







本来针对上几篇,以为自己已经可以写一些OpenCL程序了。但就是不知道怎么优化达到最快,怎么合理分配device上的资源使程序最优,于是请教大神,大神说先看完OpenCL-SDK再说!于是我开始看。下载地址 https://developer.nvidia.com/opencl 下载对应版本 我的是linux。下载好后,我是按照 http://developer.download.nvidia.com/compute/cuda/3_0/sdk/website/OpenCL/website/samples.html#oclDeviceQuery 这个中的顺序开始学习的。
一、Device Query和BandWidth-Test
中间出现过报错“ more undefined references to 'shrLog' follow” 类似这种报错。解决办法:将cmd_arg_reader.cpp oclUtils.cpp shrUtils.cpp连其头文件都包含进这个工程,或者者不加这些cpp但要包含进各自的lib进来,一样的道理。
我的机器的结果:
[root@localhost Debug]# ./Device_Query
[Nvidia_SDK_multiThreads] starting...
./Nvidia_SDK_multiThreads Starting...
OpenCL SW Info:
CL_PLATFORM_NAME: NVIDIA CUDA
CL_PLATFORM_VERSION: OpenCL 1.2 CUDA 8.0.0
OpenCL SDK Revision: 7027912
OpenCL Device Info:
1 devices found supporting OpenCL:
---------------------------------
Device GeForce GTX 750 Ti
---------------------------------
CL_DEVICE_NAME: GeForce GTX 750 Ti
CL_DEVICE_VENDOR: NVIDIA Corporation
CL_DRIVER_VERSION: 375.39
CL_DEVICE_VERSION: OpenCL 1.2 CUDA
CL_DEVICE_OPENCL_C_VERSION: OpenCL C 1.2
CL_DEVICE_TYPE: CL_DEVICE_TYPE_GPU
CL_DEVICE_MAX_COMPUTE_UNITS: 5
CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS: 3
CL_DEVICE_MAX_WORK_ITEM_SIZES: 1024 / 1024 / 64
CL_DEVICE_MAX_WORK_GROUP_SIZE: 1024
CL_DEVICE_MAX_CLOCK_FREQUENCY: 1150 MHz
CL_DEVICE_ADDRESS_BITS: 64
CL_DEVICE_MAX_MEM_ALLOC_SIZE: 500 MByte
CL_DEVICE_GLOBAL_MEM_SIZE: 2000 MByte
CL_DEVICE_ERROR_CORRECTION_SUPPORT: no
CL_DEVICE_LOCAL_MEM_TYPE: local
CL_DEVICE_LOCAL_MEM_SIZE: 48 KByte
CL_DEVICE_MAX_CONSTANT_BUFFER_SIZE: 64 KByte
CL_DEVICE_QUEUE_PROPERTIES: CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE
CL_DEVICE_QUEUE_PROPERTIES: CL_QUEUE_PROFILING_ENABLE
CL_DEVICE_IMAGE_SUPPORT: 1
CL_DEVICE_MAX_READ_IMAGE_ARGS: 256
CL_DEVICE_MAX_WRITE_IMAGE_ARGS: 16
CL_DEVICE_SINGLE_FP_CONFIG: denorms INF-quietNaNs round-to-nearest round-to-zero round-to-inf fma
CL_DEVICE_IMAGE <dim> 2D_MAX_WIDTH 16384
2D_MAX_HEIGHT 16384
3D_MAX_WIDTH 4096
3D_MAX_HEIGHT 4096
3D_MAX_DEPTH 4096
CL_DEVICE_EXTENSIONS: cl_khr_global_int32_base_atomics
cl_khr_global_int32_extended_atomics
cl_khr_local_int32_base_atomics
cl_khr_local_int32_extended_atomics
cl_khr_fp64
cl_khr_byte_addressable_store
cl_khr_icd
cl_khr_gl_sharing
cl_nv_compiler_options
cl_nv_device_attribute_query
cl_nv_pragma_unroll
CL_DEVICE_COMPUTE_CAPABILITY_NV: 5.0
NUMBER OF MULTIPROCESSORS: 5
MapSMtoCores SM 5.0 is undefined (please update to the latest SDK)!
