






可视化智能关键字PPT模板爬取
本次项目所要使用的库文件有requests、Beautifulsoup、tkinter、selenium、zipfile、rarfile、lxml。以上模块的安装请自行百度,这里不作详细介绍。使用软件为Pycharm,个人比较推荐这个,当然你用VScode也可以哦。
项目通过对输入的关键字,在第一PPT网页的搜索栏中进行搜索,对搜索结果中选定PPT网页链接后,进入该网页并获取下载链接,由于下载文件为压缩包,我们调用相应的函数进行解压并存储。
代码文件分为1ppt.py以及Selenium.py。以下为各模块的介绍
requests请求函数
def request_get(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
res = requests.get(url)
soup = BeautifulSoup(res.content, 'lxml')
return soup
在这里我们定义一个头部信息表明自身浏览器信息,通过requests模块的get方法,对目标链接url获取网页源码,再使用美丽汤即Beautifulsoup对其进行解析,这里我们使用的解析器为lxml,当然你可以用其他的解析器,不过我这里推荐这个,功能相对更强大便捷。解析后将值传给soup并返回。
搜索关键字函数
def search(key):
global title
url = 'http://so.1ppt.com/cse/search?q='+key+'&click=1&entry=1&s=18142763795818420485&nsid='
soup = request_get(url)
try :
if soup.find('div',class_='nors').text :
return '1'
except:
for i in soup.find_all('h3', class_='c-title'):
if '图片' not in i.find('a').text:
url = i.find('a').get('href')
break
if url[:27] == 'http://www.1ppt.com/article':
res = requests.get(url)
soup = BeautifulSoup(res.content, 'lxml')
title = soup.find('div', class_='ppt_info clearfix').find('h1').text
return url
else:
soup = request_get(url)
soup1 = soup.find('ul', class_='tplist').find('li').find('a')
position = soup1.get('href')
soup2 = soup.find('ul', class_='tplist').find('li').find('img')
title = soup2.get('alt')
url = 'https://www.1ppt.com' + position
return url
通过外部传参将关键字传入该函数,通过搜索页url解析得知关键字位于url中部,我们将字符串进行拼接就是我们需要访问的搜索链接并调用上面的请求函数获取解析后的文件。通过try-except语句进行结果的判定搜索结果是否为空,是则返回标记值’1’,否则进行except部分的代码执行。我们通过循环并利用find函数对标签为h3,class名为c-titile的标签值进行判断其名字中是否含有图片,因为搜索结果中可能含有PPT图片而非PPT模板,有则进入下一个搜索标签值的检查,否则获取其标签值中的a标签中的链接(url一般位于a标签中的href属性中)。接下来我们还要进行一次判断,当其为PPT模板页为具体的文章详情页时,获取其下载页面链接及其文章的标题并返回链接。
获取下载链接函数
def getDownloadUrl(url):
soup = request_get(url)
for i in soup.find_all('ul', class_='downurllist'):
for j in i.find_all('a'):
url = j.get('href')
url = 'https://www.1ppt.com' + url
res = requests.get(url)
soup = BeautifulSoup(res.content, 'lxml')
for i in soup.find_all('li', class_ = 'c1'):
for j in i.find_all('a'):
url = j.get('href')
return url
在这里通过传入的下载链接对其进行解析,通过循环找寻ul标签且其class值为downurllist下的a标签的链接值,但这链接并不能直接使用,其为相对链接,我们需将其与主干也就是该网站域名进行拼接。
我们再通过上面合成的url链接进行一次网页的获取。通过循环找寻li标签且其class值为c1下的a标签的链接值。这个链接便是最终的PPT下载链接。
下载PPT函数
def downloadPPT(url):
global title
formatt = url[-3:]
res = requests.get(url, stream=True)
path = '..//download//zip//'+title+'.'+formatt
f = open(path, 'wb')
for chunk in res.iter_content(chunk_size=128):
f.write(chunk)
f.close()
return path
经过多次下载发现,其压缩包文件可能为zip也可能为rar,我们通过url[-3:]截取url链接的最后三位获取其文件格式,设置好文件路径,下载并保存。
解压函数
def unzip_file(src, dst):
if zipfile.is_zipfile(src):
fz = zipfile.ZipFile(src, 'r')
# for file in fz.namelist():
# fz.extract(file, dst_dir)
fz.extractall(dst)
fz.close()
elif rarfile.is_rarfile(src):
fz = rarfile.RarFile(src)
fz.extractall(dst)
fz.close()
之前提到过文件可能有两种,所以在这里需要进行文件格式的判断并执行相应的解压操作。
可视化
root = Tk()
root.geometry('600x300')
root.title('可视化智能关键字PPT模板爬取')
