






文章目录
课程内容总结
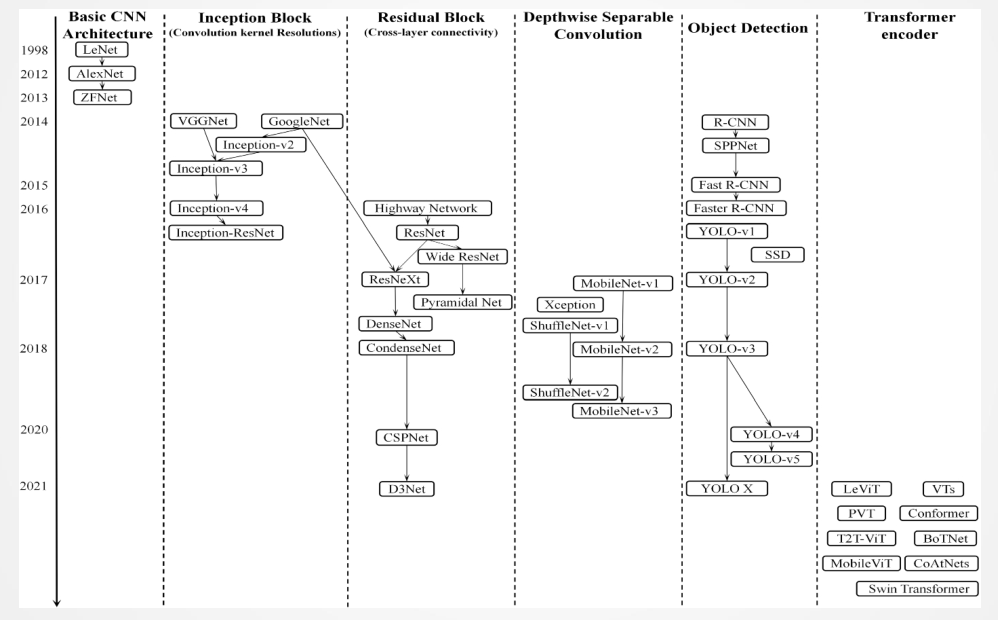
卷积神经网络基础
- 全连接网络问题:参数过多导致计算慢、难收敛,易过拟合。例如输入为1000×1000图像,隐含层有1M个节点时,参数量级达1×10¹²。
- 局部连接网络:减少权值连接,每个节点只与上一层少数神经元连接,如使用10×10滤波器时参数量为100M。
- 深度学习优势:模仿人类信息分层处理方式,逐层提取更高级别特征,解决全连接网络问题。
深度学习平台简介
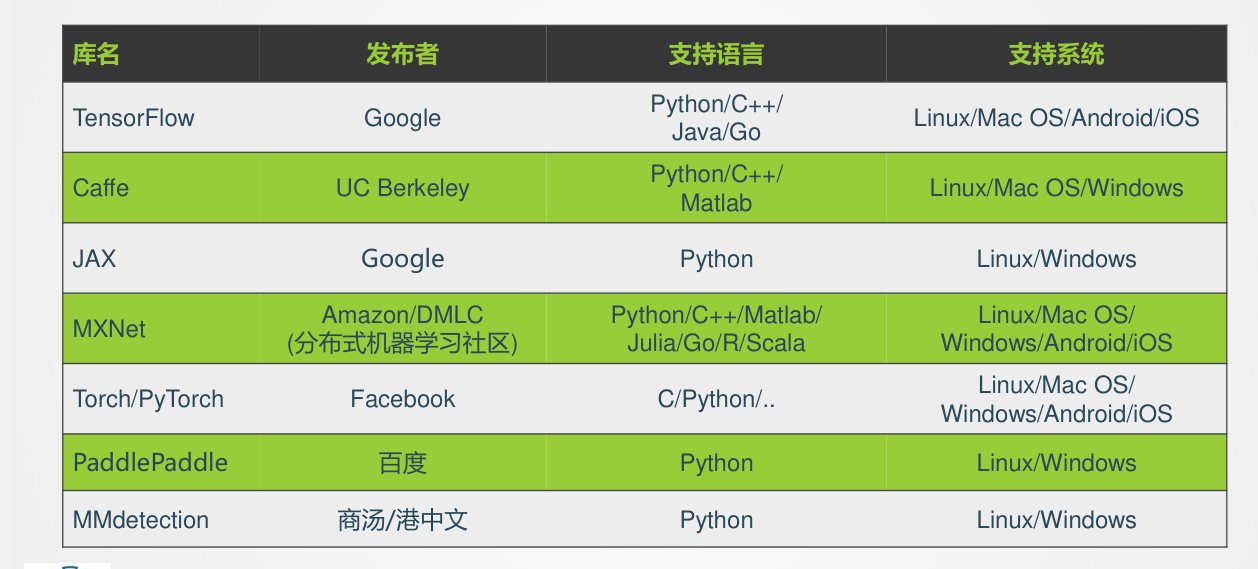
- 主流框架:
- TensorFlow:Google发布,支持多语言、多系统,功能丰富,运行速度快。
- Caffe:UC Berkeley开发,Python/C++支持,Linux/MacOS/Windows适用,以CNN建模见长。
- PyTorch:Facebook推出,Python/C支持,多系统兼容,易用性高,适合RNN建模。
- PaddlePaddle:百度开发,Python支持,Linux/Windows适用,多GPU支持良好。
- 学习材料:列举了各平台的官方教程、快速入门资料等,如PyTorch的60分钟快速入门、官方教程等。
PyTorch基本使用
- 基本概念:
- 张量(Tensor):表示高维物理量,类似多维数组。
- 计算图:用节点和边描述数学计算,节点表示操作或数据输入输出,边表示输入输出关系。
- 使用方式:使用tensor表示数据,Dataset、DataLoader读取样本,变量(Variable)存储参数,计算图表示计算任务,代码运行时执行计算图。
- 简单示例:展示了构建简单计算图的代码,tensor的使用与numpy多维数组类似,通过加法操作演示了计算图的构建和输出。
卷积神经网络结构与学习算法
- 特征提取:卷积操作模拟人类视觉感知,对图像进行不同方向滤波。例如,使用5×5卷积核对96×96图像提取特征,局部连接网络相比全连接网络参数大幅减少。
- 填充(Padding):在矩阵边界填充值(如0或复制边界像素),增加矩阵大小,保持图像边缘信息。
- 步长(Stride):卷积核移动的步长,影响输出特征图的大小。
- 多通道卷积:如RGB图像,使用多个卷积核分别对每个通道进行卷积,再将结果叠加。
- 池化(Pooling):使用局部统计特征(如均值或最大值)减少特征数量,降低计算复杂度,如2×2最大池化。
- 网络结构:由多个卷积层和下采样层构成,后面可接全连接网络。卷积层使用多个滤波器提取特征,下采样层采用mean或max pooling。
- 学习算法:
- 前向传播:逐层计算,卷积层输出为输入与卷积核的卷积结果,池化层输出为局部统计特征。
- 误差反向传播:根据链式法则,计算误差对各层参数的梯度,更新参数。对于卷积层与池化层的组合,以及卷积层与全连接层的组合,分别给出了梯度计算公式。
经典卷积神经网络结构
- LeNet-5:
- 网络结构:输入32×32图像,经过两次卷积与池化,再接两次全连接层,输出10类结果。具体包括C1层(6个5×5卷积核,输出6@28×28特征图)、S2层(平均池化,输出6@14×14特征图)、C3层(16个5×5卷积核,输出16@10×10特征图)、S4层(平均池化,输出16@5×5特征图)、C5层(120个5×5卷积核,输出120个特征)、F6层(84个神经元,全连接)、输出层(10个RBF单元)。
- 特点:网络较浅,参数少(约6万),未使用padding,池化层采用平均池化,激活函数为Sigmoid或tanh。
- 代码实现:使用PyTorch构建LeNet-5网络,展示了代码实现方式,包括各层的定义和连接。