NUMBER OF CUDA CORES: 4294967291
CL_DEVICE_REGISTERS_PER_BLOCK_NV: 65536
CL_DEVICE_WARP_SIZE_NV: 32
CL_DEVICE_GPU_OVERLAP_NV: CL_TRUE
CL_DEVICE_KERNEL_EXEC_TIMEOUT_NV: CL_TRUE
CL_DEVICE_INTEGRATED_MEMORY_NV: CL_FALSE
CL_DEVICE_PREFERRED_VECTOR_WIDTH_<t> CHAR 1, SHORT 1, INT 1, LONG 1, FLOAT 1, DOUBLE 1
---------------------------------
2D Image Formats Supported (75)
---------------------------------
# Channel Order Channel Type
1 CL_R CL_FLOAT
2 CL_R CL_HALF_FLOAT
3 CL_R CL_UNORM_INT8
4 CL_R CL_UNORM_INT16
5 CL_R CL_SNORM_INT16
6 CL_R CL_SIGNED_INT8
7 CL_R CL_SIGNED_INT16
8 CL_R CL_SIGNED_INT32
9 CL_R CL_UNSIGNED_INT8
10 CL_R CL_UNSIGNED_INT16
11 CL_R CL_UNSIGNED_INT32
12 CL_A CL_FLOAT
13 CL_A CL_HALF_FLOAT
14 CL_A CL_UNORM_INT8
15 CL_A CL_UNORM_INT16
16 CL_A CL_SNORM_INT16
17 CL_A CL_SIGNED_INT8
18 CL_A CL_SIGNED_INT16
19 CL_A CL_SIGNED_INT32
20 CL_A CL_UNSIGNED_INT8
21 CL_A CL_UNSIGNED_INT16
22 CL_A CL_UNSIGNED_INT32
23 CL_RG CL_FLOAT
24 CL_RG CL_HALF_FLOAT
25 CL_RG CL_UNORM_INT8
26 CL_RG CL_UNORM_INT16
27 CL_RG CL_SNORM_INT16
28 CL_RG CL_SIGNED_INT8
29 CL_RG CL_SIGNED_INT16
30 CL_RG CL_SIGNED_INT32
31 CL_RG CL_UNSIGNED_INT8
32 CL_RG CL_UNSIGNED_INT16
33 CL_RG CL_UNSIGNED_INT32
34 CL_RA CL_FLOAT
35 CL_RA CL_HALF_FLOAT
36 CL_RA CL_UNORM_INT8
37 CL_RA CL_UNORM_INT16
38 CL_RA CL_SNORM_INT16
39 CL_RA CL_SIGNED_INT8
40 CL_RA CL_SIGNED_INT16
41 CL_RA CL_SIGNED_INT32
42 CL_RA CL_UNSIGNED_INT8
43 CL_RA CL_UNSIGNED_INT16
44 CL_RA CL_UNSIGNED_INT32
45 CL_RGBA CL_FLOAT
46 CL_RGBA CL_HALF_FLOAT
47 CL_RGBA CL_UNORM_INT8
48 CL_RGBA CL_UNORM_INT16
49 CL_RGBA CL_SNORM_INT16
50 CL_RGBA CL_SIGNED_INT8
51 CL_RGBA CL_SIGNED_INT16
52 CL_RGBA CL_SIGNED_INT32
53 CL_RGBA CL_UNSIGNED_INT8
54 CL_RGBA CL_UNSIGNED_INT16
55 CL_RGBA CL_UNSIGNED_INT32
56 CL_BGRA CL_UNORM_INT8
57 CL_BGRA CL_SIGNED_INT8
58 CL_BGRA CL_UNSIGNED_INT8
59 CL_ARGB CL_UNORM_INT8
60 CL_ARGB CL_SIGNED_INT8
61 CL_ARGB CL_UNSIGNED_INT8
62 CL_INTENSITY CL_FLOAT
63 CL_INTENSITY CL_HALF_FLOAT
64 CL_INTENSITY CL_UNORM_INT8
65 CL_INTENSITY CL_UNORM_INT16
66 CL_INTENSITY CL_SNORM_INT16
67 CL_LUMINANCE CL_FLOAT
68 CL_LUMINANCE CL_HALF_FLOAT
69 CL_LUMINANCE CL_UNORM_INT8
70 CL_LUMINANCE CL_UNORM_INT16
71 CL_LUMINANCE CL_SNORM_INT16
72 CL_BGRA CL_SNORM_INT8
73 CL_BGRA CL_SNORM_INT16
74 CL_ARGB CL_SNORM_INT8
75 CL_ARGB CL_SNORM_INT16
---------------------------------
3D Image Formats Supported (75)
---------------------------------
# Channel Order Channel Type
1 CL_R CL_FLOAT
2 CL_R CL_HALF_FLOAT
3 CL_R CL_UNORM_INT8
4 CL_R CL_UNORM_INT16
5 CL_R CL_SNORM_INT16
6 CL_R CL_SIGNED_INT8
7 CL_R CL_SIGNED_INT16
8 CL_R CL_SIGNED_INT32
9 CL_R CL_UNSIGNED_INT8
10 CL_R CL_UNSIGNED_INT16
11 CL_R CL_UNSIGNED_INT32
12 CL_A CL_FLOAT
13 CL_A CL_HALF_FLOAT
14 CL_A CL_UNORM_INT8
15 CL_A CL_UNORM_INT16
16 CL_A CL_SNORM_INT16
17 CL_A CL_SIGNED_INT8
18 CL_A CL_SIGNED_INT16
19 CL_A CL_SIGNED_INT32
20 CL_A CL_UNSIGNED_INT8
21 CL_A CL_UNSIGNED_INT16
22 CL_A CL_UNSIGNED_INT32
23 CL_RG CL_FLOAT
24 CL_RG CL_HALF_FLOAT
25 CL_RG CL_UNORM_INT8
26 CL_RG CL_UNORM_INT16
27 CL_RG CL_SNORM_INT16
28 CL_RG CL_SIGNED_INT8
29 CL_RG CL_SIGNED_INT16
30 CL_RG CL_SIGNED_INT32
31 CL_RG CL_UNSIGNED_INT8
32 CL_RG CL_UNSIGNED_INT16
33 CL_RG CL_UNSIGNED_INT32
34 CL_RA CL_FLOAT
