






你有没有看过曼波,哈基米,或者懒羊羊,光头强,蜡笔小新的玩梗视频呢?哪这是如何制作的呢?今天就0门槛,从零开始教会你!如何克隆任何人的声音!
认识一下GPT-SoVITS
是一款由B站UP主花儿不哭开发的开源低成本AI音色克隆项目,基于文转音的方式进行音频合成的一个项目。
模型融合:GPT-SoVits通过巧妙融合GPT模型与SoVITS变声器技术,使得用户仅需少量样本数据,即可实现高质量的语音克隆。
深度学习:该软件利用深度学习算法,特别是基于Transformer架构的GPT模型,来学习和模拟目标人物的音色和语调。这种技术能够捕捉到声音的细微差别,从而实现高度逼真的音色克隆效果。

主要功能
音色克隆:GPT-SoVits的核心功能是音色克隆,即通过输入一段目标人物的声音样本,学习并模拟其音色和语调,从而生成具有相同或相似音色的新音频。
跨语种合成:除了中文和英文外,GPT-SoVits还支持韩语、日语、粤语等多种语言的音色合成,满足不同用户的需求。
多音字优化:针对中日英韩粤等五种语言新增了多音字优化功能,进一步提升了合成语音的准确性和自然度。
版本介绍:
花儿不哭大佬已经更新了两个版本,在新的V2版本上有了很多的改进,大家可以看看我的分析然后自行进行选择使用即可:
| GPT-SoVITS V1 | GPT-SoVITS V2 | |
| 主要功能 | - 由参考音频的情感、音色、语速控制合成音频的情感、音色、语速 | - 继承V1的主要功能,并新增多项改进 |
| - 可以少量语音微调训练,也可不训练直接推理 | - 对低音质参考音频合成出来音质更好 | |
| - 可以跨语种生成,即参考音频(训练集)和推理文本的语种为不同语种 | - 底模训练集增加到5000小时,zero shot性能更好音色更像,所需数据集更少 | |
| - 增加韩语和粤语的支持,中日英韩粤5个语种均可跨语种合成 | ||
| 技术更新 | - 基于Transformer架构的GPT模型与SoVITS变声器技术融合 | - 将hp2模型替换为model_bs_roformer_ep_317_sdr_12.9755模型 |