- AlexNet:
- 网络结构:输入227×227×3图像,包含5层卷积层(部分后接最大池化层)和3层全连接层,最后接softmax分类器。具体为11×11卷积核的卷积层(96个滤波器,步长4)、最大池化层、5×5卷积核的卷积层(256个滤波器)、最大池化层、3×3卷积核的卷积层(384、384、256个滤波器)、全连接层(4096、4096、1000个神经元)。
- 改进点:采用最大池化、ReLU激活函数,网络规模扩大,参数量接近6000万,使用“多个卷积层+一个池化层”结构,引入Dropout和双GPU策略。
- 训练技巧:对输入样本进行数据增强,如随机裁剪、水平翻转、颜色抖动等,提高模型泛化能力。
- VGG-16:
- 网络结构:输入224×224×3图像,包含13层卷积层(使用3×3卷积核,部分后接最大池化层)和3层全连接层,最后接softmax分类器。具体为2次(64个滤波器的3×3卷积+最大池化)、2次(128个滤波器的3×3卷积+最大池化)、3次(256个滤波器的3×3卷积+最大池化)、3次(512个滤波器的3×3卷积+最大池化)、全连接层(4096、4096、1000个神经元)。
- 特点:网络规模进一步增大,参数量约为1.38亿,结构规整,各卷积层、池化层超参数基本相同。
- 参数变化:详细列出了每一层的输入输出尺寸、参数数量和内存占用情况,展示了网络的深度和参数规模。
- 残差网络(ResNet):
- 背景:非残差网络随层数增加会出现梯度消失问题,导致深层网络难以训练。ResNet通过引入残差块解决了这一问题,使深层网络能够有效训练。
- 残差块结构:包含主路径(两个权重层和ReLU激活函数)和捷径连接(将输入直接加到输出),使网络能够学习输入与输出的残差。
- 网络结构:展示了不同层数(18、34、50、101、152层)的ResNet结构,包括各层的名称、输出尺寸和卷积核大小等信息。
- 设计原则:采用3×3卷积核,遵循特征图尺寸减半时滤波器数量加倍的原则,减少过滤器数量和复杂性。
- 实验结果:在CIFAR-10数据集上,ResNet能够有效训练深层网络,且随着层数增加,训练误差和测试误差均降低。
常用数据集
- MNIST:包含60000个训练样本和10000个测试样本,每个样本为28×28像素的灰度手写数字图片,共10类。提供了数据集的文件组成和加载方式。
- Fashion-MNIST:替代MNIST的图像数据集,包含7万个28×28像素的灰度图片,涵盖10种类别的服装商品,数据集大小、格式和划分与MNIST一致。
- CIFAR-10:包含60000个32×32彩色图像,分为10个类别,每个类别6000个图像,分为50000个训练图像和10000个测试图像。
- PASCAL VOC:目标分类、检测、分割常用数据集,包含20个类别,提供了数据集的文件格式和标注格式,以及各类别的图像和目标数量统计。
2.CNN实战------手写数字识别
使用卷积神经网络(CNN)进行图像分类的简单例子,基于经典的 MNIST 数据集,使用 Python 和 PyTorch 框架实现。这个例子涵盖了数据加载、模型定义、训练和测试的完整流程。
示例:使用卷积神经网络进行 MNIST 手写数字分类
1. 环境准备
确保安装了以下依赖库:
pip install torch torchvision matplotlib
2. 数据加载
加载 MNIST 数据集,并进行简单的预处理。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 数据预处理:将图像转换为张量并归一化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载 MNIST 数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=1000, shuffle=False)
