







目录
声明:告诉编译器一个东西的名称、类型,函数的类型(签名式)通过返回值类型、参数类型决定。
定义:提供声明中遗漏的细节。对象分发内存、提供函数代码本体的地方。
explicit:在构造函数中禁止隐式类型转换
class B{
public:
explicit B(int x=0,bool b=true);
}
void doSomething(B bObject); //函数,接受一个类型为B的对象
B bObj1; //一个类型为B的对象
doSomething(bObj1); //没问题,传递一个类型为B的对象
B bObj2(28); //根据int创建一个B,bool参数缺省
doSomething(28); //错误!应该接受一个B,没有隐式转换
doSomething(B(28)); //没问题,使用B的构造函数将int显式转换
拷贝构造:
class Widget{
public:
Widget(); //默认构造函数
Widget(const Widget &rhs); //拷贝构造函数
Widget& oprator=(const Widget& rhs); //拷贝赋值操作符
};
Widget w1; //调用默认构造
Widget w2(w1); //调用拷贝构造
w1 = w2; //调用 拷贝赋值操作符
Widget w3 = w2; //调用拷贝构造
//是否调用构造取决于对象是否新创建,如果已经被创建过了则调用 拷贝赋值
bool func1(Widget w);
bool re = func1(w1); //func1参数使用值传递的方式(pass-by-value),调用时,将w1复制到w内,这个动作由Widget的拷贝构造函数完成;通常而言,自定义类型一般建议使用 指针传递参数(pass-by-reference-to-const)
标准模板库STL:(standard Template Library),是c++标准库的一部分,实现了容器(vector,list,set,map等)、迭代器、算法(for_each,find,sort等)。
一 让自己习惯C++
01 视C++为一个语言联邦
一开始,c++只是在c的基础上增加了一些面向对象特性,后来加入各种观念、特性。
主要的次语言归纳为四类:
- C:区块、语句、预处理器、内置数据类型、数组、指针,都来自C。
- Object-Oriented c++:面向对象;类、封装、继承、多态、虚函数(动态绑定)。
- Template C++:c++泛型编程部分
- STL:STL是个template程序库,对容器、迭代器、算法(algorithms)和函数对象进行了约定建置。
对于内置类型,pass-by-value 通常比 pass-by-reference 高效。
用户自定义类型,pass-by-reference-to-const 一般更合适。
C++ 高效编程守则视情况而变,取决于你使用c++的哪一部分。
02 尽量以const,enums,inline替换#define
或者说“宁可 以编译期替换预处理器”。
因为#define不是语言的一部分,记号名称不会被编译期看到如#define ASPECT_RATION 1.653,记号表(symbol table)内可能不会有ASPECT_RATION,如此追踪起来会无法理解对应概念。
建议换成const double AspectRation=1.653(大写名称通常用于宏,这里修改名称写法)。
指针常量–指针类型的常量(int * const p)
如果指针不允许修改,类似宏的作用,则应声明为指针常量。
本质上一个常量,指针用来说明常量的类型,表示该常量是一个指针类型的常量。在指针常量中,指针自身的值是一个常量,不可改变,始终指向同一个地址。在定义的同时必须初始化。
int a = 10, b = 20;
int * const p = &a;
*p = 30; // p指向的地址是一定的,但其内容可以修改
常量指针—指向“常量”的指针(const int * p, int const * p)
如果指针指向的内容为常量,则需要用const修饰所指向的变量。
常量指针本质上是一个指针,常量表示指针指向的内容,说明该指针指向一个“常量”。在常量指针中,指针指向的内容是不可改变的,指针看起来好像指向了一个常量
int a = 10, b = 20;
const int *p = &a;
p = &b; // 指针可以指向其他地址,但是内容不可以改变
int main() {
int m = 10;
const int n = 20; // 必须在定义的同时初始化
const int *ptr1 = &m; // 指针指向的内容不可改变
int * const ptr2 = &m; // 指针不可以指向其他的地方
ptr1 = &n; // 正确
ptr2 = &n; // 错误,ptr2不能指向其他地方
*ptr1 = 3; // 错误,ptr1不能改变指针内容
*ptr2 = 4; // 正确
int *ptr3 = &n; // 错误,常量地址不能初始化普通指针吗,常量地址只能赋值给常量指针
const int * ptr4 = &n; // 正确,常量地址初始化常量指针
int * const ptr5; // 错误,指针常量定义时必须初始化
ptr5 = &m; // 错误,指针常量不能在定义后赋值
const int * const ptr6 = &m; // 指向“常量”的指针常量,具有常量指针和指针常量的特点,指针内容不能改变,也不能指向其他地方,定义同时要进行初始化
*ptr6 = 5; // 错误,不能改变指针内容
ptr6 = &n; // 错误,不能指向其他地方
const int * ptr7; // 正确
ptr7 = &m; // 正确
int * const ptr8 = &n;//错误,指针常量与所指向的地址类型不匹配,个人理解
*ptr8 = 8;//错误,如果指向常量n,则不可修改
return 0;
}
原文地址:https://blog.csdn.net/weixin_52244492/article/details/124081709
如果要在头文件定义一个常量的 char*-base 字符串,需要写两个const:
const char* const authorName = "scoot meyers";
对于此种场景,字符串使用string会简单清晰的多:
const std::string authorName("scoot meyers");
类静态常量成员
静态成员只有一份;作用域限于类内。
#define不支持作用域,所以无法实现类专属成员。
class GamePlayer{
private:
static const int NumTurns = 5; //常量声明(编译器支持类内初始化,一般只允许整型成员)
int scores[NumTurns]; //使用常量
}
以上static const int NumTurns = 5;只是声明;但是编译器有可能需要对静态成员进行定义(一般都需要),则需要在实现文件中定义:
const int GamePlayer::NumTurns;//已经初始化,不需要赋值
静态成员变量在类中仅仅是声明,没有定义,所以要在类的外面定义(一般都需要),定义实际上是给静态成员变量分配内存。通常要求任何使用的东西都提供一个定义,但如果是静态常量成员,需要特殊处理;理论上如果不取静态常量成员 的地址,无需提供定义。
以上情况,如果编译器不支持类内初始化,则需要在定义时初始化,如:
class CostEstimate{
private:
static const double FudgeFactor;//常量声明,头文件内
};
const double CostEstimate::FudgeFactor = 1.5;//常量定义,实现文件内
编译器不支持类内初始化时,以上GamePlayer类的构造将会面临数组声明时,大小没法确定的问题;此时可使用“enum hack”,(翻译貌似叫枚举基础):
class GamePlayer{
private:
enum {NumTurns=5}; //NumTurns是值为5的一个记号名称
int scores[NumTurns];
};
枚举的两个好处:
- 不可访问地址:枚举类似
#define,不允许访问其地址,所以不会产生额外的内存分配。 - 模板元变成的基础。
类似函数的宏
使用宏时,实参最好加上小括号,即使加上,可能也难免遇到其他问题:
#define CALL_WITH_MAX(a,b) f((a)>(b)?(a):(b))
int a = 5,b = 0;
CALL_WITH_MAX(++a, b); //a被累加两次
CALL_WITH_MAX(++a, b+10); //a被累加一次
解决方法就是使用 内联模板函数:
template<typename T> inline void callWithMax(const T& a,const T& b){
f(a>b?a:b);
}
总结
- 对于单纯常量,最好以
const对象或者enums替换#define - 对于形似函数的宏,最好改用
inline函数替换#define
03 尽量使用const
指针常量与常量指针
char greeting[]="Hello";
char* p=greeting; //non-const pointer,non-const data
const char* p = greeting; //non-const pointer,const data
char* const p = greeting; //const pointer,non-const data
const char* const p = greeting; //const pointer,const data
如果关键字const出现在星号左边,表示被指物是常量;
如果出现在星号右边,表示指针自身是常量;
如果出现在星号两边,表示被指物和指针都是常量。
被指物是常量,有人会将const写在类型之前,也有人会将const写在类型后、星号前(两种都对):
void f1(const Widget* pw); //f1获得一个指针,指向常量
void f2(Widget const * pw); //f2也一样,获得一个指针,指向常量
STL迭代器
迭代器的作用就像个T指针。
声明迭代器为const,就像声明指针为const一样(T const指针),表示迭代器不得指向不同的东西,但他指向的东西的值可以改动。
声明迭代器指向的东西不可改动(const T*指针),需要使用const_iterator:
std::vector<int> vec;
const std::vector<int>::iterator iter = vec.begin();//作用同 T* const
*iter = 100; //正确
++iter; //错误
std::vector<int>::const_iterator citer = vec.begin();//作用同 const T*
*citer = 100; //错误
++citer; //正确
const 应用在函数中
举例如下,返回常量返回值
class Rational{...};
const Rational operator* (const Rational& lhs, const Rational& rhs);
可以避免以下这种情况
(a+b)=c; //内置类型也是不支持这种操作的
if(a+b=c) //本来是要比较操作,结果误写了
const 成员函数
就是形如以下的成员函数
class Stack
{
public:
intGetCount(void) const; // const 成员函数
};
//在编写const成员函数时,若不慎修改了数据成员,或者调用了其他非const成员函数,编译器将指出错误;
//理论上 const成员函数 旨在不得在函数内部对类成员进行修改
const成员函数的好处:
1、知道哪个函数可以改变对象,哪个函数不可以
2、是操作常量对象成为可能(应该是操作 自定义的类型的对象 的const成员函数)
成员函数如果只是常量性不同,可以被重载:
class TextBlock{
public:
const char& operator[](std::size_t position) const //为const对象提供的[]操作符
{return text[position];}
char& operator[](std::size_t position) //为non-const对象提供的[]操作符
{return text[position];}
private:
std::string text;
}
//使用
TextBlock tb("Hello");
std::cout << tb[0]; //调用non-const TextBlock::operator[]
tb[0]='x'; //没问题,写一个non-const TextBlock
const TextBlock ctb("Hello");
std::cout << ctb[0]; //调用const TextBlock::operator[]
ctb[0]='x'; //错误,写一个 const TextBlock;const char& 类型进行赋值不被允许
//一般场景:const对象多用于 pass-by-pointer-to-const 或 pass-by-reference-to-const的传递结果,如:
void print(const TextBlock& ctb) //此函数中ctb是const
{
std::cout<<ctb[0]; //调用const TextBlock::operator[]
}
假设char& operator[](std::size_t position) 返回类型不是引用(char&)而是char,则在 tb[0]='x';时将会报错。(函数返回值类型是内置类型,改动返回值不合法)
数据常量性(bitwise constness):const成员函数不能修改对象的成员变量。编译器只需要查看函数内是否对变量有赋值行为。但是以下情况却违反了const成员函数的初衷:
class CTextBlock{
public:
char& operator[](std::size_t position) const
{return ptext[position];}
private:
char* ptext;
}
const CTextBlock cctb("hello"); //声明一个常量对象。
char* pc = &cctb[0]; //调用const operator[]取得一个指针,指向cctb的数据。
*pc='J'; //cctb修改为“Jello”
最终是建立了一个常量,但是还是修改了该常量的值。
所以出现逻辑常量性(Logical constness),即允许某些数据被修改,只要这些改动不会反映在外。
如,旨在获取一个文本长度的函数length(),虽然中心思想不修改pText,但是校验时还是会修改成员变量,以下代码就会报错
class Text{
public:
std::sizt_t length() const;
private:
char* pText;
std::size_t length;
bool lengthValid;
....
