







1 堆
1.1 简介
n个关键字序列Kl,K2,…,Kn称为(Heap),当且仅当该序列满足如下性质(简称为堆性质):
(1)ki<=k(2i)且ki<=k(2i+1)(1≤i≤ n),当然,这是小根堆,大根堆则换成>=号。//k(i)相当于二叉树的非叶结点,K(2i)则是左孩子,k(2i+1)是右孩子
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:
树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
1.2 堆的高度
堆可以被看成是一棵树,结点在堆中的高度可以被定义为从本结点到叶子结点的最长简单下降路径上边的数目;定义堆的高度为树根的高度。我们将看到,堆结构上的一些基本操作的运行时间至多是与树的高度成正比,为O(lgn)。
1.3 堆排序
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
① 先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
② 再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
③由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作:
① 初始化操作:将R[1..n]构造为初始堆;
② 每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意:
①只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
②用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。堆排序和直接选择排序相反:在任何时刻堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往
1.4 算法分析
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用Heapify实现的。
堆排序的最坏时间复杂度为O(nlogn)。堆序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1),
它是不稳定的排序方法。
1.5 算法实现
要将初始文件R[l..n]调整为一个大根堆,就必须将它所对应的完全二叉树中以每一结点为根的子树都调整为堆。
显然只有一个结点的树是堆,而在完全二叉树中,所有序号大于n/2的结点都是叶子,因此以这些结点为根的子树均已是堆。这样,我们只需依次将以序号为n/2,…,1的结点作为根的子树都调整为堆即可。
- #include <iostream>
- using namespace std;
- const int MAX = 100;
- typedef struct SQLIST
- {
- int r[MAX];
- int length;
- }SqList;
- typedef SqList HeapType;
- void HeapAdjust(HeapType &H, int s, int m)
- {
- //已知H.r[s..m]记录的关键字除H.r[s]之外均满足堆的定义,本函数调整H.r[s]
- //的关键字,使H.r[s..m]成为一个小顶堆(对其中记录的关键字而言)
- int rc = H.r[s];
- for (int j = 2 * s; j <= m; j *= 2)//沿着值较大的孩子节点向下筛选
- {
- if (j < m && H.r[j] < H.r[j+1])
- {
- ++ j;//j为值较大的记录的下标
- }
- if (rc >= H.r[j])
- {
- break;//rc应插入在位置s上
- }
- H.r[s] = H.r[j];
- s = j;
- }
- H.r[s] = rc;//插入
- }
- void HeapSort(HeapType &H)
- {
- //对顺序表H进行堆排序
- for (int i = H.length / 2; i > 0; -- i)//把H.r[1..H.length]建成堆,这里是为了让每个节点都是堆,因为大于n/2的点都是叶子节点,已是堆
- {
- HeapAdjust(H,i,H.length);
- }
- for (int i = H.length; i > 1; -- i)
- {
- int tmp = H.r[1];//将堆顶记录和当前未经排序子序列H.r[1..i]中最后一个记录相互交换
- H.r[1] = H.r[i];
- H.r[i] = tmp;
- HeapAdjust(H, 1, i -1);//将H.r[1..i-1]重新调整为堆
- }
- }
- int main()
- {
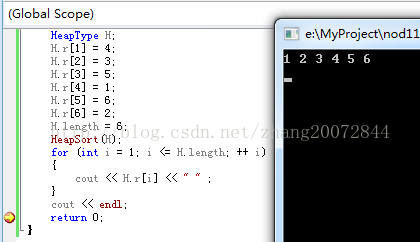
- HeapType H;
- H.r[1] = 4;
- H.r[2] = 3;
- H.r[3] = 5;
- H.r[4] = 1;
- H.r[5] = 6;
- H.r[6] = 2;
- H.length = 6;
- HeapSort(H);
- for (int i = 1; i <= H.length; ++ i)
- {
- cout << H.r[i] << " " ;
- }
- cout << endl;
- return 0;
- }
结果:(小顶堆)
如果将if (j < m && H.r[j] < H.r[j+1])和if (rc >= H.r[j])改为if (j < m && H.r[j] > H.r[j+1])和if (rc <= H.r[j])输出将变为6 5 4 3 2 1(大顶堆)
2 优先队列
2.1 简介
队列的特点是先进先出。通常都把队列比喻成排队买东西,大家都很守秩序,先排队的人就先买东西。但是优先队列有所不同,它不遵循先进先出的规则,而是根据队列中元素的优先权,优先权最大的先被取出。通常把优先队列比喻成现实生活中的打印。一个打印店里有很多打印机,每台机器的性能不一样,有的打印机打印很快,有的打印机打印速度很慢。当这些打印机陆陆续续打印完自己的任务时进入排队等候状态。如果我这个时候要打印一份文件,我选的不是第一个排队的打印机,而是性能最好,打印最快的打印机。
重点:优先级队列,是要看优先级的,谁的优先级更高,谁就先得到权限。不分排队的顺序!
