







0、.准备
0.1.目录
- 用VMware创建3个Ubuntu虚拟机
- 用Xshell+Xftp远程连接创建好的虚拟机
- 配置Ubuntu虚拟机源、ssh无密匙登录、jdk
- 配置Hadoop集群文件(Github源码)
- 启动Hadoop集群、在Windows主机上显示集群状态。
0.2.提前准备安装包
- Windows10(宿主操作系统)
- VMware12 workstation(虚拟机)
- Ubuntu16.04.01 LTS 服务器版 (lsb_release -a 查看)
- Hadoop2.6.5 (hadoop-2.6.5.tar.gz)
- jdk1.8 (jdk-8u131-linux-x64.tar.gz)
- Xshell+Xftp(远程连接工具)
- spark(spark-1.6.0-bin-hadoop2.6.tgz)
- Scala版本为2.10.x
- Github源码,记得start哦(CSDN博文中全部源码公开至个人github)
1、配置好3台虚拟机,
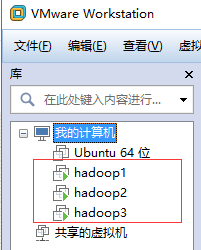
建立好的虚拟机如下
通过
ifconfig
命令查看服务器ip地址hadoop1 IP
192
.
168
.
101
.
49
默认主机名wuhadoop2 IP
192
.
168
.
101
.
48
默认主机名wuhadoop3 IP
192
.
168
.
101
.
47
默认主机名wu下一步会修改主机名hostname
小注:
ifconfig
命令 需要先安装
net-tools
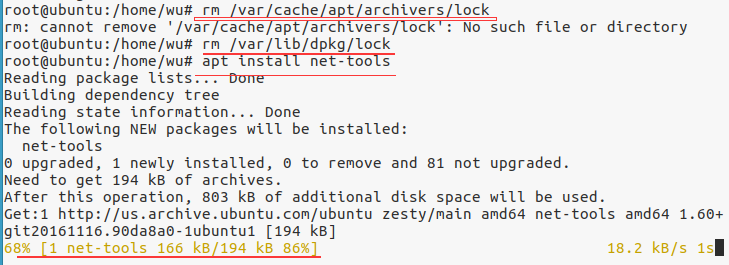
如果安装时出现以下错误

解决方案:
在终端中敲入以下两句
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
再进行安装即可!!!

2、 安装ssh即可
。
这里不需要
ssh-keygen
。
打开终端或者服务器版命令行
查看是否安装(ssh)openssh-server,否则无法远程连接
sshd
sudo
apt install openssh-server
2.1、安装ssh后,可以通过工具
(putty或者MobaXterm或 Xshell)远程连接已经建立好的服务器(Hadoop1,Hadoop2,Hadoop3)
在Hadoop1、Hadoop2、Hadoop3中
xiaolei
@ubuntu
:~
$
sudo vi /etc/apt/sources.list
# 用下面的代码全部替换原来的
# deb cdrom:[Ubuntu 16.04.1 LTS _Xenial Xerus_ - Release amd64 (20160719)]/ xenial main restricted
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to
# newer versions of the distribution.
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial main restricted
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial main restricted
## Major bug fix updates produced after the final release of the
## distribution.
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates main restricted
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## universe WILL NOT receive any review or updates from the Ubuntu security
## team.
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial universe
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates universe
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## multiverse WILL NOT receive any review or updates from the Ubuntu
