







文本处理工具
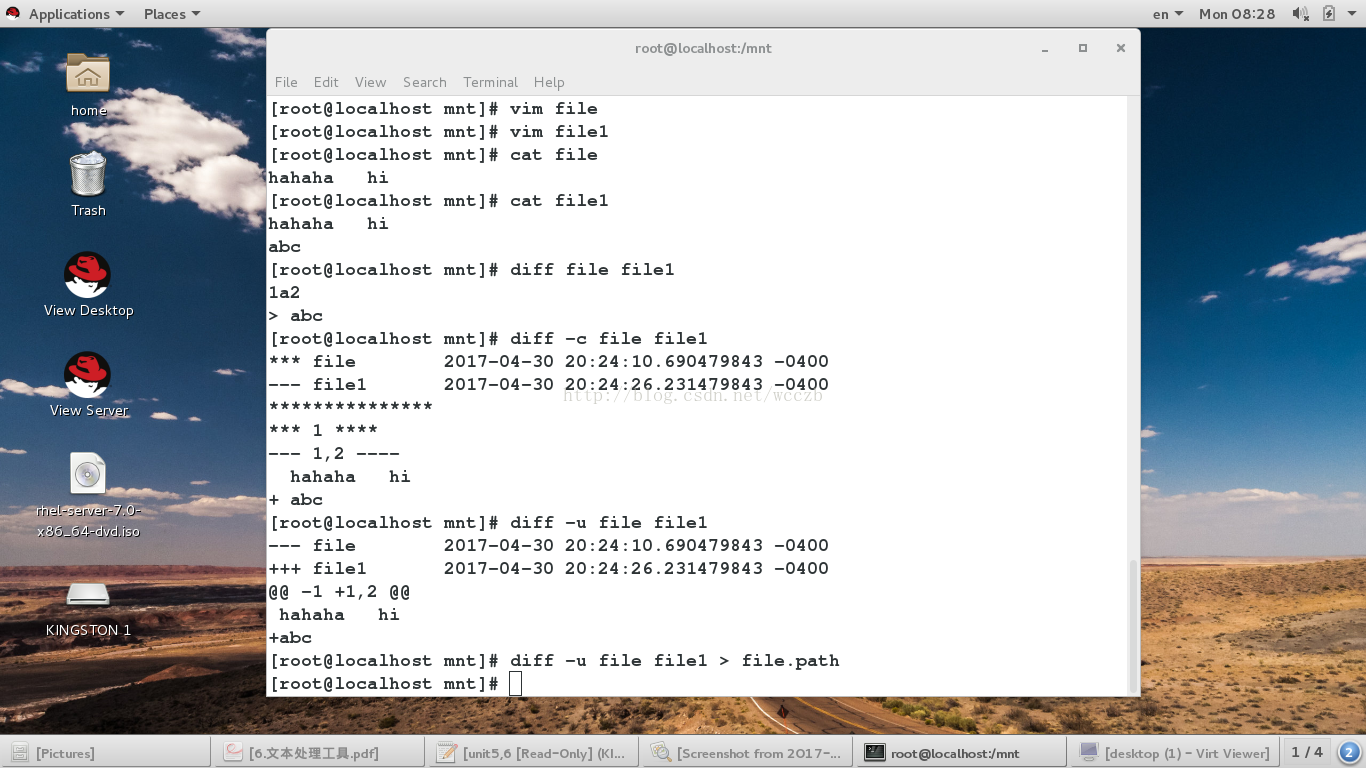
1.diff 命令• diff 命令用于比较两个文件的内容 , 以了解其区别。它还可
用于创建补丁文件。补丁文件用于在企业环境的多台计算
机之间对相似文件进行更改
diff -u file file.new >file.path ##生成补丁文件
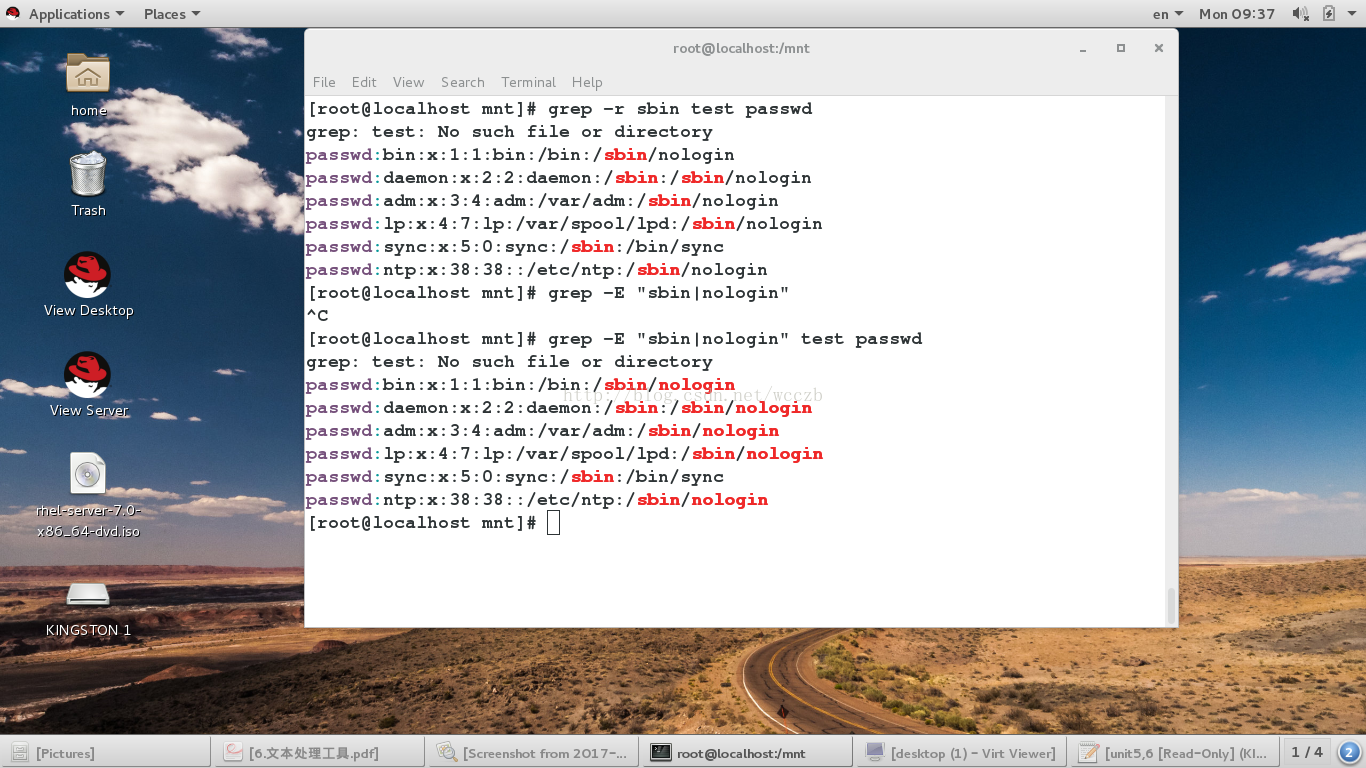
2.grep 命令
• grep 将显示文件中与模式匹配的行。其也可以处理标准输入