35 CL_RA CL_HALF_FLOAT
36 CL_RA CL_UNORM_INT8
37 CL_RA CL_UNORM_INT16
38 CL_RA CL_SNORM_INT16
39 CL_RA CL_SIGNED_INT8
40 CL_RA CL_SIGNED_INT16
41 CL_RA CL_SIGNED_INT32
42 CL_RA CL_UNSIGNED_INT8
43 CL_RA CL_UNSIGNED_INT16
44 CL_RA CL_UNSIGNED_INT32
45 CL_RGBA CL_FLOAT
46 CL_RGBA CL_HALF_FLOAT
47 CL_RGBA CL_UNORM_INT8
48 CL_RGBA CL_UNORM_INT16
49 CL_RGBA CL_SNORM_INT16
50 CL_RGBA CL_SIGNED_INT8
51 CL_RGBA CL_SIGNED_INT16
52 CL_RGBA CL_SIGNED_INT32
53 CL_RGBA CL_UNSIGNED_INT8
54 CL_RGBA CL_UNSIGNED_INT16
55 CL_RGBA CL_UNSIGNED_INT32
56 CL_BGRA CL_UNORM_INT8
57 CL_BGRA CL_SIGNED_INT8
58 CL_BGRA CL_UNSIGNED_INT8
59 CL_ARGB CL_UNORM_INT8
60 CL_ARGB CL_SIGNED_INT8
61 CL_ARGB CL_UNSIGNED_INT8
62 CL_INTENSITY CL_FLOAT
63 CL_INTENSITY CL_HALF_FLOAT
64 CL_INTENSITY CL_UNORM_INT8
65 CL_INTENSITY CL_UNORM_INT16
66 CL_INTENSITY CL_SNORM_INT16
67 CL_LUMINANCE CL_FLOAT
68 CL_LUMINANCE CL_HALF_FLOAT
69 CL_LUMINANCE CL_UNORM_INT8
70 CL_LUMINANCE CL_UNORM_INT16
71 CL_LUMINANCE CL_SNORM_INT16
72 CL_BGRA CL_SNORM_INT8
73 CL_BGRA CL_SNORM_INT16
74 CL_ARGB CL_SNORM_INT8
75 CL_ARGB CL_SNORM_INT16
oclDeviceQuery, Platform Name = NVIDIA CUDA, Platform Version = OpenCL 1.2 CUDA 8.0.0, SDK Revision = 7027912, NumDevs = 1, Device = GeForce GTX 750 Ti
System Info:
[Nvidia_SDK_multiThreads] test results...
PASSED
> exiting in 3 seconds: 3...2...1...done!
[root@localhost Debug]# ./BandWidth_test
Running on...
GeForce GTX 750 Ti
Quick Mode
shrDeltaT returning early
shrDeltaT returning early
Host to Device Bandwidth, 1 Device(s), Paged memory, direct access
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 inf
shrDeltaT returning early
shrDeltaT returning early
Device to Host Bandwidth, 1 Device(s), Paged memory, direct access
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 inf
shrDeltaT returning early
shrDeltaT returning early
Device to Device Bandwidth, 1 Device(s)
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 inf
[Nvidia_SDK_multiThreads] test results...
PASSED
> exiting in 3 seconds: 3...2...1...done!二、vector-addition
这个工程之前包括别人的博客上已经写过多次,但我从这个开始要慢慢学习分配NDRange workgroup优化这些。所以也开始细看,思考SDK上为什么这样分配等。
#include <CL/cl.h>
#include <stdlib.h>
#include <stdio.h>
#include <vector>
#include <string.h>
//the 3rd NVIDIA-OPENCL-SDK-CODE-SAMPLE:vector_add!
//NVIDIA-OPENCL-SDK已经将很多功能封装在这两个类里了,经常要用到这两个头文件!
#include "oclUtils.h"
#include "shrQATest.h"
const char* cSourceFile = "VectorAdd.cl";
void *srcA, *srcB, *dst;
void* Golden;
cl_context cxGPUContext; // OpenCL context
cl_command_queue cqCommandQueue;// OpenCL command que
cl_platform_id cpPlatform; // OpenCL platform
cl_device_id cdDevice; // OpenCL device
cl_program cpProgram; // OpenCL program
cl_kernel ckKernel; // OpenCL kernel
cl_mem cmDevSrcA; // OpenCL device source buffer A
cl_mem cmDevSrcB; // OpenCL device source buffer B
cl_mem cmDevDst; // OpenCL device destination buffer
size_t szGlobalWorkSize; // 1D var for Total # of work items
size_t szLocalWorkSize; // 1D var for # of work items in the work group
size_t szParmDataBytes; // Byte size of context information
size_t szKernelLength; // Byte size of kernel code
cl_int ciErr1, ciErr2; // Error code var
char* cPathAndName = NULL; // var for full paths to data, src, etc.
