










NIPS 2023
paper
code
通过diffusion模型生成海量的合成数据用于RL策略以及价值函数训练,在离线以及在线设定下均表现优异,并且适用于pixel-based的RL设定,同时允许提高UTD进一步提升sample efficiency
Method

算法伪代码如下:

方法很简单,就是利用已有数据训练diffusions model生成数据,然后与原始数据混合采样。在线设定下的原始数据就是环境交互得到的真实数据,离线设定下则就是所提供的数据。
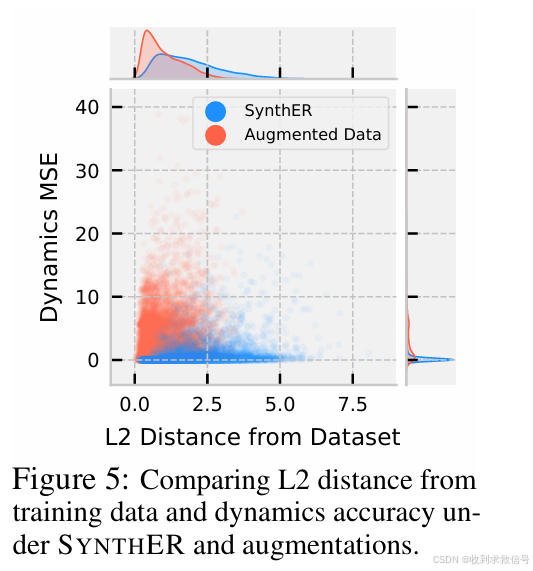