• 模式可以包含正则表达式元字符 , 因此始终为正则表达式加引号通常被视为一种好办法。在本单元后面的部分中将介
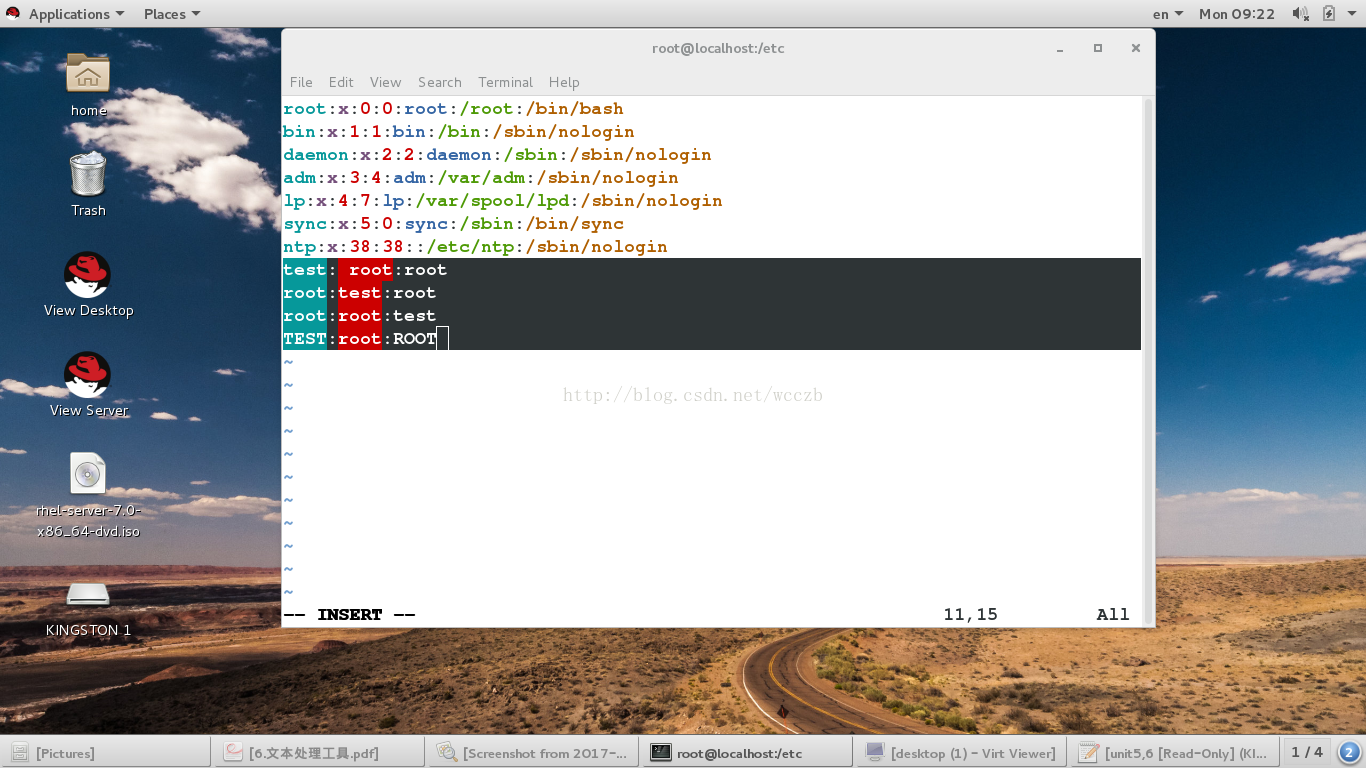
grep##过滤字符
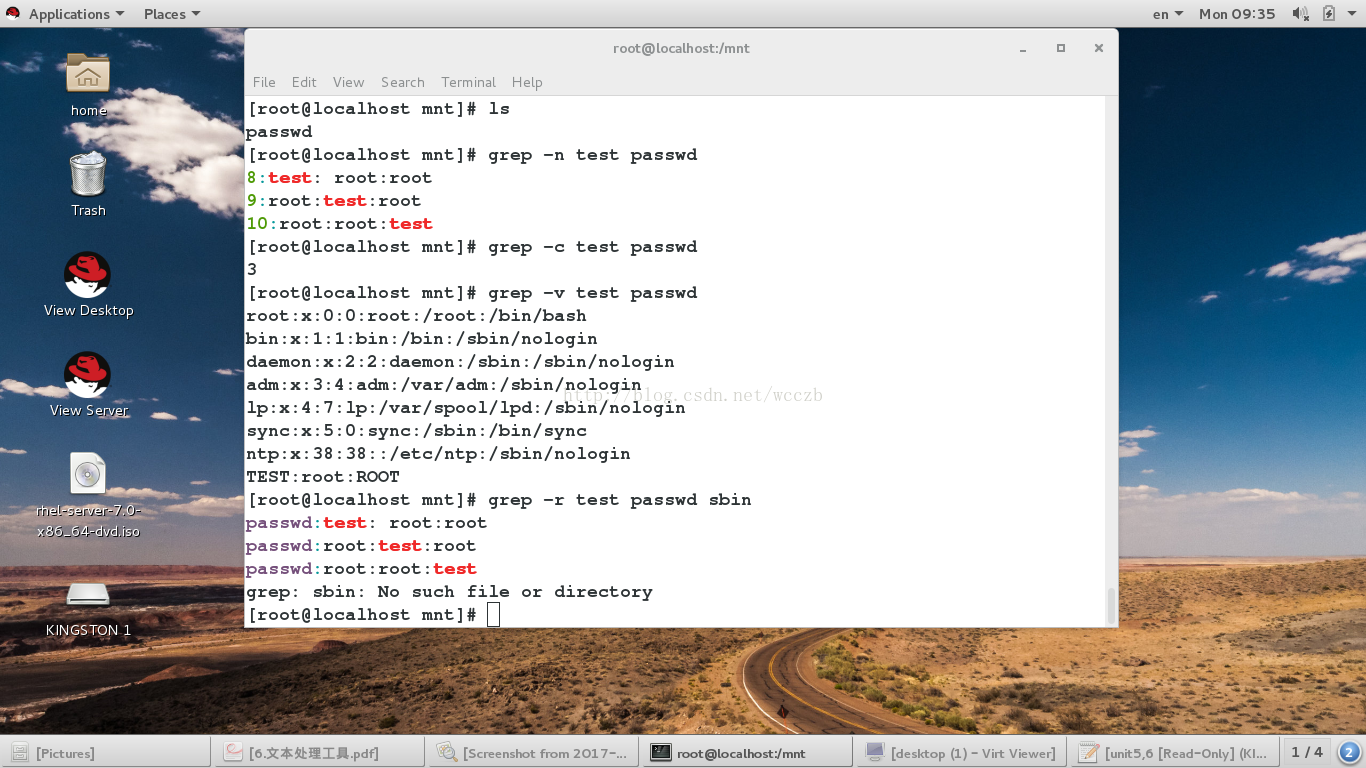
-i ##或略大小写-n ##显示结果所在行的行号
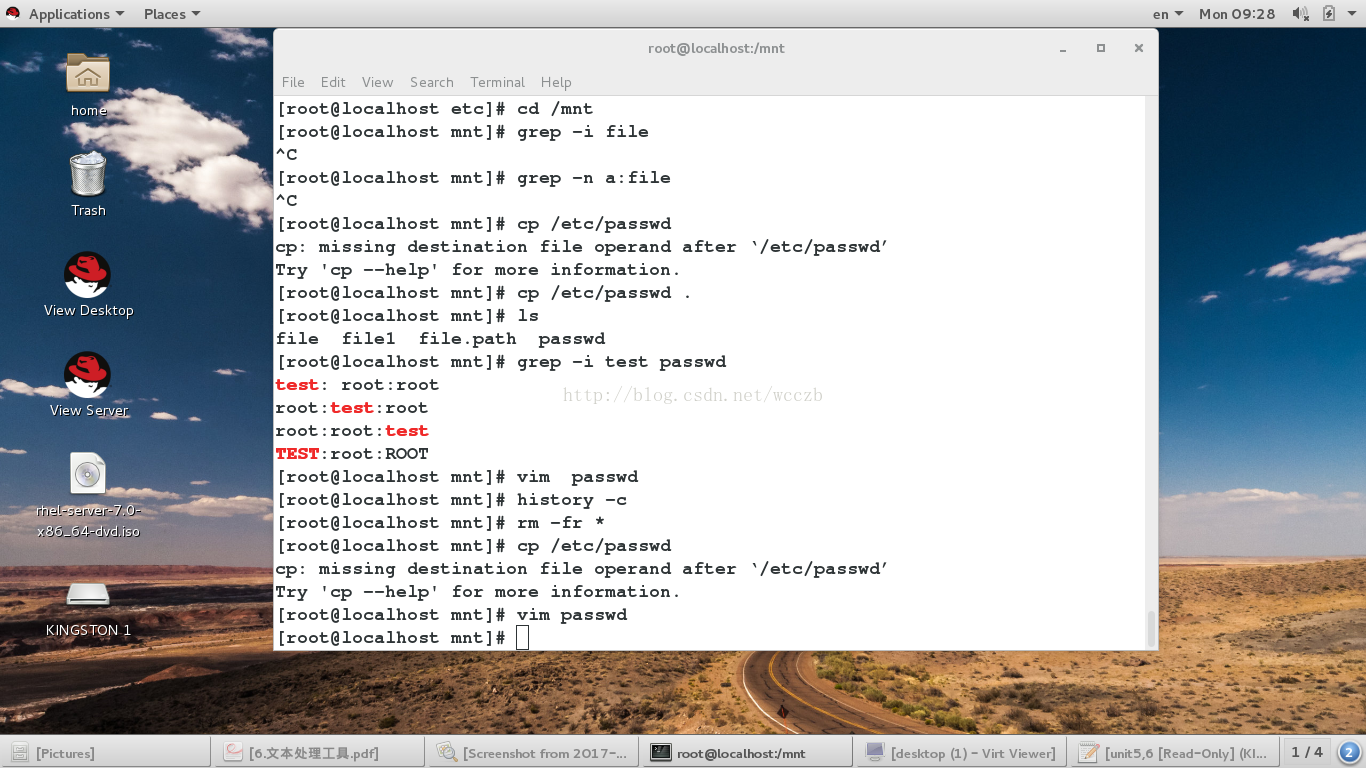
-v ##反向过滤
-r 关键字 目录 ##在目录中过滤还有关键字的文件
-E "关键字1|关键字2|....." ##过滤多个关键字
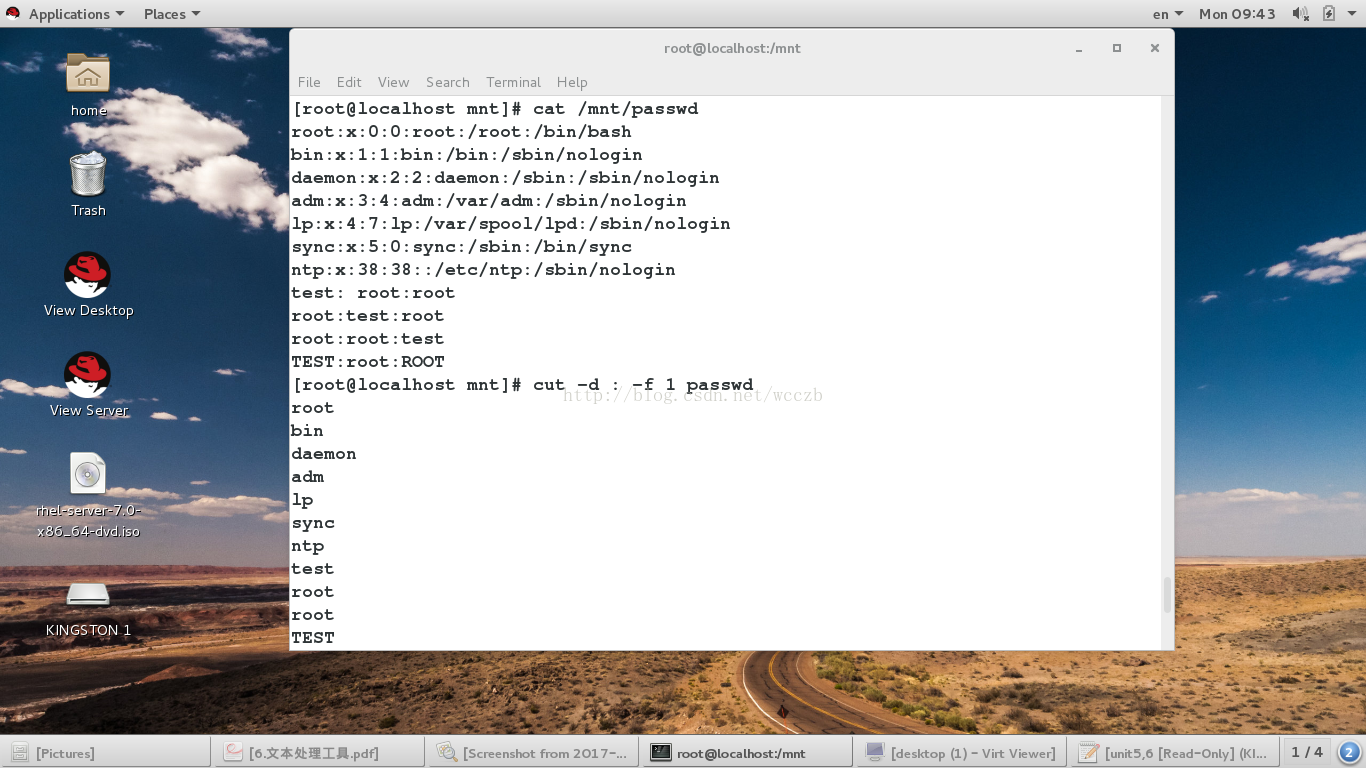