## security team.
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial multiverse
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-updates multiverse
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial-updates multiverse
## N.B. software from this repository may not have been tested as
## extensively as that contained in the main release, although it includes
## newer versions of some applications which may provide useful features.
## Also, please note that software in backports WILL NOT receive any review
## or updates from the Ubuntu security team.
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
# deb-src http://cn.archive.ubuntu.com/ubuntu/ xenial-backports main restricted universe multiverse
## Uncomment the following two lines to add software from Canonical's
## 'partner' repository.
## This software is not part of Ubuntu, but is offered by Canonical and the
## respective vendors as a service to Ubuntu users.
# deb http://archive.canonical.com/ubuntu xenial partner
# deb-src http://archive.canonical.com/ubuntu xenial partner
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security main restricted
# deb-src http://security.ubuntu.com/ubuntu xenial-security main restricted
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security universe
# deb-src http://security.ubuntu.com/ubuntu xenial-security universe
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ xenial-security multiverse
# deb-src http://security.ubuntu.com/ubuntu xenial-security multiverse
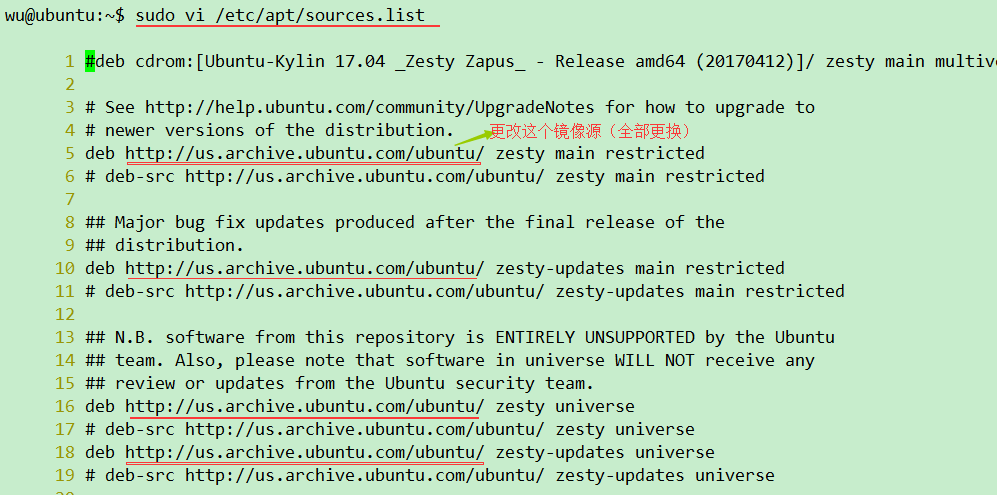
将上面的
http://us.archive.ubuntu.com/ubuntu/
全部对应更换成:
https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
把 http://security.ubuntu.com/ubuntu
替换成
https://mirrors.tuna.tsinghua.edu.cn/ubuntu
即:将源文件中的所有镜像源,
都更换成
https://mirrors.tuna.tsinghua.edu.cn/ubuntu
(可以将
/etc/apt/sources.list考到Windows桌面,用word打开,替换镜像源,完成后,考到Linux,执行命令
sudo cp
sources.list /etc/apt/
即可
)
更新源
xiaolei
@ubuntu
:~
$
sudo apt update
2.3.安装vim编辑器,默认自带vi编辑器
sudo
apt install vim
- 1
- 1
更新系统(服务器端更新量小,桌面版Ubuntu更新量较大,可以暂时不更新)
sudo
apt-get upgrade
2.4 修改Ubuntu服务器hostname主机名,主机名和ip是一一对应的。
#在192.168.193.131
xiaolei
@ubuntu
:~
$
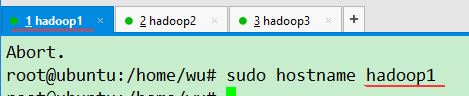
sudo hostname hadoop1
hadoop1 IP
192
.
168
.
101
.
49
默认主机名wuhadoop2 IP
192
.
168
.
101
.
48
默认主机名wuhadoop3 IP
192
.
168
.
101
.
47
默认主机名wu
输入
bash
刷新下,主机名将会改变
其他2台 也一样处理
2.5.增加hosts文件中ip和主机名对应字段
在Hadoop1,2,3中
xiaolei
@hadoop1
:~
$
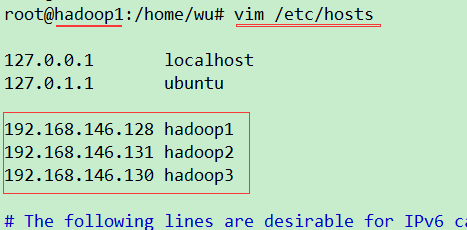
sudo vim /etc/hosts
192
.
168
.
101
.
49
hadoop1
192
.
168
.
101
.
48
hadoop2
192
.
168
.
101
.
47
hadoop3
hadoop2,hadoop3 也进行以上操作!
