







我打开AMD-APP-SDK3.0里的例子,我以为可以直接运行,结果不行。就比如这第一个例子:AdvancedConvolution 里需要amdsdk但根本没有相关的头文件和库。后来终于找到了:
然后将这个工程照着例子改成这样,我习惯这样看:
一、advancedNonSeparableConvolution 这个kernel:
main.cpp:
#include <CL/cl.h>
#include "SDKBitMap.hpp"
#include "FilterCoeff.h"
#include "oclUtils.h"
#include "shrQATest.h"
using namespace std;
using namespace streamsdk;
int main()
{
/host datas ready...
cl_uint filterSize=3, filterType=0,useLDSPass1=0;
cl_uint filterRadius,height,width,paddedHeight,paddedWidth;
cl_uchar4 *inputImage2D,*paddedInputImage2D,*nonSepOutputImage2D,*sepOutputImage2D,*nonSepVerificationOutput,*sepVerificationOutput;
cl_float *mask,*rowFilter,*colFilter;
size_t localThreads[2],globalThreads[2];
// Check whether isLds is zero or one
if(useLDSPass1 != 0 && useLDSPass1 != 1)
{
std::cout << "isLds should be either 0 or 1" << std::endl;
return -1;
}
// initialization of mask
if(filterSize != 3 && filterSize != 5)
{
std::cout << "Filter Size should be either 3 or 5" << std::endl;
return -1;
}
if (filterType !=0 && filterType != 1 && filterType !=2)
{
std::cout << "Filter Type can only be 0, 1 or 2 for Sobel, Box and Gaussian filters respectively." << std::endl;
return -1;
}
switch (filterType)
{
case 0: /* Sobel Filter */
if(filterSize == 3)
{
mask = SOBEL_FILTER_3x3;
rowFilter = SOBEL_FILTER_3x3_pass1;
colFilter = SOBEL_FILTER_3x3_pass2;
}
else
{
mask = SOBEL_FILTER_5x5;
rowFilter = SOBEL_FILTER_5x5_pass1;
colFilter = SOBEL_FILTER_5x5_pass2;
}
break;
case 1: /* Box Filter */
if(filterSize == 3)
{
mask = BOX_FILTER_3x3;
rowFilter = BOX_FILTER_3x3_pass1;
colFilter = BOX_FILTER_3x3_pass2;
}
else
{
mask = BOX_FILTER_5x5;
rowFilter = BOX_FILTER_5x5_pass1;
colFilter = BOX_FILTER_5x5_pass2;
}
break;
case 2: /* Gaussian Filter */
if(filterSize == 3)
{
mask = GAUSSIAN_FILTER_3x3;
rowFilter = GAUSSIAN_FILTER_3x3_pass1;
colFilter = GAUSSIAN_FILTER_3x3_pass2;
}
else
{
mask = GAUSSIAN_FILTER_5x5;
rowFilter = GAUSSIAN_FILTER_5x5_pass1;
colFilter = GAUSSIAN_FILTER_5x5_pass2;
}
break;
}
// load input bitmap image
SDKBitMap inputBitmap;
char imgName[]={"/home/jumper/OpenCL_projects/AMD-Sample-AdvancedConvolution/AdvancedConvolution_Input.bmp"};
inputBitmap.load(imgName);
// error if image did not load
if(!inputBitmap.isLoaded())
{
std::cout << "Failed to load input image!";
return SDK_FAILURE;
}
// get width and height of input image
height = inputBitmap.getHeight();
width = inputBitmap.getWidth();
// allocate memory for input image data to host
inputImage2D = (cl_uchar4*)malloc(width * height * sizeof(cl_uchar4));
CHECK_ALLOCATION(inputImage2D,"Failed to allocate memory! (inputImage2D)");
// get the pointer to pixel data
uchar4 *pixelData = inputBitmap.getPixels();
if(pixelData == NULL)
{
std::cout << "Failed to read pixel Data!";
return SDK_FAILURE;
}
// Copy pixel data into inputImageData2D
cl_uint pixelSize=sizeof(uchar4);
memcpy(inputImage2D, pixelData, width * height * pixelSize);
// allocate and initalize memory for padded input image data to host
filterRadius = filterSize - 1;
paddedHeight = height + filterRadius;
paddedWidth = width + filterRadius;
paddedInputImage2D = (cl_uchar4*)malloc(paddedWidth * paddedHeight * sizeof(cl_uchar4));
CHECK_ALLOCATION(paddedInputImage2D,"Failed to allocate memory! (paddedInputImage2D)");
memset(paddedInputImage2D, 0, paddedHeight*paddedWidth*sizeof(cl_uchar4));