};
std::size_t Text::length() const{
if(!lengthValid){
//做某些错误检测
length = std::strlen(pText); //错误,在const成员函数内,不能赋值textLength和lengthValid
lengthValid = true;
}
return length; //这行才是代码核心
}
为了满足这种思想上没有错误,但是操作中却被“冤枉”的场景,引入了mutable 关键字。mutable 释放掉了non-static 成员变量的 bitwise constness约束:
class Text{
public:
std::sizt_t length() const;
private:
char* pText;
mutable std::size_t length;
mutable bool lengthValid; //可修改,即使在const成员函数中
....
};
std::size_t Text::length() const{
if(!lengthValid){
//做某些错误检测
length = std::strlen(pText); //允许
lengthValid = true; //不报错
}
return length;
}
const与non-const成员函数避免重复
当operator[] 操作符函数变的复杂和庞大之后,'写两遍’会造成代码冗余、维护成本提升、编译时间变长等问题,所以修改为以下方式:
class TextBlock{
public:
...
const char& operator[](std::size_t pos) const
{
... //边界检验
... //日志记录访问记录
... //检验数据完整性
return text[position];
}
char& operator[](std::size_t pos){
return
const_cast<char&>(
static_cast<const Text&>(*this)
[position]
);
}
/*
该非常量成员函数中有两个类型转换动作:
第一个是将 *this 从其原始类型 TextBlock& 转换为 const TextBlock&,即为它加上了const;
第二个是从 const operator[] 的返回值中移除 const
*/
...
private:
std:string text;
}
注意:用常量成员函数调用非常量成员函数是不合适的,因为非常量成员函数方法有可能修改数据,而 常量成员函数调用之后,就可能也会修改数据,不符合常量成员函数语义。
总结
- 将某些东西声明为
const可帮助编译器侦测出错误用法;const可被用于任何作用域内的对象、函数参数、函数返回类型、成员函数本体。 - 编译器强制实施
bitwise constness但是编写程序时应该使用概念上的常量性conceptual constness(关键数据保持常量性)。 - 当
const和non-const成员函数有实质等价实现时,用non-const调用const版本可避免代码重复
04 确定对象被使用前已被初始化
参考:https://blog.csdn.net/qq_34168988/article/details/121153945
变量未初始化前的值不确定(c和c++中表现不一样,再加上其他语言联邦中的表现也不一样),为了避免记忆这些不确定情况规则,使用前最好进行初始化。
内置类型手动初始化
int a = 10; //对int进行手工初始化
const char* str = "Hello"; //对指针进行手工初始化
double d;
cin>>d; //以读取输入流的方式完成初始化
使用构造函数的初始化列表
class PhoneNumber{
...
};
class ABEntry{
public:
ABEntry(const string &name, const string &address,const list<PhoneNumber> &phones);
ABEntry();//无参构造
private:
string theName; //自定义类型(不是用户自定义,是std)
string theAddress; //自定义类型
list<PhoneNumber> thePhones; //自定义类型
int numTimesConsulted; //内置类型
};
//第一版:在构造函数执行体内进行赋值操作
ABEntry::ABEntry(const string &name, const string &address,const list<PhoneNumber> &phones)
{
theName = name; //这些都是赋值
theAddress = address; //而非初始化
thePhones = phones;
numTimesConsulted = 0;
}
//第二版:使用初始化列表
ABEntry::ABEntry(const string &name, const string &address,const list<PhoneNumber> &phones):
theName(name),
theAddress(address),
thePhones(phones),
numTimesConsulted(0)//这些都是初始化
{
//构造函数本体无需任何动作
}
ABEntry::ABEntry():theName(),theAddress(),thePhones(),numTimesConsulted(0)
{
//对于无参构造函数,也可以使用初始化列表,因为theName(),theAddress(),thePhones()会调用它们的默认构造函数
}
第一版中,先调用string、list的默认构造函数为theName、theAddress、thePhones赋初值;然后进入了构造函数,执行构造函数中的赋值语句为对应的变量赋值。numTimesConsulted是内置类型,不保证在执行构造函数中的numTimesConsulted = 0;赋值语句之前获取到初值。
第二版中,先调用string、list的拷贝构造函数为theName、theAddress、thePhones赋初值,用0对numTimesConsulted进行初始化操作。
显然第二版的效率更高,减少了不必要的赋值操作。(numTimesConsulted为内置类型,其初始化和赋值的成本基本一致,可以忽略;写入到初始化列表只是为了保持一致)
虽然 如果不写初始化列表仍然会调用默认构造函数;内置类型的赋值成本与初始化相差不多;将多个初始化公用的赋值操作放入函数中进行调用减少初始化列表的书写;
但是为了不遗漏,造成不确定的初值,仍然建议初始化列表方式。
初始化列表的顺序并不是构造的顺序,构造调用顺序取决于成员声明的顺序。
静态对象的初始化
静态对象存放在全局变量区域,所以它的生命周期是从对象构造出开始到到程序结束。
静态对象可以分为:
- 静态局部对象:定义在函数内部的静态对象;在程序调用时构造。
- 非静态局部对象:定义于namespace、类内、文件作用域中的静态对象;在程序开始时main执行前构造。
另外普通全局对象在 程序开始时main执行前构造,程序结束时销毁。
编译单元指在编译阶段生成的每个obj文件。
一个obj文件就是一个编译单元。
一个.cpp(.c)和它相应的.h文件共同组成了一个编译单元。
当一个编译单元要使用另一个编译单元内的非静态局部对象时,不能保证被使用的对象已经被创建,此时可以使用以下方式:
class FileSystem{
public:
std::size_t numDisks() const;//被其他用户使用的方法
};
extern FileSystem tfs;
//计划使用的方式
class Directory{
public:
Directory(params);
};
Directory::Directory(params)
{
...
std::size_t disks = tfs.numDisks(); //此时不能保证tfs已经初始化
}
class FileSystem{...};
FileSystem& tfs()
{
}
class Directory{...};
Directory::Directory(params)
{
...
std::size_t disks = tfs().numDisks(); //从调用对象的方法---改为调用一个返回引用的函数,进而调用其方法
}
Directory& tempDir()
{
static Directory td;
return td; //返回初始化的一个局部静态对象的引用
}
总结
- 为内置类型的对象进行手动初始化,c++不保证初始化他们。
- 构造函数最好使用初始化列表;且其次序尽量与类声明中的次序相同。
- 为了避免出现跨编译单元初始化顺序问题,使用
local static代替non-local static对象。
二 构造、析构、赋值运算符
05 了解C++ 默默编写并调用哪些函数
如果写了一个空类,编译器则会加入默认构造、拷贝构造、析构、拷贝赋值操作符函数:
class Empty {};
//就如同写为这样
class Empty{
public:
Empty(){...}; //默认构造函数
Empty(const Empty& rhs){...}; //拷贝构造函数
~Empty(){...}; //析构函数
Empty& oprator=(const Empty& rhs){...}; //拷贝赋值操作符
};
书中说到:“当这些函数被需要(被调用),他们才被编译期创造出来”。这个怎么测试呢,虽然对使用好像都没啥影响。
编译器产出的析构函数是非 虚析构函数,除非这个类的基类的析构为虚析构函数。(虚析构函数是为了避免内存泄露,而且是当子类中会有指针成员变量时才会使用得到的。也就说虚析构函数使得在删除指向子类对象的基类指针时可以调用子类的析构函数达到释放子类中堆内存的目的,而防止内存泄露的.)
当类中声明了一个构造函数后,编译器不再为他创建默认构造函数。(不影响编译器增加析构、拷贝、拷贝赋值操作符函数)
编译器加入的拷贝构造(拷贝赋值操作符函数类似)只是将成员拷贝到目标对象;如果目标成员对象为引用类型或者const常量类型,则编译器会拒绝改成员的赋值,如下场景:
template<class T>
class NamedObject{
public:
NamedObject(std::string& name, const T& value);
...
private:
std::string& nameValue;
const T objectValue;
};
std::string newDog("Persephone");
std::string oldDog("satch");
NamedObject<int> p(newDog,2);
NamedObject<int> s(oldDog,36);
p=s; //编译器报错,尝试引用已删除的函数
总结
编译器会暗自为类创建 默认构造函数、拷贝构造函数、拷贝赋值操作符 和 析构函数。
06 如不想使用编译器自动生成的函数,就该明确拒绝
不允许拷贝构造、拷贝赋值运算符的实现方法
class Uncopyable{
protected:
Uncopyable();
~Uncopyable();
private:
Uncopyable(const Uncopyable&); //将拷贝函数转移至此
Uncopyable& operator=(const Uncopyable&);
};
class HomeSale:private Uncopyable{
public:
HomeSale(int no):m_no(no){};
private:
HomeSale(const HomeSale&);//因为不打算实现,可以省略参数名称
HomeSale& operator=(const HomeSale&);
int m_no;
}
int main()
{
HomeSale h1(10);
HomeSale h2(20);
HomeSale h3(h1); //编译不通过
h1 = h2; //编译不通过
return 0;
}
当友元函数或者成员函数调用拷贝构造时,编译器会试着生成一个拷贝构造(或者赋值运算符),这个生成的拷贝构造函数调用它的基类的对应函数,但是基类的拷贝构造函数是私有的,所以会报错,编译不通过,打到不允许自动生成拷贝构造函数(赋值运算符)的目的。
07 为多态基类声明virtual析构函数
class TimeKeeper{
public:
TimeKeeper();
~TimeKeeper();
};
TimeKeeper* ptk = getTimeKeeper();
...
delete ptk;//产生问题
getTimeKeeper函数返回一个 派生自TimeKeeper的子类指针。
此时会有一个问题:删除一个指向子类的父类指针时,且基类的析构函数非虚,这时将不会执行派生类的析构函数,只执行基类的析构函数。
解决方法:为基类析构函数增加虚析构函数。
class TimeKeeper{
public:
TimeKeeper();
~virtual TimeKeeper();
};
TimeKeeper* ptk = getTimeKeeper();
...
delete ptk;//没有问题
但是这时如果实例化基类的对象,由于基类含有虚函数,那么这个对象将会产生一个指针(vptr)指向虚函数表,多占用了一个指针的空间。
可以将此基类声明为接口类,避免实例化。也就是说,应用于多态的基类避免实例化使用。
class TimeKeeper{
public:
TimeKeeper();
~virtual TimeKeeper() = 0;
};
TimeKeeper::TimeKeeper(){ } //由于派生类析构时会调用此纯虚函数 ,所以需要提供定义
总结
- 带有多态性质的基类应该声明一个虚析构函数。如果一个类带有任何一个虚函数,他就应该拥有一个虚析构函数。
- 一个类的设计如果不是作为基类使用,或者不是为了具备多态性,那么不应该声明虚析构函数。
08 别让异常逃离析构函数
参考https://blog.csdn.net/qq_34168988/article/details/121185298
C++并不禁止析构函数抛出异常,但它不鼓励你这样做
class Widget{
public:
...
~Widget(){...} //假设此析构函数可能会抛出异常
};
void doSomething(){
std::vector<Widget> v;
...
