







分布式系统原理系列目录
所谓分布式系统顾名思义就是利用多台计算机协同解决单台计算机所不能解决的计算、存储等问题,这个大家都明白 分布式系统解决了单机无法解决的问题,但是也引入了一些问题、或者说在建设分布式系统时,会有一些麻烦
网络异常
相比使用单台计算机完成任务,使用多台计算机协调完成任务有本质区别,单机上的程序完全运行在计算机内部,你调用一个函数,结果要么成功、要么失败,不会有其他结果。但在分布式系统中,多节点协调的唯一途径就是网络,网络是要经过现实世界的,现实世界什么都可能会发生
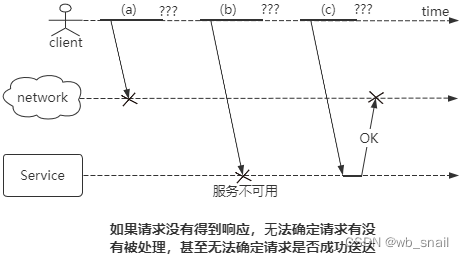
如上图,如果客户端远程调用服务端,并等待响应,这个过程就可能发生各种问题
1. 比如有⼈拔掉了⽹线,请求丢失
2. 比如网络拥塞,请求一直在某个交换机上排队
3. 远程节点不可用
4. 远程节点已经处理了请求,但是回复的响应丢失了、或者延迟了
发生这些问题后,对发送端来说,他唯一知道的就是他还没拿到响应,至于对端到底有没有处理成功是没法确定的,甚至连请求有没有送到对端都无法确定。这个就是三态问题,成功、失败、不知道成功或者失败
对于这种情况,唯一有效的办法就是超时机制了,client等一段时间后放弃等待(然后考虑要不要重试),否则线程一直hung在那里,hung的线程越来越多,系统也越来越慢,最终可能被拖垮。但是超时机制也只是为了容错,为了保护自己不被拖累,并没有实际解决三态问题,所以我们说三态是个麻烦的问题
部分失效
组成整个分布式系统的各类硬件都可能会出现不可预知的故障,比如最常见的机器宕机、还有交换机损坏、机架电源短路、甚至机房级别的比如机房火灾。这些问题中的任意一个都可能会导致系统的某些部分被破坏,这被称为部分失效(partial failure)。部分失效是不确定的,你永远不知道下一秒哪里会发生问题,尤其是机器宕机,有人统计过,大型机房每日发生宕机的概率为千分之一的级别,挺高的一个概率了
不管是部分失效、还是网络异常,都表明分布式系统中存在一些不可靠因素,而且这些不可靠还很难避免。在设计分布式系统时,不可能说因为这些事情发生的概率低,就不考虑了,对吧,我们必须面对这些问题,不然可能就要面对领导
分布式系统的一个非常重要的初衷就是要用不可靠的组件构成可靠的系统,这点非常关键。单机是不可靠的,硬件设备是不可靠的、网络是不可靠的,但是基于这些东西构建的系统得是可靠的。 也就是说,要充分考虑容错。咱们的微服务要考虑容错、咱们用的那些基础设施也要考虑容错、很多分布式算法也要考虑容错。在分布式系统中怎么强调容错都不过分
不可靠时钟
很多事情的正确性依是赖于时钟的,或者说依赖于顺序的。比如锁竞争,先来的先抢到,后来的就得排队。再比如更新数据,肯定是以最后的更新为准 所以确定先后顺序很关键,在单机上这件事情很简单,因为单机上的时钟就一个。但是在分布式系统中,这个事情就比较麻烦了,具体体现在下面两点:

第一个还是跟网络有关,多节点通信时,由于⽹络中的延迟是不确定的,有时候就没办法确定事情发生的顺序。如上图,NodeA和NodeB通过网络同步数据,每次NodeA写入成功后,都会发送一条同步消息给NodeB,NodeA先后收到write k=1、write k=2的请求,也先后向NodeB发送了同步k=1和k=2的消息,但是NodeB却先收到同步k=2的消息,因为网络延迟是不确定的,导致了NodeA上的顺序不一定等于NodeB上的顺序
好,再看第二点:每台机器都有自己的时钟,时钟通常是⽯英晶体振荡器,这东西是硬件设备,硬件时钟必然没法做到百分百精确,可能会变快变慢,所以每台机器上的时间可能有误差,这也有可能导致比较麻烦的事情,如下图,这是个多主的存储系统,两个node都接收读写请求,并且双向同步,像这种多节点写数据的架构,可能会存在写冲突的问题,就是说两个节点都写了同一条数据,而且写值不同 ,当数据同步时,发现冲突,解决写冲突的一个方案是:最后写 ⼊胜利(LWW, last write wins),下图的系统用的就是这个方案(有一些去中心化的数据库也是这种方案,比如cassendra)