| - DeEchoNormal和DeReverb模型,提升去混响效果 | ||
| 性能优化 | - 高效性和灵活性 | - 推理速度大幅提升 |
| - 支持跨语种合成 | ||
| - 更好的文本前端,中英文加入多音字优化 | ||
| 用户体验 | - 用户可以通过简单的操作步骤,即可完成从数据准备到模型训练再到语音生成的整个过程 | - 自动文件路径填充,简化操作流程 |
使用基础
环境准备:分为两类情况,如果你只是需要使用模型进行推理出音频不需要训练模型的情况你可以直接跳过下面的“模型训练”部分直接到模型“推理部分”!并且您不需要参考下面的硬件需求,关于没有训练没有模型怎么办,不要担心我给大家准备了400余个已经训练好的,高质量的各种GPT Sovits模型可以跳转到推理部分进行免费获取!
如果您需要自己训练模型请确保本地电脑满足支持CUDA的NVIDIA显卡,AMD显卡暂时不太能使用本项目,(至少4-6G以上显存,本人亲测4GB 1050ti可以使用该项目)的要求。如果本地电脑不满足条件,可以使用云环境。
温馨提示:
为了确保在使用中避免意外问题,不要翻墙!笔记本电脑不要断电!不要在后面的软件操作中刷新任何页面!!!如果电脑有360,腾讯电脑管家,联想电脑管家等等,请退出不要使用!
使用教程:
【下载本项目】
你需要先下载这个项目,你可以直接在花儿不哭大佬的githob项目中下载。但是由于网络问题,这个过程应该会很痛苦没有关系,我已经为大家下载打包好了。
下载地址:
夸克网盘:
githob地址:
https://github.com/RVC-Boss/GPT-SoVITS![]() https://github.com/RVC-Boss/GPT-SoVITS
https://github.com/RVC-Boss/GPT-SoVITS
在此非常感谢花儿不哭大佬的无私奉献。
【运行本项目】