} //在这一行调用了v的析构函数,资源被释放
当 vector v 被释放的时候,它容器内的 Widget 也需要释放。假设 v 内有十个 Widget ,而在析构第一个 Widget 期间,有异常抛出,其它九个 Widget 还是需要被释放的(否则会导致内存泄漏),因此需要继续释放剩下的九个 Widget 的资源,但第二个 Widget 的析构函数也抛出异常。现在有两个异常出现,但C++最多只能同时处理一个异常,因此程序这时会自动调用 std::terminate() 函数,导致我们程序的闪退或者崩溃。
但是如果是不可避免的场景该如何处理呢,
举个数据库连接的例子:
class DBConnection{ //数据库连接类
public:
...
static DBConnection create(); //建立一个连接
void close(); //关闭一个连接
};
class DBConn{ //创建一个资源管理类来管理DBConnection对象
public:
....
~DBConn(){
db.close();//确保数据库连接总是会关闭
}
private:
DBConnection db;
};
{
DBConn dbc(DBConnection::create()); //创建一个DBConn类的对象
... //使用这个对象
} //对象dbc被释放资源,但它的析构函数调用了可能会抛出异常的close()方法
这里可以用到的处理方式有:
1、捕获并提前终止程序:
DBConn::~DBConn(){
try{
db.close();
}catch(...){
std::abort();//记录访问历史,记录close()的调用失败
}
}
2、捕获打印并无视不处理(由于忽略了关键信息,不做推荐):
DBConn::~DBConn(){
try{
db.close();
}catch(...){
//记录访问历史
}
}
建议的方式是,提供更多的主动权给用户 void DBConn::close(),同时做好预防手段 DBConn::~DBcon():
class DBConn{
public:
...
~DBConn();
void close(); //关闭数据库连接,需要用户自己调用
private:
DBConnection db;
bool isClose = false; //数据库连接是否被关闭
};
void DBConn::close(){ //当需要关闭连接,手动调用此函数
db.close();
isClose = true;
}
DBConn::~DBcon(){
if(!closed){//析构函数虽然还是要留有备用(双重保险),但不用每次都承担风险了
try{
db.close();
}catch(...){
//记录访问历史
//消化异常或者主动关闭
}
}
}
总结
- 析构函数绝对不要抛出异常。如果不可避免抛出,析构函数应该捕获异常,不处理(不建议)或结束程序(abort)
- 如果客户需要对操作函数期间的异常做出反应,那么类需要提供普通函数执行该操作(而不是在析构函数中)。
09 绝不在构造和析构过程中调用virtual函数
举例,实现不同派生类创建时打印各自的日志:
//基类
class Transaction{
public:
Transaction();
virtual void logTransaction() const = 0; //打印日志,依据派生类而定
};
Transaction::Transaction()
{
logTransaction();
}
//派生类
class BuyTransaction::public Transaction{
public:
virtual void logTransaction() const; //打印买入日志
};
class SellTransaction::public Transaction{
public:
virtual void logTransaction() const; //打印卖出日志
};
//执行
BuyTransaction b;
在BuyTransaction对象创建时,首先调用基类的构造函数,此时,派生类BuyTransaction还没构造出来,视为没有这个类,可以理解为此时该对象的类型还是Transaction,而非BuyTransaction(在BuyTransaction构造完成前都是Transaction), 这里虽然声明logTransaction()为虚函数,但是仍然会调用基类Transaction的logTransaction()日志函数,但此函数是纯虚函数,没有实现,所以此处不仅没有实现预期功能,还会报错。
同样的,在析构时如果调用虚函数也有这样的问题;在派生类调用析构函数后,派送类成员变量即为未定义状态,c++视他们不存在,然后调用基类的析构函数,此处如果调用了虚函数,则会仍然调用基类的成员函数。
如下写法也会有同样的问题:
class Transaction{
public:
Transaction(){
init(); //调用非虚函数
};
virtual void logTransaction() const = 0; //打印日志,依据派生类而定
void init(){
logTransaction(); //调用虚函数
}
};
此场景的解决方法就是在构造函数中传参:
//基类
class Transaction{
public:
explicit Transaction(const std::string& logInfo);
void logTransaction(const std::string& logInfo) const; //非虚函数
};
Transaction::Transaction(const std::string& logInfo)
{
logTransaction(logInfo);
}
//派生类
class BuyTransaction::public Transaction{
public:
BuyTransaction(parameters):Transaction(createLogString(parameters)){...} //将打印信息传给基类构造函数
private:
static std::string createLogString(parameters);
};
使用静态函数发送打印信息可读性比较强,而且避免了构造完成才可以调用的限制。
总结
- 在构造和析构期间不要调用
virtual函数,因为此种调用不会下降至派生类(比起当前执行构造和析构函数的那层)
10 令operator=返回一个reference to *this
赋值操作:
int x,y,z;
x = y = z = 15;//连锁赋值 解析为 x = (y = (z = 15))
为了达到以上效果,同样是遵守协议(不成文),赋值操作符必须返回一个reference指向操作符的左侧实参:
class Widget{
public:
Widget& operator=(const Widget& rhs){//返回类型为一个引用
...
return* this;//返回左侧对象
}
Widget& operator+=(const Widget& rhs){//返回类型为一个引用
...
return* this;//返回左侧对象
}
Widget& operator=(int rhs){//该函数也适用,即使此操作符参数类型不符合规定
...
return* this;//返回左侧对象
}
};
这只是个协议,无强制性。如果不遵守它,一样可以编译通过
总结
令赋值操作符返回一个reference to *this
11 在operator=中处理自我赋值
自定义类型难免在使用时出现自我赋值的情况,如:
class Widget{...};
Widget w;
...
w = w; //赋值给自己
a[i]=a[j]; //潜在自我赋值,当i与j相同
*px=*py; //潜在自我赋值,当px与py指向同一个对象
/
class Base{};
class Derived:public Base{};
void func(const Derived* d,const Base& b);//d和b有可能指向同一个对象
此种情况如果没有考虑,可能会导致异常,如下:
class Bitmap{...};
class Widget{
...
private:
Bitmap* pb;//堆中分配的对象
}
//赋值
Widget& Widget::operator=(const Widget& rhs)
{
delete pb;
pb = new Bitmap(*rhs.pb);
return *this;
}
如上情况,如果是自赋值,那么delete pb不仅可以销毁自己的pb,也会销毁*rhs.pb;新创建的对象将会指向一个被销毁的对象。
可以增加证同测试:
Widget& Widget::operator=(const Widget& rhs)
{
if(this==&rhs) return *this;
delete pb;
pb = new Bitmap(*rhs.pb);
return *this;
}
优点是避免了自赋值问题,缺点是 当new Bitmap出现问题仍然会有问题;证同测试同样会增加一般开销(每次赋值都会判断)。
修改为:
Widget& Widget::operator=(const Widget& rhs)
{
Bitmap* pOrig = pb; //保存原先的pb
pb = new Bitmap(*rhs.pb); //pb指向新创建的对象
delete pOrig ; //删除原先的pb
return *this;
}
当new Bitmap出现问题,原来所指向的内容仍然存在;自赋值的情况也不会出现异常,虽然会同样进行一次操作,但毕竟属于小概率使用场景。
方法3:
class Widget{
void swqp(Widget& rhs); //交换*this和rhs的数据
};
Widget& Widget::operator=(const Widget& rhs)
{
Widget temp(rhs); //为rhs数据制作一份副本
swap(temp); //将*this 数据和上述附件的数据交换
return *this;
}
总结
- 确保当对象自我赋值时
operator=有良好的行为;技术包括:“来源对象”和“目标对象”的地址比较、精心周到的语句顺序、或者交换数据等方式。 - 确保任何函数如果操作一个以上的对象,其中对个对象是同一个对象时,其行为仍然正确。
12 复制对象时勿忘每一个成分
当我们写了拷贝构造和赋值操作符函数后,编译器将不会为我们自动完成这两个函数;如果我们写的拷贝构造和赋值操作符函数中有遗漏的成员没有初始化或者赋值,编译器也不会自动添加。因此我们应谨记每一个成员。
class Customer{
public:
Customer(const Customer& rhs);
Customer& operator=(const Customer& rhs);
private:
std::string name;
};
Customer::Customer(const Customer& rhs):name(rhs.name){
}
Customer& Customer::operator=(const Customer& rhs){
name=rhs.name;
return *this;
}
对于有继承关系的子类的拷贝构造和赋值运算符,需要注意不要遗漏父类的成员。
class PriorityCustomer:public Customer{
public:
PriorityCustomer(const PriorityCustomer& rhs);
PriorityCustomer& operator=(const PriorityCustomer& rhs);
private:
int priority;
};
PriorityCustomer::PriorityCustomer(const PriorityCustomer& rhs)
:Customer(rhs), //调用基类的构造函数
priority(rhs.priority)
{
}
PriorityCustomer& PriorityCustomer::PriorityCustomer& operator=(const PriorityCustomer& rhs){
Customer::operator=(rhs); //调用基类的赋值操作
priority = rhs.priority;
return *this;
}
不建议在拷贝构造函数中调用赋值操作符函数,反之也不建议;如果想避免代码重复,可增加一个公用函数。
总结
- 拷贝函数(构造、赋值运算符)应确保复制对象内的所有成员变量及基类部分。
- 不要尝试以某个拷贝函数实现另一个拷贝函数。应该将共同机制放进第三个函数中,由两个拷贝函数共同调用。
三 资源管理
主要针对内存、句柄等的释放。
13 以对象管理资源
考虑如下使用场景
class Investment{...}; //使用的类
Investment* createInvestment(); //工厂函数,动态分配产生一个Investment类
//以下是对Investment类 的使用
void f(){
Investment* pInv = createInvestment();
...