char* cSourceCL = NULL; // Buffer to hold source for compilation
const char* cExecutableName = NULL;
//两个数组各自的实际大小
int iNumElements = 11444777;
shrBOOL bNoPrompt = shrFALSE;
void VectorAddHost(const float* pfData1, const float* pfData2, float* pfResult, int iNumElements);
void Cleanup (int argc, char **argv, int iExitCode);
int main(int argc, char **argv)
{
//获得工程的名字
shrQAStart(argc, argv);
bNoPrompt = shrCheckCmdLineFlag(argc, (const char**)argv, "noprompt");
//将工程的打印结果保存为txt文件
cExecutableName = argv[0];
shrSetLogFileName ("oclVectorAdd.txt");
shrLog("%s Starting...\n\n# of float elements per Array \t= %i\n", argv[0], iNumElements);
//11444777本来是实际所需大小,因设定工作组大小256,为了取整设置了11444992个全局工作项,即44707个工作组
szLocalWorkSize = 256;
szGlobalWorkSize = shrRoundUp((int)szLocalWorkSize, iNumElements); //计算取整后的全局工作项个数 即大小
shrLog("Global Work Size \t\t= %u\nLocal Work Size \t\t= %u\n# of Work Groups \t\t= %u\n\n",
szGlobalWorkSize, szLocalWorkSize, (szGlobalWorkSize % szLocalWorkSize + szGlobalWorkSize/szLocalWorkSize));
//host端的三个参数的大小
shrLog( "Allocate and Init Host Mem...\n");
srcA = (void *)malloc(sizeof(cl_float) * szGlobalWorkSize);
srcB = (void *)malloc(sizeof(cl_float) * szGlobalWorkSize);
dst = (void *)malloc(sizeof(cl_float) * szGlobalWorkSize);
Golden = (void *)malloc(sizeof(cl_float) * iNumElements);
//用随机数初始化两个待加数组,实际初始化11444777个就行了。
shrFillArray((float*)srcA, iNumElements);
shrFillArray((float*)srcB, iNumElements);
ciErr1 = clGetPlatformIDs(1, &cpPlatform, NULL);
shrLog("clGetPlatformID...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clGetPlatformID, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
ciErr1 = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 1, &cdDevice, NULL);
shrLog("clGetDeviceIDs...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clGetDeviceIDs, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
cxGPUContext = clCreateContext(0, 1, &cdDevice, NULL, NULL, &ciErr1);
shrLog("clCreateContext...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clCreateContext, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
cqCommandQueue = clCreateCommandQueue(cxGPUContext, cdDevice, 0, &ciErr1);
shrLog("clCreateCommandQueue...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clCreateCommandQueue, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
cmDevSrcA = clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY, sizeof(cl_float) * szGlobalWorkSize, NULL, &ciErr1);
cmDevSrcB = clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY, sizeof(cl_float) * szGlobalWorkSize, NULL, &ciErr2);
ciErr1 |= ciErr2;
cmDevDst = clCreateBuffer(cxGPUContext, CL_MEM_WRITE_ONLY, sizeof(cl_float) * szGlobalWorkSize, NULL, &ciErr2);
ciErr1 |= ciErr2;
shrLog("clCreateBuffer...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clCreateBuffer, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
//用这个读kernel方便多了,之前都是另写一个函数读的
shrLog("oclLoadProgSource (%s)...\n", cSourceFile);
cPathAndName = shrFindFilePath(cSourceFile, argv[0]);
cSourceCL = oclLoadProgSource(cPathAndName, "", &szKernelLength);
//后面的和之前学的就几乎一样了,很简单了没什么看的
cpProgram = clCreateProgramWithSource(cxGPUContext, 1, (const char **)&cSourceCL, &szKernelLength, &ciErr1);
shrLog("clCreateProgramWithSource...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clCreateProgramWithSource, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
#ifdef MAC
char* flags = "-cl-fast-relaxed-math -DMAC";
#else
char* flags = "-cl-fast-relaxed-math";
#endif
ciErr1 = clBuildProgram(cpProgram, 0, NULL, NULL, NULL, NULL);
shrLog("clBuildProgram...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clBuildProgram, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
ckKernel = clCreateKernel(cpProgram, "VectorAdd", &ciErr1);
shrLog("clCreateKernel (VectorAdd)...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clCreateKernel, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
ciErr1 = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&cmDevSrcA);
ciErr1 |= clSetKernelArg(ckKernel, 1, sizeof(cl_mem), (void*)&cmDevSrcB);
ciErr1 |= clSetKernelArg(ckKernel, 2, sizeof(cl_mem), (void*)&cmDevDst);
ciErr1 |= clSetKernelArg(ckKernel, 3, sizeof(cl_int), (void*)&iNumElements);
shrLog("clSetKernelArg 0 - 3...\n\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clSetKernelArg, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
ciErr1 = clEnqueueWriteBuffer(cqCommandQueue, cmDevSrcA, CL_FALSE, 0, sizeof(cl_float) * szGlobalWorkSize, srcA, 0, NULL, NULL);
ciErr1 |= clEnqueueWriteBuffer(cqCommandQueue, cmDevSrcB, CL_FALSE, 0, sizeof(cl_float) * szGlobalWorkSize, srcB, 0, NULL, NULL);
shrLog("clEnqueueWriteBuffer (SrcA and SrcB)...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clEnqueueWriteBuffer, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
//它用的最简单的一维 为什么不用一块一块的workgroup去算呢 一维寻址最快?