下载完之后解压项目文件,这里要注意的是,解压的路径不能有中文。解压完毕之后,打开解压的文件夹双击gowebui.bat文件。
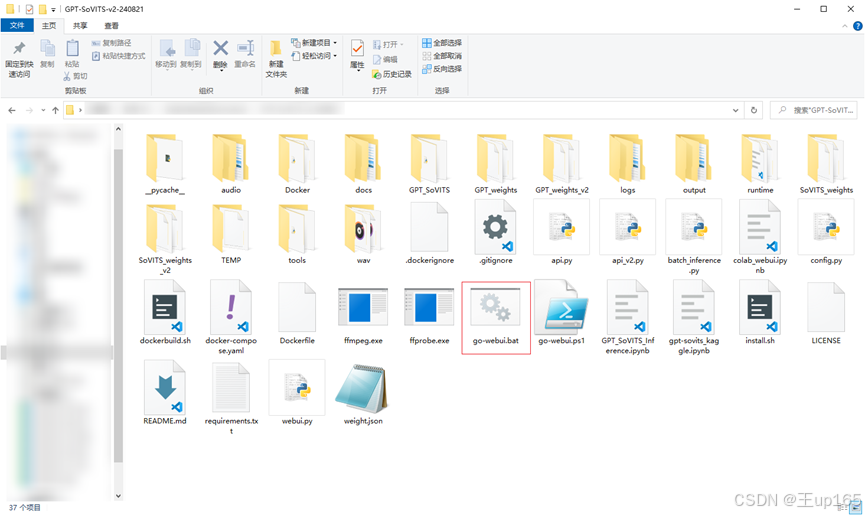
这时会弹出一个黑色的命令行界面,请一定不要关闭它,因为这是软件的本体。等待加载会自动跳转浏览器,这里就是我们的操作界面了。
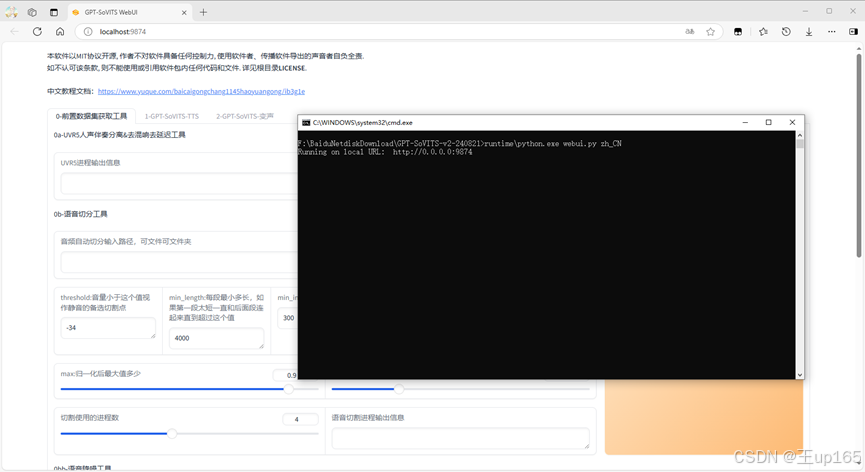
同样在这个界面,请不要使用右键刷新任何界面。在我们克隆声音之前,我们要了解GPTSovits一共分为两种训练模式:
快速克隆:我们只需要准备一段简短的声音,进行克隆但是缺点显而易见,由于训练集太小。出来的效果也质量非常差,非常不推荐。
克隆模型:需要准备好训练的素材,准备素材前一定要注意:1.素材时长最好不要小于3-5分钟,且不能有多的杂音。2.如果有背景音乐的话,背景音乐不能盖过说话的人声。3.整段音频内说话的语气,最好是有情绪起伏,如果一直是平静或者一种的语气,那出来的模型也是一种语气。
【训练素材准备】
素材可以在网上下载素材,然后丢到au里面,进行音频的裁剪将无关内容减去并调整音频,完成后记得保存为wav格式。如果你只是想克隆自己的声音,直接用AU或者其他录音软件录制即可,到这一步,恭喜你就已经完成了训练ai最重要的一步,准备素材。
【训练音频预处理】
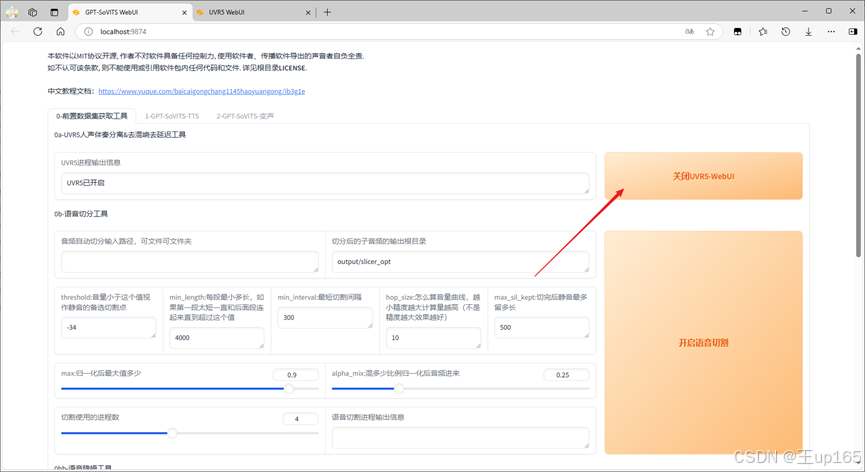
我们回到刚刚的软件界面,点击第1个标签页面的,最上面的按钮开启uvr5。开启后同样会跳转新的标签页,这一步的目的是将你刚下载的音频素材进行降噪背景音乐和人声的分离避免训练出来的模型出现问题。
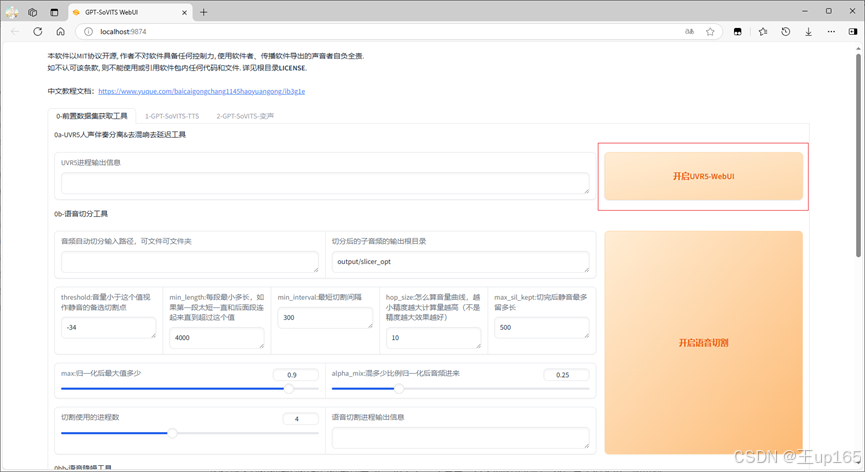
首先输入音频文件夹的路径,这里建议大家直接在项目的文件夹里面创建一个文件夹,然后将我们刚刚准备好的音频复制进文件夹,然后再将这个文件路径粘贴到这里。
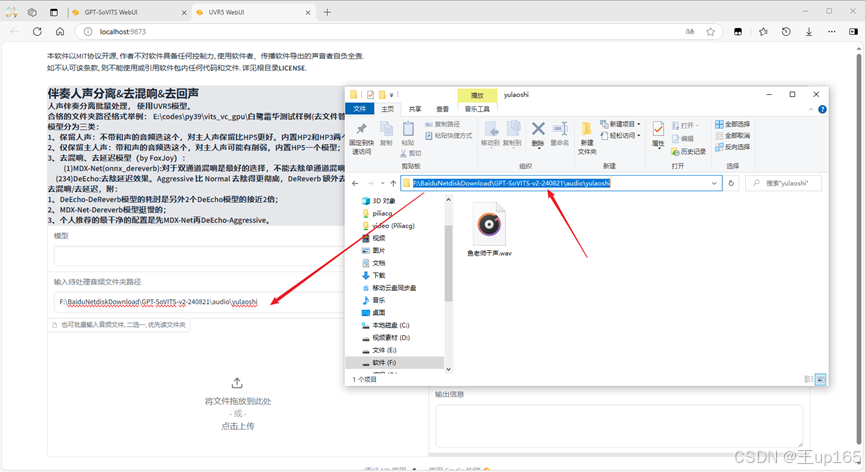