delete pInv;//释放pInv
}
当函数f中执行一半时返回,或者抛出异常,那么可能会造成没有释放pInv而造成内存泄漏。
这里可以考虑依赖c++的析构函数自动调用机制(当离开作用域后,自动调用该作用域中定义对象的析构函数),也就是书中介绍的使用智能指针。
智能指针拓展介绍
RALL:RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。
其实现如下:
// 使用RAII思想设计的SmartPtr类
template<class T>
class SmartPtr {
public:
SmartPtr(T* ptr = nullptr)
: _ptr(ptr)
{}
~SmartPtr()
{
if(_ptr)
delete _ptr;
}
T& operator*() {return *_ptr;}//重载operator*和opertaor->,具有像指针一样的行为
T* operator->() {return _ptr;}
private:
T* _ptr;
};
针对在智能指针进行拷贝构造或者赋值时,会出现两个指针指向同一块内存的情况的处理,可将智能指针分成3类:
auto_ptr
auto_ptr的实现原理:管理权转移的思想,简单的将原指针设为空,把管理权交给新指针。
auto_ptr(auto_ptr<T>& sp)
:_ptr(sp._ptr)
{
// 管理权转移
sp._ptr = nullptr;
}
缺点:因为有时候指针的权限已经发生了转移,但是使用指针的人并不知道,很可能造成越界访问。
unique_ptr
unique_ptr的实现原理:简单粗暴的防拷贝。
unique_ptr(const unique_ptr<T>& sp) = delete;
unique_ptr<T>& operator=(const unique_ptr<T>& sp) = delete;
shared_ptr
C++11中开始提供更靠谱的并且支持拷贝的shared_ptr。shared_ptr的原理是通过引用计数的方来实现多个shared_ptr对象之间共享资源。
- shared_ptr在其内部,给每个资源都维护了着一份计数,用来记录该份资源被几个对象共享。
- 在对象被销毁时(也就是析构函数调用),就说明自己不使用该资源了,对象的引用计数减一。
- 如果引用计数是0,就说明自己是最后一个使用该资源的对象,必须释放该资源;
- 如果不是0,就说明除了自己还有其他对象在使用该份资源,不能释放该资源,否则其他对象就成野指针了。
注意:
引用计数支持多个拷贝管理同一个资源,最后一个析构对象释放资源。为了保证指向同一块资源的shared_ptr具有相同的count,count要开辟在堆上,每个shared_ptr对象中有一个int类型指针,指向相同资源的shared_ptr中的int类型指针指向相同的count。这里不能为了达到共用效果定义静态类型count,因为静态类型是给所有对象共用,指向不同资源的指针也会共用一个count。
由于引用计数count是共用的,在多线程中可能会发生安全问题,所以要加锁来保护。
模拟实现如下:
template<class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
:_ptr(ptr)
, _pcount(new int(1))
, _pmutex(new mutex)
{}
~shared_ptr()
{
RealseRef();
}
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _pcount(sp._pcount)
, _pmutex(sp._pmutex)
{
AddRef();
}
shared_ptr<T>& operator= (const shared_ptr<T>&sp)
{
if (_ptr == sp._ptr)
{
return *this;
}
//先释放掉现在指向的资源
RealseRef();
_ptr = sp._ptr;
_pmutex = sp._pmutex;
_pcount = sp._pcount;
AddRef();
return *this;
}
private:
void AddRef()
{
_pmutex->lock();
(*_pcount)++;
_pmutex->unlock();
}
void RealseRef()
{
_pmutex->lock();
bool flag = false;
if (--(*_pcount) == 0)
{
delete _ptr;
delete _pcount;
flag = true;
}
_pmutex->unlock();
if (flag == true)
{
delete _pmutex;
}
}
T* _ptr;
int* _pcount;
mutex* _pmutex;
};
缺点:在某些情况下会使用到循环引用,这时候可能会出现问题。
struct ListNode
{
int _data;
shared_ptr<ListNode> _prev;
shared_ptr<ListNode> _next;
~ListNode(){ cout << "~ListNode()" << endl; }
};
int main()
{
shared_ptr<ListNode> node1(new ListNode);
shared_ptr<ListNode> node2(new ListNode);
node1->_next = node2;
node2->_prev = node1;
return 0;
}
就是你中有我,我中有你的关系。(解决方法见原文的weak_ptr)
原文链接:https://blog.csdn.net/weixin_59371851/article/details/127128774
删除器:
析构智能指针时需要的操作并不相同,有时候传给智能指针的指针可能会一下new出来了多个值,这时候就需要delete[ ],或者传过去的指针是打开文件的指针,析构时不应该delete而是进行关闭文件操作。shared_ptr设计了一个删除器来解决这个问题。
template<class T>
struct DelArr
{
void operator()(const T* ptr)
{
cout << "delete[]:"<<ptr<<endl;
delete[] ptr;
}
};
void test_shared_ptr_deletor()
{
std::shared_ptr<ListNode> spArr(new ListNode[10], DelArr<ListNode>());
std::shared_ptr<FILE> spfl(fopen("test.txt", "w"), [](FILE* ptr){
cout << "fclose:" << ptr << endl;
fclose(ptr);
});//lambda匿名函数,捕获变量为空
}
auto_ptr使用讨论
基本使用
void f()
{
std::auto_ptr<Investment> pInv(createInvestment());
...//结束自动经由auto_ptr 销毁 pInv;
}
以对象管理资源的主要思想:
- 获得资源后立即放入管理对象:资源获得时机就是初始化时机。
- 管理对象利用析构函数确保资源被释放:控制流离开作用域,对象被销毁,调用对象的析构完成资源释放。
就如同上面介绍的,如果auto_ptr指向了同一个地方,那么将会析构时产生问题,所以auto_ptr拷贝时转移了控制权,保证了没有一个以上的auto_ptr控制相同的一个资源,所以引入了share_ptr。
share_ptr使用讨论
tr1::shared_ptr就是一个RCSP(reference-counting smart pointer)“引用计数型智能指针”。
void f()
{
std::tr1::share_ptr<Investment> pInv(createInvestment());
...//结束自动经由share_ptr 销毁 pInv;
}
但是无论是auto_ptr还是share_ptr,删除时都是使用的delete而非delete [],所以以下使用还是有些问题,而且可以通过编译:
std::auto_ptr<std::string> aps(new std::string[10]);
std::tr1::shared_ptr<int> spi(new int[1024]);
解决方法可以使用删除器。
以上建议并非只针对、限于auto_ptr、share_ptr,而是其以对象管理资源的主旨。同样以上提到的问题点也是使用时需要考虑的地方。
总结
- 为了 防止资源泄漏,使用RALL对象,他们在构造函数中获取资源,在析构函数中释放资源
- 经常使用的RALL 类有
auto_ptr、share_ptr。通常share_ptr效果更好;auto_ptr复制时会使他指向null。
14 在资源管理类中小心coping行为
就像条款13所说,资源有很多,不止有堆上的内存,还有锁等,碰到这种资源,可能就需要自己写一个管理的类了,如:
class Lock{
public:
explicit Lock(Mutex* pm):mutexPtr(pm){lock(mutexPtr);}
~Lock(){unlock(mutexPtr);}
private:
Mutex mutexPtr;
};
//使用
Mutex m;
{
Lock m1(&m); //锁定
... //解锁
}
同样会面临 复制的问题,其处理可以分为以下四类
禁止复制
实际应用方面也是比较可以理解的,不可对锁进行复制,实现方式参照条款6:
class Lock:private Uncopyable{//禁止复制的类
public:
...
}
使用引用计数
内部含有share_ptr,实现对应的计数
class Lock{
public:
Lock(Mutex* pm):mutexPtr(pm,unlock) //初始化共享指针,unlock作为删除器
{
lock(mutexPtr.get()); //可以获取trl:share_ptr中的资源,这里为对应的锁
}
private:
std::trl:share_ptr<Mutex> mutexPtr; //使用trl:share_ptr替换普通指针
};
这里没有定义析构函数,编译器会自动生成一个,并在析构时调用成员mutexPtr的析构函数,然后减少mutexPtr引用计数,进而调用删除器,完成解锁。
复制底层资源
重新创建一份资源,如在内存中开辟一个空间存放字符串。当前案例似乎不太适合。
转移资源拥有权
就如同auto_ptr。
总结
- 复制
RALL对象时需要复制其管理的资源。复制资源的方式决定了RALL对象的复制行为。 - 常见的
RALL复制行为:禁止复制、使用引用计数。
15 在资源管理类中提供对原始资源的访问
在使用智能指针时总会难以避免的直接访问指针内管理的对象,其访问方式提供了显式和隐式两种。
显式:
std::trl::shared_ptr<Investment> pInv(createInvestment());
int daysHeld(const Investment* pi); //使用函数声明,参数需要是Investment 指针
int days = daysHeld(pInv.get()); //使用以上函数,将pInv内的原始指针传入
另外,share_ptr也重载了*、->操作符。
class Investment
{
public:
bool inTaxFree() const;
};
Investment* createInvestment(); //工厂函数
std::trl::shared_ptr<Investment> pil(createInvestment()); //创建资源并管理
bool taxable = !(pil->isTaxFree()); //通过 -> 运算符访问资源
bool taxable2 = !((*pil).isTaxFree()); //通过 * 运算符访问资源
隐式:
声明隐私转换(格式为:operator type_name();)
FontHandle getFont(); //C API,省略参数
void releaseFont(FontHandle fh); //C API
void changeFontSize(FontHandle f,int newSize); //C API
class Font
{
public:
explicit Font(FontHandle fh):f(fh){ } //获取资源
~Font(){releaseFont(f);} //释放资源
FontHandle get() const {return f;) //显示转换函数
operator FontHandle() const
{return f;} //隐式转换函数,返回一个FontHandle类型的返回值
private:
FontHandle f; //字体资源
};
//使用
Font f(getFont());
int newfontsize;
//显示转换函数使用
changeFontSize(f.get(),newfontsize); //将Font隐式转换为FontHanle
//隐式转换函数使用
changeFontSize(f,newfontsize); //将Font隐式转换为FontHanle
但是隐式转换会增加错误的机会,在需要Font的时候实际上获取到的是FontHandle类型
Font f1(getHanel());
FontHanle f2 = f1; //本意是拷贝一个Font对象,但是却隐式转换为了底部的FontHandle,然后再复制他
//是不是应该写成 Font f2 = f1;
隐式转换 不能说是更好也谈不上更坏,取决于使用场合更偏向于何种方式,更易用,更少出错。
总结
- API往往需要访问原始资源,所以RALL 类应该提供一个取得管理资源的办法。
- 原始资源的访问可能是隐式、显式,一般而言显式更安全,隐式更方便。
16 成对使用new和delete时要采用相同形式
错误使用delete:
std::string* stringArray = new std::string[100];
...
delete stringArray;
正确方式应该是
std::string* stringArray = new std::string;
std::string* stringArray2 = new std::string[100];
...
delete stringArray;
delete [] stringArray2;
创建和销毁的方式应该对应,仔细检查
如下例子:
typedef std::string AddressLinews[4];
std::string* pal = new AddressLinews; //new AddressLinews 返回一个string* ,同 new string[4]
delete pal;//错误
delete [] pal;//正确
所以尽量减少对数组使用typedef
总结
- 在
new中使用[],必须对应delete中也使用[]。如果new中没有使用[],delete中也不要使用[]。
17 以独立语句将newed对象置入智能指针
考虑以下场景:
//定义两个函数
int priority();
void processWidget(std::trl::shared_ptr<Widget> pw, int npriority);
//使用
processWidget(std::trl::shared_ptr<Widget>(new Widget),priority());//第一个参数不能写成new Widget
此种场景可能出现内存泄漏。原因在于参数中函数的调用顺序。
使用过程主要完成第几个操作:
- 调用
priority() - 执行
new Widget - 调用
trl::shared_ptr构造函数
其中,new Widget的执行肯定发生在调用trl::shared_ptr构造函数前,但是priority()的执行顺序确实不受控制,其执行顺序可能如下:
1、执行new Widget
2、调用priority()
3、调用trl::shared_ptr构造函数
如果在调用priority()期间出现异常,意外结束,就有可能造成创建的Widget没有释放。解决方法就是分成两句执行,保证顺序:
std::trl::shared_ptr<Widget> pw(new Widget);
processWidget(pw,priority());
总结
- 以独立的语句将newd对象存储于只能指针内。如果不是这样,一旦异常抛出,可能就以难以察觉的方式造成资源泄漏。
四 设计与声明
18 让接口容易使用,不易被误用
以日期类为例
class Date{
public:
Date(int month, int day, int year);
};
构造时可能写错数字范围,也可能写错顺序(数值范围正确时还不会报错,如2023.06.08写成2023.08.06也不会报错)。
引入适当的类型:
struct Day{
explicit Day(int d):val(d){}
int val;
};
struct Month{
explicit Month(int d):val(d){}
int val;
};
struct Year{
explicit Year(int d):val(d){}
int val;
};
class Date{
public:
Date(const Month& month, const Day& day, const Year& year);
};
这样在使用时就不会意外赋值,保证对应位置是对应的输入类型,输入错误会报错。
可以进一步约束输入范围:
class Month{
public:
static Month Jan(){return Month(1);}
static Month Feb(){return Month(2);}
...
static Month Dec(){return Month(12);}
private:
explicit Month(int m);
};
Date d(Month::Mar(), Day(30),Year(1955));
除非有好理由,否则应该尽量令你的类型的行为与内置类型一致
避免让用户记住做哪些事情,如之前的Investment* createInvestment,返回一个指针,需要用户使用后删除,但是很容易被忘记,导致出错。
避免错误使用createInvestment产生的指针,在创建的时候传入删除器。
std::trl::shared_ptr<Investment> createInvestment()
{
std::trl::shared_ptr<Investment> retVal(static_cast<Investment*>(0),getRidOfInvestment);
retVal = ...;//令retVal指向正确的对象
return retVal;
}
不太理解以上操作,第二步是打算(retVal = new Investment )吗,那为什么不直接写成
std::trl::shared_ptr<Investment> createInvestment()
{
std::trl::shared_ptr<Investment> retVal(new Investment ,getRidOfInvestment);
return retVal;
}
可能是因为函数调用顺序问题,导致先new Investment,然后意外返回导致泄漏?
