







文章目录
本次需要用到软件:
1. 安装虚拟机
- 下载
- 安装
- 打开
2. 安装centos7
- 选择
- 选择
- 选择
- 下一步
- 配置网卡信息
3. 安装hadoop
-
静态IP的配置
1.1 打开网络配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens331.2 配置文件需要添加
IPADDR=ip地址 NETMASK=255.255.255.0 DNS=8.8.8.8 -
更改主机名
vi /etc/hostname -
配置本地域名解析(host)
vi /etc/hosts -
设置linux防火墙
关闭防火墙:
service iptables status;#查看防火墙状态 service iptables start;#立即开启防火墙,但是重启后失效。 service iptables stop;#立即关闭防火墙,但是重启后失效。 重启后生效 chkconfig iptables on;#开启防火墙,重启后生效 chkconfig iptables off;#关闭防火墙,重启后生效防火墙配置文件:
sudo vi /etc/sysconfig/selinux# This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled #=========>这里需要配置成disabled # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted -
配置ssh(免密连接)
ssh-keygen -t rsa -P ‘’~/.ssh/id_rsa
ssh-copy -id 主机名(这里需要执行两次命令,分别配置到另外两台主机)
配置免密:
cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys验证:
ssh 主机名推出:
exit -
安装java
- rpm安装jdk
下载或者是找到本机的rpm安装包(
rpm -aq | grep jdk) java jdkrpm -i jdk-7u67-linux-x64.rpmwhereis javavi + /etc/profileexport JAVA_HOME=/usr/bin/javaexport PATH=$PATH:$JAVA_HOME/bin更新包:
source /etc/profile-
通过yum安装jdk :
sudo yum install java -
通过压缩包安装jdk
-
下载
JDK压缩包:wget https://javadl.oracle.com/webapps/download/AutoDL?BundleId=245469_4d5417147a92418ea8b615e228bb6935 -
解压:
tar -zxf 文件名 -C 对应路径 -
配置java环境变量(我的如下)
export JAVA_HOME=/usr/local/java/jdk#(此处填对应的java路径——> 即是你的解压路径)
export JRE_HOME= J A V A H O M E / j r e e x p o r t C L A S S P A T H = . : JAVA_HOME/jre export CLASSPATH=.: JAVAHOME/jreexportCLASSPATH=.:JAVA_HOME/lib/dt.jar: J A V A H O M E / l i b / t o o l s . j a r e x p o r t P A T H = JAVA_HOME/lib/tools.jar export PATH= JAVAHOME/lib/tools.jarexportPATH=PATH:$JAVA_HOME/bin
-
安装hadoop
-
下载hadoop(或者是通过ssh软件进行上传======>通用的ssh软件有xshell,finalshell)
$ wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.2/hadoop-2.7.2.tar.gz # 下载hadoop软件
-
解压安装
