







Python2.x:
简而言之,Python 2.x里字符串有两种:str和Unicode
前者到后者要decode,后者到前者要encode,'utf-8'为例:
str.decode('utf-8') -> Unicode
str <- Unicode.encode('utf-8')
建议一、使用字符编码声明,并且同一工程中的所有源代码文件使用相同的字符编码声明
#encoding=utf-8
建议二、抛弃str,全部使用unicode
test1 = 'présenter'
test2 = u'汉字'print type(test1)test_unicode = test1.decode('utf-8')print type(test_unicode)print ("%s+%s" % (test_unicode, test2)).encode('utf-8')
终极原则:decode early, unicode everywhere, encode late
即:在输入或者声明字符串的时候,尽早地使用decode方法将字符串转化成unicode编码格式;然后在程序内使用字符串的时候统一使用unicode格式进行处理,比如字符串拼接、字符串替换、获取字符串的长度等操作;最后,在输出字符串的时候(控制台/网页/文件),通过encode方法将字符串转化为你所想要的编码格式,比如utf-8等。按照这个原则处理Python的字符串,基本上可以解决所有的编码问题(只要你的代码和Python环境没有问题)。
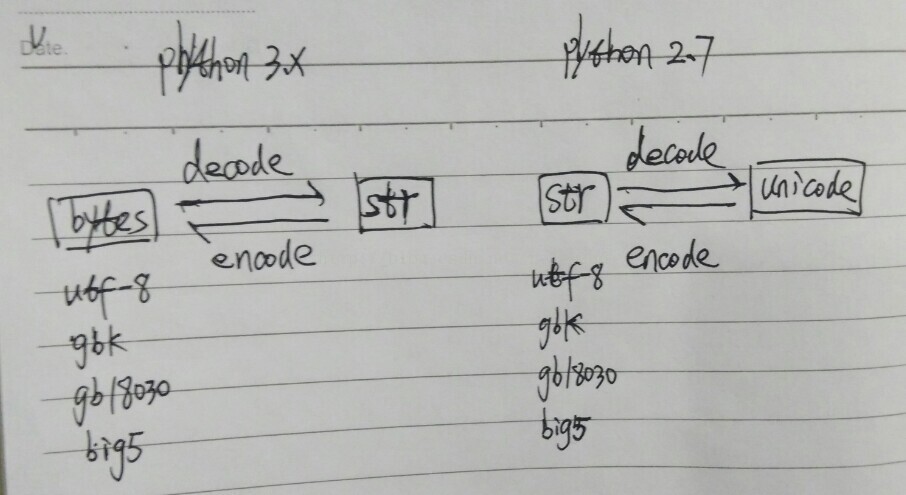
Python3.x:
在python3以后的版本中,str默认已经为unicode格式。当然也可以使用b''来定义bytes的string。
但是有的时候我们需要对str进行ASCII和Unicode间转化,unicode的str的转化bytes时使用str.encode(),bytes的str转化为unicode时使用str.decode()。














 3262
3262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