在模型选项中,我们选择HP2,这是一个人声分离模型可以很好的分离伴奏和人声,这里如果你的电脑性能比较好的话可以使用HP5,可能会获得更好的效果,记得切换导出格式为wav。
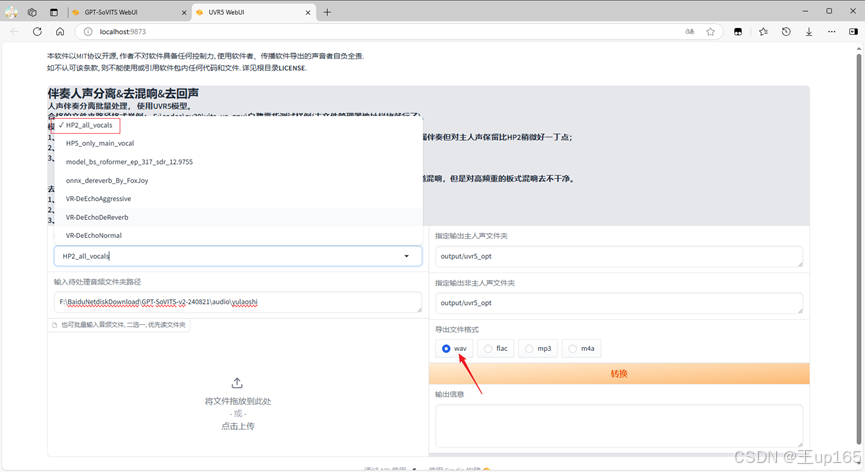
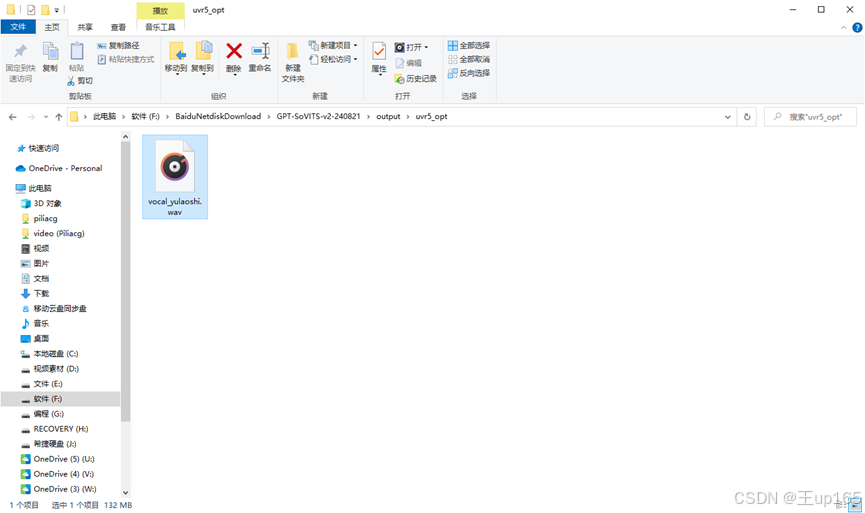
完成后点击转换,这时我们可以切换到cmd命令行可以查看进度转化完毕之后,我们回到项目文件夹进入output文件里面会有一个uvr5opt,进入后我们只保留vocal开头的这个文件其他的删除完成后我们回到uvr5的界面。
这里记住将待处理的音频文件夹路径进行更改,更改为刚刚的uvropt文件夹路径然后在模型中选择foxjoy这个模型再次进行处理这个步骤的目的是为了去除混响和延迟,完成之后同样会生成多个文件。
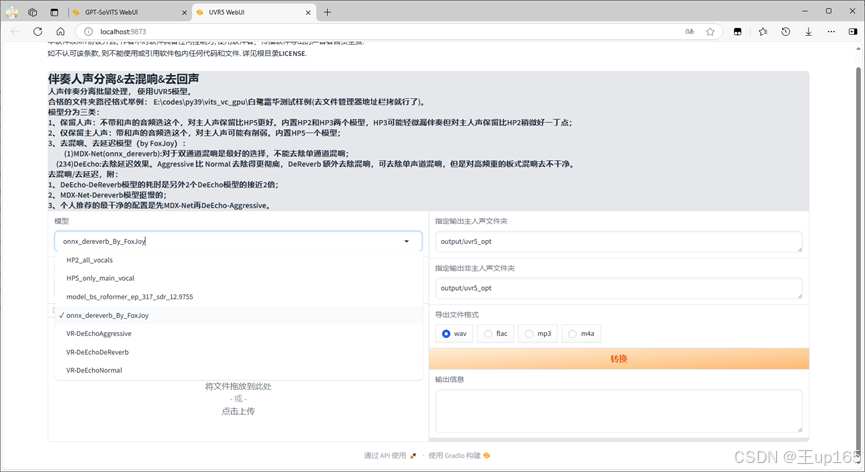
我看到会有带有vocal-vocal文件,只保留这个文件其他的全部删除,这个时候你可以听一下这个文件,如果你觉得满意了就可以进行下一步。如果还是有部分噪音的话我们需要对它进行二次降噪,如果需要进行二次降噪路径不更改选择vr尾缀为sive的模型进行转换两次。
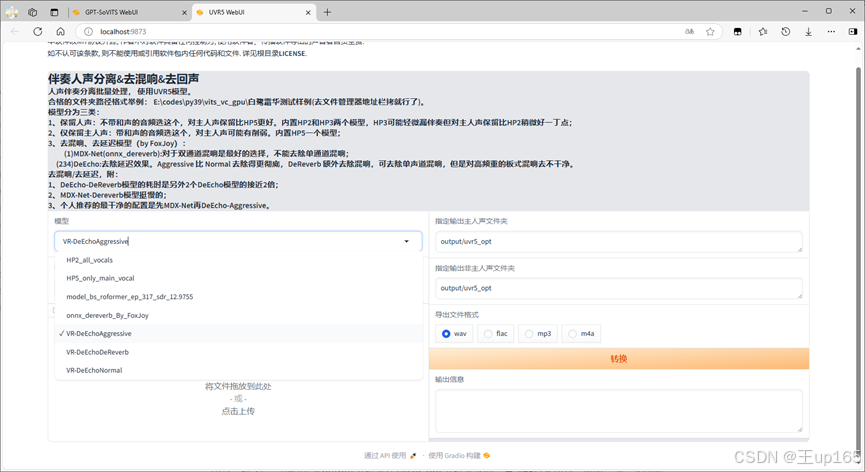
记得每次转换都会生成两个音频,只保留最新生成的vocal文件即可完成这一步操作,我们的音频文件已经非常的干净了。操作完成,记得关闭uvr5。
第2步我们进行音频切割,这一步的目的是为了方便ai学习和打标标注,说人话就是把一段五六分钟的声音切成一段一段几秒钟的音频,这里我们粘贴刚刚的uvr5路径对于下面的参数新手用户,我只介绍两个参数:第一个就是音频小于这个值视为静音的备选切割点,这个值可以适当调小如果你的音频声音比较小。
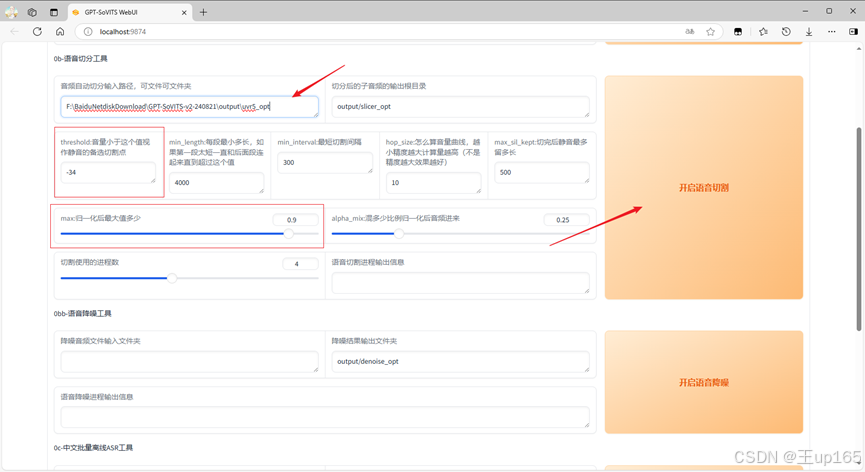