文章分析为何diffusion-based的生成模型对比VAE以及GAN的其他方法有效。原因是该方法生成的数据在保证更好的差异性同时,与真原始数据的MSE较低,也就是说明生成数据更符合环境动力学
海量数据的产生意味着,能够对基于TD3+BC的策略以及价值模型结构进行扩展,实现performance的提升,但是对于IQL以及EDAC提升不明显:
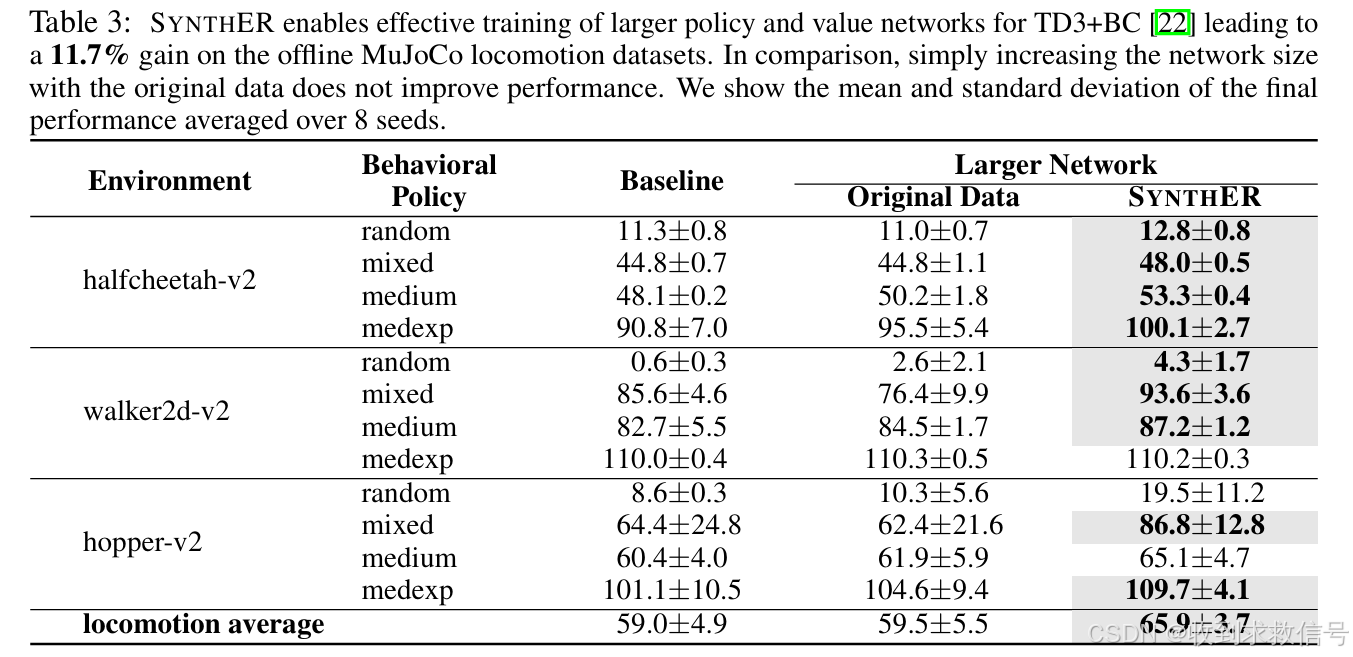
(是否是因为BC项的存在,使得TD3+BC符合Scaling law)
结果