3.Cut 命令
• cut 用于“剪切”文件中的文本字段或列并将
其显示到标准输出
(1)将文本中第一列取出:
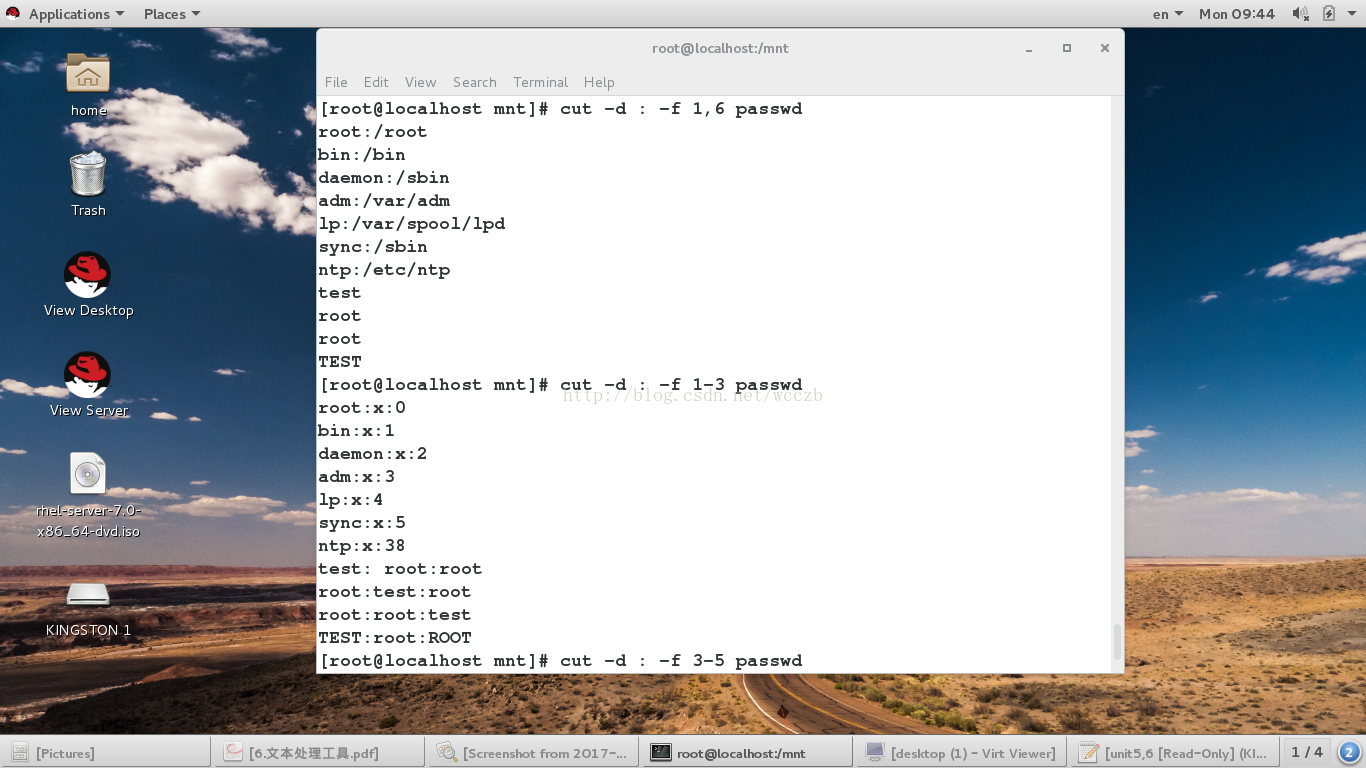
(2)将文本中第一列和第六列的内容取出,还有第一列至第三列取出:
ex:截取本机ip

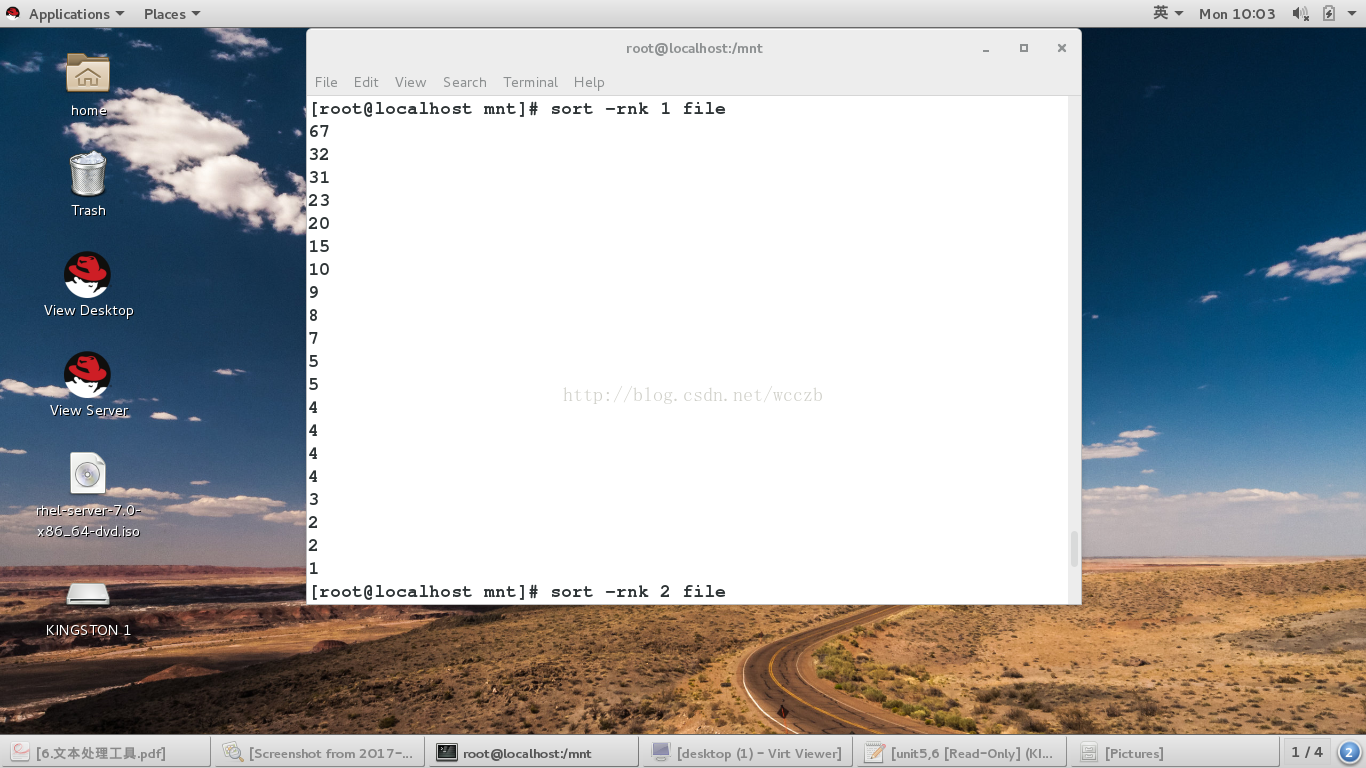
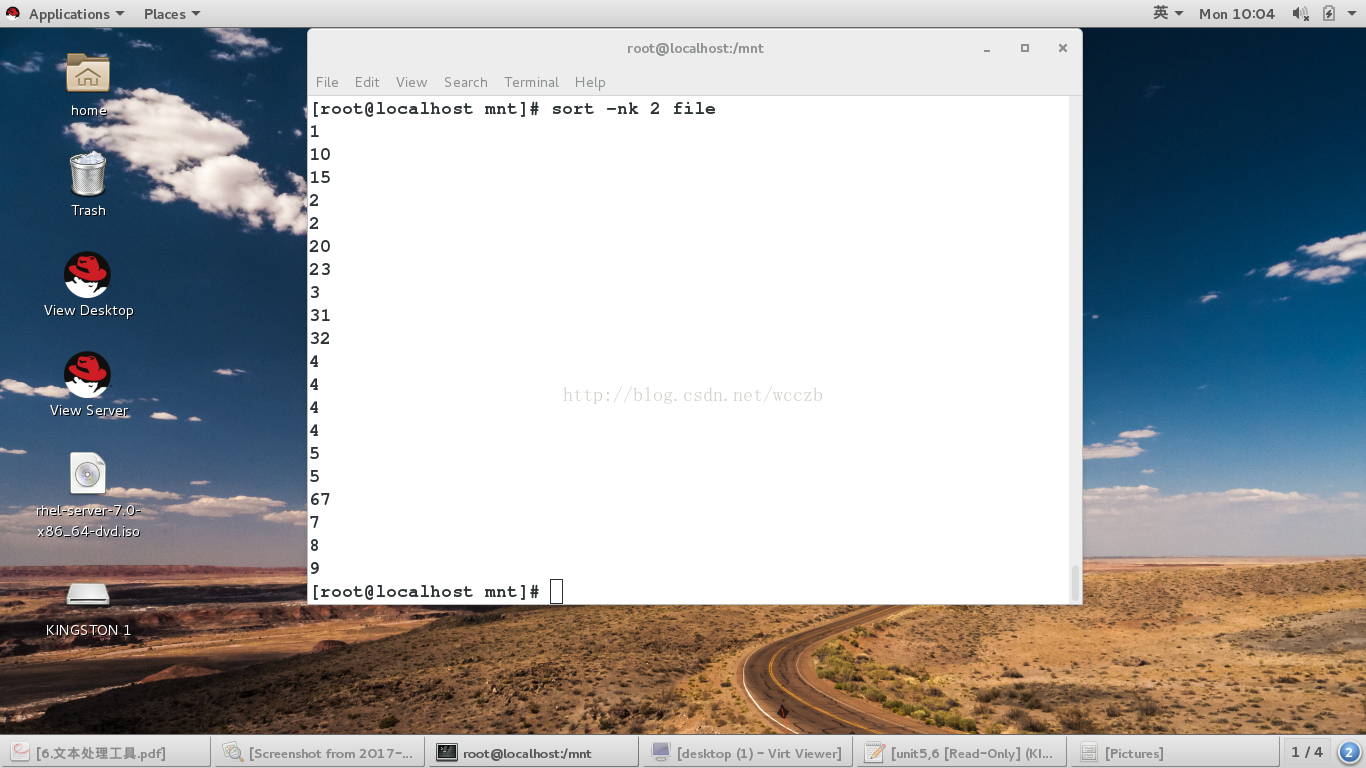
4.sort 命令
• sort 用于排序文本数据。该数据可以位于文件中或其他命令输出中。 Sort 通常与管道一起使用