的话就不建议调整建议可以调整成负25~30左右,还有第二个下面的选项归一化后最大值多少,如果你的电脑性能不好那建议可以给他调到6,这样子它的切分音频就会越短对于机能不是很好的电脑就会友好很多,在后续操作时不会爆显存。这一步很重要不然很可能导致后续操作前功尽弃完成后点击开始音频切割按钮。
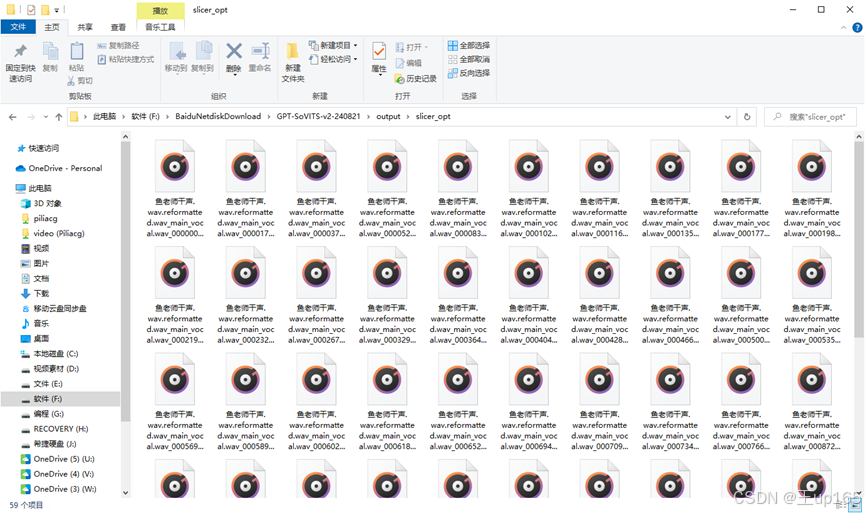
切割完毕之后,我们进到output文件夹在slicer_opt文件夹下面会看到非常多切割完成的音频,下面的步骤有一部叫做语音降噪。因为我们uvr5已经做过音频的降噪处理,这一步我们就可以跳过。
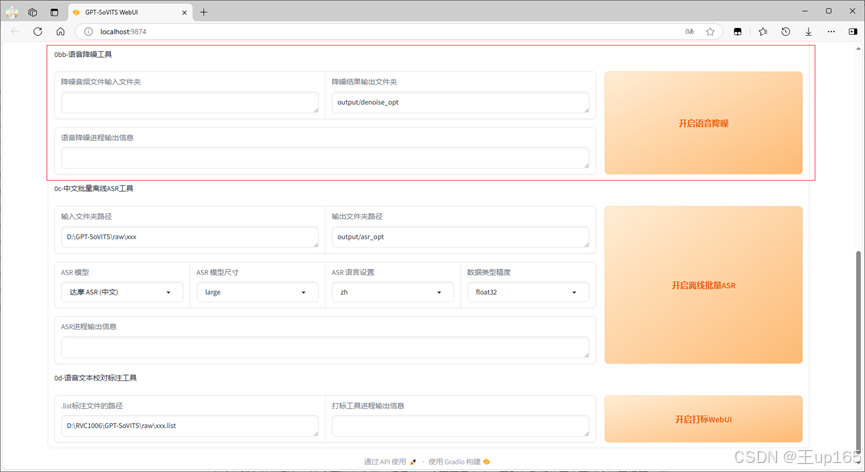
这里有一个输入文件夹路径,填写一下我们刚刚打开的slicer_opt文件夹路径,下面选项中有一个ASR模型选项。
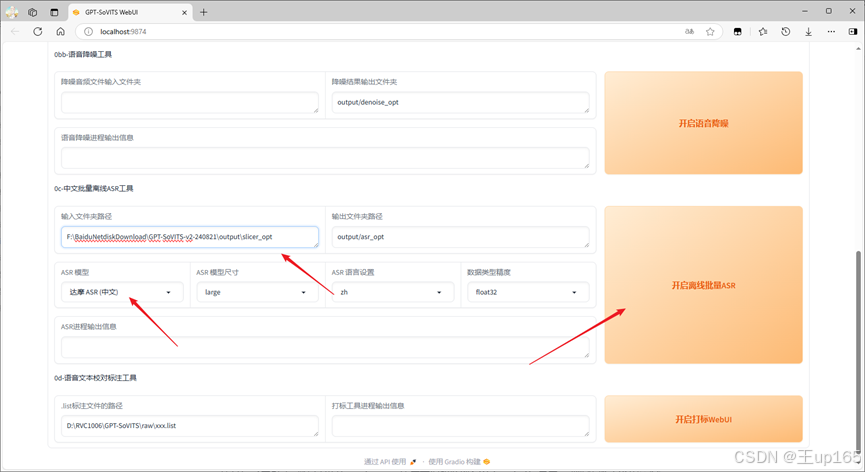
这里只需要做一个切换,如果你训练的是中文语音模型那请切到达摩ASR如果是其他语言,例如日语英语请切换到多语种选项,切换完毕之后,点击开始离线批量asr。
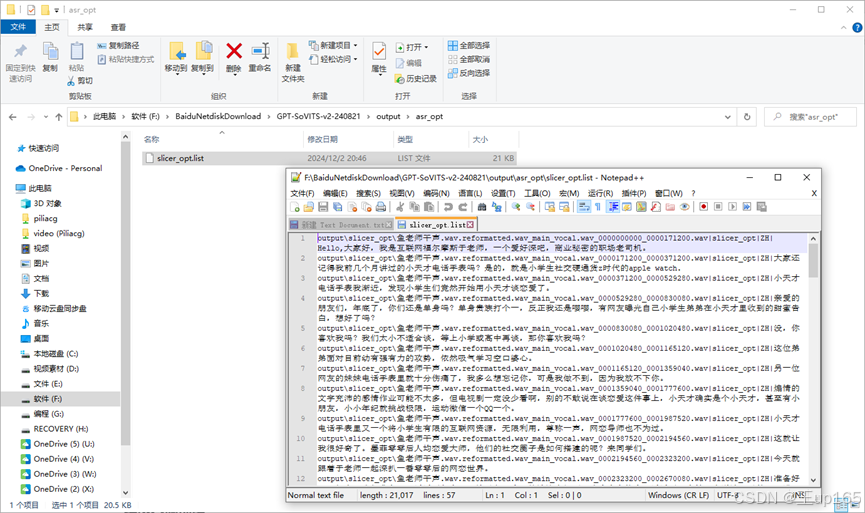
等待命令行结束,结束完毕之后,我们回到项目文件夹在asr_opt文件夹中可以看到一个打标文件。
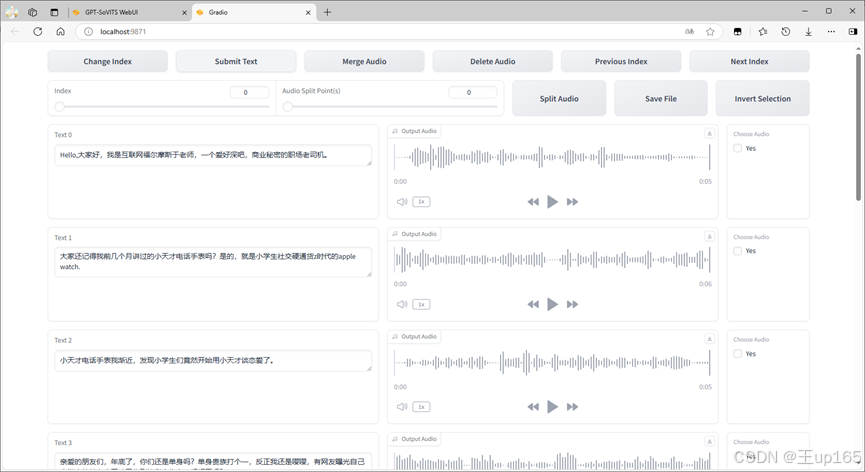
你可以通过下载文本编辑工具,进行直接打标修改这个是我比较推荐的方法,或者也可以直接使用模型自带的打标工具点击打开打标webui同样会跳转新的标签页。
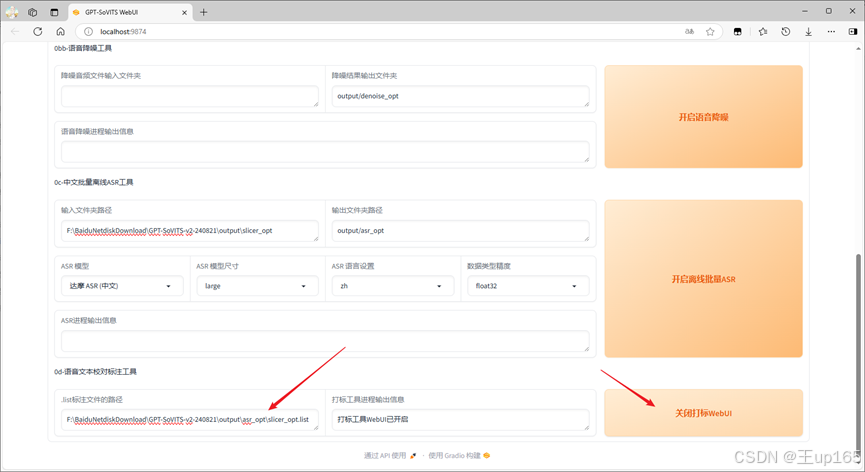
在这里我们可以边预览音频边去修改对应的文字台本,如果发现有错误的字,请修正。默认一个打标页面只显示10个你可以点击右上角的next index,进行页面的切换完成后一定要记得点击sava flie保存,如果你在听音频的时候,发现音频中有bgm或者质量不佳的点击右侧的yes勾选,再点击delete audio删除这个打标片段即可。
【训练集格式化】
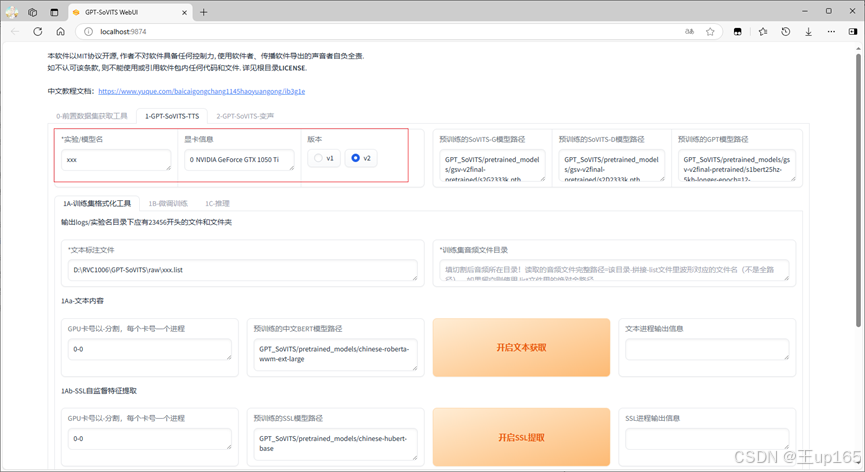