基本操作:
empty() 如果队列为空返回真
pop() 删除对顶元素
push() 加入一个元素
size() 返回优先队列中拥有的元素个数
top() 返回优先队列对顶元素
在默认的优先队列中,优先级高的先出队。在默认的int型中先出队的为较大的数。
2.2 用堆实现优先队列
下面是最小堆实现的优先队列:
- #include <iostream>
- #include <vector>
- using namespace std;
- class Heap
- {
- public:
- Heap(int iSize);
- ~Heap();
- int Enqueue(int iVal);
- int Dequeue(int &iVal);
- int GetMin(int &iVal);
- void printQueue();
- protected:
- int *m_pData;
- int m_iSize;
- int m_iAmount;
- };
- Heap::Heap(int iSize = 100)//注意这里是从0开始,所以如果根是i,那么左孩子是2*i+1,右孩子是2*i+2
- {
- m_pData = new int[iSize];
- m_iSize = iSize;
- m_iAmount = 0;
- }
- Heap::~Heap()
- {
- delete []m_pData;
- }
- int Heap::Enqueue(int iVal)//进入堆
- {
- if (m_iAmount == m_iSize)
- {
- return 0;
- }
- m_pData[m_iAmount ++] = iVal;
- int iIndex = m_iAmount - 1;
- while (m_pData[iIndex] < m_pData[(iIndex - 1) /2])//上浮,直到满足最小堆
- {
- swap(m_pData[iIndex],m_pData[(iIndex - 1) /2]);
- iIndex = (iIndex - 1) /2;
- }
- return 1;
- }
- int Heap::Dequeue(int &iVal)//出堆
- {
- if (m_iAmount == 0)
- {
- return 0;
- }
- iVal = m_pData[0];//出堆的数据
- m_pData[0] = m_pData[m_iAmount - 1];//最后一个数据放到第一个根上面
- -- m_iAmount;//总数减1
- int rc = m_pData[0];
- int s = 0;
- for (int j = 2*s +1; j < m_iAmount; j *= 2)//最后一个数放到第一个位置以后,开始下沉,来维持堆的性质
- {
- if (j < m_iAmount - 1 && m_pData[j] > m_pData[j+1])
- {
- ++ j;
- }
- if (rc < m_pData[j])//rc应该插入在s位置上
- {
- break;
- }
- m_pData[s] = m_pData[j];
- s = j;
- }
- m_pData[s] = rc;
- return 1;
- }
- int Heap::GetMin(int &iVal)
- {
- if (m_iAmount == 0)
- {
- return 0;
- }
- iVal = m_pData[0];
- return 1;
- }
- void Heap::printQueue()
- {
- for (int i = 0; i < m_iAmount; ++ i)
- {
- cout << m_pData[i] << " ";
- }
- cout << endl;
- }
- int main()
- {
- Heap heap;
- heap.Enqueue(4);
- heap.Enqueue(1);
- heap.Enqueue(3);
- heap.Enqueue(2);
- heap.Enqueue(6);
- heap.Enqueue(5);
- heap.printQueue();
- int iVal;
- heap.Dequeue(iVal);
- heap.Dequeue(iVal);
- heap.printQueue();
- return 0;
- }
2.3 STL实现优先队列
使用方法:
头文件:
声明方式:
1、普通方法:
//通过操作,按照元素从大到小的顺序出队
2、自定义优先级:
- struct cmp
- {
- bool operator()(int x, int y)
- {
- return x > y;
- }
- };
{
int x, y;
friend bool operator < (node a, node b)
{
return a.x > b.x; //结构体中,x小的优先级高
}
};
priority_queue<node>q;//定义方法
//在该结构中,y为值, x为优先级。
//通过自定义operator<操作符来比较元素中的优先级。
//在重载”<”时,最好不要重载”>”,可能会发生编译错误
3 应用
首先优先队列是由堆来实现的,所以以后用到优先队列的地方,可以直接用C++中的STL来直接实现,但是最好还是自己实现几次,否则我们只会成为傻瓜,什么东西就知道怎么用,不知道是如何实现的。
优先队列适用的范围很广,比如:
1、构造哈夫曼编码
构造哈夫曼编码是找到节点集合中频率最小的两个点,然后合并节点在插入到集合中,再循环。。。
2、一些任务调度算法
比如操作系统的线程的调度算法,有的是按照优先级来调度的,每次都执行优先级较高的线程
3、合并n个有序文件为一个有序文件
首先把n个有序文件的第一个元素取出来,放到优先队列里面,然后取最小值,然后再插入元素导优先队列,取最小值。。。
4、由于优先队列内部是有堆实现的,所以适用于堆的都适用于优先队列
比如排序,找中位数,找最大的k个数
原文出自:http://blog.csdn.net/zhang20072844/article/details/10286997














 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









