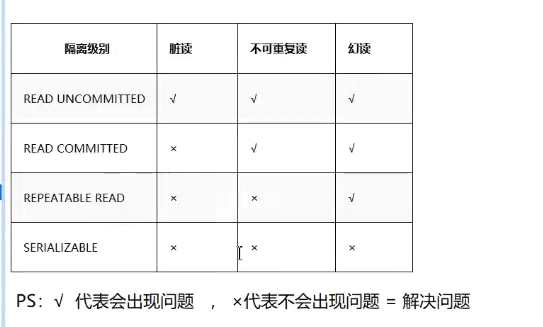
事务并发问题
脏读
不可重复读
幻读
为了解决事务并发问题,引入隔离级别
查看默认的事务隔离级别
select @@transaction_isolation;
设置事务隔离级别
set session transaction isolation level read uncommitted; set session transaction isolation level read committed; set session transaction isolation level repeatable read; set session transaction isolation level serializable;
视图
创建视图
create view myview01 as select empno,ename,job,deptno from emp where deptno = 20; insert into myview01(empno,ename,job,deptno) values(7777,'lili','clerk',30); create view myview01 as select empno,ename,job,deptno from emp where deptno = 20 with check option; --在插入数据时进行校验,如果插入deptno=30的数据无法插入
存储过程
--创建一个myproc01存储过程
create procedure myproc01(name varchar(10))
BEGIN
if name is null or name = "" THEN
select * from account;
else
select * from account where uname like concat('%',name,'%');
end if;
END;
--调用存储过程
call myproc01("丽丽");
call myproc01(null);
--删除存储过程
drop procedure myproc01;创建一个带返回值的存储过程
create procedure myproc02(in name varchar(10),out num int(3)) BEGIN if name is null or name ="" THEN select * from account; else select * from account where uname like concat('%',name,'%'); endif; select found_rows() into num; END; --调用存储过程 call myproc02("丽丽",@num); --@num表示返回值输出到num select @num --查看返回值
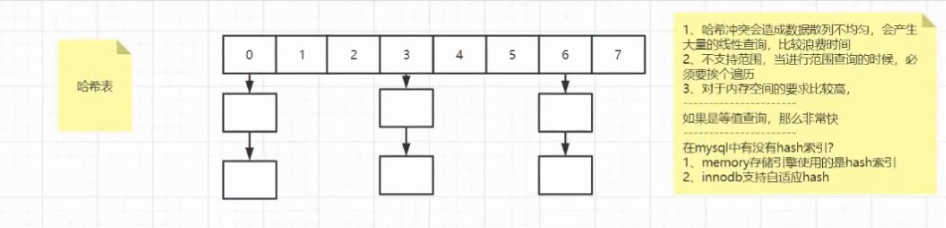
回表
--假如有一张表,有id,name,age,sex四个字段,id是主键,name是索引列
select * from table where name = 'xxx';
先根据name查询id,在根据id查询正行的记录,走了2棵B+树,此时这种现象叫做回表。
----当更加普通索引查询到聚簇索引的key值之后,在根据key值在聚簇索引中获取所有行记录。
索引覆盖
select id, name from table where name = zhangsan;
--根据name可以直接查询到id,name两个列的值,直接返回即可,不需要从聚簇索引查询任何数据,此时叫做索引覆盖。
最左匹配
【假如有一张表,有id,name,age,sex四个字段,id是主键,name,age是组合索引列】
----组合索引使用的时候必须先匹配name,然后匹配age
select * from table where name=? and age=? 【可用】 select * from table where name=? 【可用】 select * from table where age=? 【不可用】 select * from table where age=? and name=? 【可用】 mysql内部有优化器,会调整对应的顺序
存储下推
mysql5.7以后的特性,不需要调整表及sql语句。

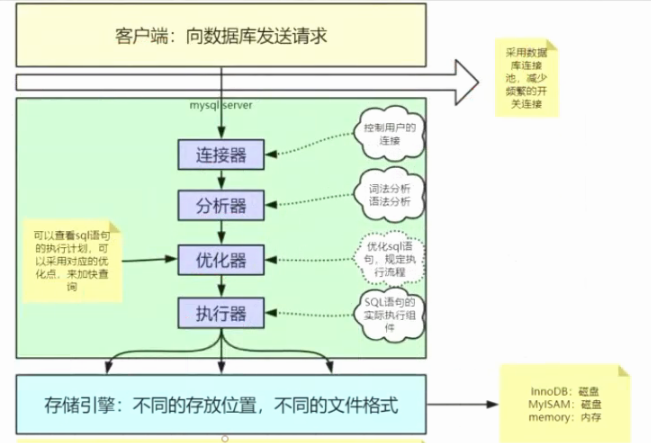
Mysql调优
- 性能监控
- schema与数据类型优化
- 执行计划
- 通过索引进行优化
性能监控
set profiling=1; --执行select查询 show profiles; --查看select查询执行时间 show profile; --查看每个步骤执行时间 show profile for query 2; --查看哪条Query_id的执行时间 show profile BLOCK IO;--BLOCK IO为查看的付带io使用情况 --CUP等各种参数
performance_schema
哪类的SQL执行最多? select digest_text,count_star,first_seen,last_seen from events_statements_summary_by_digest order by count_star desc\G;哪类sql指向的时间最多? select digest_text,avg_timer_wait from events_statements_summary_by_digest order by count_star desc\G;----更多内容查看mysql官网performance_schema----
查看当前数据库连接
show processlist;
















 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