文章原文:如果被pInv管理的原始指针可以在建立pInv之前先确定下来,那么将原始指针传给pInv构造函数会比先将pInv初始化为null再对他做一次赋值操作为佳。
另外,共享智能指针可以跨模块dll使用,指针引用变0后,会调用创建指针模块中的delete(或删除器)。
智能指针会比原始指针大且慢,可能使用动态内存。但在许多程序中额外的执行成本并不显著,确可以减低客户错误,瑕不掩瑜了算是。
总结
- 好的接口 容易被正确使用,不容易被误用。应该努力达成这个性质。
- 促进正确使用的办法包括接口一致性、与内存类型行为兼容。
- 阻止误用的办法包括建立新类型,限制类型上的操作、束缚对象值,以及消除用户对资源的管理。
- trl::shared_ptr 支持定制型删除器,可防范DLL问题(跨模块内存管理),可以用来解除互斥锁等。
19 设计class犹如设计type
设计类时需要考虑如下问题:
- 新类型的对象如何被创建和销毁:也就是构造和析构函数中要执行的操作,包括分配内存,释放内存等。
- 对象的初始化和对象的赋值有什么差别: 构造函数和赋值操作符中的行为
- 新类型如果是值传递,意味着什么:拷贝构造函数中定义了值传递的实现
- 什么是新类型的合法值:哪些数据集是有效的,需要哪些约束条件,成员函数如构造、赋值操作符需要的检查工作。
- 新类型是否在某个继承体系中:如果在,就需要考虑是否有virtual函数,如果是基类可能需要virtual析构函数(条款7)
- 是否需要类型转换:如果允许隐式类型转换,则需要写相应的类型转换函数(operator T2)。但是当 没有explicit关键字说明的 单一参数的构造函数(non-explicit-one-argument) 与 类型转换函数同时存在则会报错(编译器不知道该调用哪个函数,https://blog.csdn.net/qq_43142509/article/details/125076477),尽量避免二者同时存在;如果希望所有的转换都有显示说明,即只允许explicit构造函数存在,则应避免使用类型转换函数(类型转换操作符operator)和没有explicit关键字说明的 单一参数的构造函数(non-explicit-one-argument),这两种函数都会进行类型转换。
- 新类型支持何种成员函数、操作符等。
- 哪些函数应声明为私有函数。
- 谁可以使用该类型的成员:也就是哪些成员需要声明为public、private,以及友元。
- 未声明接口(undeclared interface):没太理解,就是接口中限制对共享资源的保证。那什么叫未声明接口呢。
- 新类型有多么一般化:就是说新类型该定义为类,还是模板类。
- 是否确实创建一个新类型:考虑是不是只需要在原有类型的基础上派生就可以?
20 宁以 pass-by-reference-to-const 替换 pass-by-value
值传递过程
函数以对象值作为参数,调用时:
1.首先实参需要调用对象的拷贝构造函数,构造出形参
2.如果返回值为对象,在函数结束时,还会拷贝一份新的对象,同时析构形参
对象如果是派生类,则还会调用基类的拷贝构造函数,同样包括对象的成员的拷贝构造函数也需要调用,造成很大的开销。
如果函数参数是对象的常量引用方式,则节省很大开销
Student func(const Student& s){}
对象切割
如下面例子
#include <iostream>
#include <string>
class Window {
public:
Window() { m_strName = "window"; }
Window(std::string &n) { m_strName = n; }
Window(Window& w) { this->m_strName = w.name(); }
~Window() {};
std::string name() const {
return m_strName;
}
virtual void display() const{
printf("name=%s\n", m_strName.c_str());
}
private:
std::string m_strName;
};
class WindowWithBar :public Window {
public:
WindowWithBar() {};
WindowWithBar(std::string &n):Window(n) {};
~WindowWithBar() {};
virtual void display() const {
printf("wb name=%s\n", this->name().c_str());
}
};
void printName(Window w)
{
std::cout << w.name()<<std::endl;
w.display();
}
int main()
{
std::string str("wb");
WindowWithBar wb(str);
std::string str1 = wb.name();
wb.display();//wb name=wb
Window w;
std::string str2 = w.name();
w.display();//name=window
printName(wb);
//wb
//name=wb
printName(w);
//window
//name=window
std::cout << "Hello World!\n";
return 0;
}
函数printName调用时,实参wb拷贝为形参时,忽略了所有WindowWithBar 类型特性,在使用时,总是调用Window::display()。解决切割的方法如下:
void printName(const Window& w)
{
std::count<<w.name();
w.display();
}
引用往往以指针实现,通过引用传参通常意味着传递的是指针。
内置类型 STL迭代器 函数对象
如果对象是内置类型(如int),通过值传递,比引用传递效率更高些;同样适用的还有STL迭代器、函数对象。
参考:https://www.zhihu.com/question/52007599
可以理解STL迭代器为一种泛型指针,拷贝不会有大花销。
而由于编译器可能更侧重把内置类型放入缓存器,所以执行起来更高效。
#include <algorithm>
#include <vector>
#include <ctime>
#include <iostream>
struct neg {
int operator()(int x) { return -x; }
};
void foo1(int i, neg& n) {
int val = n(i);
val = val + 1;
}
void foo2(int i, neg n) {
int val = n(i);
val = val + 1;
}
void test1()
{
neg neg;
clock_t start, end;
start = clock();
for (size_t i = 0; i < 10000000; ++i)
foo1(i, neg);
end = clock();
std::cout << " pass by reference cost: " << end - start << "ms" << std::endl;
}
void test2()
{
neg neg;
clock_t start, end;
start = clock();
for (size_t i = 0; i < 10000000; ++i)
foo2(i, neg);
end = clock();
std::cout << " pass by value cost: " << end - start << "ms" << std::endl;
}
int main()
{
test1();
test2();
/*neg neg1,neg2;
clock_t start, end;
start = clock();
for (size_t i = 0; i < 10000000; ++i)
foo1(i, neg1);
end = clock();
std::cout << " pass by reference cost: " << end - start << "ms" << std::endl;*/
//start = clock();
//for (size_t i = 0; i < 10000000; ++i)
// foo2(i, neg2);
//end = clock();
//std::cout << " pass by value cost: " << end - start << "ms" << std::endl;
return 0;
}

对比foo1,foo2耗时,虽然差的不多,值传递还是快一点(奇怪的是我用注释地方执行结果就是值传递耗时更多,貌似和先后顺序有关)。
总结
- 尽量用常量引用传递 替换 值传递。前者通常比较高效,并且可以避免切割问题
- 以上规则不适用于内置类型,内置类型、STL迭代器、函数对象,值传递更恰当
21 必须返回对象时,别妄想返回其 reference
由于上一节的分析,所以带着避免成员函数内调用构造函数来增加效率的想法进行阅读(最后结果是避免构造函数调用的思想也不需要特别坚持QAQ)
看一个例子:
class Rational {
public:
Rational(int mumerator = 0, int denominator = 1);
private:
int n, d;
friend const Rational operator*(const Rational& lhs, const Rational& rhs);
};
//使用场景如下
Rational a(1, 2);
Rational b(1, 2);
Rational c = a * b;
用于计算有理数的类,其中operator*的实现是研究的重点,试想以下方式
const Rational& operator*(const Rational& lhs, const Rational& rhs)
{
Rational result(lhs.n * rhs.n, lhs.d * rhs.d);
return result;
}
返回值为对象的引用Rational&,而引用所指向的内容定义在函数内部,函数结果后,临时变量result被销毁,引用就没有意义了,导致严重的错误。
那么改进成以下方式:
const Rational& operator*(const Rational& lhs, const Rational& rhs)
{
Rational* result=new Rational(lhs.n * rhs.n, lhs.d * rhs.d);
return *result;
}
Rational w, x, y, z;
w = x * y*z;
解决了局部变量销毁的问题,但是引入了内存泄漏的风险,返回的值还需要使用者及时delete;而且以上合理的使用场景中,无法获取返回的对象,更无从谈起销毁堆中创建的对象。
改进成以下方式:
const Rational& operator*(const Rational& lhs, const Rational& rhs)
{
static Rational result;
result= ...;//计算结果
return result;
}
那么,当增加比较操作符时
if((a*b)==(c*d)){
...