如果没有安装
vim
,可以使用
vi(操作类似vim)
,或
gedit
2.6.更改系统时区(将时间同步更改为北京时间)

xiaolei
@hadoop1
:~
$
dateWed Oct
26
02:42:
08 PDT
2016
xiaolei
@hadoop1
:~
$
sudo tzselect
根据提示选择
Asia
China
Beijing Time
yes
最后将Asia/Shanghai shell scripts 复制到/etc/localtime
xiaolei
@hadoop1
:~
$
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
xiaolei
@ubuntu
:~
$
dateWed Oct
26
17:45:30
CST
2016
可以直接执行
:
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3. Hadoop集群完全分布式部署过程
- JDK配置
- Hadoop集群部署
3.1.1将所需文件
(Hadoop2.6.5、JDK1.8)上传至Hadoop1服务器(可以直接复制粘贴)
这里使用
Xftp
传送文件
jdk-8u131-linux-x64.tar.gz hadoop-2.6.5.tar.gz
3.1.2.解压缩并将jdk放置/opt路径下
xiaolei
@hadoop1
:~
$
tar -zxf jdk-8u131-linux-x64.tar.gz
hadoop1
@hadoop1
:~
$
sudo mv jdk1.8.0_131 /opt/
[sudo] password
for
hadoop1:
xiaolei
@hadoop1
:~
$
3.1.3.配置环境变量
编写环境变量脚本并使其生效
xiaolei
@hadoop1
:~
$
sudo vim /etc/profile.d/jdk1.
8
.sh
输入内容(或者在我的github上下载jdk环境配置脚本源码)
#!/bin/sh
# author:wangxiaolei 王小雷
# blog:http://blog.csdn.net/dream_an
# date:20170524
export
JAVA_HOME=/opt/
jdk1.8.0_131
export
JRE_HOME=
${JAVA_HOME}
/jre
export
CLASSPATH=.:
${JAVA_HOME}
/lib:
${JRE_HOME}
/lib
export
PATH=
${JAVA_HOME}
/bin:
$PATH
xiaolei
@hadoop1
:~
$
source /etc/profile
3.1.4.验证jdk成功安装

3.1.5.同样方法安装其他集群机器。
也可通过scp命令
#注意后面带 : 默认是/home/wu路径下
xiaolei
@hadoop1
:~
$
scp
jdk-8u131-linux-x64.tar.gz
hadoop2:/home/wu
命令解析:
scp
远程复制
-r
递归
本机文件地址
app是文件,里面包含jdk、Hadoop包
远程主机名@远程主机ip:远程文件地址
3.2.集群ssh无密匙登录
3.2.1.在hadoop1,hadoop2,hadoop3中都执行
sudo apt install sshsudo apt install rsync
#进入到我的home目录
输入命令:
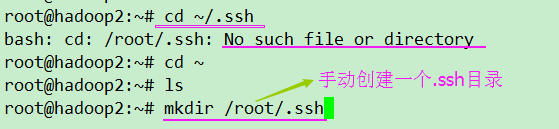
cd ~/.ssh
进入rsa公钥私钥文件存放的目录,删除目录下的id_rsa,id_rsa.pub文件。
二、在每台机上产生新的rsa公钥私钥文件,并统一拷贝到一个authorized_keys文件中
1) 登录hadoop1,在.ssh目录下输入命令:
ssh-keygen
-t rsa
,三次回车后,该目录下将会产生id_rsa,id_rsa.pub文件。其他主机也使用该方式产生密钥文件。
2) 登录hadoop1,输入命令:
cat
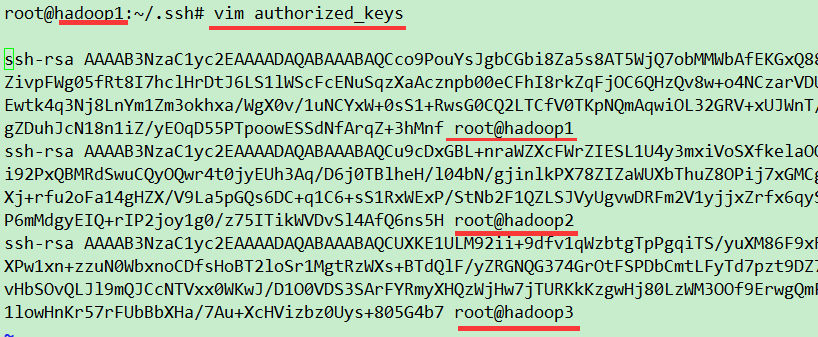
id_rsa.pub >> authorized_keys
,将id_rsa.pub公钥内容拷贝到authorized_keys文件中。
3) 登录其他主机,将其他主机的公钥文件内容都拷贝到hadoop1主机上的authorized_keys文件中,命令如下:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
#登录hadoop2,将公钥拷贝到hadoop1的authorized_keys中ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
#登录hadoop3,将公钥拷贝到hadoop1的authorized_keys中
最后查看hadoop1的
authorized_keys
三、授权authorized_keys文件
1) 登录hadoop01,在.ssh目录下输入命令:
chmod
600
authorized_keys
四、将授权文件分配到其他主机上
1) 登录hadoop1,将授权文件拷贝到hadoop2、hadoop3...,命令如下:
scp
/root/.