sort ##排序
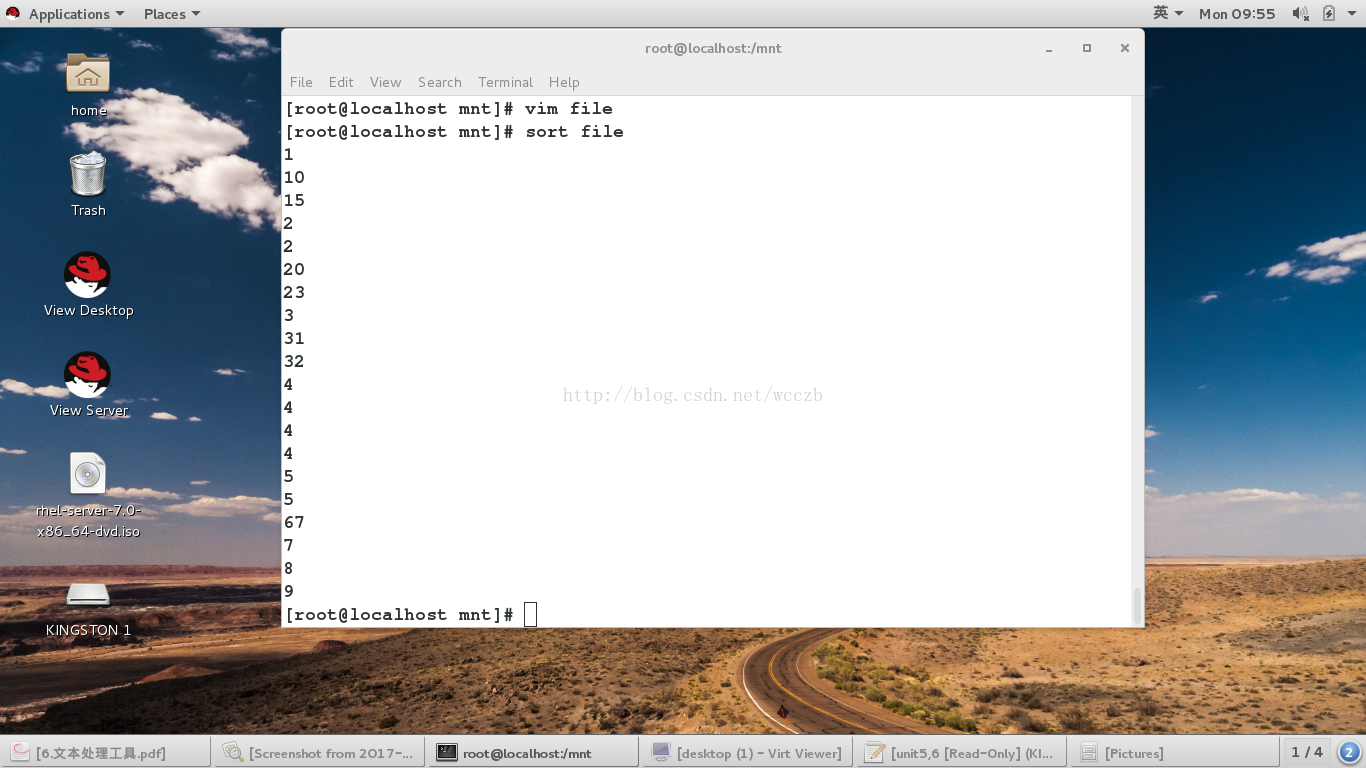
-n ##纯数字
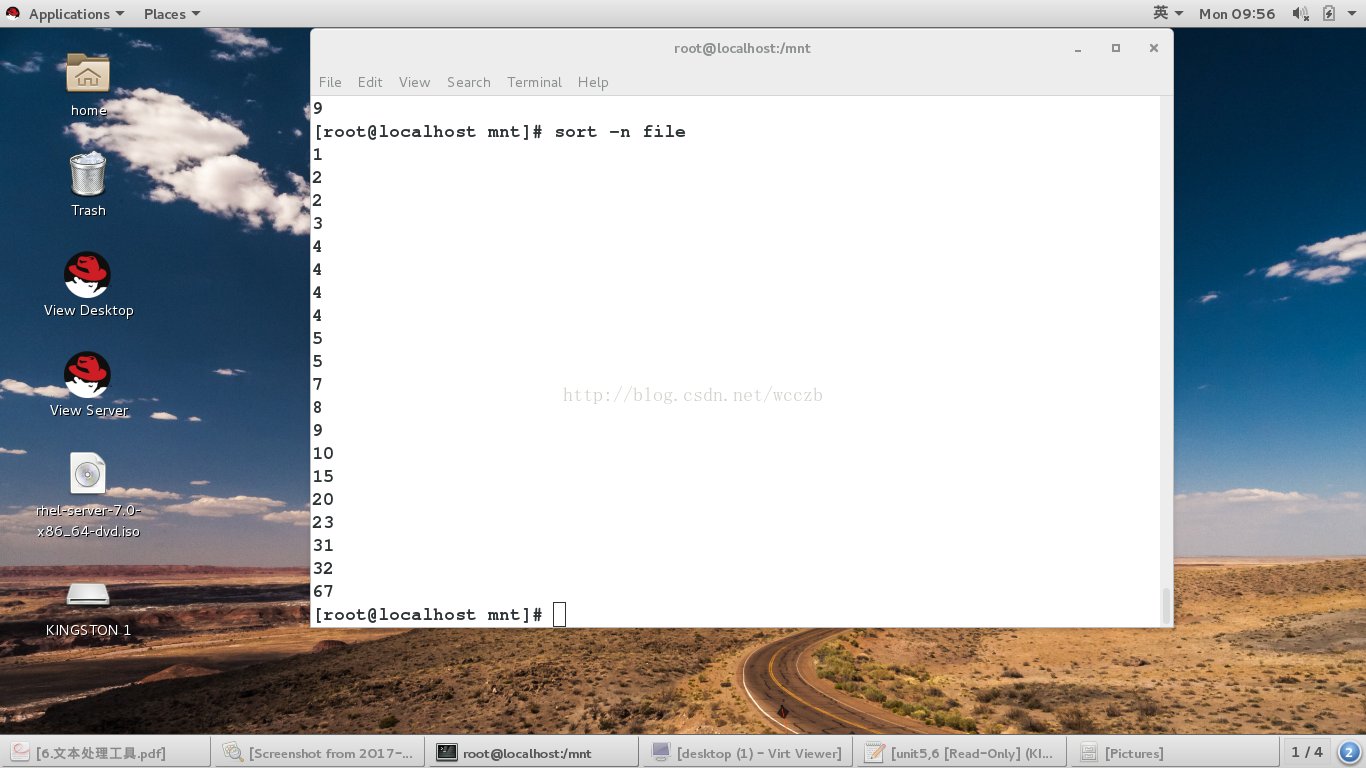
-r ##倒序
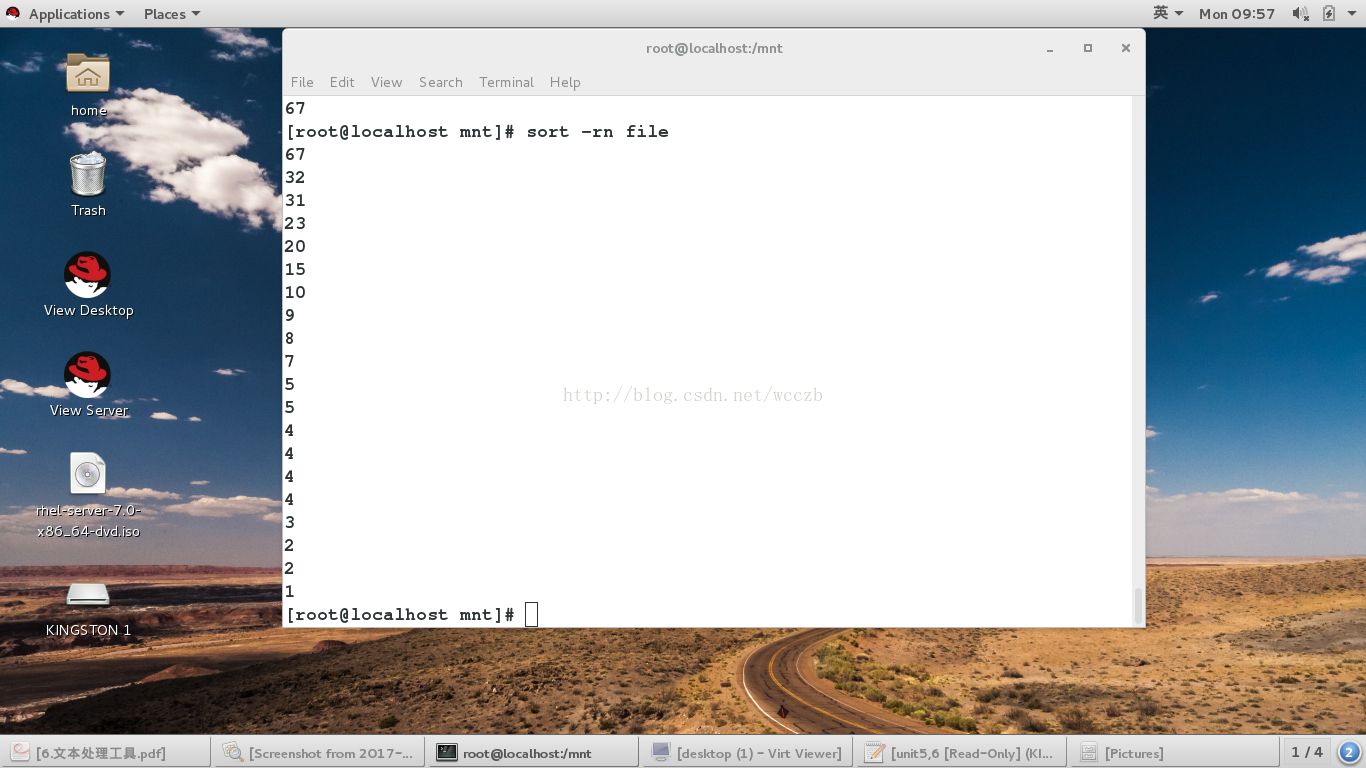
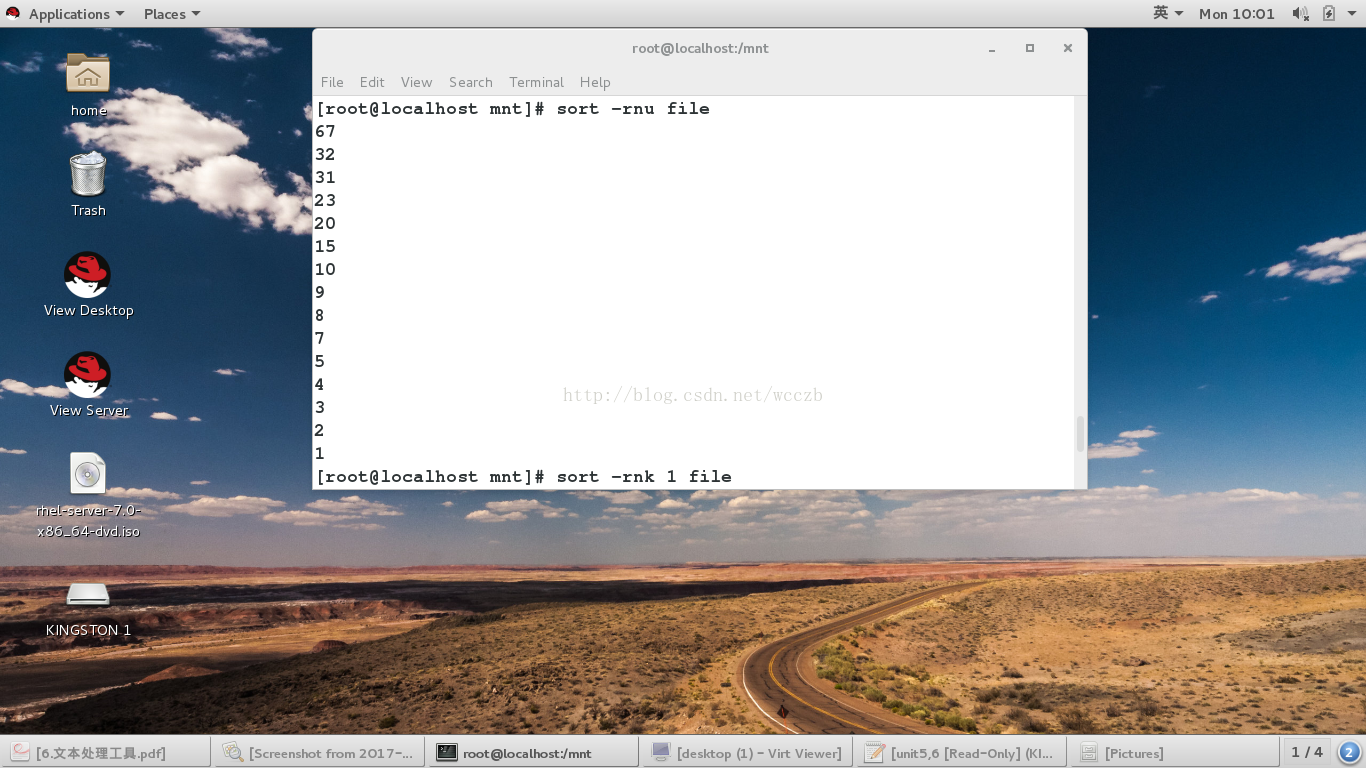
-u ##去掉重复行
-t ##指定分隔符
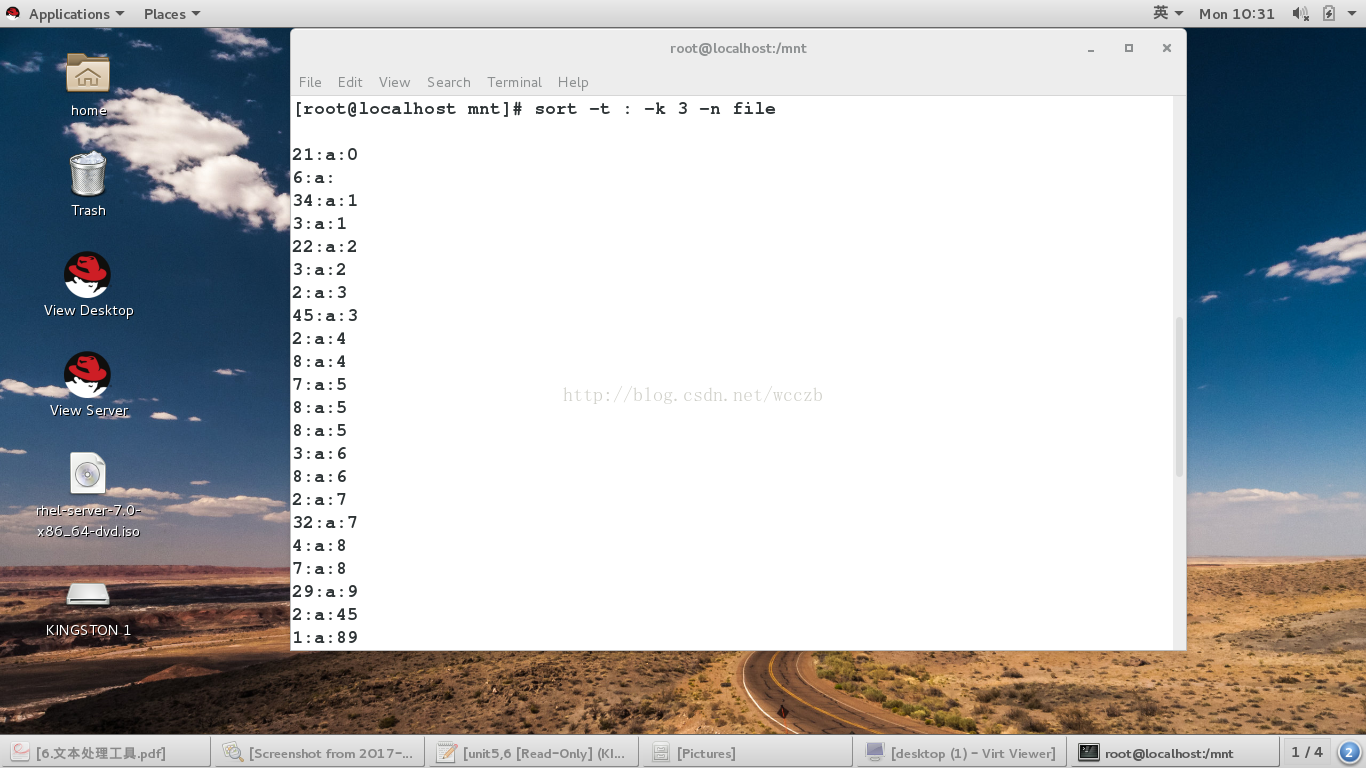
-k ##指定排序的列
4.uniq 命令