for(cl_uint i = filterRadius; i < height + filterRadius; i++)
{
for(cl_uint j = filterRadius; j < width + filterRadius; j++)
{
paddedInputImage2D[i * paddedWidth + j] = inputImage2D[(i - filterRadius) * width + (j - filterRadius)];
}
}
// allocate memory for output image data for Non-Separable Filter to host
nonSepOutputImage2D = (cl_uchar4*)malloc(width * height * sizeof(cl_uchar4));
CHECK_ALLOCATION(nonSepOutputImage2D,"Failed to allocate memory! (nonSepOutputImage2D)");
memset(nonSepOutputImage2D, 0, width * height * pixelSize);
// allocate memory for output image data for Separable Filter to host
sepOutputImage2D = (cl_uchar4*)malloc(width * height * sizeof(cl_uchar4));
CHECK_ALLOCATION(sepOutputImage2D,"Failed to allocate memory! (sepOutputImage2D)");
memset(sepOutputImage2D, 0, width * height * pixelSize);
// allocate memory for verification output
nonSepVerificationOutput = (cl_uchar4*)malloc(width * height * pixelSize);
CHECK_ALLOCATION(nonSepVerificationOutput,"Failed to allocate memory! (verificationOutput)");
sepVerificationOutput = (cl_uchar4*)malloc(width * height * pixelSize);
CHECK_ALLOCATION(sepVerificationOutput,"Failed to allocate memory! (verificationOutput)");
memset(nonSepVerificationOutput, 0, width * height * pixelSize);
memset(sepVerificationOutput, 0, width * height * pixelSize);
size_t blockSizeX=16,blockSizeY=16;
localThreads[0] = blockSizeX;
localThreads[1] = blockSizeY;
// set global work-group size, padding work-items do not need to be considered
globalThreads[0] = (width + localThreads[0] - 1) / localThreads[0];//????????????????? ?
globalThreads[0] *= localThreads[0];
globalThreads[1] = (height + localThreads[1] - 1) / localThreads[1];
globalThreads[1] *= localThreads[1];
//set up OpenCL...
cl_uint platformNum;
cl_int status;
status=clGetPlatformIDs(0,NULL,&platformNum);
if(status!=CL_SUCCESS){
printf("cannot get platforms number.\n");
return -1;
}
cl_platform_id* platforms;
platforms=(cl_platform_id*)alloca(sizeof(cl_platform_id)*platformNum);
status=clGetPlatformIDs(platformNum,platforms,NULL);
if(status!=CL_SUCCESS){
printf("cannot get platforms addresses.\n");
return -1;
}
cl_platform_id platformInUse=platforms[0];
cl_device_id device;
status=clGetDeviceIDs(platformInUse,CL_DEVICE_TYPE_DEFAULT,1,&device,NULL);
cl_context context=clCreateContext(NULL,1,&device,NULL,NULL,&status);
cl_command_queue queue=clCreateCommandQueue(context,device,CL_QUEUE_PROFILING_ENABLE, &status);
std::ifstream srcFile("/home/jumper/OpenCL_projects/AMD-Sample-AdvancedConvolution/convolution.cl");
std::string srcProg(std::istreambuf_iterator<char>(srcFile),(std::istreambuf_iterator<char>()));
const char * src = srcProg.c_str();
size_t length = srcProg.length();
cl_program program=clCreateProgramWithSource(context,1,&src,&length,&status);
status=clBuildProgram(program,1,&device,NULL,NULL,&status);
if (status != CL_SUCCESS)
{
cout<<"error:clBuildProgram()..."<<endl;
shrLogEx(LOGBOTH | ERRORMSG, status, STDERROR);
oclLogBuildInfo(program, oclGetFirstDev(context));
oclLogPtx(program, oclGetFirstDev(context), "oclfluore.ptx");
return(EXIT_FAILURE);
}
cl_kernel nonSeparablekernel = clCreateKernel(program, "advancedNonSeparableConvolution", &status);
CHECK_OPENCL_ERROR(status, "clCreateKernel failed (advancedNonSeparableConvolution).");
///Prepare needed buffers...