ssh
/authorized_keys hadoop2:/root/.
ssh
/ #拷贝到hadoop2上
或者
ssh-copy-id hadoop2
或者
ssh-copy-id -i ~/
.
ssh/id_rsa
.
pub hadoop2
如果弹出
Permission denied
,需要在hadoop2上,按照
小注
提到的重新设置
scp
/root/.
ssh
/authorized_keys hadoop3:/root/.
ssh
/ #拷贝到hadoop3上
如果弹出
Permission denied
,需要在hadoop3上,按照
小注
提到的重新设置
scp
/root/.
ssh
/authorized_keys hadoop04:/root/.
ssh
/ #拷贝到hadoop04上
scp
/root/.
ssh
/authorized_keys hadoop05:/root/.
ssh
/ #拷贝到hadoop05上
小注:
如果执行
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
出现:Permission denied (publickey,password)
解决方法:
登录hadoop1 执行以下命令:
1、修改配置文件:
- Setting PasswordAuthentication yes in /etc/ssh/sshd_config
- Setting RSAAuthenication yes in /etc/ssh/sshd_config
- Setting PubkeyAuthentication yes in /etc/ssh/sshd_config
- Setting PermitRootLogin yes in /etc/ssh/sshd_config

systemctl stop sshd # 先停止sshd
systemctl start sshd # 启动sshd
2、设置hadoop1(master)的localhost
passwd root
# 最好设置的密码与机器对应的登录密码一致
ssh root@localhost
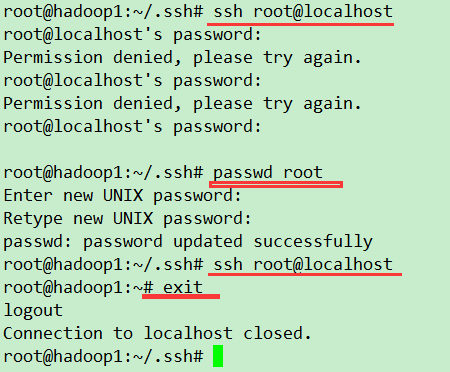
3、修改文件权限
root@hadoop1:~/.ssh#
chmod 700 ../.ssh
root@hadoop1:~/.ssh#
chmod 600 authorized_keys
sudo /etc/init.d/ssh restart
再登录其他主机执行
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop1
五、测试无密码登录


说明两者之间已经可以互相无密码登录
4、Hadoop安装
打开hadoop1
解压安装:
tar -zxvf hadoop-2.6.5.tar.gz -C /opt/
4.1.1.在
Hadoop1,2,3
中配置Hadoop环境变量
xiaolei@hadoop2:~$
sudo vim /etc/profile.d/hadoop2.6.5.sh
输入
#!/bin/sh# Author:wangxiaolei 王小雷# Blog:http://blog.csdn.net/dream_an# Github:https://github.com/wxiaolei# Date:20161027# Path:/etc/profile.d/hadoop2.6.5.sh
export HADOOP_HOME="/opt/hadoop-2.6.5"export PATH="$HADOOP_HOME/bin:$PATH"export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
配置Hadoop
Hadoop的集群部署模式需要修改Hadoop文件夹中
/etc/hadoop/
中的配置文件,更多设置项可见官方说明,这里只设置了常见的设置项:hadoop-env.sh,yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves。