var1 = StringVar()
var2 = StringVar()
label1 = Label(root, text="请输入模板关键字", font=('宋体', 16))
label1.pack(pady=10)
entry = Entry(root)
entry.pack(pady=10)
button = Button(root, text="提交", command=getKey, width=10)
button.pack(pady=10)
show = Button(root, text="自动化演示", command=lambda :sele(key), width=10)
show.pack(pady=10)
text = Label(root, textvariable=var1, font=('宋体', 12))
text.pack(pady=10)
label2 = Label(root, textvariable=var2, font=('宋体', 12))
label2.pack(pady=10)
root.mainloop()
这里就要用到我们之前提到的tkinter了,调用相应的方法设置其标题和窗口大小,设置一个标签设置其文本内容为“请输入模板关键字”,pack用于组件的定位这里我们设置pady为10,将其居中处理。下面创建一个文本框,让用户输入关键字。再创建两个按钮,一个用于执行上面的爬取操作,一个用于自动化演示。在按钮下方设置两个标签,用于结果的显示,默认其为空值。

由于下方标签为空值所以我们暂时看不到。
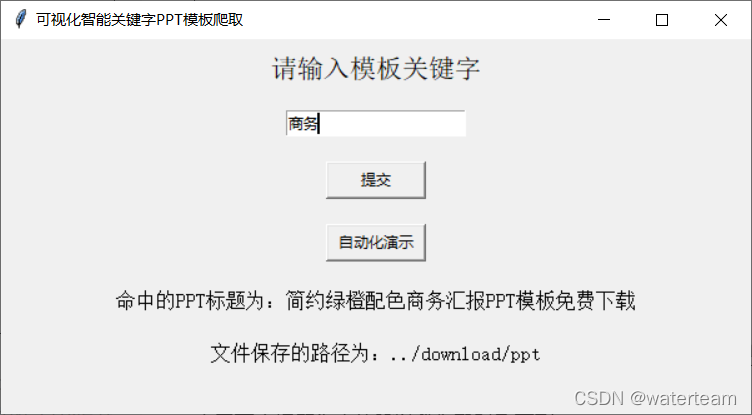
这是运行后的显示效果,下方成功显示出了命中的标题名字以及保存路径
调用函数
def getKey():
global key,url,title
var1.set('未命中标题,请重新输入新的关键字')
var2.set('')
key = entry.get()
url = search(key)
if url != '1' :
print('关键字链接:'+url)
url = getDownloadUrl(url)
print('下载链接:'+url,'\n标题:'+title)
src_path = downloadPPT(url)
print("文件压缩包的路径为:"+src_path)
flag = unzip_file(src_path, r'../download/ppt/' + title)
var1.set("命中的PPT标题为:" + title)
var2.set("文件保存的路径为:../download/ppt")
主程序调用该函数时,按钮下方的第一个标签值默认设置为’未命中标题,请重新输入新的关键字’。下方就开始调用上面我们写的所有函数,记得我们在搜索关键字函数中提到的,无搜索结果会返回一个标记值‘1’,这里我们就需要进行判断,不是‘1’则表明可运行,继续调用上面我们写的函数。
自动化测试文件
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
def sele(key):
# 不自动关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
# 将option作为参数添加到Chrome中
driver = webdriver.Chrome(chrome_options=option)
driver.get('https://www.1ppt.com')
text = driver.find_element('id', 'search_txt1')
text.send_keys(key)
button = driver.find_element_by_class_name('search-submit')
button.click()
driver.implicitly_wait(3)
driver.switch_to.window(driver.window_handles[1])
answer = driver.find_elements_by_xpath("//h3[@class='c-title']/a")
for i in answer :
if '图片' not in i.text :
url = i.get_attribute('href')
break
if url[:27] == 'http://www.1ppt.com/article':
driver.get(url)
answer = driver.find_element_by_xpath("//ul[@class='downurllist']/li/a")
url = answer.get_attribute('href')
driver.get(url)
answer = driver.find_element_by_xpath("//ul[@class='downloadlist']/li[@class='c1']/a")
url = answer.get_attribute('href')
else :
driver.get(url)
answer = driver.find_element_by_xpath("//ul[@class='tplist']/li/a")
url = answer.get_attribute('href')
driver.get(url)
answer = driver.find_element_by_xpath("//ul[@class='downurllist']/li/a")
url = answer.get_attribute('href')
driver.get(url)
answer = driver.find_element_by_xpath("//ul[@class='downloadlist']/li[@class='c1']/a")
url = answer.get_attribute('href')
time.sleep(3)
driver.quit()
本代码将实现爬取全过程的模拟操作,供展示操作。该部分为单独文件,文件名为Selenium.py。
主程序全部代码
import requests
from bs4 import BeautifulSoup
import zipfile,rarfile
from tkinter import *
from Selenium import sele
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
title = ''
def request_get(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
res = requests.get(url)