}
此时先计算(a*b)和(c*d),其结果无论如何,都是一个,定义在操作符函数中的变量static Rational result;,结果也就是一直相同(函数内创建static对象全局唯一)。
正确做法:
inline const Rational operator*(const Rational& lhs, const Rational& rhs)
{
return Rational(lhs.n * rhs.n, lhs.d * rhs.d);
}
虽然有构造和析构的代价,但是是正确的实现方式,可以承受这些代价。
在返回引用和返回值之间挑选正确的那个。
总结
- 绝对不要返回一个指向局部变量的指针或引用,或者指向局部静态对象的引用(同时被多个使用者使用)
22 将成员变量声明为private
其原因大致有以下几点
一致性
访问功能时使用函数,访问成员时也使用函数,减少了挤破头皮的思考时间
精确控制
使用函数方式访问成员变量,就可以在函数中做限制,完成只读、只写、读写等功能,通过函数完成成员的读写。
封装性
这也是最重要的原因。
方便日后改动:
比如对成员的调用时机各种情况不一,调用次数少的可以每次调用计算返回值,调用次数多的可以一直维护改变量并在调用时返回,每次改变,用户代码只需要重新编译,不需要修改,因为都是通过相同的成员函数进行访问。
同理,当删除了成员、修改成员后,如果用户代码是直接访问,则会造成大量的用户代码进行修改。
总结
- 切记成员变量声明为private。可赋予客户访问数据的一致性、细分访问控制、允许约束条件获得保证,并提供类作者充分的实现弹性
- protected并不比public更具封装性
23 宁以 non-memeber、non-friend 替换 member 函数
考虑一个浏览器类,可实现清空缓存、urls、历史记录功能:
class WebBrowser{
public:
void clearCache();
void clearHistory();
void removeCookies();
};
那么 清空所有 的功能该怎么实现呢:
写到成员函数中
class WebBrowser{
public:
void clearEverything();
};
写到一个非成员函数
void clearBrowser(WebBrowser& wb)
{
wb.learCache();
wb.clearHistory();
wb.removeCookies();
}
那么哪个更好些呢,考虑封装性:
越多东西被封装,越少人可以看到它,就有越大的弹性改变他,进而对现有客户代码影响越小。
越少代码可以看到数据(成员变量),越多数据可以被封装,越能自由改变对象数据(成员变量的数量、类型等)
理解为 非成员函数且非友元函数放问不到成员变量,所以它的封装性更好;这里的 非成员函数且非友元函数 同样包括其他类的成员函数。
常用的实现方法:将clearBrowser与WebBrowser声明在同一个命名空间内:
namespace WebBrowserStuff{
class WebBrowser{...};
void clearBrowser(WebBrowser& wb);
}
放入命名空间的好处之一就是可以跨源码文件。
另外一个好处就是方便扩展:
浏览器不仅有历史记录等,还有书签、打印等功能,后续肯定还需要更多像clearBrowser功能的函数,那么就可以如下定义:
//头文件 webbrowser.h
namespace WebBrowserStuff{
class WebBrowser{...};//核心机能,所有用户都需要
}
//头文件 webbrowserbookmarks.h
namespace WebBrowserStuff{
void clearBrowser(WebBrowser& wb);//书签、历史记录相关函数
}
//头文件 webbrowserprints.h
namespace WebBrowserStuff{
void clearBrowserPrint(WebBrowser& wb);//打印相关函数
}
将相关便利函数放到多个头文件中,但是隶属于同一个命名空间,用户就可以轻松扩展便利函数,只需要添加响应的函数到命名空间即可。
使用时只需要引用对应的头文件即可,减少了编译不必要函数的消耗。
总结
- 宁可用非成员非友元函数(non-member non-friend)替换成员函数。这样做可以增加封装性、包裹弹性和机能扩充性。
24 若所有参数皆需类型转换,请为此采用 non-member 函数
以一个有理数类为例,想要实现两个有理数的相乘
class Rational {
public:
Rational(int numerator = 0, int denominator = 1);//构造函数刻意不适用explicit
int numerator() const;
int denominator() const;
private:
int numerator;
int denominator;
};
操作符*函数可以使用成员函数,也可以使用非成员函数实现,先看看作为成员函数的实现方法:
class Rational {
public:
const Rational operator*(const Rational& rhs) const;
};
//使用
Rational oneEighth(1, 8);
Rational oneHalf(1, 4);
Rational result = oneHalf * oneEighth;//正确
result = result * oneEighth;//正确
result = oneHalf * 2;//正确
result = 2 * oneHalf;//报错
//等价于
result = oneHalf.operator*( 2 );
result = 2.operator*(oneHalf);//报错
执行oneHalf * 2时,虽然参数为2,而Rational ::operator*需要Rational类型,这里进行了隐式转换(类似:const Rational temp(2); result = oneHalf * temp;),所以 Rational 的构造函数没有进行explicit声明。
这里在计算result = 2 * oneHalf的时候,整数2没有相应的类,也就没有operator*成员函数,这时,编译器尝试寻找非成员函数的operator*(在命名空间内或global作用域中),因为不存在这样的可用函数,所以执行此语句自然会报错。
正确的方式是将operator*声明为全局函数。
class Rational {
public:
...
};
const Rational operator*(const Rational& lhs,const Rational& rhs){
return Rational (lhs.numerator() * rhs.numerator(),lhs.denominator() * rhs.denominator());
}
//使用
Rational oneEighth(1, 8);
Rational oneHalf(1, 4);
result = oneHalf * 2;//正确
result = 2 * oneHalf;//正确
避免友元函数的使用
总结
- 如果需要为某个函数的所有参数(包括this指针所指的那个隐喻参数)进行类型转换,这个函数必须要是非成员函数
25 考虑写出一个不抛出异常的swap函数
忘记为啥swap一定要不抛出异常了,简单回忆下:
为了保证异常安全,当程序在异常发生的时候,程序可以回退的很干净。什么是回退的很干净呢?其实就是函数在发生异常的时候不会泄露资源或者不会发生任何数据结构的破坏。如果说一个函数是异常安全的,那么它必须满足上面提到的两个条件。
异常安全分为三个级别:
- 基本级别:可能发生异常,且在异常发生的时候代码保证做了任何必要的清理工作,即程序在合法阶段,但是一些数据结构可能已经被函数更改,不一定是调用之前的状态,但是基本是保证符合对象正常的要求的;
- 强烈级别:可能发生异常,且在发生异常时代码保证函数对数据做的任何修改都可以被回滚。即如果调用成功,则完全成功;如果调用失败,则对象依旧是调用之前的状态;
- 无异常:即函数保证不会抛出异常(比如标准库的swap函数等)。
参考:https://zhuanlan.zhihu.com/p/318741315
为了正常对接标准库的swap,要做到不抛出异常。
swap原本是STL的一部分,后来成为异常安全编程的脊柱。
默认实现方式
namespace std{
template<typename T>
void swap(T& a,T& b)
{
T temp(a);//置换a、b的值
a = b;
b = temp;
}
}
此种实现方式,只需要T支持拷贝构造函数、拷贝赋值操作符函数。
pimp手法
pointer to implementation,指向实现的指针,以此种方式设计的类如下:
class WidgetImpl{
public:
...
private:
int a, b, c; //表示可能有很多数据
std::vector<double> v; //意味着复制时间会很长
};
class Widget{ //此类使用pimpl的手法
public:
Widget(const Widget& rhs);//肯定存在WidgetImpl对象的复制
Widget& operator=(const Widget& rhs)
{
...
*pImpl = *(rhs.pImpl);//相当于WidgetImpl对象的复制
...
}
private:
WidgetImpl* pImpl; //指针
};
如果要置换两个Widget对象的值,只需要置换其pImpl指针;但是如果使用swap的缺省版本,不只复制了三个Widget,还复制了三个WidgetImpl(两次赋值,一次拷贝构造),导致效率很低(*pImpl内容比较大)。
这里可以在交换两个对象的值时,值进行pImpl指针内容的交换,为了如此实现,需要针对std::swap进行Widget特化,考虑如下:
namespace std{
template<>
void swap<Widget>(Widget& a,Widget& b)
{
swap(a.pImpl, b.pImpl); //只需要置换两个对象的pImpl指针就可以了
}
}
template<>表示这个函数是std::swap的一个全特化版本;函数名之后的 表示此特化版是针对T是Widget设计的。
通常我们不被允许改变std命名空间内的任何东西,但是可以为标准模板制造特化版本,使他专属于我们自己的类,如上的Widget
但是以上写法不能通过编译,因为pImpl是私有成员;但是如果修改为友元函数,又破坏了封装性,考虑以下实现方式:
class Widget{
public:
Widget(const Widget& rhs);
Widget& operator=(const Widget& rhs)
{
...
}
void swap(Widget& other)
{
using std::swap;//声明命名空间,使用标准的swap
swap(pImpl, other.pImpl);//只需要置换两个对象的pImpl指针
}
private:
WidgetImpl* pImpl; //指针
};
namespace std{
template<>
void swap<Widget>(Widget& a,Widget& b)
{
a.swap(b); //调用成员方法执行pImpl指针执行
}
}
模板类的swap
//模板类的实现比较容易
template<typename T>
class WidgetImpl{...};
template<typename T>
class Widget{...};
//特化时出现问题
namespace std{
template<typename T>
void swap<Widget<T>>(Widget<T>& a,Widget<T>& b) //错误,不合法 ,企图偏特化函数模板
{
a.swap(b);
}
}
再看下特化的相关说明:
全特化:将所有模板参数固定成指定类型,以此来告诉编译器,当为此种类型时,需要特殊处理。
偏特化:将部分模板参数固定成指定类型。函数模板是不允许偏特化的,但函数允许重载,从而声明另一个函数模板即可替代偏特化的需要。
偏特化分为个数上面的偏特化和范围上的偏特化。函数存在重载和重定义的特性,函数推导过程必须要依次精确匹配,函数不存在偏特化。
如果想要偏特化一个函数模板,惯用的方法时增加一个重载:
namespace std{
template<typename T>
void swap(Widget<T>& a,Widget<T>& b) //函数的重载
{
a.swap(b);
}
}
但是依旧不合法,因为std是一个特殊的命名空间,c++标准委员会禁止添加新的模板到std中。于是修改为:
namespace WidgetStuff{
...
template<typename T>
class Widget{...}; //同前,内含swap成员函数
template<typename T>
void swap(Widget<T>& a,Widget<T>& b) //函数的重载,非成员函数,不属于std命名空间
{
a.swap(b);
}
}
在使用时,为了保证可以用到std命名空间中的版本,应该如下使用:
template<typename T>
void doSometion(T& obj1,T& obj2)
{
using std::swap; //令std::swap在此函数内可用
swap(obj1,obj2); //为T类型对象调用最佳的swap版本
}
编译器优先查找全局及T定义的命名空间内的 swap 的T类型特例化版本,如果没有特例的,则会寻找std中模板的swap。
如果T类型为 Widget,那么则会调用 WidgetStuff 中重载版 swap ;如果写为std::swap(obj1,obj2),那么就会强制调用std中的swap
整体过程
如果 默认版本的swap能够满足需求,那就最好了,直接调用就可以。
如果 默认版本的swap效率不足(如上面提到的,还有pimpl手法),那么可以考虑如下实现方式:
- 提供一个公有的成员函数
swap,实现高效的置换自定义类的对象值,这个函数不能抛出异常。 - 在这个自定义类或者模板类的命名空间内提供一个非成员函数
swap,调用以上的成员函数swap - 如果编写的类没有使用template,可以为此类特化一个
std::swap函数,并用它调用以上的成员函数swap
使用时,确保声明了using std::swap;,然后不加命名空间修饰的、赤裸裸的调用swap.
总结
- 当
std::swap效率不高时,提供一个公有的成员函数swap,这个函数不能抛出异常。 - 如果提供一个成员函数
swap,也该提供一个非成员函数swap来调用前者,对于类,需要特化std::swap。 - 调用swap时应针对std::swap使用using声明,调用swap时不带任何“命名空间资格修饰”
- 为用户自定义类进行std templates全特化是推荐的,但是不要尝试在std中增加对于std而言是全新的东西(如函数重载)
五 实现
26 尽可能延后变量定义式的出现时间
举例说明:
std::string encryptPassword(const std::string& password)
{
using namespace std;
string encrypted; //位置1
if(password.length() < minimum){
throw logicErr("password too short");
}
//string encrypted;//位置2
...
