







一:背景
Hadoop2.0开始MapReduce作业支持链式处理,类似于富士康生产苹果手机的流水线,每一个阶段都有特定的任务要处理,比如提供原配件——>组装——打印出厂日期,等等。通过这样进一步的分工,从而提高了生成效率,我们Hadoop中的链式MapReduce也是如此,这些Mapper可以像水流一样,一级一级向后处理,有点类似于Linux的管道。前一个Mapper的输出结果直接可以作为下一个Mapper的输入,形成一个流水线。
注:链式MapReduce的执行规则:整个Job中只能有一个Reducer,在Reducer前面可以有一个或者多个Mapper,在Reducer的后面可以有0个或者多个Mapper。
二:技术实现
#需求:现有如下销售数据,要求使用链式MapReduce,在第一个Mapper中过滤金额大于10000的数据,在第二个Mapper中过滤数据在100-10000之间的数据,在Reduce中进行分类汇总,在Reduce后面的Mapper中过滤掉商品名长度大于8的数据。
-
Phone 5000
-
Computer 2000
-
Clothes 300
-
XieZi 1200
-
QunZi 434
-
ShouTao 12
-
Books 12510
-
SmallShangPing 5
-
SmallShangPing 3
-
DingCan 2
实现代码:
-
public class ChainMapReduce {
-
-
// 定义输入输出路径
-
private static final String INPUTPATH = "hdfs://liaozhongmin21:8020/chainFiles/*";
-
private static final String OUTPUTPATH = "hdfs://liaozhongmin21:8020/out";
-
-
public static void main(String[] args) {
-
-
try {
-
-
Configuration conf = new Configuration();
-
// 创建文件系统
-
FileSystem fileSystem = FileSystem.get( new URI(OUTPUTPATH), conf);
-
-
// 判断输出路径是否存在,如果存在则删除
-
if (fileSystem.exists( new Path(OUTPUTPATH))) {
-
fileSystem.delete( new Path(OUTPUTPATH), true);
-
}
-
-
// 创建Job
-
Job job = new Job(conf, ChainMapReduce.class.getSimpleName());
-
-
// 设置输入目录
-
FileInputFormat.addInputPath(job, new Path(INPUTPATH));
-
// 设置输入文件格式
-
job.setInputFormatClass(TextInputFormat.class);
-
-
// 设置自定义的Mapper类
-
ChainMapper.addMapper(job, FilterMapper1.class, LongWritable.class, Text.class, Text.class, DoubleWritable.class, conf);
-
ChainMapper.addMapper(job, FilterMapper2.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf);
-
ChainReducer.setReducer(job, SumReducer.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf);
-
// 注:Reducer后面的Mapper也要用ChainReducer进行加载
-
ChainReducer.addMapper(job, FilterMapper3.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf);
-
-
// 设置自定义Mapper类的输出key和value
-
job.setMapOutputKeyClass(Text.class);
-
job.setMapOutputValueClass(DoubleWritable.class);
-
-
// 设置分区
-
job.setPartitionerClass(HashPartitioner.class);
-
// 设置reducer数量
-
job.setNumReduceTasks( 1);
-
-
// 设置自定义的Reducer类
-
// 设置输出的Key和value类型
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(DoubleWritable.class);
-
-
// 设置输出路径
-
FileOutputFormat.setOutputPath(job, new Path(OUTPUTPATH));
-
// 设置输出格式
-
job.setOutputFormatClass(TextOutputFormat.class);
-
-
// 提交任务
-
System.exit(job.waitForCompletion( true) ? 0 : 1);
-
-
} catch (Exception e) {
-
e.printStackTrace();
-
}
-
}
-
-
-
/**
-
* 过滤掉金额大于10000的记录
-
* @author 廖钟民 2015年3月17日下午6:27:05
-
*/
-
public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, DoubleWritable> {
-
-
// 定义输出的key和value
-
private Text outKey = new Text();
-
private DoubleWritable outValue = new DoubleWritable();
-
-
-
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context) throws IOException,
-
InterruptedException {
-
-
// 获取行文本内容
-
String line = value.toString();
-
-
if (line.length() > 0) {
-
// 对行文本内容进行切分
-
String[] splits = line.split( "\t");
-
// 获取money
-
double money = Double.parseDouble(splits[ 1].trim());
-
// 过滤
-
if (money <= 10000) {
-
// 设置合法结果
-
outKey.set(splits[ 0]);
-
outValue.set(money);
-
// 把合法结果写出去
-
context.write(outKey, outValue);
-
}
-
}
-
}
-
}
-
-
/**
-
* 过滤掉金额大于100的记录
-
* @author 廖钟民 2015年3月17日下午6:29:27
-
*/
-
public static class FilterMapper2 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> {
-
-
-
protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException,
-
InterruptedException {
-
if (value.get() < 100) {
-
-
// 把结果写出去
-
context.write(key, value);
-
}
-
}
-
}
-
-
/**
-
* 金额汇总
-
* @author 廖钟民
-
*2015年3月21日下午1:46:47
-
*/
-
public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
-
// 定义输出的value
-
private DoubleWritable outValue = new DoubleWritable();
-
-
-
protected void reduce(Text key, Iterable<DoubleWritable> values, Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context)
-
throws IOException, InterruptedException {
-
-
// 定义汇总结果
-
double sum = 0;
-
// 遍历结果集进行统计
-
for (DoubleWritable val : values) {
-
-
sum += val.get();
-
}
-
// 设置输出value
-
outValue.set(sum);
-
// 把结果写出去
-
context.write(key, outValue);
-
}
-
}
-
-
/**
-
* 过滤商品名称长度小于8的商品
-
* @author 廖钟民
-
*2015年3月21日下午1:47:01
-
*/
-
public static class FilterMapper3 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> {
-
-
-
protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException,
-
InterruptedException {
-
// 过滤
-
if (key.toString().length() < 8) {
-
// 把结果写出去
-
System.out.println( "写出去的内容为:" + key.toString() + "++++"+ value.toString());
-
context.write(key, value);
-
}
-
}
-
-
}
-
-
}
-
-
-
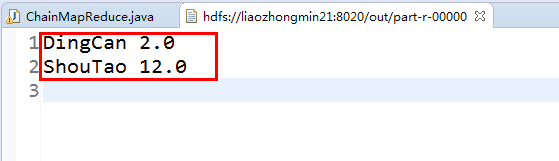
输出结果:














 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