即在
/opt/hadoop-2.6.5/etc/hadoop
4.1.2配置 hadoop-env.sh 增加如下内容
vim
/opt/hadoop-2.6.5/etc/hadoop/
hadoop-env.sh
增加以下语句:
export JAVA_HOME=/opt/jdk1.8.0_131
yarn-env.sh
中配置JAVA_HOME
# some Java parameters export JAVA_HOME=
/opt/jdk1.8.0_131
4.1.3.配置slaves文件,增加slave主机名
hadoop2hadoop3
4.1.4.配置 core-site.xml
<
configuration
>
<!-- 指定hdfs的nameservice为ns1 -->
<
property
>
<
name
>
fs.defaultFS
</
name
>
<
value
>
hdfs://hadoop1:9000
</
value
>
</
property
>
<!-- Size of read/write buffer used in SequenceFiles. -->
<
property
>
<
name
>
io.file.buffer.size
</
name
>
<
value
>
131072
</
value
>
</
property
>
<!-- 指定hadoop临时目录,自行创建 -->
<
property
>
<
name
>
hadoop.tmp.dir
</
name
>
<
value
>
/home/wu/hadoop/tmp
</
value
>
</
property
>
</
configuration
>
4.1.5.配置 hdfs-site.xml
<
configuration
>
<
property
>
<
name
>
dfs.namenode.secondary.http-address
</
name
>
<
value
>
hadoop1:50090
</
value
>
</
property
>
<
property
>
<
name
>
dfs.replication
</
name
>
<
value
>
2
</
value
>
</
property
>
<
property
>
<
name
>
dfs.namenode.name.dir
</
name
>
<
value
>
file:/home/wu/hadoop/hdfs/name
</
value
>
</
property
>
<
property
>
<
name
>
dfs.datanode.data.dir
</
name
>
<
value
>
file:/home/wu/hadoop/hdfs/data
</
value
>
</
property
>
</
configuration
>
4.1.6.配置yarn-site.xml
<
configuration
>
<!-- Site specific YARN configuration properties -->
<!-- Configurations for ResourceManager -->
<
property
>
<
name
>
yarn.nodemanager.aux-services
</
name
>
<
value
>
mapreduce_shuffle
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.address
</
name
>
<
value
>
hadoop1:8032
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.scheduler.address
</
name
>
<
value
>
hadoop1:8030
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.resource-tracker.address
