







java8出来这么久,当中的一种特性就是流处理,流处理的代码看起来相当简洁;下面就总结下有哪些流处理的API;
一、foreach
作用:用于集合的遍历,代码如下:
@Test
public void foreach(){
List<String> strings = new ArrayList<>();
strings.add("xxxx");
strings.add("yyyy");
strings.stream().forEach(System.out::println);
}输出:
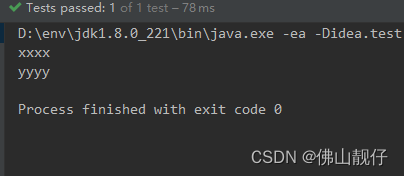
特别说明一下双冒号在java8中是什么意思,双冒号是lambda表达式的一种简写,被用作方法引用;用lambda表达式会创建匿名函数,但有时候需要使用一个lambda表达式只调用一个已经存在的方法,不做其他,所以才有这个引用;所以上述代码等价于以下:

二、collect
作用:收集器,能够将流转换为其他形式,例如:list、set、map集合
@Test
public void collect(){
List<String> strings = new ArrayList<>();
strings.add("xxxx");
strings.add("yyyy");
System.out.println("strings = " + strings);
// 将 strings 集合转化成 set 集合
Set<String> set = strings.stream().collect(Collectors.toSet());
System.out.println("set = " + set);
// 将 strings 转换成 map 集合,key 为 prod_ + 集合中的值,value 为集合中的值
/**
* v -> "prod_" + v key
* v -> v value
* (oldValue, newValue) -> newValue 遇到重复的选 newValue
*/
Map<String, String> toMap = strings.stream().collect(Collectors.toMap(v -> "prod_" + v, v -> v, (oldValue, newValue) -> newValue));
System.out.println("toMap = " + toMap);
// 将 student 集合按照 id(唯一) 封装成 map 集合
List<Student> students = new ArrayList<>();
students.add(new Student(1, 2));
students.add(new Student(2, 4));
Map<String, Student> studentMap = students.stream().collect(Collectors.toMap(student -> student.getId().toString(), student -> student));
System.out.println("studentMap = " + studentMap);
// 将 students 集合按照 年龄 封装成 map 集合
Map<String, List<Student>> studentListMap = students.stream().collect(Collectors.groupingBy(student -> String.valueOf(student.getAge())));
System.out.println("studentListMap = " + studentListMap);
}
@Data
class Student{
private Integer id;
private Integer age;
public Student(int id, int age){
this.id = id;
this.age = age;
}
}输出:

三、filte
作用:过滤元素
@Test
public void filter() {
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("yyyy");
// 将 strings 集合中带 f 的字符串筛选出来放如另外一个集合
List<String> filterStrings = strings.stream().filter(str -> str.contains("f")).collect(Collectors.toList());
filterStrings.forEach(System.out::println);
System.out.println("====================================");
// 将 students 集合中叫年龄为 18 的同学找出来
List<Student> students = new ArrayList<>();
students.add(new Student(1, 18));
students.add(new Student(2, 4));
List<Student> filterStudents = students.stream().filter(student -> {return 18 == student.getAge();}).collect(Collectors.toList());
filterStudents.forEach(System.out::println);
}
@Data
class Student{
private Integer id;
private Integer age;
public Student(int id, int age){
this.id = id;
this.age = age;
}
}输出:
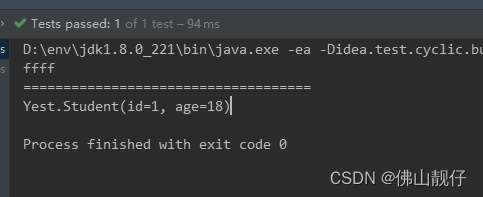
四、distinct
作用:跟数据库中的distinct函数一样,用于去除重复的数据
@Test
public void distinct() {
// 去除集合中重复的元素
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyy");
List<String> distinct = strings.stream().distinct().collect(Collectors.toList());
distinct.forEach(System.out::println);
System.out.println("====================================");
List<Student> students = new ArrayList<>();
students.add(new Student(1, 18));
students.add(new Student(1, 18));
List<Student> distinctStudents = students.stream().distinct().collect(Collectors.toList());
distinctStudents.forEach( student -> System.out.println(student.toString()));
}
@Data
class Student{
private Integer id;
private Integer age;
public Student(int id, int age){
this.id = id;
this.age = age;
}
}输出:
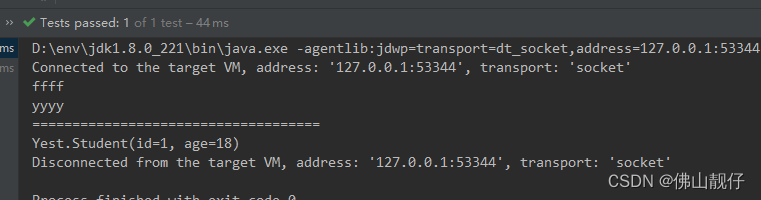
说明:去重是基于hashCode()和equals()方法去比较是否重复的;
五、limit
作用:获取数据流中的前n个;类似于mysql的limit分页;
@Test
public void limit() {
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyy");
List<String> limitStrings = strings.stream().limit(2).collect(Collectors.toList());
limitStrings.forEach(System.out::println);
System.out.println("====================================");
Random random = new Random();
random.ints().limit(5).forEach(System.out::println);
}输出:

六、skip
作用:获取数据流中 除去前n个元素 的其他所有元素
@Test
public void skip() {
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyy");
List<String> skipNames = strings.stream().skip(2).collect(Collectors.toList());
skipNames.forEach(System.out::println);
}输出:

七、map
作用:用于映射每个元素到对应的结果; 它会对流中所有的元素进行处理,并且创建一个新的版本返回,不会在原有的元素上修改数据;
@Test
public void map() {
// 将集合 names 中的每个元素都拼接一个 A- str -A
// 会将箭头函数处理出来的结果作为集合中的元素返回
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyy");
List<String> mapNames = strings.stream().map( str -> "A-"+ str.concat("-A")).collect(Collectors.toList());
mapNames.forEach(System.out::println);
System.out.println("====================================");
// 获取 students 集合中每个同学的 名字
List<Student> students = new ArrayList<>();
students.add(new Student(1, 18, "xxxx"));
students.add(new Student(1, 18, "yyyy"));
List<String> mapStudents = students.stream().map(Student::getName).collect(Collectors.toList());
mapStudents.forEach(System.out::println);
}
@Data
class Student{
private Integer id;
private Integer age;
private String name;
public Student(int id, int age){
this.id = id;
this.age = age;
}
public Student(int id, int age, String name){
this.id = id;
this.age = age;
this.name = name;
}
}输出:

八、flatMap
作用:流的扁平化处理; 跟map不同的是flatmap 是会将元素的子集合元素全部拿出来做统一处理;
@Test
public void flatMap() {
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyy");
List<Character> flatMap = strings.stream().flatMap(Yest::getCharacterByString)
.collect(Collectors.toList());
System.out.println(flatMap);
}
public static Stream<Character> getCharacterByString(String str) {
List<Character> characterList = new ArrayList<>();
for (Character character : str.toCharArray()) {
characterList.add(character);
}
return characterList.stream();
}输出:
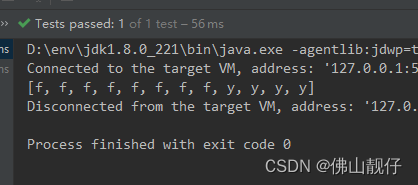
九、mapToxxx
作用:类型转换
@Test
public void mapToXxx() {
// 提取出 students 集合的 age 属性并转换成 Long 类型
List<Student> students = new ArrayList<>();
students.add(new Student(1, 18, "xxxx"));
students.add(new Student(1, 18, "yyyy"));
List<Long> mapToLongStudents = students.stream().mapToLong(Student::getAge).boxed().collect(Collectors.toList());
System.out.println("mapToLongStudents = " + mapToLongStudents);
}
@Data
class Student{
private Integer id;
private Integer age;
private String name;
public Student(int id, int age){
this.id = id;
this.age = age;
}
public Student(int id, int age, String name){
this.id = id;
this.age = age;
this.name = name;
}
}输出:
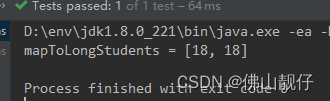
说明:boxed()是对long进行包装Long
十、sorted
作用:顾名思义是用于数据流中对数据进行排序
@Test
public void sorted() {
// 默认排序
List<Integer> ints = new ArrayList<>();
ints.add(3);
ints.add(2);
ints.add(1);
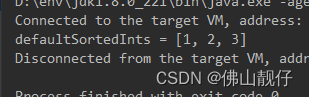
List<Integer> defaultSortedInts = ints.stream().sorted().collect(Collectors.toList());
System.out.println("defaultSortedInts = " + defaultSortedInts);
}输出:
十一、anyMatch
作用:检查集合中是否至少匹配一个元素,返回boolean类型
@Test
public void anyMatch() {
// 检查集合 strings 中是否有包含 bc 的元素
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyybc");
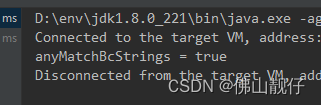
boolean anyMatchBcStrings = strings.stream().anyMatch(s -> s.contains("bc"));
System.out.println("anyMatchBcStrings = " + anyMatchBcStrings);
}输出:
十二、allMatch
作用:检查集合中是否匹配所有的元素,返回boolean类型
@Test
public void allMatch() {
// 检查集合中的元素是否都大于 0
List<Integer> ints = new ArrayList<>();
ints.add(3);
ints.add(2);
ints.add(1);
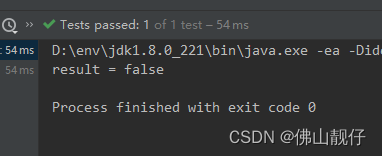
boolean result = ints.stream().allMatch(s -> s>0);
System.out.println("result = " + result);
}输出:

十三、noneMatch
作用:检查集合中是否没有匹配到所有的元素,返回boolean
@Test
public void noneMatch() {
// 检查集合中的元素长度是否都不大于 5
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyybc");
boolean result = strings.stream().noneMatch(s -> s.length()<5);
System.out.println("result = " + result);
}输出:
十四、findAny
作用:返回数据流中任意元素
@Test
public void findAny() {
List<String> strings = new ArrayList<>();
strings.add("ffff");
strings.add("ffff");
strings.add("yyyybc");
Optional<String> any = strings.stream().findAny();
// 获取一下值,如果是 串行的流 默认会返回集合中的第一个(效率快)
//if (any.isPresent()) System.out.println(any.get());
any.ifPresent(System.out::println);
Optional<String> any1 = strings.parallelStream().findAny();
// 获取一下值,如果是 并行的流 集合里的元素都有可能拿得到
any1.ifPresent(System.out::println);
}输出:
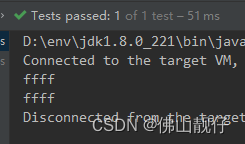
十五、findFirst
作用:将返回集合中的第一个元素
@Test
public void findFirst() {
List<String> strings = new ArrayList<>();
strings.add("ffff11");
strings.add("ffff");
strings.add("yyyybc");
Optional<String> first = strings.stream().findFirst();
first.ifPresent(System.out::println);
}输出:
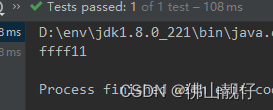
十六、reduce
作用:可以将流元素反复结合起来,得到一个值
@Test
public void reduce() {
/**
* acc:初始化值,默认为 null
* item:集合中的元素
*/
List<String> strings = new ArrayList<>();
strings.add("ffff11");
strings.add("ffff");
strings.add("yyyybc");
Optional<String> reduce = strings.stream().reduce((acc,item) -> {return acc+item;});
//if (reduce.isPresent()) System.out.println(reduce.get());
reduce.ifPresent(System.out::println);
}输出:

十七、count
作用:获取集合中元素的数量
@Test
public void count() {
// 查看 strings 集合中有多少元素
List<String> strings = new ArrayList<>();
strings.add("ffff11");
strings.add("ffff");
strings.add("yyyybc");
long count = strings.stream().count();
System.out.println("count = " + count);
}输出:
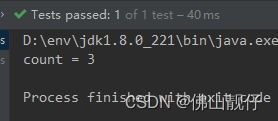
十八、peek
作用:接收一个没有返回值的λ表达式,可以做一些输出,外部处理等
@Test
public void peek() {
//
Map<String, Integer> data = new HashMap<>();
data.put("score", 1);
List<Map<String, Integer>> dataMap = new ArrayList<>();
dataMap.add(data);
List<Map<String, Integer>> result = dataMap.stream().filter(item -> item.containsKey("score")).peek(item -> item.put("score", 2)).collect(Collectors.toList());
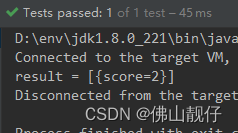
System.out.println("result = " + result);
}输出:
十九、Stream.of
作用:初始化集合;超级好用
@Test
public void streamOf() {
List<String> list = Stream.of("1", "2", "3").collect(Collectors.toList());
System.out.println("list = " + list);
}输出:
总结
以上常用的stream流都总结出来了,实际开发中用到流操作能提高开发效率,也能让代码变得简洁。
感谢大佬的总结:https://edu.csdn.net/job/javabe_01/java-77d7a80503af4222b7fdd0a06d1daf30















 8531
8531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