完成打标之后也请记得关闭打标webui。完成后我们切换到GPT Sovits tts页面,训练集格式化在第1行中输入我们的模型名,这个可以自定义,但是请一定不要用中文,否则在后期使用中可能会出现问题。模型名的右边会看到有显卡信息这是你现在在使用的显卡,侧边是现在的合成版本。请不要进行调整,使用v2即可。
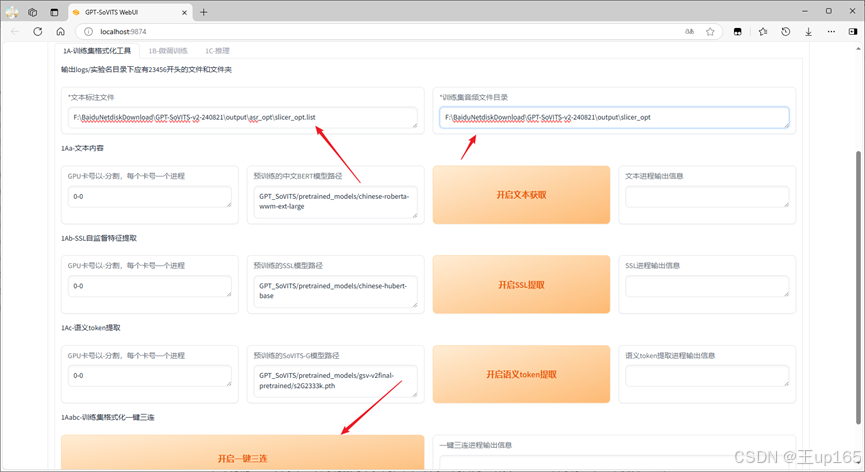
在下面的训练及格式化工具中,有一个文件标注路径,也就是我们的打标文件路径。我们将路径粘贴到这里然后点击下方的开启一键三连,完成数据集处理。
【模型微调训练】
我们观察到界面提示已完成,Cmd命令行也停止运行再切换到左侧的微调训练选项卡模型训练,在这里面我们可以看到有两个训练一个是Sovits,一个是GPT。
这两个模型是相辅相成的都需要完成训练。如果其中一个训练失败那么都无法使用。
这里特别要提到的几个选项是,在每张显卡的 Size选项中如果你的显卡性能不好或者是显存6G以下,请将这个值调为1或者2,这一步是为了降低每一次训练的工作量。
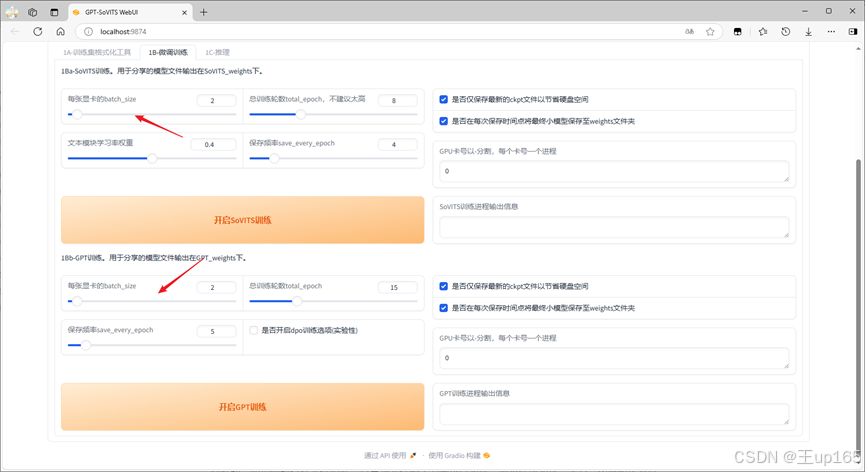
避免因为爆显存导致训练失败用时间换效果,在训练轮数中第1个sovits训练时建议不要调整的太高。调高了也没有任何意义建议默认8或者10。
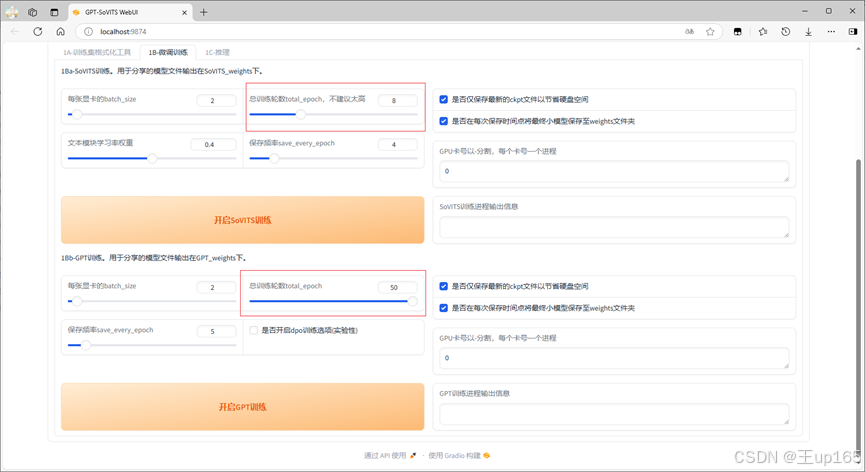
在下方的GPT训练中总训练轮数可以拉高,但是训练时间会同比增长。sovits训练有一个文本模块学习率权重,如果你的打标文件没有任何问题。你可以适当的提高这个权重值。如果你的打标比较混乱,请使用默认参数。
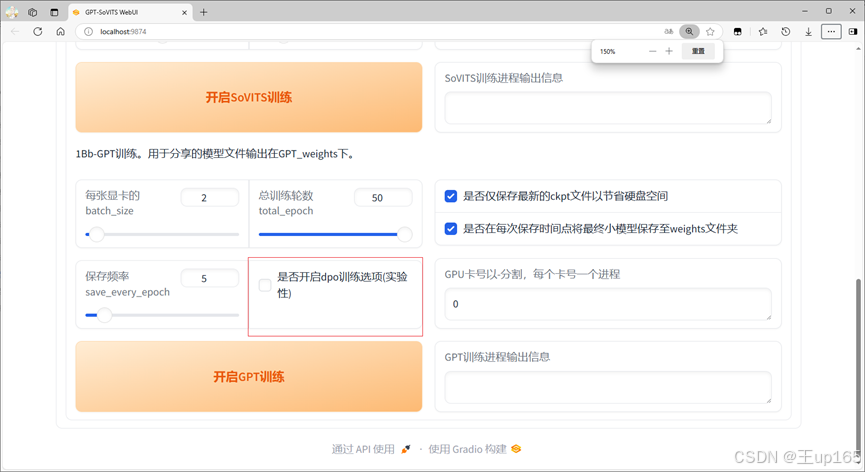
在这里特别要说明的是GPT训练有一个dpo训练选项这个选项可以一定程度,提高模型的训练质量,同样的,如果你的打标文件精准,且音频文件咬字清晰可以勾选否则不建议勾选,尤其是电脑机能不好的,请直接忽略上面的说明一定不能勾选!