• uniq“ 删除”文件中重复的相邻行。若要只打印文件中出现的唯一行(“ 删除”所有重复行 ), 必须首先对 uniq 的输入进行排序。由于可以为uniq 指定其决策所基于的字段或列 , 因此这些字段或列是对其输入进行排序所必须的字段或列。如果未与选项一起使用 , uniq 会使用整个记录作为决策键 , 删除其输入中的重复行。
uniq ##处理重复行
-c ##统计重复行的个数

-d ##显示重复行
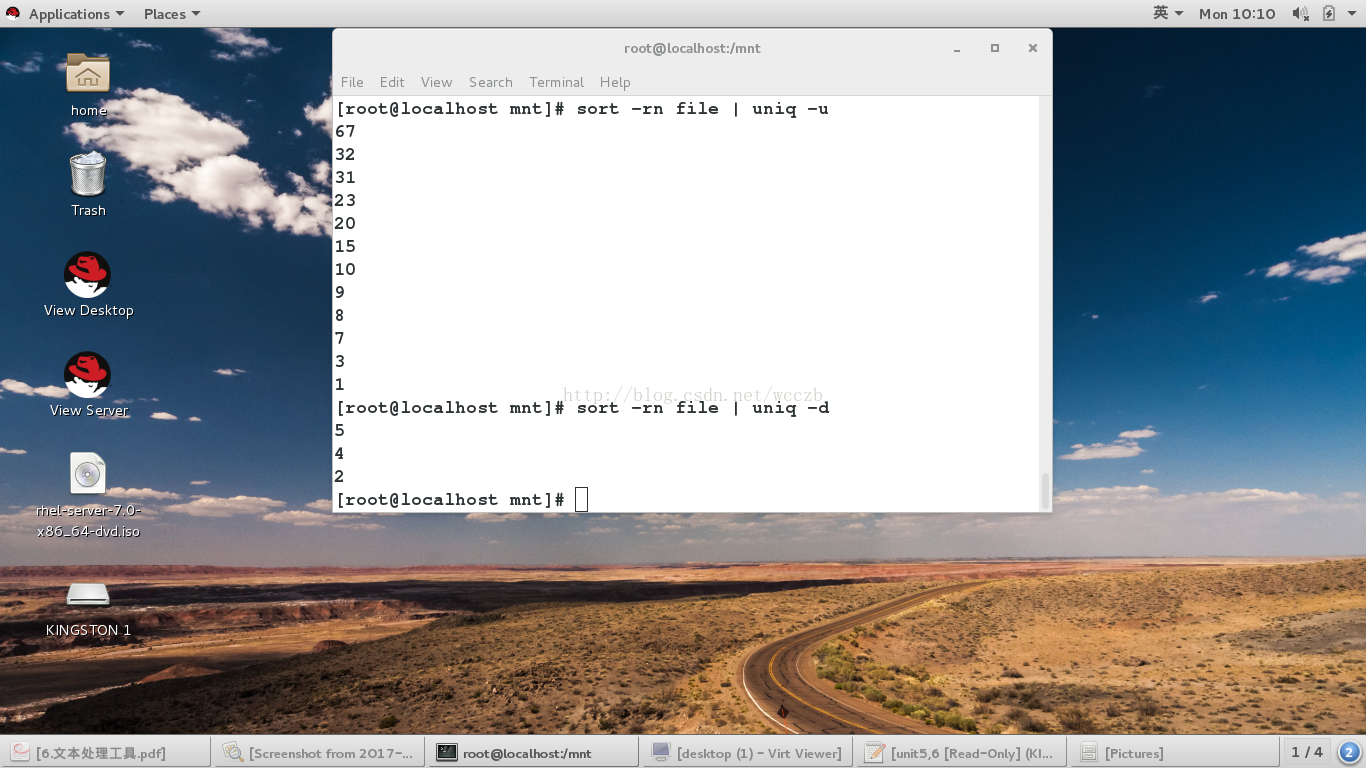
ex:取出内存占用率排在前五的PID

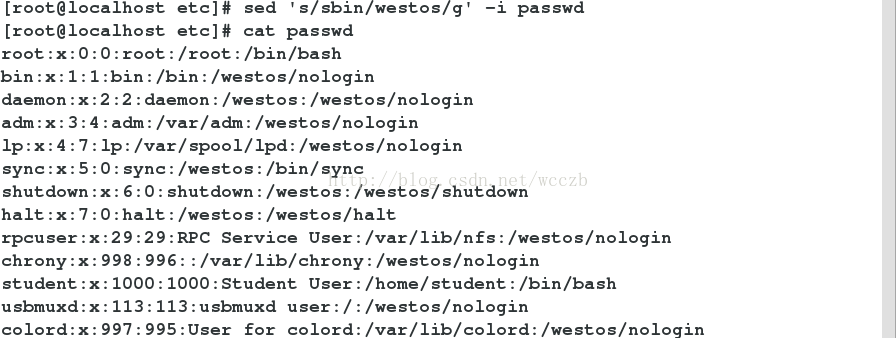