//5 buffer
cl_mem inputBuffer = clCreateBuffer(context,CL_MEM_READ_ONLY | CL_MEM_USE_HOST_PTR,pixelSize * paddedWidth * paddedHeight,paddedInputImage2D,&status);
cl_mem outputBuffer = clCreateBuffer(context,CL_MEM_WRITE_ONLY,pixelSize * width * height,NULL,&status);
cl_mem maskBuffer = clCreateBuffer(context,CL_MEM_READ_ONLY | CL_MEM_USE_HOST_PTR,sizeof(cl_float ) * filterSize * filterSize,mask,&status);
cl_mem rowFilterBuffer = clCreateBuffer(context,CL_MEM_READ_ONLY | CL_MEM_USE_HOST_PTR,sizeof(cl_float ) * filterSize,rowFilter,&status);
cl_mem colFilterBuffer = clCreateBuffer(context,CL_MEM_READ_ONLY | CL_MEM_USE_HOST_PTR,sizeof(cl_float ) * filterSize,colFilter,&status);
///launch the non-Separate kernel...
cl_event event0;
// Set appropriate arguments to the kernel
status = clSetKernelArg(nonSeparablekernel, 0,sizeof(cl_mem),(void *)&inputBuffer);
CHECK_OPENCL_ERROR( status, "clSetKernelArg failed. (inputBuffer)");
status = clSetKernelArg(nonSeparablekernel, 1, sizeof(cl_mem),(void *)&maskBuffer);
CHECK_OPENCL_ERROR( status, "clSetKernelArg failed. (maskBuffer)");
status = clSetKernelArg(nonSeparablekernel, 2,sizeof(cl_mem),(void *)&outputBuffer);
CHECK_OPENCL_ERROR( status, "clSetKernelArg failed. (outputBuffer)");
status = clSetKernelArg(nonSeparablekernel,3,sizeof(cl_uint),(void *)&width);
CHECK_OPENCL_ERROR( status, "clSetKernelArg failed. (width)");
status = clSetKernelArg(nonSeparablekernel,4, sizeof(cl_uint),(void *)&height);
CHECK_OPENCL_ERROR( status, "clSetKernelArg failed. (height)");
status = clSetKernelArg(nonSeparablekernel,5,sizeof(cl_uint),(void *)&paddedWidth);
CHECK_OPENCL_ERROR( status, "clSetKernelArg failed. (paddedWidth)");
// Enqueue a kernel run call.
status = clEnqueueNDRangeKernel(queue,nonSeparablekernel,2,NULL,globalThreads,localThreads,0, NULL,&event0);
CHECK_OPENCL_ERROR( status, "clEnqueueNDRangeKernel failed.");
status = clFlush(queue);
CHECK_OPENCL_ERROR(status,"clFlush() failed");
status = clWaitForEvents(1,&event0);
CHECK_ERROR(status, SDK_SUCCESS, "WaitForEventAndRelease(events[0]) Failed");
clReleaseEvent(event0);
status = clEnqueueReadBuffer(queue,outputBuffer,CL_TRUE,0,width * height * pixelSize,nonSepOutputImage2D,0,NULL,NULL);
CHECK_OPENCL_ERROR( status, "clEnqueueReadBuffer(nonSepOutputImage2D) failed.");
memcpy(pixelData, nonSepOutputImage2D, width * height * pixelSize);
// write the output bmp file
if(!inputBitmap.write("NonSeparableOutputImage.bmp"))
{
std::cout << "Failed to write output image!";
return SDK_FAILURE;
}
/clean up all variables...