调整完参数之后,可以按顺序进行训练。此过程比较长,可以及时的关注cmd的运行状态,如果出现报错请检查你的调参,如果调整后无效,请跳转到本视频的音频切割教程部分进行重新切割。
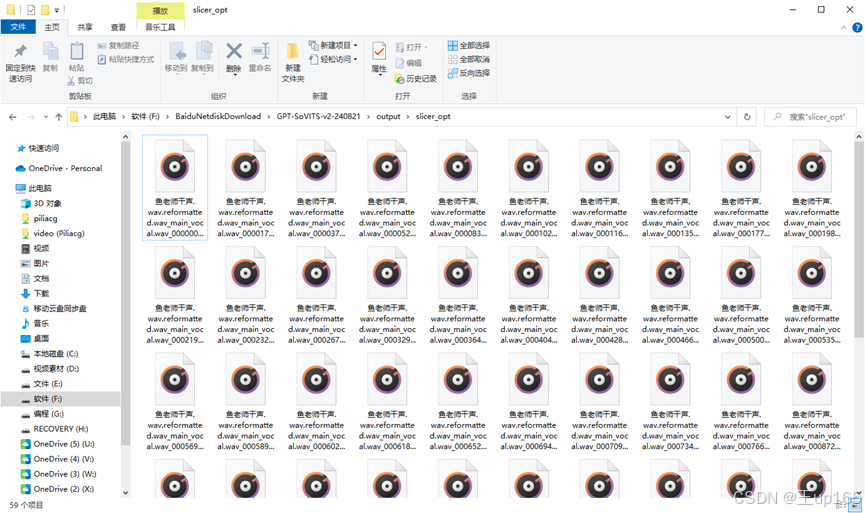
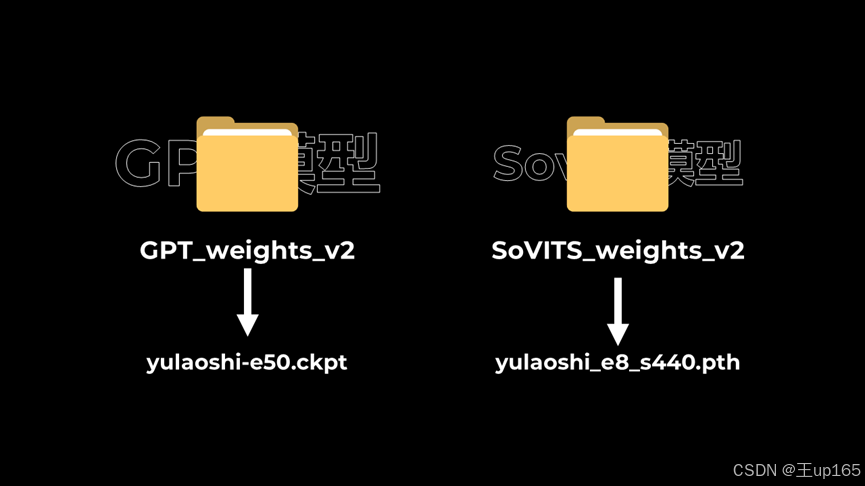
降低切割的归一化后最大值重新切割前请回到slicer_opt文件夹。删除里面的所有音频并进入asr opt文件夹,删除打标文件重新操作之前的步骤,并进行合理的调参重新训练GPT和sovits模型,如果没有任何报错,那么你会看到输出的训练信息均提示完成。在项目文件中进入根目录,在GPT_weights v2和sovits_wenights v2文件夹中看到已经训练完成的模型。
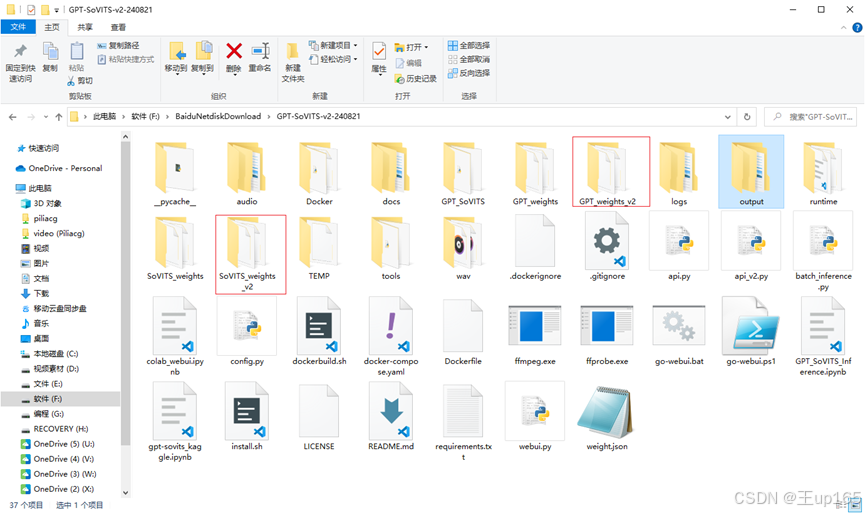
GPT模型是ckpt后缀的,Sovits模型是pth后缀的文件中前面是模型的名称,中间的e后面跟的数字是训练的轮数,S后面跟的数字代表训练的步数。

一个模型会有四五个类似文件,可以在后面步骤中使用推理工具,尝试每一个模型的质量之后进行择优留下如果完成这步,那么恭喜你你已经训练完成模型了。

【建立参考音频】
最后一步就是将我们的训练集音频导出,建立参考音频,打开项目文件夹中的切分音频文件路径slicer_opt文件夹里面有很多我们已经切割好的音频。这里去挑选5~6个5秒以上,10秒以内质量比较好的声音片段。

什么是好的音频片段呢?一种情绪的起伏可以保留一个且音频片段不能有杂音,新建一个参考音频文件夹进行保存然后听音频的内容台本,记录下内容关闭音频之后将内容台本命名成为音频的名称,就可以愉快的使用了
【模型推理使用】
切换到推理选项卡,点击开启tts推理webui按钮。同样会跳转出新的浏览器页面,如果你的电脑性能不好,这个过程需要等待一下。
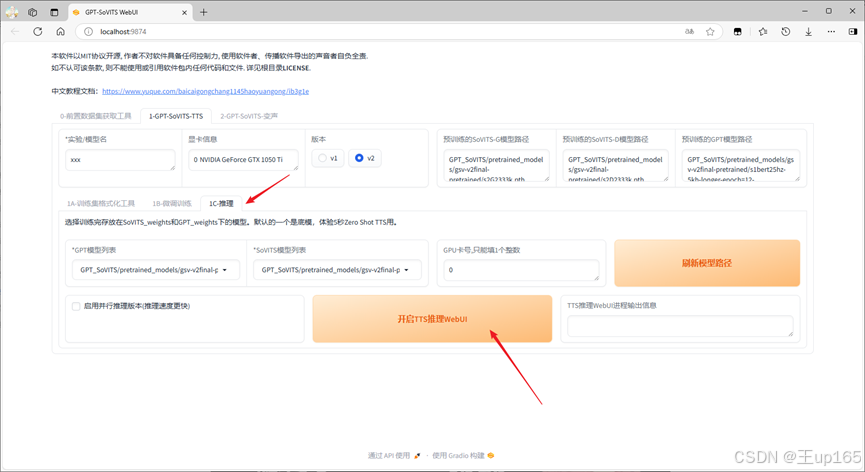
进入页面之后,在模型列表中可以切换成你刚刚训练的模型,两个模型列表中都要选择,互对应的模型如果发现模型列表中没有你的模型文件。
【免费模型赠送】
说到没有模型,那就要推荐我们的!!
哈哈哈,没有广告是送大家我已经训练和整理好的成套模型文件啦,有很多大家耳熟能详的模型。
你们的傻不拉几曼波!还有哈你个牛魔啊哈尼米!