ciErr1 = clEnqueueNDRangeKernel(cqCommandQueue, ckKernel, 1, NULL, &szGlobalWorkSize, &szLocalWorkSize, 0, NULL, NULL);
shrLog("clEnqueueNDRangeKernel (VectorAdd)...\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clEnqueueNDRangeKernel, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
ciErr1 = clEnqueueReadBuffer(cqCommandQueue, cmDevDst, CL_TRUE, 0, sizeof(cl_float) * szGlobalWorkSize, dst, 0, NULL, NULL);
shrLog("clEnqueueReadBuffer (Dst)...\n\n");
if (ciErr1 != CL_SUCCESS)
{
shrLog("Error in clEnqueueReadBuffer, Line %u in file %s !!!\n\n", __LINE__, __FILE__);
Cleanup(argc, argv, EXIT_FAILURE);
}
//将GPU结果与CPU结果对比 一致则正确 否则错误
shrLog("Comparing against Host/C++ computation...\n\n");
VectorAddHost ((const float*)srcA, (const float*)srcB, (float*)Golden, iNumElements);
shrBOOL bMatch = shrComparefet((const float*)Golden, (const float*)dst, (unsigned int)iNumElements, 0.0f, 0);
Cleanup (argc, argv, (bMatch == shrTRUE) ? EXIT_SUCCESS : EXIT_FAILURE);
}三、DotProduct点乘
下载这个工程:https://pan.baidu.com/s/1pLJNAjD
kernel文件:
__kernel void DotProduct (__global float* a, __global float* b, __global float* c, int iNumElements)
{
// find position in global arrays
int iGID = get_global_id(0);
// bound check (equivalent to the limit on a 'for' loop for standard/serial C code
if (iGID >= iNumElements)
{
return;
}
// process
int iInOffset = iGID << 2; //*4
c[iGID] = a[iInOffset] * b[iInOffset]+ a[iInOffset + 1] * b[iInOffset + 1]+ a[iInOffset + 2] * b[iInOffset + 2]+ a[iInOffset + 3] * b[iInOffset + 3];
//c[iGID] = a[iGID] * b[iGID]+ a[iGID + 1] * b[iGID + 1]+ a[iGID + 2] * b[iGID + 2]+ a[iGID + 3] * b[iGID + 3];
}#include <CL/cl.h>
#include <stdlib.h>
#include <stdio.h>
#include <vector>
#include <string.h>
#include "oclUtils.h"
#include "shrQATest.h"
// Name of the file with the source code for the computation kernel
// *********************************************************************
const char* cSourceFile = "DotProduct.cl";
// Host buffers for demo
// *********************************************************************
void *srcA, *srcB, *dst; // Host buffers for OpenCL test
void* Golden; // Host buffer for host golden processing cross check
// OpenCL Vars
cl_platform_id cpPlatform; // OpenCL platform
cl_device_id *cdDevices; // OpenCL device
cl_context cxGPUContext; // OpenCL context
cl_command_queue cqCommandQueue;// OpenCL command que
cl_program cpProgram; // OpenCL program
cl_kernel ckKernel; // OpenCL kernel
cl_mem cmDevSrcA; // OpenCL device source buffer A
cl_mem cmDevSrcB; // OpenCL device source buffer B
cl_mem cmDevDst; // OpenCL device destination buffer
size_t szGlobalWorkSize; // Total # of work items in the 1D range
size_t szLocalWorkSize; // # of work items in the 1D work group
size_t szParmDataBytes; // Byte size of context information
size_t szKernelLength; // Byte size of kernel code
cl_int ciErrNum; // Error code var
char* cPathAndName = NULL; // var for full paths to data, src, etc.
char* cSourceCL = NULL; // Buffer to hold source for compilation
const char* cExecutableName = NULL;
// demo config vars
int iNumElements= 1277944; // Length of float arrays to process (odd # for illustration)
shrBOOL bNoPrompt = shrFALSE;
// Forward Declarations
// *********************************************************************
void DotProductHost(const float* pfData1, const float* pfData2, float* pfResult, int iNumElements);
void Cleanup (int iExitCode);
void (*pCleanup)(int) = &Cleanup;
int *gp_argc = NULL;
char ***gp_argv = NULL;
// Main function
// *********************************************************************
int main(int argc, char **argv)
{
gp_argc = &argc;
gp_argv = &argv;
shrQAStart(argc, argv);
// start logs //不能像原工程那样放置,因为不会生成oclDotProduct.txt而是生成shrUtils类默认的SdkConsoleLog.txt!