if (nonSeparablekernel != NULL)
{
status = clReleaseKernel(nonSeparablekernel);
CHECK_OPENCL_ERROR(status, "clReleaseKernel failed.(nonSeparablekernel)");
}
if (program)
{
status = clReleaseProgram(program);
CHECK_OPENCL_ERROR(status, "clReleaseProgram failed.(program)");
}
if (inputBuffer)
{
status = clReleaseMemObject(inputBuffer);
CHECK_OPENCL_ERROR(status, "clReleaseMemObject failed.(inputBuffer)");
}
if (outputBuffer)
{
status = clReleaseMemObject(outputBuffer);
CHECK_OPENCL_ERROR(status, "clReleaseMemObject failed.(outputBuffer)");
}
if (maskBuffer)
{
status = clReleaseMemObject(maskBuffer);
CHECK_OPENCL_ERROR(status, "clReleaseMemObject failed.(maskBuffer)");
}
if (rowFilterBuffer)
{
status = clReleaseMemObject(rowFilterBuffer);
CHECK_OPENCL_ERROR(status, "clReleaseMemObject failed.(rowFilterBuffer)");
}
if(colFilterBuffer)
{
status = clReleaseMemObject(colFilterBuffer);
CHECK_OPENCL_ERROR(status, "clReleaseMemObject failed.(colFilterBuffer)");
}
if (queue)
{
status = clReleaseCommandQueue(queue);
CHECK_OPENCL_ERROR(status, "clReleaseCommandQueue failed.(commandQueue)");
}
if (context)
{
status = clReleaseContext(context);
CHECK_OPENCL_ERROR(status, "clReleaseContext failed.(context)");
}
// release program resources (input memory etc.)
FREE(inputImage2D);
FREE(paddedInputImage2D);
FREE(nonSepOutputImage2D);
FREE(sepOutputImage2D);
FREE(nonSepVerificationOutput);
FREE(sepVerificationOutput);
return 0;
}#define FILTERSIZE 3
__kernel void advancedNonSeparableConvolution(
__global uchar4 *input,
__global float *mask,
__global uchar4 *output,
uint nWidth,
uint nHeight,
uint nExWidth)
{
int col = get_global_id(0);
int row = get_global_id(1);
if (col >= nWidth || row >= nHeight) return;
int lid_x = get_local_id(0);
int lid_y = get_local_id(1);
int start_col, start_row;
int cnt = 0;
#if 1
//#USE_LDS == 1
__local uchar4 local_input[(16 + 3 - 1) * (16 + 3 - 1)];
int tile_xres = (16 + 3 - 1);
int tile_yres = (16 + 3 - 1);
start_col = get_group_id(0) * 16; //Image is padded
start_row = get_group_id(1) * 16;
int lid = lid_y * 16 + lid_x;
int gx, gy;
do {
gy = lid / tile_xres;
gx = lid - gy * tile_xres;
local_input[lid] = input[(start_row + gy) * nExWidth + (start_col + gx)];
lid += (16 * 16);
} while (lid < (tile_xres * tile_yres));
barrier(CLK_LOCAL_MEM_FENCE);
start_col = lid_x;
start_row = lid_y;
#else
start_col = col;
start_row = row;
#endif
float4 sum = (float4)0.0f;
int m = 0, n = 0;
#pragma unroll 16
for (int j = start_row; j < start_row + FILTERSIZE; j++,m++)
{
n = 0;
for (int i = start_col; i < start_col + FILTERSIZE; i++,n++)
{
//#if USE_LDS == 1
#if 1
{
sum = mad(convert_float4(local_input[j * tile_xres + i]), (float4)mask[m * FILTERSIZE + n], sum);//a*b+c
}
#else
{
sum = mad(convert_float4(input[(j)*nExWidth + (i)]), (float4)mask[m * FILTERSIZE + n], sum);
}
#endif
}
}
output[row * nWidth + col] = (convert_uchar4_sat)(sum);
}其实这个kernel就这两步。巧妙之处:先将图像扩展边界;利用SDKBitMap库即决定了后续要利用uchar4 float4节约空间并且快读读到像素值;利用LDS缓冲加速;每个item负责一个像素点的卷积;很机智的使用了#pragma unroll 16!