</
name
>
<
value
>
hadoop1:8031
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.admin.address
</
name
>
<
value
>
hadoop1:8033
</
value
>
</
property
>
<
property
>
<
name
>
yarn.resourcemanager.webapp.address
</
name
>
<
value
>
hadoop1:8088
</
value
>
</
property
>
</
configuration
>
4.1.7.配置mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
<
configuration
>
<
property
>
<
name
>
mapreduce.framework.name
</
name
>
<
value
>
yarn
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.jobhistory.address
</
name
>
<
value
>
hadoop1:10020
</
value
>
</
property
>
<
property
>
<
name
>
mapreduce.jobhistory.address
</
name
>
<
value
>
hadoop1:19888
</
value
>
</
property
>
</
configuration
>
4.1.8.复制Hadoop配置好的包到其他Linux主机
scp -r /opt/hadoop-2.6.5 hadoop2:/opt/scp -r /opt/hadoop-2.6.5 hadoop3:/opt/
再按照 4.1.1.在
hadoop1,2,3
中配置Hadoop环境变量
4.2 验证Hadoop是否安装成功
启动Hadoop
,只需要在master(hadoop1)进行下列操作即可
cd /opt/hadoop-2.6.5 #进入Hadoop目录# sudo bin/hadoop namenode –format #格式化namenode
bin/
hadoop namenode -format
#格式化namenode,如果启动了namenode,下次启动
//或者
bin/
hdfs namenode -format
hadoop就不用再使用这句,重复使用会导致DataNode无法启动sbin/start-dfs.sh #启动HDFSsbin/start-yarn.sh #启动资源管理器
启动Hadoop
./sbin/start-all.sh
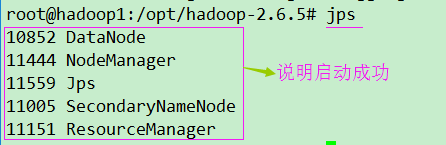
上面的没有启动NameNode
先关闭 ./sbin/stop-all.sh
hadoop namenode -format
再启动
./sbin/start-all.sh
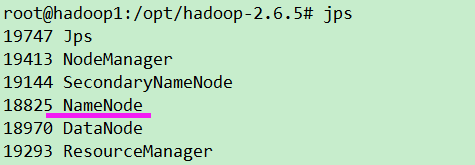
如果多次
bin/hadoop namenode –format(
不用多次使用
),
导致DataNode无法启动
cd /home/wu/ (Hadoop1,2,3都需清除)
rm -rf hadoop
#
清除hadoop文件夹
停止Hadoop
./sbin/stop-all.sh
或者
sbin/stop-dfs.sh
sbin/stop-yarn.sh
4.2.1.在主机上查看,博主是Windows10,直接在浏览器中输入hadoop1 集群地址即可。
http:
//192.168.101.49:8088/ # 点开左边的Nodes
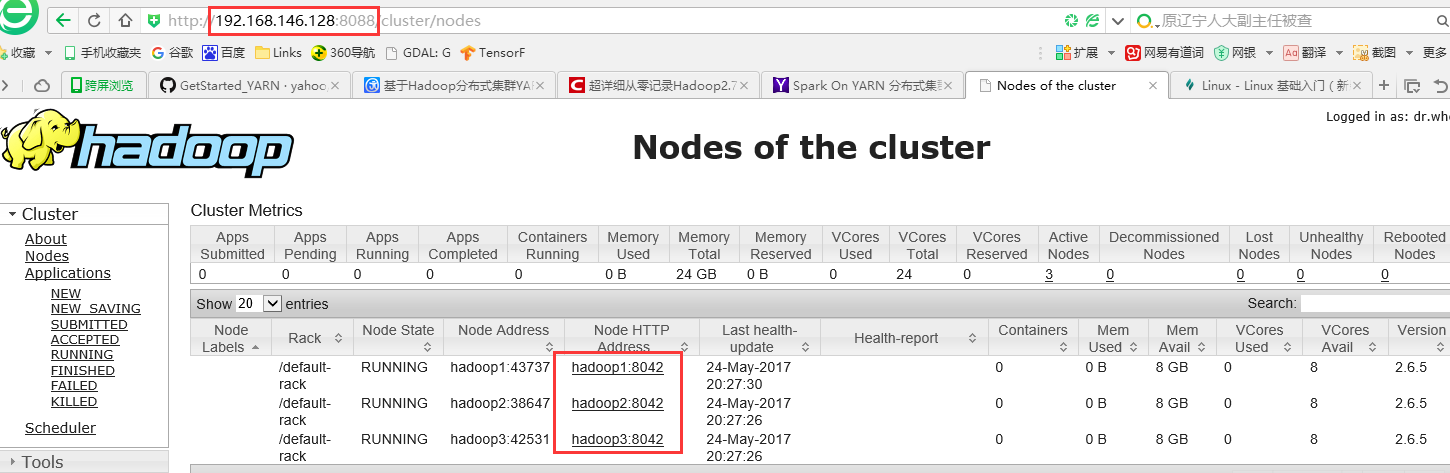
先停止Hadoop
./sbin/stop-all.sh
四、安装Scala
sudo tar zxvf scala-2.10.6.tgz -C /usr/local/