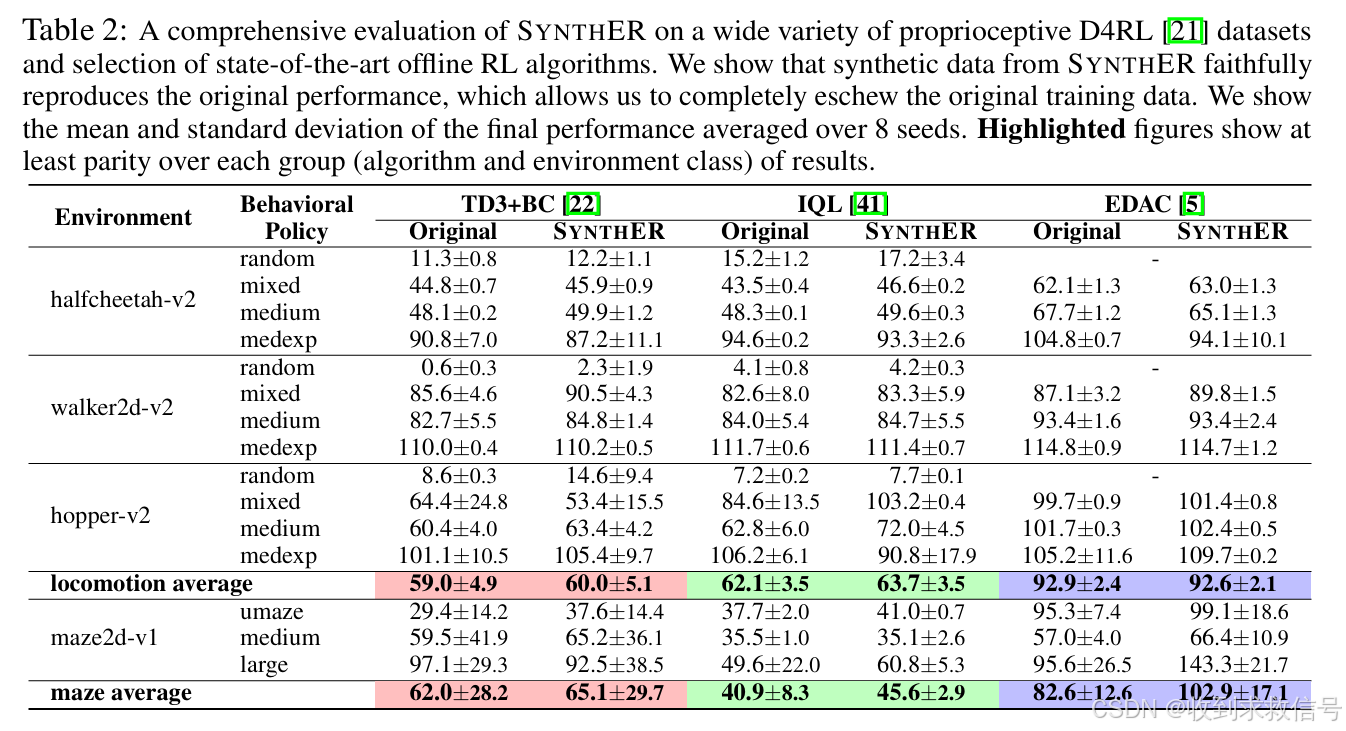
离线结果
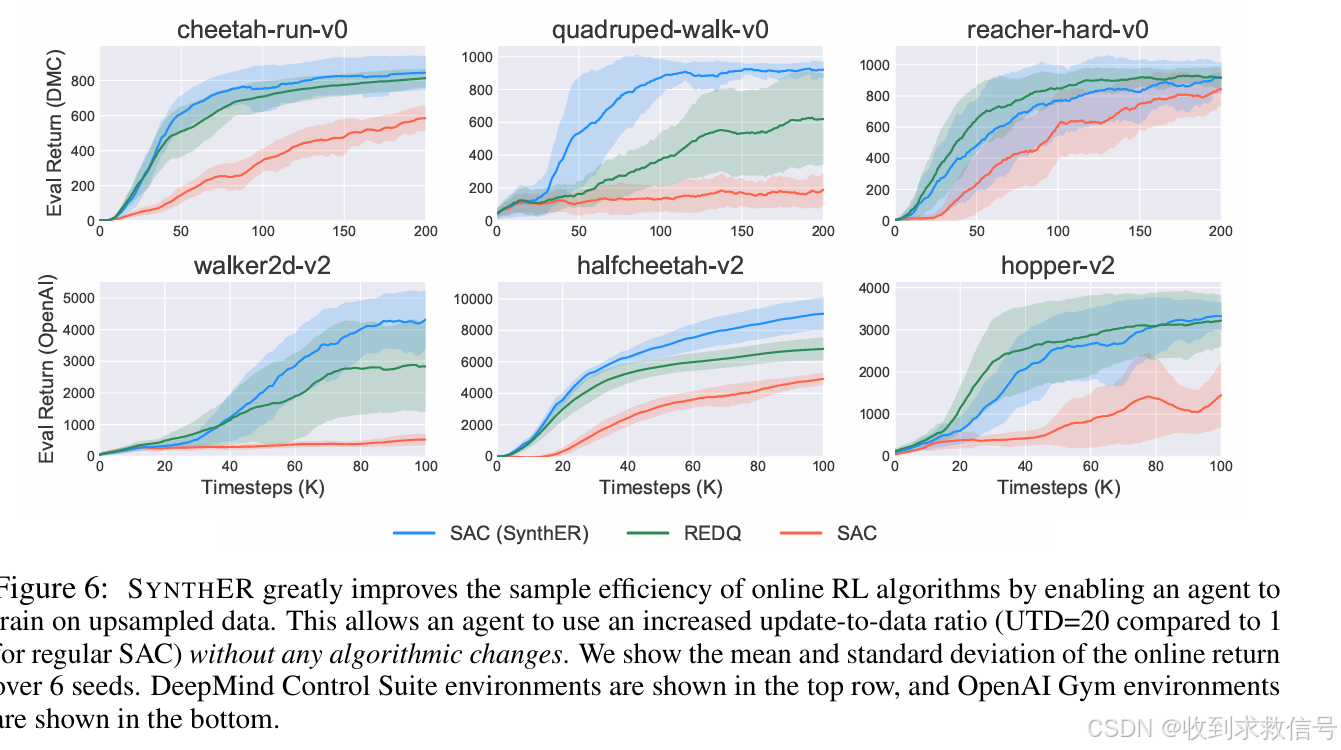
在线设定下的结合SAC便能达到甚至超越REDQ的性能
其他
离线设定下效果,感觉在maze上的提升明显,在连环控制上不太突出。是否意味着diffusion-based的方法通过生成丰富的合成数据,极高的提升探索能力(还不与环境交互),未来该解决在此基础上精确利用,实现二者的平衡


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









