







参考:
1、https://github.com/tensorflow/models/blob/master/research/slim/nets/cifarnet.py
2、https://github.com/tensorflow/models/blob/master/research/slim
模型:slim搭建的DNN
数据:mnist
通过直接对TF-slim快速搭建cnn 修改,即可完成DNN的搭建
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
"""使用slim API快速搭建cnn,
使用的数据集 mnist
参考:
1、https://github.com/tensorflow/models/blob/master/research/slim/nets/cifarnet.py
2、http://blog.csdn.net/wc781708249/article/details/78414028
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import tensorflow.contrib.slim as slim
# slim = tf.contrib.slim
from tensorflow.examples.tutorials.mnist import input_data
import argparse
import sys
# 搭建dnn 多层感知神经层
def cifarnet(images,num_classes=10,is_training=False,
dropout_keep_prob=0.5,
prediction_fn=slim.softmax,
scope='CifarNet'):
"""
Creates a variant of the CifarNet model.
:param images: 输入图像数据 形状[n,h*w*c]
:param num_classes: 类别数
:param is_training: 是否训练 模型训练设置为True,测试、推理设置为False
:param dropout_keep_prob: droupout保持率
:param prediction_fn: 输出层的激活函数
:param scope: 节点名
:return:
net:2D Tensor ,logits (pre-softmax激活)如果num_classes
是非零整数,或者如果num_classes为0或None输入到逻辑层
end_points:从网络组件到相应的字典激活。
"""
end_points = {}
# 如果使用mnist images的shape为[n,28*28*1]
with tf.variable_scope(scope, 'CifarNet', [images]): # 其中[images]为传入的数据
net = slim.fully_connected(images, 384, scope='fc1') # 全连接层,输出节点384 ;shape [n,384]
end_points['fc1'] = net
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout3') # droupout 层 ;shape [n,384]
net = slim.fully_connected(net, 192, scope='fc2') # # 全连接层,输出节点192 ;shape [n,192]
end_points['fc2'] = net
if not num_classes: # num_classes为0、Nnoe,返回的不是最终的输出层,
return net, end_points
logits = slim.fully_connected(net, num_classes,
biases_initializer=tf.zeros_initializer(),
weights_initializer=tf.truncated_normal_initializer(1 / 192.0),
weights_regularizer=None,
activation_fn=None,
scope='logits') # 输出层 ;shape [n,num_classes]
end_points['Logits'] = logits
end_points['Predictions'] = prediction_fn(logits, scope='Predictions')
return logits, end_points
cifarnet.default_image_size = 28 # 这里使用mnist数据 如果使用cifar 改成32
def cifarnet_arg_scope(weight_decay=0.004):
"""Defines the default cifarnet argument scope.
设置各层的一些参数
Args:
weight_decay: 用于规范模型的权重衰减。.
Returns:
用于inception v3模型的`arg_scope`。
"""
with slim.arg_scope(
[slim.conv2d], # 设置卷积层一些参数,
weights_initializer=tf.truncated_normal_initializer(stddev=5e-2),# 权重初始化
activation_fn=tf.nn.relu): # 设置激活函数
with slim.arg_scope(
[slim.fully_connected], # 设置全连接层的一些参数
biases_initializer=tf.constant_initializer(0.1), # biases 初始化为0.1
weights_initializer=tf.truncated_normal_initializer(0.04), # 权重初始化
weights_regularizer=slim.l2_regularizer(weight_decay), # L2正则化
activation_fn=tf.nn.relu) as sc:
return sc
def inception_resnet_v2_arg_scope(weight_decay=0.00004,
batch_norm_decay=0.9997,
batch_norm_epsilon=0.001,
activation_fn=tf.nn.relu):
"""Returns the scope with the default parameters for inception_resnet_v2.
使用了batch_norm,相对来说要比cifarnet_arg_scope效果更佳,推荐使用该方式进行各层参数配置
Args:
weight_decay: the weight decay for weights variables.
batch_norm_decay: decay for the moving average of batch_norm momentums.
batch_norm_epsilon: small float added to variance to avoid dividing by zero.
activation_fn: Activation function for conv2d.
Returns:
a arg_scope with the parameters needed for inception_resnet_v2.
"""
# Set weight_decay for weights in conv2d and fully_connected layers.
with slim.arg_scope([slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay),
biases_regularizer=slim.l2_regularizer(weight_decay)):
batch_norm_params = {
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'fused': None, # Use fused batch norm if possible.