soup = BeautifulSoup(res.content, 'lxml')
return soup
def search(key):
global title
url = 'http://so.1ppt.com/cse/search?q='+key+'&click=1&entry=1&s=18142763795818420485&nsid='
soup = request_get(url)
try :
if soup.find('div',class_='nors').text :
return '1'
except:
for i in soup.find_all('h3', class_='c-title'):
if '图片' not in i.find('a').text:
url = i.find('a').get('href')
break
if url[:27] == 'http://www.1ppt.com/article':
res = requests.get(url)
soup = BeautifulSoup(res.content, 'lxml')
title = soup.find('div', class_='ppt_info clearfix').find('h1').text
return url
else:
soup = request_get(url)
soup1 = soup.find('ul', class_='tplist').find('li').find('a')
position = soup1.get('href')
soup2 = soup.find('ul', class_='tplist').find('li').find('img')
title = soup2.get('alt')
url = 'https://www.1ppt.com' + position
return url
def getDownloadUrl(url):
soup = request_get(url)
for i in soup.find_all('ul', class_='downurllist'):
for j in i.find_all('a'):
url = j.get('href')
url = 'https://www.1ppt.com' + url
res = requests.get(url)
soup = BeautifulSoup(res.content, 'lxml')
for i in soup.find_all('li', class_ = 'c1'):
for j in i.find_all('a'):
url = j.get('href')
return url
def downloadPPT(url):
global title
formatt = url[-3:]
res = requests.get(url, stream=True)
path = '..//download//zip//'+title+'.'+formatt
f = open(path, 'wb')
for chunk in res.iter_content(chunk_size=128):
f.write(chunk)
f.close()
return path
def unzip_file(src, dst):
if zipfile.is_zipfile(src):
fz = zipfile.ZipFile(src, 'r')
# for file in fz.namelist():
# fz.extract(file, dst_dir)
fz.extractall(dst)
fz.close()
elif rarfile.is_rarfile(src):
fz = rarfile.RarFile(src)
fz.extractall(dst)
fz.close()
def getKey():
global key,url,title
var1.set('未命中标题,请重新输入新的关键字')
var2.set('')
key = entry.get()
url = search(key)
if url != '1' :
print('关键字链接:'+url)
url = getDownloadUrl(url)
print('下载链接:'+url,'\n标题:'+title)
src_path = downloadPPT(url)
print("文件压缩包的路径为:"+src_path)
flag = unzip_file(src_path, r'../download/ppt/' + title)
var1.set("命中的PPT标题为:" + title)
var2.set("文件保存的路径为:../download/ppt")
if __name__=="__main__":
key = ''
root = Tk()
root.geometry('600x300')
root.title('可视化智能关键字PPT模板爬取')
var1 = StringVar()
var2 = StringVar()
label1 = Label(root, text="请输入模板关键字", font=('宋体', 16))
label1.pack(pady=10)
entry = Entry(root)
entry.pack(pady=10)
button = Button(root, text="提交", command=getKey, width=10)
button.pack(pady=10)
show = Button(root, text="自动化演示", command=lambda :sele(key), width=10)
show.pack(pady=10)
text = Label(root, textvariable=var1, font=('宋体', 12))
text.pack(pady=10)
label2 = Label(root, textvariable=var2, font=('宋体', 12))
label2.pack(pady=10)
root.mainloop()
使用时请勿忘记将Selenium.py文件和该py文件放置于同一文件夹,并在上层目录创建名为download的文件夹且在该文件夹中创建名为zip和ppt的两个文件夹用于存放结果。
结果展示



结语
该项目总计不到200行,去掉测试部分和调优部分约大几十行。这次项目为我的一次课程设计,代码均有本人手敲,代码健壮性和格式方面均有待完善。如有疑问请及时留言联系。有兴趣话也可私信交流哦。















 2141
2141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