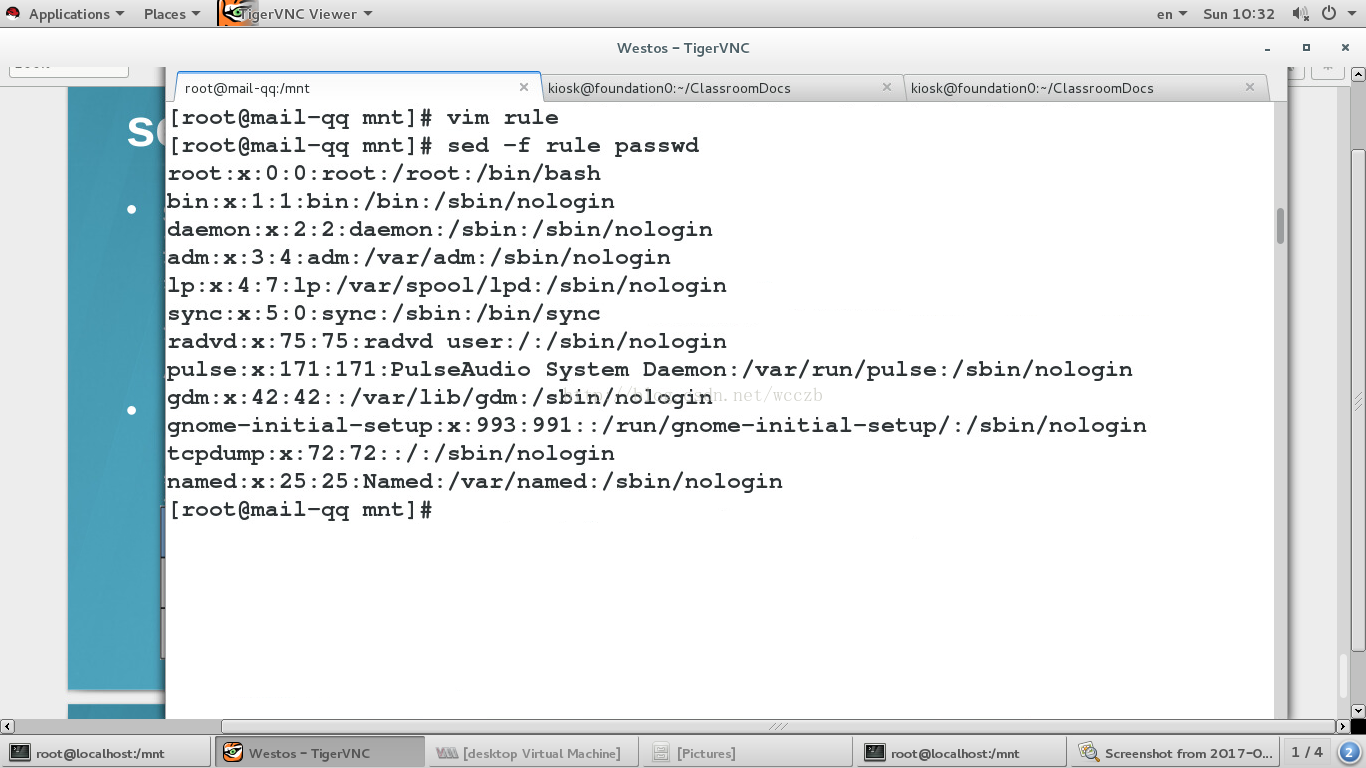
5.sed 命令
• sed 命令是流编辑器 , 用于对文本数据流执行编辑。假定要处理一个文件名 , sed 将对文件中的所有行执行搜索和替换 , 以将修改后的数据发送到标准输出 ; 即 , 其实际上并不修改现有文件。与 grep 一样 , sed 通常在管道使用
• 由于 sed 命令通常包含可以解释为 shell 元字符的字符 ,因此请按下面示例所示引用 sed 命令。默认情况下 , sed对文件中的所有行执行操作。在提供 sed 时 , 可带有地址。
sed ##控制流输出