这个例子里ClientA先发送了个write k=1的请求到Node1上,Node1此刻的时间是30.005(毫秒),写入完成后发送一条同步消息到NodeB,这条消息会带上Node1的时间戳。在ClientA的写入完成之后,ClientB发送了一个write k=2的请求到Node2上,注意这里的在ClientA完成之后指的是现实世界的之后哦。但是Node2上的时钟比Node1上早了那么几毫秒,在Node2上收到写入的时间是30.002,这个时候因为发生写入冲突了,要以后写入的为准,也就是以x=1为准,因为它上面的时间是30.005,x=2就被放弃了,但是实际上它是后写入的
这两个问题一个是因为网络延迟的不确定性,一个是因为硬件时钟有误差,但本质上都是一个问题,就是缺乏全局时钟
真理由谁定义
上面说的机器故障、网络异常、部分失效及时钟不可靠等问题,在分布式系统里面我们得意识到这些问题的存在,否则它们可能会发生一些让你很迷惑的问题
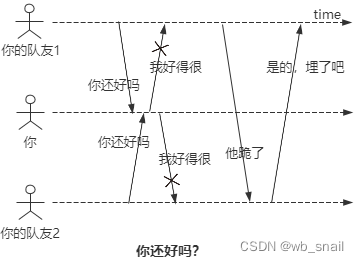
例一(如上图):你和你的两个队友组成了一个3节点的集群,你们通过心跳包确认对方是否健在,某段时间内,出现了一种不对称的网络故障,你可以收到两个队友的消息,但是你给他们的消息它们收不到。他们问"你还好吗",你说"我好得很",但是他们都收不到你的回复,一致认为你跪了,准备把你埋了。这就很尴尬了,他们认为你跪了,你认为我tm不是好好的吗,为什么会有这种问题?就是因为你们只能通过网络来确认对方是否正常,而网络是不可靠的。 那真相是什么,你到底跪没跪?
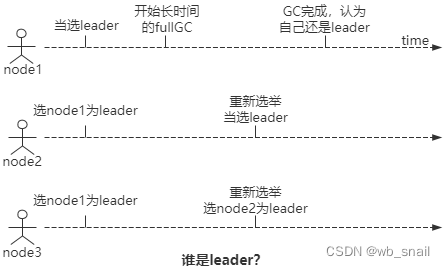
例二(如上图):一个3节点的中心化集群,集群初始化时节点1被选为leader,系统运行一段时间后,节点1进入长时间的full GC(卡死了)。在此期间,node2/node3发送到node1的心跳包没法得到回复,node2/3一致认为node1挂了,重新发起选举,最后node2当选为新leader。又运行一段时间后,node1 GC完成,能正常工作了,这时候他还认为自己是leader,他甚至不知道时间已经过了很久了,然而其他节点并不这样认为。那真相是什么,到底谁是leader?
面对这类”谁说了算”或者”真相是什么”的问题,许多算法采用的都是“少数服从多数”的原则,一旦超过半数的节点同意一个决策,那就认为决策通过。这样做有哪些好处呢?
第一个很明显,因为少数服从多数,上面这两个问题都有了答案:第一张图的真相是你确实跪了,不接受反驳,第二张图node2是leader。 简而言之就是你一个人认为这样没用,必须法定人数的人同意的那才行,大家都说你跪了,那就是官宣,那你就是跪了
第二个好处是不要求所有节点同意这个决策,只要过半节点同意就OK,这样就可以容忍少数的节点发生前面说的不可靠的问题(比如网络分区啊、宕机啊这种问题),那这样系统的可用性就提高了,而且可以通过增加机器数量来提升系统整体的可用性。 3个节点的系统允许1个节点故障,5个节点的系统就允许2个节点故障,节点数越多可以容忍的故障节点数也就越多
前面一直提到的” 刚好过半”这个要求称为法定人数(quorum),法定人数可以不是刚好过半,但通常都是这样。为什么是刚好过半,刚好过半有什么特殊意义呢?这体现在下面两个方面:
1.系统做决策时,必然不会同时产生两个不同的决策,因为系统不会同时出现两个不同的过半节点集,这点非常关键,比如系统要选出个leader,最终只可能有一node当选,而不可能是两个,不然就乱套了。就像下面这张图里,5个节点的集群分成两组,只有一个组会超过半数,这个道理很简单

2.两组过半节点必有交集,啥意思呢?我们拿一个5节点的集群来举例,如果每次写入时要求数据同步到至少3个节点,那我任选3个节点,这3个节点中至少有1个节点在前面那同步了最新数据的3个节点中,这是一个有力的保证。比如系统运行一段时间后,leader挂了,剩余节点会重新选举,一个节点能被选为leader的一个条件是,他拥有最新数据,否则就会有数据丢失,选举时要求至少3个节点达成一致,最终这达成一致的3个节点里至少有1个节点含有最新数据

像上面这张图里,假如一开始node1是leader,一条数据同步到node1/2/3上后,node1挂了,然后重新选举时要求至少3个节点同意才能当选,在node2/3/4/5中任选三个节点,至少有一个节点上面是有最新数据的,对不对。这样才能保证数据不丢失。同样道理哦,如果数据同步写入到3个节点算成功,数据读取时,只要也是读取3个节点,那一定能读到最新数据
Quorum机制在我们后面要说的分布式共识算法中意义比较重大,这里先有个印象,后面再看看它是怎么应用















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