}
# Set activation_fn and parameters for batch_norm.
with slim.arg_scope([slim.conv2d], activation_fn=activation_fn,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params) as scope:
return scope
class Conv_model(object):
# def __init__(self, X, Y, weights, biases, learning_rate, keep):
def __init__(self, Y, learning_rate):
# super(Conv_model, self).__init__(X,Y,w,b,learning_rate) # 返回父类的对象
# 或者 model.Model.__init__(self,X,Y,w,b,learning_rate)
# self.X = X
self.Y = Y
# self.weights = weights
# self.biases = biases
self.learning_rate = learning_rate
# self.keep = keep
'''
def conv2d(self, x, W, b, strides=1):
# Conv2D wrapper, with bias and relu activation
x = tf.nn.conv2d(x, W, strides=[1, strides, strides, 1], padding='SAME')
x = tf.nn.bias_add(x, b) # strides中间两个为1 表示x,y方向都不间隔取样
return tf.nn.relu(x)
def maxpool2d(self, x, k=2):
# MaxPool2D wrapper
return tf.nn.max_pool(x, ksize=[1, k, k, 1], strides=[1, k, k, 1],
padding='SAME') # strides中间两个为2 表示x,y方向都间隔1个取样
def inference(self, name='conv', activation='softmax'): # 重写inference函数
with tf.name_scope(name):
conv1 = self.conv2d(self.X, self.weights['wc1'], self.biases['bc1'])
conv1 = self.maxpool2d(conv1, k=2) # shape [N,1,1,32]
conv1 = tf.nn.lrn(conv1, depth_radius=5, bias=2.0, alpha=1e-3, beta=0.75)
conv1 = tf.nn.dropout(conv1, self.keep)
fc1 = tf.reshape(conv1, [-1, self.weights['wd1'].get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, self.weights['wd1']), self.biases['bd1'])
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, self.keep)
y = tf.add(tf.matmul(fc1, self.weights['out']), self.biases['out'])
if activation == 'softmax':
y = tf.nn.softmax(y)
return y
'''
def loss(self, pred_value, MSE_error=False, one_hot=True):
if MSE_error:
return tf.reduce_mean(tf.reduce_sum(
tf.square(pred_value - self.Y), reduction_indices=[1]))
else:
if one_hot:
return tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=self.Y, logits=pred_value))
else:
return tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.cast(self.Y, tf.int32), logits=pred_value))
def evaluate(self, pred_value, one_hot=True):
if one_hot:
correct_prediction = tf.equal(tf.argmax(pred_value, 1), tf.argmax(self.Y, 1))
# correct_prediction = tf.nn.in_top_k(pred_value, Y, 1)
else:
correct_prediction = tf.equal(tf.argmax(pred_value, 1), tf.cast(self.Y, tf.int64))
return tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
def train(self, cross_entropy):
global_step = tf.Variable(0, trainable=False)
return tf.train.GradientDescentOptimizer(self.learning_rate).minimize(cross_entropy,
global_step=global_step)
class Inputs(object):
def __init__(self,file_path,batch_size,one_hot=True):
self.file_path=file_path
self.batch_size=batch_size
self.mnist=input_data.read_data_sets(self.file_path, one_hot=one_hot)
def inputs(self):
batch_xs, batch_ys = self.mnist.train.next_batch(self.batch_size)
return batch_xs, batch_ys
def test_inputs(self):
return self.mnist.test.images,self.mnist.test.labels
FLAGS=None
def train():
# 开始搭建cnn
input_model = Inputs(FLAGS.data_dir, FLAGS.batch_size, one_hot=FLAGS.one_hot)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 28*28*1],'x')
y_ = tf.placeholder(tf.float32, [None,10],'y_')
keep=tf.placeholder(tf.float32)
is_training= tf.placeholder(tf.bool, name='MODE')
# image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
# with slim.arg_scope(cifarnet_arg_scope()):
with slim.arg_scope(inception_resnet_v2_arg_scope()):
y, _ = cifarnet(images=x,num_classes=10,is_training=is_training,dropout_keep_prob=keep)
model=Conv_model(y_,FLAGS.learning_rate)
cross_entropy = model.loss(y, MSE_error=False, one_hot=FLAGS.one_hot)
train_op = model.train(cross_entropy)
accuracy = model.evaluate(y, one_hot=FLAGS.one_hot)
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
with tf.Session() as sess:
sess.run(init)
for step in range(FLAGS.num_steps):
batch_xs, batch_ys = input_model.inputs()
train_op.run({x: batch_xs, y_: batch_ys,keep:0.7,is_training:True})
if step % FLAGS.disp_step == 0:
acc=accuracy.eval({x: batch_xs, y_: batch_ys,keep:1.,is_training:False})
print("step", step, 'acc', acc,
'loss', cross_entropy.eval({x: batch_xs, y_: batch_ys,keep:1.,is_training:False}))
# test acc
test_x, test_y = input_model.test_inputs()
acc = accuracy.eval({x: test_x, y_: test_y,keep:1.,is_training:False})
print('test acc', acc)
def main(_):
# if tf.gfile.Exists(FLAGS.log_dir):
# tf.gfile.DeleteRecursively(FLAGS.log_dir)
# if not tf.gfile.Exists(FLAGS.log_dir):
# tf.gfile.MakeDirs(FLAGS.log_dir)
train()
if __name__=="__main__":
# 设置必要参数
parser = argparse.ArgumentParser()
parser.add_argument('--num_steps', type=int, default=1000,
help = 'Number of steps to run trainer.')
parser.add_argument('--disp_step', type=int, default=100,
help='Number of steps to display.')
parser.add_argument('--learning_rate', type=float, default=0.01,
help='Learning rate.')
parser.add_argument('--batch_size', type=int, default=128,
help='Number of mini training samples.')
parser.add_argument('--one_hot', type=bool, default=True,
help='One-Hot Encoding.')
parser.add_argument('--data_dir', type=str, default='./MNIST_data',
help = 'Directory for storing input data')
parser.add_argument('--log_dir', type=str, default='./log_dir',
help='Summaries log directory')
FLAGS, unparsed = parser.parse_known_args()
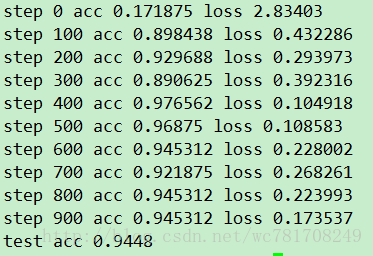
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)结果:














 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