sed 's/sbin/westos/g' -i passwd##替换输出中的nologin为westos
sed '1,5s/nologin/linux/g' -i passwd ##替换输出中1-3行的nologin为linux
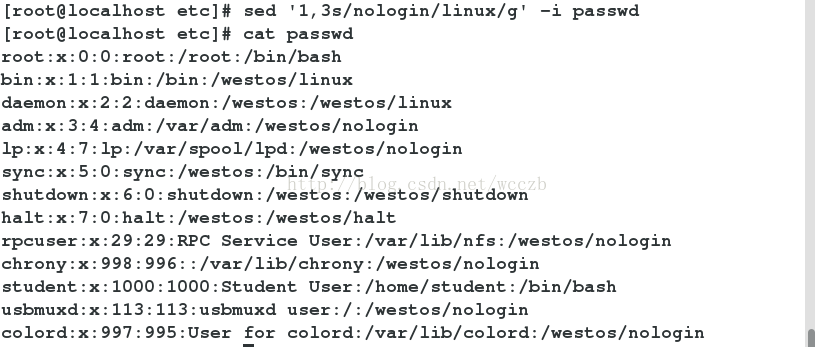
sed -e 's/westos/redhat/g' -e 's/nologin/hihi/g' -i passwd ##多条替换策略用-e连接
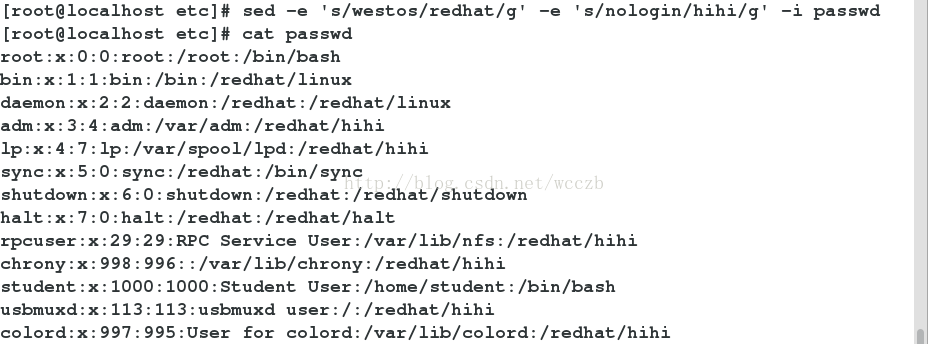
sed 3p file ##重复显示文件中的3行