要我设计的话,可能不会这样面面俱到!我要学习这些方法(提高性能前路漫长)
用CodeXL看了device上的时间:0.9670
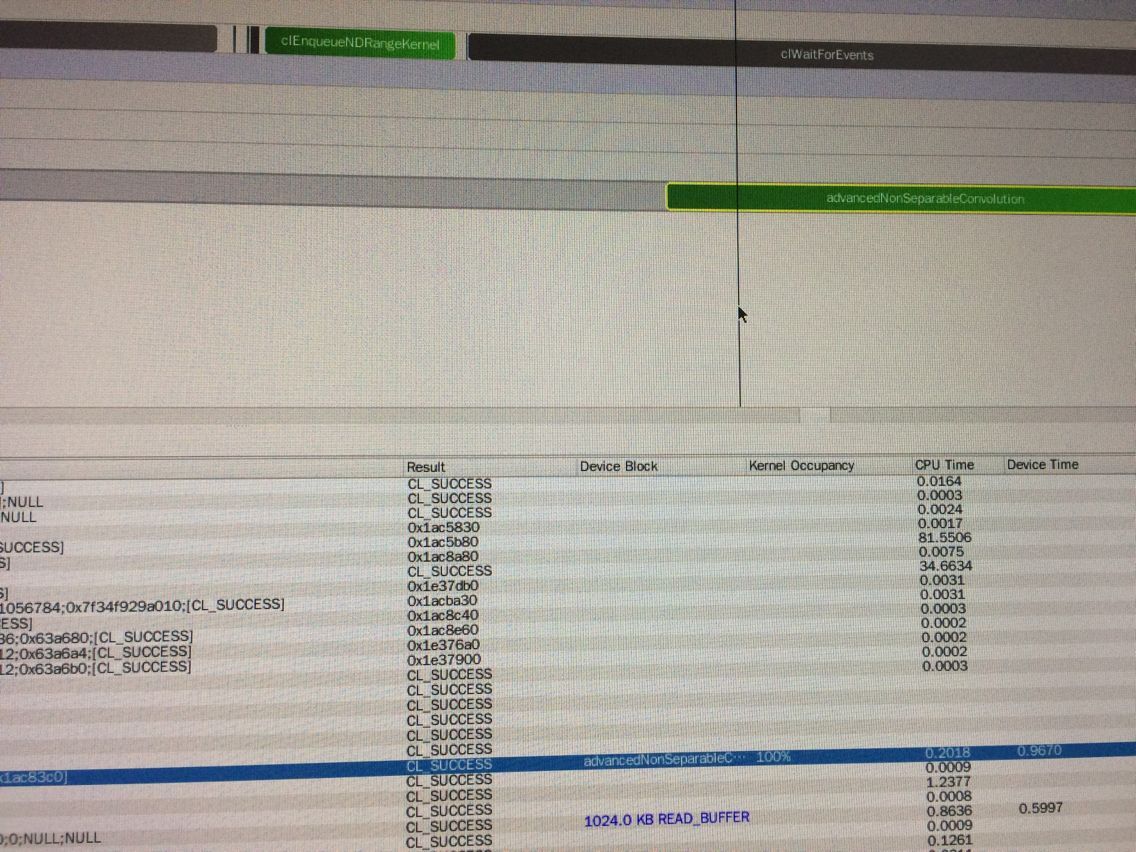
二、advancedSeparableConvolution 这个kernel:
main.cpp上其实没什么差别,和上面几乎差不多,就不废话了。重要的是kernel上蕴含的思想!