return encrypted;
}
显然,在位置1处定义 encrypted 不如在位置2处定义,因为当发生异常时,encrypted 的定义就显得有些多余了,所以尽量在变量被使用时再进行定义。
对于变量的初值问题,有过讨论,就是 调用构造 比 调用构造再调用赋值 要来的效率高些,如函数本来期望实现如下:
void encrypt(std::string& s);//实现加密的函数
std::string encryptPassword(const std::string& password)
{
using namespace std;
if(password.length() < minimum){
throw logicErr("password too short");
}
string encrypted;
encrypted = password;//这里就不如 string encrypted(password)
encrypt(encrypted);
return encrypted;
}
在这里延后变量的定义,就可以理解为 尝试延后定义直到能给它初值实参为止。
循环中的定义
考虑如下两种方式:
//定义于循环外
Widget w;
for(int i=0; i < n; ++i)
{
w = i+1;
}
//定义于循环内
for(int i=0; i < n; ++i)
{
Widget w(i+1);
}
循环外消耗:1个构造函数+1个析构函数+n个赋值操作
循环内消耗:n个构造函数+n个析构函数
一般而言,循环外定义效率会高些,尤其循环次数多,但缺点是作用域大,易维护性降低。
如果赋值成本比(构造+析构)成本高,对效率不敏感,建议使用循环定义的方式。
总结
- 尽可能延后变量定义的出现。这样可以增加程序的清晰度并改善程序效率。
27 尽量少做转型动作
四种常用的新型转型:
const_cast<T>(expression)
dynamic_cast<T>(expression)
reinterpret_cast<T>(expression)
static_cast<T>(expression)
const_cast
用来移除对象的常量属性,也是唯一有此能力的c++风格转型操作符。
如:
const int &a = 3;
const_cast<int&>(a) = 4;
同样也可以使用指针,但是不能使用非指针非引用的常量,如下错误示范
const int a = 3;
const_cast<int>(a) = 4; //错误
dynamic_cast
dynamic_cast<type_id>(expression),将expression转换为 type_id 类型(type_id必须为指针、引用或void*)
- 如果 expression 是指针类型,那么 type_id 也需要是指针类型
- 如果 expression 是引用类型,那么 type_id 也需要是引用类型
- dynamic_cast主要用于类层次间的上行转换和下行转换(子类转换为父类、父类转换位子类),还可以用于类之间的交叉转换;其中进行上行转换时,dynamic_cast和static_cast的效果一样;进行下行转换时,dynamic_cast具有类型检查功能,比static_cast更安全;
- 在多态类型之间转换主要使用dynamic_cast,多态类型之间转换:使用static_cast和使用dynamic_cast效果一样;非多态(没有声明virtual)类型之间转换:只能使用static_cast,使用dynamic_cast会编译报错;
- 如果expression类型是type-id的基类,使用dynamic_cast进行转换时,在运行时会检查expression是否真正的指向一个type-id类型的对象。
如动态判断某个类型(pa1)是否是某个类型(B)时:
A* pa1 = new B;//B是A的子类
B* b1 = dynamic_cast<B*>(pa1); //ok,编译无误,b != nullptr
if (nullptr != b1)
{
b1->Func();
}
多重继承关系情况(A派生出B,B派生出C),需要把子类逐步转换到父类(C转换为B,再转换为A)
dynamic_cast 是唯一无法由旧式语法执行的动作,也是唯一耗费巨大成本的转换动作
reinterpret_cast
执行低级转型,如把一个指向整型的指针转型为 int。单纯的把指针地址转换为整数,可以在打印指针地址时使用
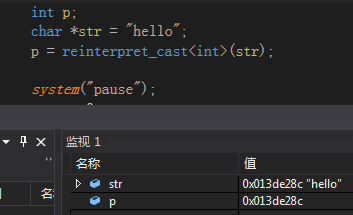
参考https://blog.csdn.net/bajianxiaofendui/article/details/86616256
该类型转换比较少用
static_cast
用来执行强制隐式转换;可以将非const类型转换为const类型;int 转换为 double(注意类型间是否有效,如char转换为int是否为有效的ASCII码);将void* 指针转换为其他自定义类 的指针,父类指针转换为子类指针(多态和非多态)。
使用新的转型好处是:1. 方便查看是否进行了类型转换;2.编译器可以方便查看是否转换错误
派生类指针与基类指针
#include <iostream>
class Widget {
public:
Widget() {};
virtual ~Widget() {};
explicit Widget(int size) { this->m_size = size; };
virtual void says() { std::cout << "Hello Widget!\n"; };
int m_size;
};
void useWidget(const Widget& w) {
return;
};
class DerivedWidget :public Widget{
void says() { std::cout << "Hello DerivedWidget!\n"; };
int m_shape;
};
int main()
{
useWidget(Widget(5));//函数风格的转型动作 创建一个Widget
useWidget(static_cast<Widget>(5));//c++ 风格的转型 动作创建一个Widget
DerivedWidget d;
DerivedWidget* pd = &d;//0x00d3f824
Widget* pb = &d;//0x00d3f824
std::cout << "Hello World!\n";
}
转型操作不仅是告诉编译器把某种类型视为另一种类型。任何一个类型转换(不论是通过转型操作而进行的显示转换,还是通过编译器完成的隐式转换)往往真的令编译器编译成运行期间执行的码(举例将int转换为double)。
基类指针指向派生类对象时,有时这两个指针值不相同(如上例,没有出现这种情况,vs2017),因为可能会有个偏移量施行到了派生类指针上,用来获取正确的基类指针值。如果出现了指针偏移的现象,应用时最好不要妄图根据偏移量来操作指针,这种方法对于不同的编译器表现可能不一样。
查看例子:
class MyWindow {
public:
virtual void onResize() {
m_nSize++;
};
int m_nSize;
};
class MySpecialWindow:public MyWindow {
public:
virtual void onResize() {
static_cast<MyWindow>(*this).onResize();
//MySpecialWindow 专属操作
};
void blink(){};
};
上例中,static_cast<MyWindow>(*this)会生成一个MyWindow的副本,再调用该副本的onResize方法,如果在onResize进行了修改成员的操作,那么修改的只是副本的成员,而不是当前基类的成员,正确方式如下:
class MySpecialWindow:public MyWindow {
public:
virtual void onResize() {
MyWindow::onResize();
//MySpecialWindow 专属操作
};
};
对于dynamic_cast的使用,尽量避免过多调用,其效率比较低,如下场景
typedef std::vector< std::strl::shared_ptr<Window> VPW;
VPW winPtrs;
for (VPW::iterator iter = winPtrs.begin(); iter != winPtrs.end(); ++iter) {
if (MySpecialWindow *psw = dynamic_cast<MySpecialWindow*>(iter->get()))
psw->blink();
}
通过dynamic_cast返回的值是不是为NULL,判断指向派生类的基类指针是不是为所要使用的派生类,然后执行其方法。这里耗时可能就比较多,尤其继承体系比较复杂、冗长的时候,尽量避免在容器中放入基类指针;或者在基类中也实现一个什么也不做的方法,(如上例子的blink),这样就可以直接调用psw->blink(),而不用判断是不是某个指定的派生类了。
同样的避免下列执行起来非常耗时的代码:
for (VPW::iterator iter = winPtrs.begin(); iter != winPtrs.end(); ++iter) {
if (MySpecialWindow *psw = dynamic_cast<MySpecialWindow*>(iter->get()))
{..}
else if (MySpecialWindow2 *psw2 = dynamic_cast<MySpecialWindow2*>(iter->get()))
{..}
else if (MySpecialWindow3 *psw3 = dynamic_cast<MySpecialWindow3*>(iter->get()))
{..}
}
这样的代码运行慢,耗时长,而且不利于维护,尽量改为基于虚函数调用的方法实现。
优良的c++代码很少使用转型,但是如果说要完全摆脱他们有不太现实。只能说尽量少使用,尽量在接口内部实现。
总结
- 如果可以,尽量避免转型,特别是在注重效率的代码中避免
dynamic_cast。如果有个设计需要转型动作,试着发展无需转型的替代设计 - 如果转型是必要的,试着将它隐藏于某个函数背后。客户随后可以调用该函数,而不需将转型放进他们自己的代码内
- 宁可使用C+±style(新式)转型,不要使用旧式转型。前者很容易辨识出来,而且也比较有着分门别类的职掌
28 避免返回handles指向对象内部成分
查看例子:
class Point{ //点类
public:
Point(int x,int y);
void setX(int newVal);
void setY(int newVal);
};
struct RectData{ //点的存储结构
Point ulhc;
Point lrhc;
};
class Rectangle{
private:
std::tr1::shared_ptr<RectData> pData;
public:
Pointer& upperLeft() const {return pData->ulhc;}
Pointer& lowerRight() const {return pData->lrhc;}
};
其中upperLeft,lowerRight函数的设计本意返回左上角的点和右下角的点,并且不允许修改这两个点,但是却返回了两点的引用,使用者可随意调用setX、setY修改其内容,打破的封装性,可修改为:
const Pointer& upperLeft() const {return pData->ulhc;}
const Pointer& lowerRight() const {return pData->lrhc;}
虽然修改了封装性,但仍然存在隐患,查看一下例子:
class GUIObject{...};
const Rectangle boundingBox(const GUIObject& obj);
GUIObject *pgo;
const Point* pUpperLeft = &(boundingBox(*pgo).upperLeft()); //取得一个指针指向外框左上点
函数 boundingBox 返回一个Rectangle 对象,调用该对象的 upperLeft 方法,进而获取Rectangle 对象的左上点,但是,Rectangle 对象在执行以上语句后马上销毁了,所以导致pUpperLeft 指向了一个无意义的地方。
所以说返回一个对象内部的指针、引用(也就是handle对象)是一件危险的事情;像vector,string的[]操作符返回内部的元素的引用,也会随着容器的销毁而销毁,这里可以当做例外,而非常态;所以除非必要,减少返回handle的使用。
总结
- 避免返回handles(包括references、指针、迭代器)指向对象内部。遵守这个条款可以增加封装性,帮助const成员函数行为更像const,并将发生 指向无意义地址 (虚掉号码牌)的可能行将至最低。
29 为“异常安全”而努力是值得的
异常安全性函数满足的条件:
- 不泄露任何资源:也就是没有内存泄漏、句柄泄漏等
- 不允许数据破坏:理解为成员/输出参数 没有错误累加、赋值、修改等。
异常安全函数提供一下三个保证之一:
- 基本承诺:如果异常被抛出,程序内的任何事物仍然保持在有效状态下。函数在异常后,可以预知各个成员是有意义的(但不一定是有逻辑性的,如成员的值错误自增,表示成功执行次数,但后面异常退出,实际没有执行成功)。
- 强烈保证:如果异常被抛出,程序状态不改变。调用这样的函数需有这样的认知:如果函数成功,就是完全成功,如果函数失败,程序会回复到“调用函数之前”的状态。
- 不抛出异常保证:承诺绝不抛出异常,因为它们总是能够完成它们原先承诺的功能。作用于内置类型(例如 ints,指针等等)身上的所有操作都提供nothrow保证。
如下例子:
class PrettyMenu{
public:
void changeBg(std::istream& imgSrc);///改变背景图像
private:
Mutex mutex; //互斥量
Image* bgImage; //当前背景图片
int imageChanges; //背景被修改的次数
};
//实现
void PrettyMenu::changeBg(std::istream& imgSrc)
{
lock(&mutex); //获取互斥量
delete bgImage; //删除旧图片
++imageChanges; //计数
bgImage = new Image(imgSrc); //加载新图片
unlock(&mutex); //删除互斥量
}
new Image(imgSrc);过程可能会异常终止,那么锁就一直没有释放,
导致锁不安全
导致计数不准
导致bgImage成员无意义
考虑之前说过的以对象管理资源
class PrettyMenu{
std::trl::shared_ptr<Image> bgImage; //当前背景图片
};
//实现
void PrettyMenu::changeBg(std::istream& imgSrc)
{
Lock ml(&mutex); //保证发生异常后可以释放
bgImage.reset(new Image(imgSrc)); //删除旧图片 加载新图片
++imageChanges; //计数
}
bgImage.reset(new Image(imgSrc));一起执行,排除指向无意义的情况;而后才计数,保证计数准确。
如果要做到 强烈保证,改怎么实现呢
struct PMImpl{
std::trl::shared_ptr<Image> bgImage;
int imageChanges;
};
class PrettyMenu{
Mutex mutex; //互斥量
std::trl::shared_ptr<PMImpl> pPMImpl; //合二为一的成员
};
//实现