3. 定义卷积神经网络模型
定义一个简单的卷积神经网络,包含两个卷积层和两个全连接层。
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 第一个卷积层:输入通道1,输出通道16,卷积核大小5×5
self.conv1 = nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2)
# 最大池化层:池化窗口2×2
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 第二个卷积层:输入通道16,输出通道32,卷积核大小5×5
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2)
# 全连接层:输入特征数32×7×7,输出特征数128
self.fc1 = nn.Linear(32 * 7 * 7, 128)
# 输出层:输入特征数128,输出特征数10(对应10个类别)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 第一层卷积+池化+ReLU激活
x = self.pool(torch.relu(self.conv1(x)))
# 第二层卷积+池化+ReLU激活
x = self.pool(torch.relu(self.conv2(x)))
# 展平
x = x.view(-1, 32 * 7 * 7)
# 第一个全连接层+ReLU激活
x = torch.relu(self.fc1(x))
# 输出层
x = self.fc2(x)
return x
4. 训练模型
定义训练过程,包括损失函数、优化器和训练循环。
# 实例化模型
model = SimpleCNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 5
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
# 清空梯度
optimizer.zero_grad()
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss / len(train_loader):.4f}')
5. 测试模型
在测试集上评估模型性能。
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total:.2f}%')
6. 可视化一些预测结果
可视化测试集中的一些图像及其预测结果。
# 可视化一些预测结果
def imshow(img):
img = img / 2 + 0.5 # 反归一化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 获取一些测试图像
dataiter = iter(test_loader)
images, labels = next(dataiter)
# 显示图像
imshow(torchvision.utils.make_grid(images))
# 预测结果
outputs = model(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join(f'{predicted[j].item():5d}' for j in range(4)))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