#define FILTERSIZE 3
__kernel void advancedSeparableConvolution(
__global uchar4 *input,
__global float *row_filter,
__global float *col_filter,
__global uchar4 *output,
uint nWidth,
uint nHeight,
uint nExWidth)
{
__local float4 local_output[16 * (16 + FILTERSIZE - 1)];
int col = get_global_id(0);
int row = get_global_id(1);
if (col >= nWidth || row >= nHeight) return;
int lid_x = get_local_id(0);
int lid_y = get_local_id(1);
int start_col, start_row;
int cnt = 0;
/***************************************************************************************
* If using LDS, get the data to local memory. Else, get the global memory indices ready
***************************************************************************************/
//#if USE_LDS == 1
#if 1
__local uchar4 local_input[(16 + FILTERSIZE - 1) * (16 + FILTERSIZE - 1)];
int tile_xres = (16 + FILTERSIZE - 1);
int tile_yres = (16 + FILTERSIZE - 1);
start_col = get_group_id(0) * 16; //Image is padded
start_row = get_group_id(1) * 16;
int lid = lid_y * 16 + lid_x;
int gx, gy;
/*********************************************************************
* Read input from global buffer and put in local buffer
* Read 256 global memory locations at a time (256 WI).
* Conitnue in a loop till all pixels in the tile are read.
**********************************************************************/
do {
gy = lid / tile_xres;
gx = lid - gy * tile_xres;
local_input[lid] = input[(start_row + gy) * nExWidth + (start_col + gx)];
lid += (16 * 16);
} while (lid < (tile_xres * tile_yres));
barrier(CLK_LOCAL_MEM_FENCE);
start_col = lid_x;
#else
/************************************************************************
* Non - LDS implementation
* Read pixels directly from global memory
************************************************************************/
start_col = col;
#endif
/***********************************************************************************
* Row-wise convolution - Inputs will be read from local or global memory
************************************************************************************/
float4 sum = (float4)0.0f;
cnt = 0;
#pragma unroll FILTERSIZE
for (int i = start_col; i < start_col + FILTERSIZE; i++)
{
//#if USE_LDS == 1
#if 1
sum = mad(convert_float4(local_input[lid_y * tile_xres + i]), (float4)row_filter[cnt++], sum);
#else
sum = mad(convert_float4(input[row * nExWidth + i]), (float4)row_filter[cnt++], sum);
#endif
}
/***********************************************************************************
* Output is stored in local memory
************************************************************************************/
local_output[lid_y * 16 + lid_x] = sum;
/***************************************************************************************
* Row-wise convolution of pixels in the remaining rows
***************************************************************************************/
if (lid_y < FILTERSIZE - 1)
{
cnt = 0;
sum = (float4)0.0f;
#pragma unroll FILTERSIZE
for (int i = start_col; i < start_col + FILTERSIZE; i++)
{
//#if USE_LDS == 1
#if 1
sum = mad(convert_float4(local_input[(lid_y + 16) * tile_xres + i]), (float4)row_filter[cnt++], sum);
#else
sum = mad(convert_float4(input[(row + 16) * nExWidth + i]), (float4)row_filter[cnt++], sum);
#endif
}
/***********************************************************************************
* Again the output is stored in local memory
************************************************************************************/
local_output[(lid_y + 16) * 16 + lid_x] = sum;
}
/***********************************************************************************
* Wait for all the local WIs to finish row-wise convolution.
************************************************************************************/
barrier(CLK_LOCAL_MEM_FENCE);
/************************************************************************************
* Column-wise convolution - Input is the output of row-wise convolution
* Inputs are always read from local memory.
* The output is written to global memory.
***********************************************************************************/
start_row = lid_y;
sum = (float4)0.0f;
cnt = 0;
#pragma unroll FILTERSIZE
for (int i = start_row; i < start_row + FILTERSIZE; i++)
{
sum = mad(local_output[i * 16 + lid_x], (float4)col_filter[cnt++], sum);
}
/* Save Output */
sum = (sum < 0.0f) ? 0.0f : sum;
output[row * nWidth + col] = (convert_uchar4_sat_rte)(sum);
}这个kernel比上一个kernel更妙。巧妙之处:先将图像扩展边界;利用SDKBitMap库即决定了后续要利用uchar4 float4节约空间并且快读读到像素值;利用LDS缓冲加速;每个item先负责一个像素点的横向卷积然后再复制纵向卷积;很机智的使用了#pragma unroll 3以及每个item所属的cnt++!
感受:AMD-OpenCL-SDK的例子的确比Nvidia-OpenCL-SDK的例子要好,更适合跟着学习如何实际一个kernel如何提高性能!!!
弄懂了开心。
















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