还有原神、崩铁、崩坏3、星穹铁道、绝区零、碧蓝档案等游戏的各种角色!
原神(全角色)
当然哥哥我和一些抽象网红也是有的哦!

应该是有400个各种模型吧,免费,分享给大家!
下载已训练好的《GPT SOVITS V1-V2模型》模型:
云雀文档:GPT SOVITS V1-V2模型 · 语雀![]() https://www.yuque.com/u32697029/cuxkbi/fwmmn48117usnnqg?singleDoc#a0b3
https://www.yuque.com/u32697029/cuxkbi/fwmmn48117usnnqg?singleDoc#a0b3
金山文档:https://kdocs.cn/l/cu3RYX5iuFHw![]() https://kdocs.cn/l/cu3RYX5iuFHw
https://kdocs.cn/l/cu3RYX5iuFHw
叠个甲,模型仅供学习,使用前一定要遵守法律法规造成任何法律问题均由使用者承担!
废话不多说来啦啊。先教大家导入模型文件。你只需要把模型中两个文件,拷贝到对应的项目文件夹,参考音频建立一个文件夹另外存放。

然后再点击刷新模型列表按钮点击上传我们刚刚的参考音频。你可以像我一样在每个音频前面都标注上这个音频的情绪。那么生成的音频也会带有这个情绪。点击上传的过程中可以直接复制参考音频的台本,粘贴到参考音频文本输入框。
完成后即可在需要合成的文本中输入你需要合成的内容,在合成文本的右侧,有几个选项,这里要说明一下,语言根据你的模型进行切换这里的怎么切?有很多种模式本质上就是如何断句。
下面选项新手用户,建议只需要调整语速然后点击合成语音,我们可以观察cmd的命令行运行状态等输出完毕停止之后在输出语音中,就能够直接预览我们合成的音频。就可以直接点击右上角的下载,进行使用。
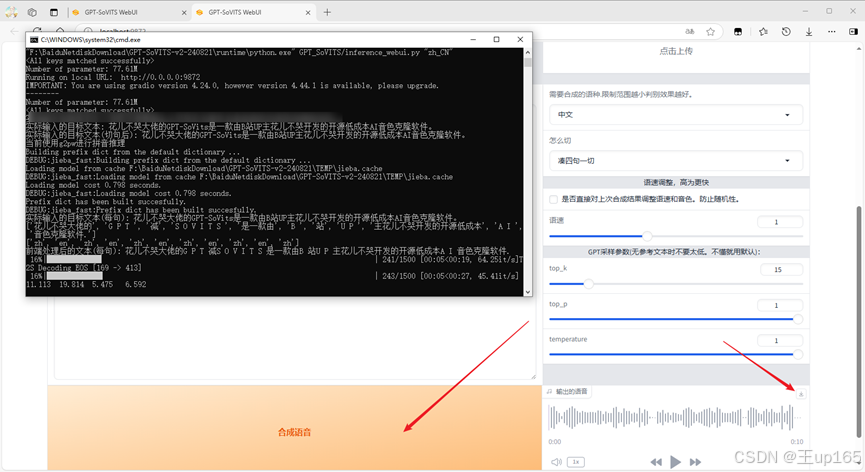
这里值得注意的是如果合成失败或者二次合成的音频,还是之前合成的内容。请检查cmd的命令行是否有报错?或者减少需要合成的文本长度。
这篇文章给大家详细的介绍GPTsovits个操作的逻辑,还有一些具体参数的调整更多的调优,还需要大家自己去学习探索。

















 3781
3781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