cExecutableName = argv[0];
shrSetLogFileName ("oclDotProduct.txt");
shrLog("%s Starting...\n\n# of float elements per Array \t= %u\n", argv[0], iNumElements);
// Get the NVIDIA platform//这部分没什么看的,记录平台和设备信息
ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, NULL);
shrLog("clGetPlatformID...\n");
// Get the NVIDIA platform
ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, NULL);
shrLog("clGetPlatformID...\n");
//Get all the devices
cl_uint uiNumDevices = 0; // Number of devices available
cl_uint uiTargetDevice = 0; // Default Device to compute on
cl_uint uiNumComputeUnits; // Number of compute units (SM's on NV GPU)
shrLog("Get the Device info and select Device...\n");
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 0, NULL, &uiNumDevices);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, NULL);
cdDevices = (cl_device_id *)malloc(uiNumDevices * sizeof(cl_device_id) );
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, uiNumDevices, cdDevices, NULL);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, NULL);
// Get command line device options and config accordingly
shrLog(" # of Devices Available = %u\n", uiNumDevices);
if(shrGetCmdLineArgumentu(argc, (const char**)argv, "device", &uiTargetDevice)== shrTRUE)
{
uiTargetDevice = CLAMP(uiTargetDevice, 0, (uiNumDevices - 1));
}
shrLog(" Using Device %u: ", uiTargetDevice);
oclPrintDevName(LOGBOTH, cdDevices[uiTargetDevice]);
ciErrNum = clGetDeviceInfo(cdDevices[uiTargetDevice], CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(uiNumComputeUnits), &uiNumComputeUnits, NULL);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, NULL);
shrLog("\n # of Compute Units = %u\n", uiNumComputeUnits);
// get command line arg for quick test, if provided
bNoPrompt = shrCheckCmdLineFlag(argc, (const char**)argv, "noprompt");
// Get the NVIDIA platform
ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Get a GPU device
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 1, &cdDevices[uiTargetDevice], NULL);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Create the context
cxGPUContext = clCreateContext(0, 1, &cdDevices[uiTargetDevice], NULL, NULL, &ciErrNum);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Create a command-queue
shrLog("clCreateCommandQueue...\n");
cqCommandQueue = clCreateCommandQueue(cxGPUContext, cdDevices[uiTargetDevice], 0, &ciErrNum);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
//工作组的大小及全局工作项取整后的大小 4992*256=1277952
// set and log Global and Local work size dimensions
szLocalWorkSize = 256;
szGlobalWorkSize = shrRoundUp((int)szLocalWorkSize, iNumElements); // rounded up to the nearest multiple of the LocalWorkSize
shrLog("Global Work Size \t\t= %u\nLocal Work Size \t\t= %u\n# of Work Groups \t\t= %u\n\n",
szGlobalWorkSize, szLocalWorkSize, (szGlobalWorkSize % szLocalWorkSize + szGlobalWorkSize/szLocalWorkSize));
// Allocate and initialize host arrays
shrLog( "Allocate and Init Host Mem...\n");
srcA = (void *)malloc(sizeof(cl_float4) * szGlobalWorkSize);
srcB = (void *)malloc(sizeof(cl_float4) * szGlobalWorkSize);