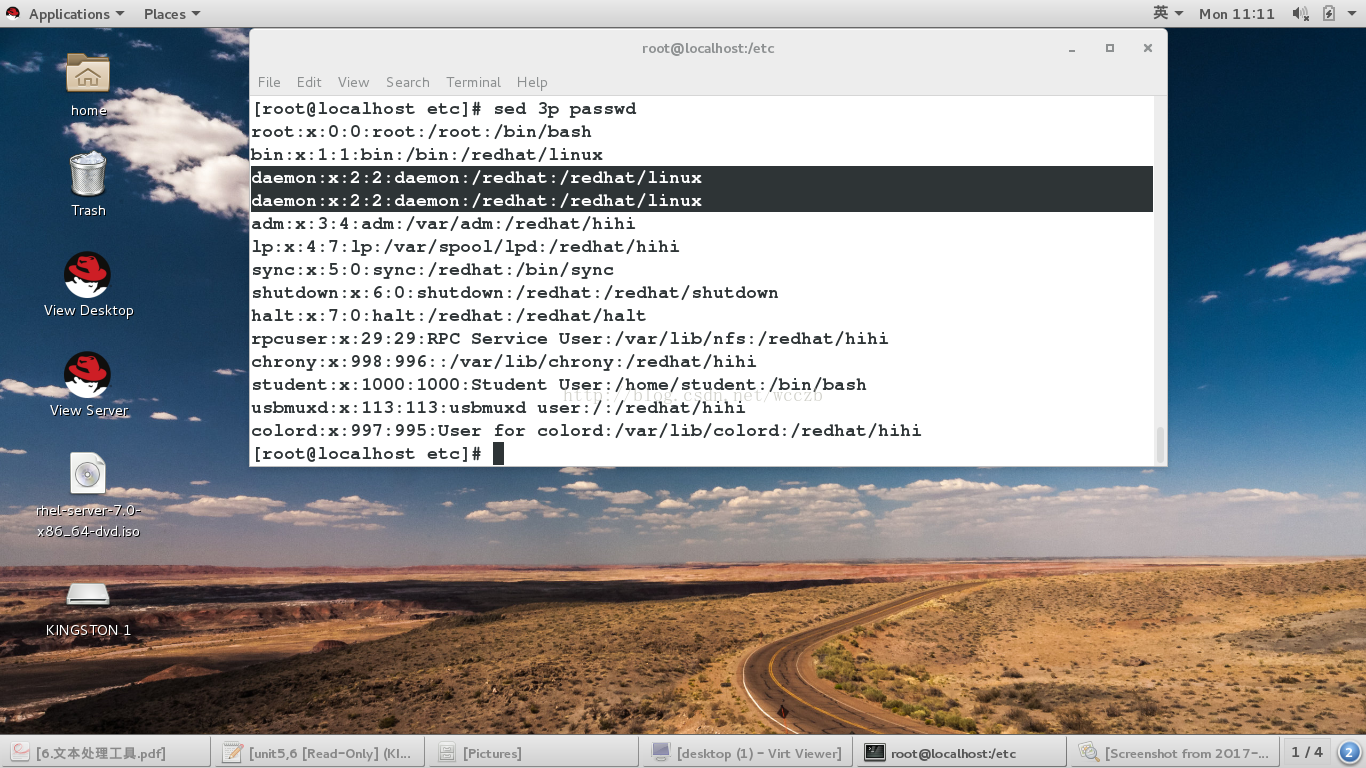
sed -n 2,4p file ##只显示文件中的3-7行

1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/lee/westos
3 daemon:x:2:2:daemon:/lee:/lee/westos
4 adm:x:3:4:adm:/var/adm:/lee/westos
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