再次添加环境变量,再次使用使用
sudo vim /etc/profile
添加以下内容:
export SCALA_HOME=/usr/local/scala-2.10.6export PATH=$PATH:$SCALA_HOME/bin
重新载入环境变量,并验证scala是否安装成功
$ source /etc/profile #重新载入环境变量$ scala -version #查看scala安装版本,如出现以下版本信息,则安装成功Scala code runner version 2.10.6 — Copyright 2002-2013, LAMP/EPFL
停止Hadoop
./sbin/stop-all.sh
5、Spark安装
在hadoop1(Master)上进行以下操作:
下载后,进行解压
sudo tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz -C /opt/
cd /optsudo mv spark-1.6.0-bin-hadoop2.6/ spark-1.6.0
#重命名文件
配置Spark
cd /opt/spark-1.6.0/conf/cp spark-env.sh.template spark-env.shsudo vim spark-env.sh
在spark-env.sh文件尾部添加以下配置:
export JAVA_HOME=/opt/jdk1.8.0_131
#Java环境变量export SCALA_HOME=/usr/local/scala-2.10.6 #SCALA环境变量 (没有安装,先注释掉,如果安装了需加上)export SPARK_WORKING_MEMORY=1g #每一个worker节点上可用的最大内存(
如果worker节点内存不足1g会报错,解决办法 扩大节点内存
)export SPARK_MASTER_IP=hadoop1 #驱动器节点IP
export HADOOP_HOME="/opt/hadoop-2.6.5"
#Hadoop路径
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#Hadoop配置目录
配置slave主机
$ cp slaves.template slaves$ sudo vim slaves
添加slave主机
hadoop2 #slave1hadoop3 #slave2
将配置好的Spark分发给所有的slave
scp -r /opt/spark-1.6.0 hadoop2:/opt/
scp -r /opt/spark-1.6.0 hadoop3:/opt/
验证Spark是否安装成功
使用下面的命令,运行Spark
cd /opt/
spark-1.6.0
./sbin/start-all.sh
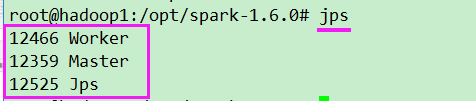
停止spark
./sbin/stop-all.sh
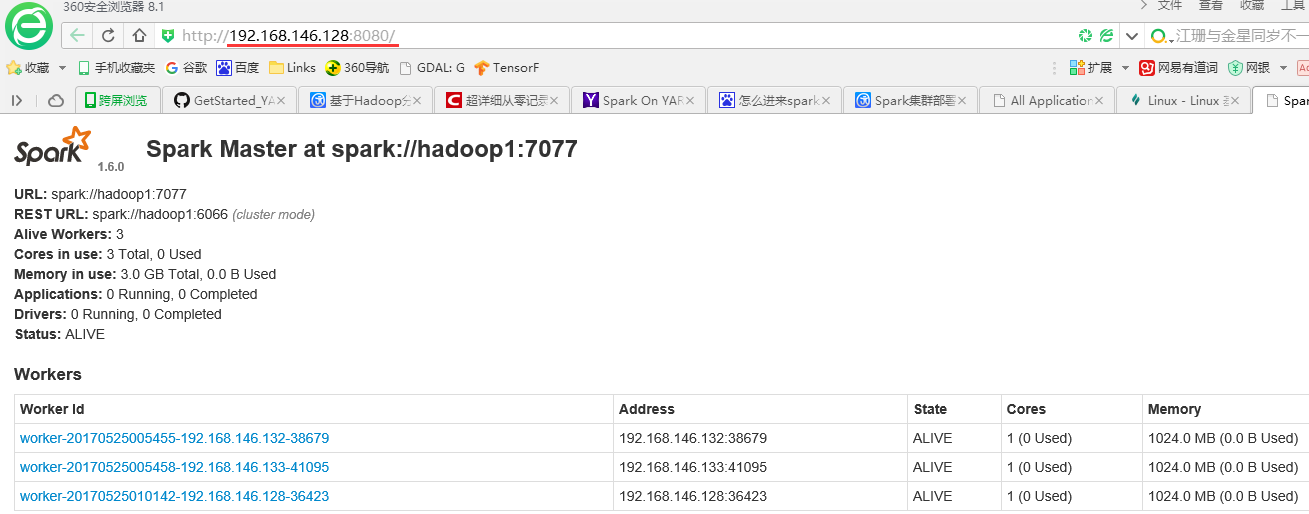
进入Spark的Web管理页面
http://192.168.101.49:8080/
运行简单示例
当需要运行Spark终端,必须将Spark的bin目录加入到系统路径。
vim /etc/profile
export SPARK_HOME=/opt/spark-1.6.0export PATH=$PATH:${SPARK_HOM}/bin
source
/etc/profile
添加Spark的bin目录路径后,运行
./spark-shell
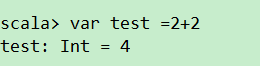
exit
# 退出
至此,hadoop、spark集群模式完全
安装成功
注:
如果ip发生变化了,必须的重新修改文件中的ip(通过以下命令)hadoop1,2,3都需修改
sudo vim /etc/hosts















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