dst = (void *)malloc(sizeof(cl_float) * szGlobalWorkSize);
Golden = (void *)malloc(sizeof(cl_float) * iNumElements);
shrFillArray((float*)srcA, 4 * iNumElements);
shrFillArray((float*)srcB, 4 * iNumElements);
// Allocate the OpenCL buffer memory objects for source and result on the device GMEM
shrLog("clCreateBuffer (SrcA, SrcB and Dst in Device GMEM)...\n");
cmDevSrcA = clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY, sizeof(cl_float) * szGlobalWorkSize * 4, NULL, &ciErrNum);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
cmDevSrcB = clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY, sizeof(cl_float) * szGlobalWorkSize * 4, NULL, &ciErrNum);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
cmDevDst = clCreateBuffer(cxGPUContext, CL_MEM_WRITE_ONLY, sizeof(cl_float) * szGlobalWorkSize, NULL, &ciErrNum);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Read the OpenCL kernel in from source file
shrLog("oclLoadProgSource (%s)...\n", cSourceFile);
cPathAndName = shrFindFilePath(cSourceFile, argv[0]);
oclCheckErrorEX(cPathAndName != NULL, shrTRUE, pCleanup);
cSourceCL = oclLoadProgSource(cPathAndName, "", &szKernelLength);
oclCheckErrorEX(cSourceCL != NULL, shrTRUE, pCleanup);
// Create the program
shrLog("clCreateProgramWithSource...\n");
cpProgram = clCreateProgramWithSource(cxGPUContext, 1, (const char **)&cSourceCL, &szKernelLength, &ciErrNum);
// Build the program with 'mad' Optimization option
#ifdef MAC
char* flags = "-cl-fast-relaxed-math -DMAC";
#else
char* flags = "-cl-fast-relaxed-math";
#endif
shrLog("clBuildProgram...\n");
ciErrNum = clBuildProgram(cpProgram, 0, NULL, NULL, NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
// write out standard error, Build Log and PTX, then cleanup and exit
shrLogEx(LOGBOTH | ERRORMSG, ciErrNum, STDERROR);
oclLogBuildInfo(cpProgram, oclGetFirstDev(cxGPUContext));
oclLogPtx(cpProgram, oclGetFirstDev(cxGPUContext), "oclDotProduct.ptx");
Cleanup(EXIT_FAILURE);
}
// Create the kernel
shrLog("clCreateKernel (DotProduct)...\n");
ckKernel = clCreateKernel(cpProgram, "DotProduct", &ciErrNum);
// Set the Argument values
shrLog("clSetKernelArg 0 - 3...\n\n");
ciErrNum = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&cmDevSrcA);
ciErrNum |= clSetKernelArg(ckKernel, 1, sizeof(cl_mem), (void*)&cmDevSrcB);
ciErrNum |= clSetKernelArg(ckKernel, 2, sizeof(cl_mem), (void*)&cmDevDst);
ciErrNum |= clSetKernelArg(ckKernel, 3, sizeof(cl_int), (void*)&iNumElements);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Asynchronous write of data to GPU device
shrLog("clEnqueueWriteBuffer (SrcA and SrcB)...\n");
ciErrNum = clEnqueueWriteBuffer(cqCommandQueue, cmDevSrcA, CL_FALSE, 0, sizeof(cl_float) * szGlobalWorkSize * 4, srcA, 0, NULL, NULL);
ciErrNum |= clEnqueueWriteBuffer(cqCommandQueue, cmDevSrcB, CL_FALSE, 0, sizeof(cl_float) * szGlobalWorkSize * 4, srcB, 0, NULL, NULL);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Launch kernel
shrLog("clEnqueueNDRangeKernel (DotProduct)...\n");