void PrettyMenu::changeBg(std::istream& imgSrc)
{
using std::swap;
Lock ml(&mutex);
std::trl::shared_ptr<PMImpl> pNew(new PMImpl(*pPMImpl));//创建副本数据
pNew->bgImage.reset(new Image(imgSrc));
++pNew->imageChanges;
swap(pPMImpl,pNew);
}
以上方式可以完成需求,隐患就是面临时间和空间的考量,需要作出副本操作。
试想一下另外一种场景:
void someFunc()
{
f1();
f2()
}
如果f1或者f2非异常安全或者强烈保证,那么someFunc也无法保证异常安全或强烈保证。
即使f1与f2都是强烈异常安全,当f2执行异常回归了执行f2之前的状态,由于已经执行了f1,someFunc无法回到执行f1之前的状态了,依旧无法保证强烈异常安全。
所以强烈异常安全不是非做不可的事,需要视具体情况考虑。
总结
- 异常安全函数(Exception-safe functions)即使发生异常也不会泄漏资源或允许任何数据结构败坏。这样的函数区分为三种可能的保证:基本型、强烈型、不抛异常型。
- “强烈保证”往往能够以 copy-and-swap 实现出来,但“强烈保证”并非对所有函数都可实现或具备现实意义。
- 函数提供的“异常安全保证”通常最高只等于其所调用之各个函数的“异常安全保证”中的最弱者。
30 透彻了解 inlining 的里里外外
如何抉择
使用内联函数的好处是可以省却函数调用的成本,潜在隐患是,当函数体比较大时可能会导致形成的目标代码比较大,会影响到效率。
所以,如果inline函数本体很小,编译器针对调用函数产生的代码 要比内联函数替换的代码大时,建议采用inline函数。
另外,如果函数被声明了inline,相关使用到的地方,如果函数发生了变量,都需要重新编译;如果不是内联函数,则只需要进行连接就可以。
内联函数的调试在很多编译器中也支持调试模型打断点。
声明方式
隐喻申请
class Person{
public:
int age() const {return theAge} //age()为内联函数
private:
int theAge;
}
明确申请inline
template<typename T>
inline const T& std::max(const T& a, const T& b)
{return a<b?b:a;} //关键字inline明确申请内联
内联函数和模板函数一般都被定义到头文件中(大多数编译器也都是在编译器完成内联函数的替换 和 模板函数的具体化),但是模板函数不一定非得是内联函数(毕竟各个类型的具象化后替换的地方比较多,有可能导致效率降低)。
什么时候内联,什么时候不内敛
申请了inline的函数不一定会真正的变成内联函数,取决于编译环境和编译器。
编译器不会把带有循环和递归的函数进行内联。
不会把虚函数进行内联(运行时才知道具体如何执行)。
不会把使用函数指针调用函数的部分进行内联。
inline void f(){...}
void (*pf)() = f; //pf为函数指针,指向f
f(); //这个调用会被内联处理
pf(); //此调用不会内联(还会生成一个outline函数,已取得他的地址)
构造和析构中的内联
c++对于“对象被创建和被销毁时发生什么事”做了各式各样的保证。当你使用new,动态创建的对象被其构造函数自动初始化;当你使用delete,对应的析构函数会被调用。当你创建一个对象,其每一个base class 及每-个成员变量都会被自动构造;当你销毁一个对象,反向程序的析构行为亦会自动发生。如果有个异常在对象构造期间被抛出,该对象已构造好的那一部分会被自动销毁。在这些情况中C++描述了什么-一定会发生,但没有说如何发生。
如以下例子:
class Base{
private:
std::string bm1,bm2;
};
class Derived:public Base{
public:
Derived(){}
private:
std::string dm1,dm2,dm3;
}
对于构造和析构,编译器为了完成c++标准的要求,可能会插入自己的代码,上面的例子中空白的Derived(){}可能就会按照以下方式实现:
Derived::Derived()
{
Base::Base(); //初始化基类部分
try{dm1.std::string::string();} //构造dm1
catch(...){
Base::~Base(); //抛出异常时销毁基类部分
throw;
}
try{dm2.std::string::string();}
catch(...){
dm1.std::string::~string();
Base::~Base();
throw;
}
try{dm3.std::string::string();}
catch(...){
dm2.std::string::~string();
dm1.std::string::~string();
Base::~Base();
throw;
}
}
这里调用了多次string的构造函数,如果这是我们自定义的类,且声明了inline,那么将会产生很多代码替换。
总结
- 将大多数inlining限制在小型、被频繁调用的函数身上。这可使日后的调试过程和二进制升级(binary upgradability)更容易,也可使潜在的代码膨胀问题最小化,使程序的速度提升机会最大化。
- 不要只因为function templates出现在头文件,就将它们声明为inline。
31 将文件间的编译依存关系降至最低
避免编译时各个文件中关联依存太多,导致所有相关文件都需要编译。
指针类型成员
测试例子:
//----------------------- a.h
#pragma once
class A
{
public:
A();
~A();
void says();
private:
int m_a;
int m_b;
};
//----------------------- a.cpp
#include"a.h"
#include<iostream>
A::A()
{
m_a = 1;
m_b = 2;
}
A::~A()
{
}
void A::says()
{
m_a++;
m_b++;
std::cout << m_a << " " << m_b << std::endl;
}
//----------------------- B.h
#pragma once
//#include"a.h"
class A;
class B
{
public:
B();
~B();
void speak();
private:
A* m_pa;//这里使用A类型的指针,所以大小固定,编译器知道需要多大空间;如果这里是A m_a;那么必须引入A的头文件,编译器才知道需要多大空间,也就不能继续按照此方法减少依存了。
int b;
};
//----------------------- B.cpp
#include"B.h"
#include"a.h"//不引用无法识别A
B::B()
{
m_pa = new A;
}
B::~B()
{
delete m_pa;
}
void B::speak()
{
m_pa->says();
}
//compile.cpp
//应用
#include <iostream>
#include"B.h"
int main()
{
B bo;
bo.speak();
bo.speak();
std::cout << "Hello World!\n";
}
类B的实现(cpp)中包含其他依赖(类A)的头文件,引用此类(B)头文件的应用程序C,在A发生变化后不需要重新编译。(当A发生变化,B会重新编译)
这就是优化后的代码,应用中引入了B.h,当B.h没有发生变化,应用cpp就不用重新编译;B.h,不需要引用A.h,只需要声明class A;,就可创建对应的指针,不影响类B的声明。
原本的场景
修改B的头文件:
#include"a.h"//增加引用
//class A;//删除声明
修改实现文件B.cpp
//#include"a.h"//删除引用
类B的头文件中包含其他依赖(类A)的头文件,引用此类(B)头文件的应用程序C,在A发生变化后需要重新编译。
(当A发生变化,B会重新编译)
这时互相依存,应用cpp引用B.h,B.h引用A.h,当其中一个发生变化,就需要编译对应引用到的文件。
将实现功能部分分离单独的类(handle classes)
//----------------------- c.h
#pragma once
class C
{
public:
C();
~C();
void says();
private:
int m_a;
int m_b;
};
//----------------------- c.pp
#include"c.h"
#include<iostream>
C::C()
{
m_a = 1;
m_b = 2;
}
C::~C()
{
}
void C::says()
{
m_a++;
m_b++;
std::cout << m_a << " " << m_b << std::endl;
}
//----------------------- d_impl.h
#pragma once
#include "c.h"
class Dimpl
{
public:
void foo(C& c);
private:
C c;//编译器需要在编译期间知道对象的大小,所以需要引用头文件c.h
};
//----------------------- d_impl.cpp
#include"d_impl.h"
void Dimpl::foo(C& c)
{
c.says();
}
指向实现类的成员指针,如此设计被称为pimpl idiom(pointer to implementation),如下的成员d_impl,将Dimpl的实现与引用d.h的应用相分离。
//----------------------- d.h
#pragma once
#include<memory>
class C;
class Dimpl;
class D
{
public:
D();
~D();
void foo(C& c);
private:
std::shared_ptr<Dimpl> d_impl;
};
//----------------------- d.cpp
#include"d.h"
#include"d_impl.h"
D::D():d_impl(new Dimpl())
{
}
D::~D()
{
}
void D::foo(C& c)
{
d_impl->foo(c);
}
//compile.cpp
#include <iostream>
#include"d.h"
int main()
{
D dobj;
std::cout << "Hello World!\n";
}

如指针方法类似,主要在于d.h中没有引入头文件,当c.h发生变化后,d.cpp和d_impl.cpp都需要重新编译,而应用compile.cpp不需要编译。
如果业务满足的情况下(d_impl不再需要C成员,或者换成C指针类型成员,接口类好像本身不需要成员变量),可以改变成如下:
//----------------------- d_impl.h
#pragma once
class C;
class Dimpl
{
public:
void foo(C& c);
};
//----------------------- d_impl.cpp
#include"d_impl.h"
#include "c.h"
void Dimpl::foo(C& c)
{
c.says();
}
当c.h发生变化后,只有d_impl.cpp都需要重新编译,而应用d.cpp和compile.cpp不需要编译。
整体思路就是:以声明的依存性来代替定义的依存性。尽量以声明式来满足文件的需求,这需要结合引用或者指针来替代对象的实例(也就是上面的C m_c;成员修改为C* m_pc;或者接口类的指针)。如果对象只出现在类的函数接口中,一般使用声明式就行了;头文件能不引入头文件就不引入头文件,声明能满足的情况下声明就好了。
- 如果使用object references 或object pointers可以完成任务,就不要使用objects。你可以只靠一个类型声明式就定义出指向该类型的references和pointers;但如果定义某类型的objects,就需要用到该类型的定义式。
- 如果能够,尽量以class声明式替换class定义式。注意,当你声明一个函数而它用到某个class时,你并不需要该class的定义;纵使函数以by value方式传递该类型的参数(或返回值)亦然:
#pragma once
class C;
class Dimpl
{
public:
void foo(C& c); //不需要C的定义
C fun1();//不需要C的定义
};
- 为声明式和定义式提供不同的头文件:比如datefwd.h中只有声明,date.h中有对类的定义。没咋遇到过此种使用方式
接口类(interface class)
就如上面的一样,只不过是更标准的c++接口类
//----------------------- e.h
#pragma once
class E
{
public:
E();
~E();
void says();
};
//----------------------- e.cpp
#include"e.h"
#include<iostream>
E::E()
{
}
E::~E()
{
}
void E::says()
{
std::cout << "cccc "<< std::endl;
}
//----------------------- f.h
//也就是接口类
#pragma once
#include <memory>
class E;
class F
{
public:
virtual ~F() {};//接口类通常没有构造函数
virtual void foo() = 0;
static std::shared_ptr<F> create();
};
//----------------------- fd.h
#pragma once
#include "e.h"
#include "f.h"
class F_d : public F
{
public:
F_d() {};
virtual ~F_d() {};
void foo();
private:
E e;
};
//----------------------- fd.cpp
#include"fd.h"
#include<iostream>
void F_d::foo() {
std::cout << "fd" << std::endl;
}
std::shared_ptr<F> F::create() { return std::shared_ptr<F>(new F_d()); }
//compile.cpp
#include <iostream>
#include "f.h"
int main()
{
F::create()->foo();
std::cout << "Hello World!\n";
}
当e.h发生变化后,只有fd.cpp需要重新编译,compile.cpp不需要重新编译。
以上参考https://blog.csdn.net/xholes/article/details/91481873
粗略过了一遍这一节,感觉可以细读一遍
总结
- 支持“编译依存性最小化”的一般构想是:相依于声明式,不要相依于定义式。基于此构想的两个手段是Handle classes和 Interface classes。
- 程序库头文件应该以“完全且仅有声明式”( full and declaration-only forms)的形式存在。这种做法不论是否涉及templates都适用。(这条没有理解)















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