ciErrNum = clEnqueueNDRangeKernel(cqCommandQueue, ckKernel, 1, NULL, &szGlobalWorkSize, &szLocalWorkSize, 0, NULL, NULL);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Read back results and check accumulated errors
shrLog("clEnqueueReadBuffer (Dst)...\n\n");
ciErrNum = clEnqueueReadBuffer(cqCommandQueue, cmDevDst, CL_TRUE, 0, sizeof(cl_float) * szGlobalWorkSize, dst, 0, NULL, NULL);
oclCheckErrorEX(ciErrNum, CL_SUCCESS, pCleanup);
// Compute and compare results for golden-host and report errors and pass/fail
shrLog("Comparing against Host/C++ computation...\n\n");
DotProductHost ((const float*)srcA, (const float*)srcB, (float*)Golden, iNumElements);
shrBOOL bMatch = shrComparefet((const float*)Golden, (const float*)dst, (unsigned int)iNumElements, 0.0f, 0);
// Cleanup and leave
Cleanup (EXIT_SUCCESS);
}这个例子没太多说的,目的是类似点乘:
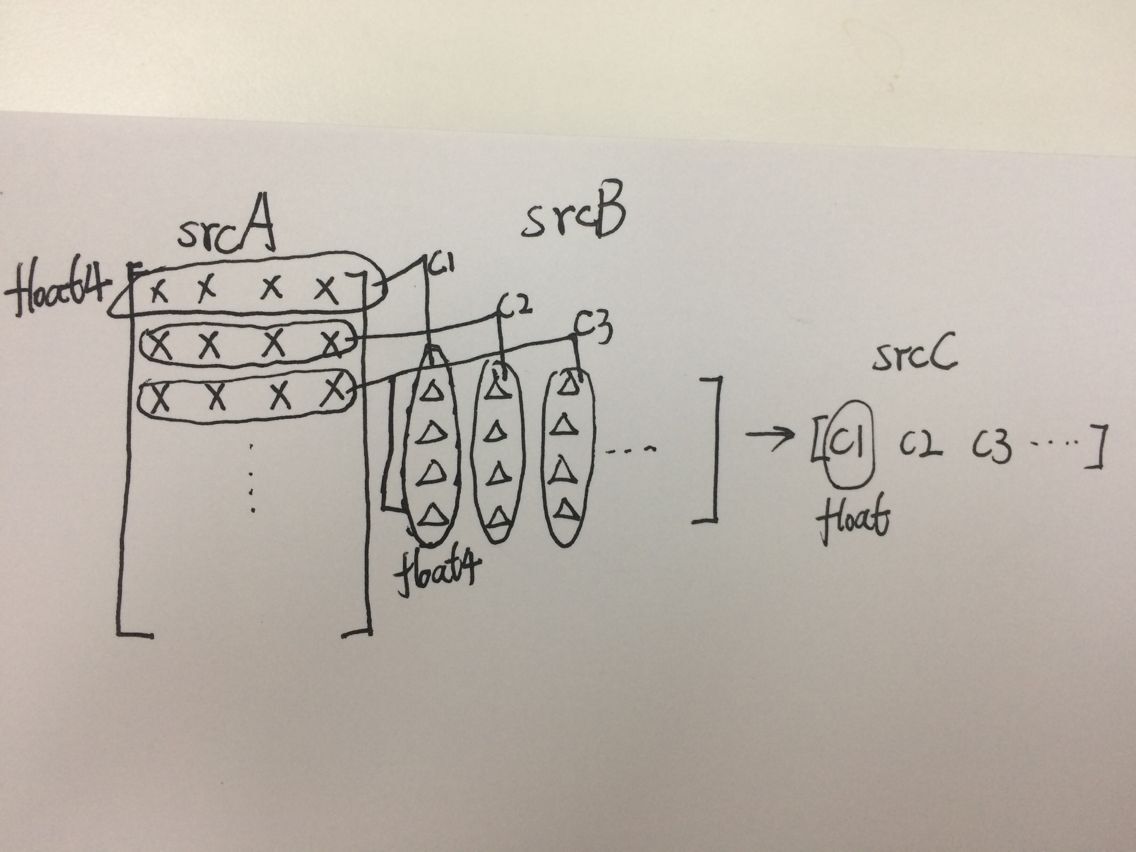
2、workgroupsize很喜欢设置成256,不知道为什么;
3、原来kernel里iGID<<2的意思就是左移2位就是乘以4的意思,大神说不建议用移位操作符,直接写成*4还好一些;
4、有个疑问:kernel里为什么不用c[iGID] = a[iGID] * b[iGID]+ a[iGID + 1] * b[iGID + 1]+ a[iGID + 2] * b[iGID + 2]+ a[iGID + 3] * b[iGID + 3];??用这个结果是错的,为什么?大神解说后明白:原来重叠了。的确重叠了每个float4的后3个数!从彩色直方图开始形成了思维定式:觉得getglobalID得到的只是位置,只是用来帮助数数,而不是真正的和数组对应处的位置。所以我才在这里以为每个kernel里只要计算出float4*float4就行了。当初计算彩色直方图时,源码意思是每个(比如第一个)workgroup里某个(比如第一个)workitem去叫后面3个workgroup对应位置的3个workitem(也就是第二个workgroup的第一个workitem、第三个workgroup的第一个workitem、第四个workgroup的第一个workitem)来帮它(第一个workgroup)计算其局部直方图结果的对应位置;而第二个workgroup里第一个workitem也会叫它后面对应位置的3个workitem(也就是第三个workgroup的第一个workitem、第四个workgroup的第一个workitem、第五个workgroup的第一个workitem)来帮它(第二个workgroup)计算其局部直方图结果的对应位置。。。以此类推,这里也重叠了,所以我当时就形成了getglobalID得到的workitem的ID只是为了辅助计算,而不是真正对应到数组数值。
但对应于当前特定的workgroup的局部直方图结果的计算中,又不是重叠的,workitem又是真正对应数组中的确切位置而且不重叠的。
所以我是分不清什么时候能使用重叠什么时候不能?
大神说我没有完全理解OpenCL“分而治之”的思想......再次被骂得狗血淋头.......我明白了的确如他所说,我又犯了计算彩色直方图时的那个错误:
http://bbs.gpuworld.cn/forum.php?mod=viewthread&tid=10651&extra=&page=1
我又想了很久:之前计算直方图中 每个workgroup上的局部直方图结果是local类型的,只被自己的workgroup共享,所以这个局部结果计算时可以借用其它workgroup的ID;而第二个workgroup的局部直方图结果计算时也借用了自己的和后面别的workgroup的ID,所以即使这两次计算有重复重叠的也没有关系?而我这次的2个float4型的向量a、b的点乘,这2个向量都是global型,所以a[0]*b[0]+a[1]*b[1]+a[2]*b[2]+a[3]*b[3]与第二个线程的a[1]*b[1]+a[2]*b[2]+a[3]*b[3]+a[4]*b[4] 这个的前三个和上面的后三个实实在在的代表了一样的数 !而不是像计算直方图中即使下标(线程ID)一样 也就是有重复 但代表的不是一样的数!
另外我刚刚看到大神说的 :workgroup里的计算时高速的,特别是原子操作在local workitem上特别快!而global变量的计算是直接在慢速的显存上很慢!
有人问为什么计算直方图的例子中 globalsize为什么不设置成height*width?我的回答是“在计算局部直方图时,也就是第二个for循环里是+=get_global_size也就是+=1024 这里是串行的,而有多个这样子的串行同时进行,也就是并行了。如果设置成height*width那就是height*width个串行了 没有并行的 岂不是比前者慢。” 大神的回答是“这样的话, 每个group内部, 在高速的CU内部的LDS上进行累加. 这也是为何要分开进行。每个group都在内部的小高速内存上(LDS)进行累加, 这种显然不能正好一个, 例如256个group, 就计算256个数据的值, 那样将无意义(将变成等效这步没用了).而如果内部累加多次, 相当于这多次都在内部的高速存储上进行, 然后再将这些高速并行得到的, 多个group的结果, 进行最后一步累加即可(慢速的全局存储器上的).如果设置成height*width,每个group内部将变得没有内部高速累加了. 此时将失去意义” “global型的操作越少越好 local型的相关计算越多越好”“globalsize可以使用更大的, 但超级大反而会影响性能下降,因为有两个矛盾的因素:,(1)越小的总线程数, 将导致每个group内部在local memory上的累加越多, 可能对性能有好处. (2)越小的线程数, 可能无法充分利用当前的设备(例如无法充分驻留多个CU, 无法有效的掩盖延迟), 可能对性能有坏处.”


















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