$ sudo tar -zxf ~/
下载文件的路径/hadoop-2.7.1.tar.gz -C /usr/local
$ cd /usr/local/
$ sudo mv ./hadoop-2.7.1/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop ./hadoop # 修改文件权限
-
-
安装配置
首先需要进行环境变量的配置(每个节点都需要配置):
需要在
/etc/profile添加如下环境:export HADOOP_INSTALL=`你安装hadoop的路径`/hadoop-2.7.2 export PATH=$PATH:${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin # 我的配置路径是: # export HADOOP_INSTALL=/usr/local/hadoop # export PATH=$PATH:${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin环境变量配置好后记得更新:
source /etc/profile对hadoop进行java环境的配置
无论是哪种安装方式都需要提前做好免密登录:
ssh-keygen -t rsa cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys- 独立模式(单机模式):无需任何守护进程,所有程序都在同一个 JVM 上执行,开发阶段测试和调试 MapReduce 程序很方便
- 伪分布模式:守护进程运行在本地机器上,模拟小规模的集群
- 全分布模式:守护进程运行在集群上
文件描述 :
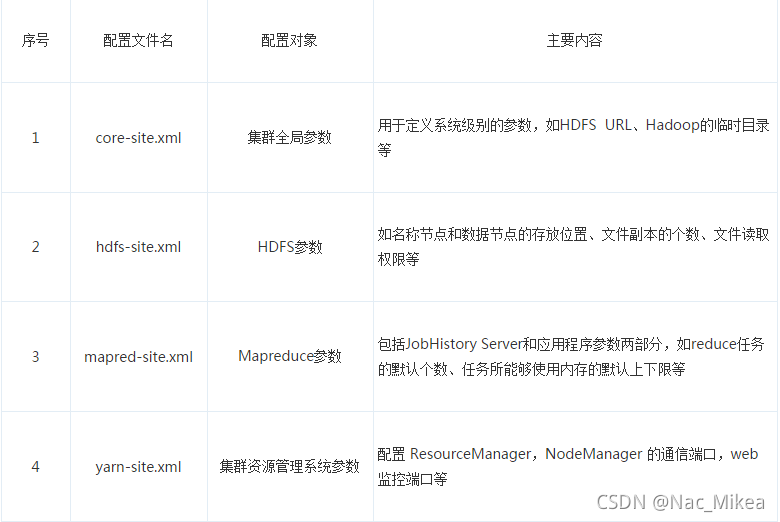
a.下载解压配置
b.独立安装时默认的无需进行配置
- 独立安装需要的配置文件:
`配置写入JAVA_HOME`
- 加入代码片段: ```sh <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost.localdomain:9000</value> <description>hdfs内部通讯访问地址</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/data/</value> <description>hadoop数据存放</description> </property> </configuration> ```
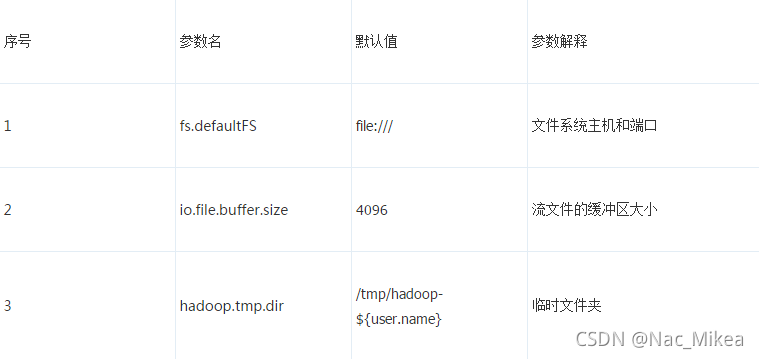
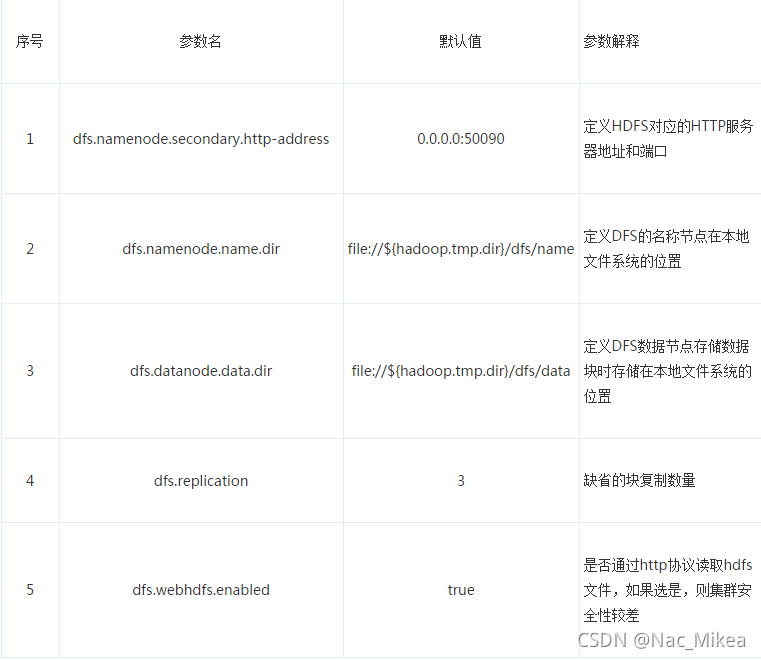
- 加入configuration片段 <!-- # replication 副本数量 # 因为是伪分布式 设置为1 # 新版本的 hadoop 块默认大小为128mb --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
# yran 集群 mv mapred-site.xml.template mapred-site.xml # 配置代码片段 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>

<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost.localdomain</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
启动dfs
- 格式化hadoop文件系统
cd /usr/local/hadoop ./bin/hdfs namenode -format
-
启动dfs
./sbin/start-dfs.sh - jps 查看服务是否已经启动(启动的进程有5个) [hadoop@localhost hadoop]$ jps 6466 NameNode 6932 Jps 6790 SecondaryNameNode 6584 DataNode - 全部启动 ./sbin/start-all.sh - 启动后截图: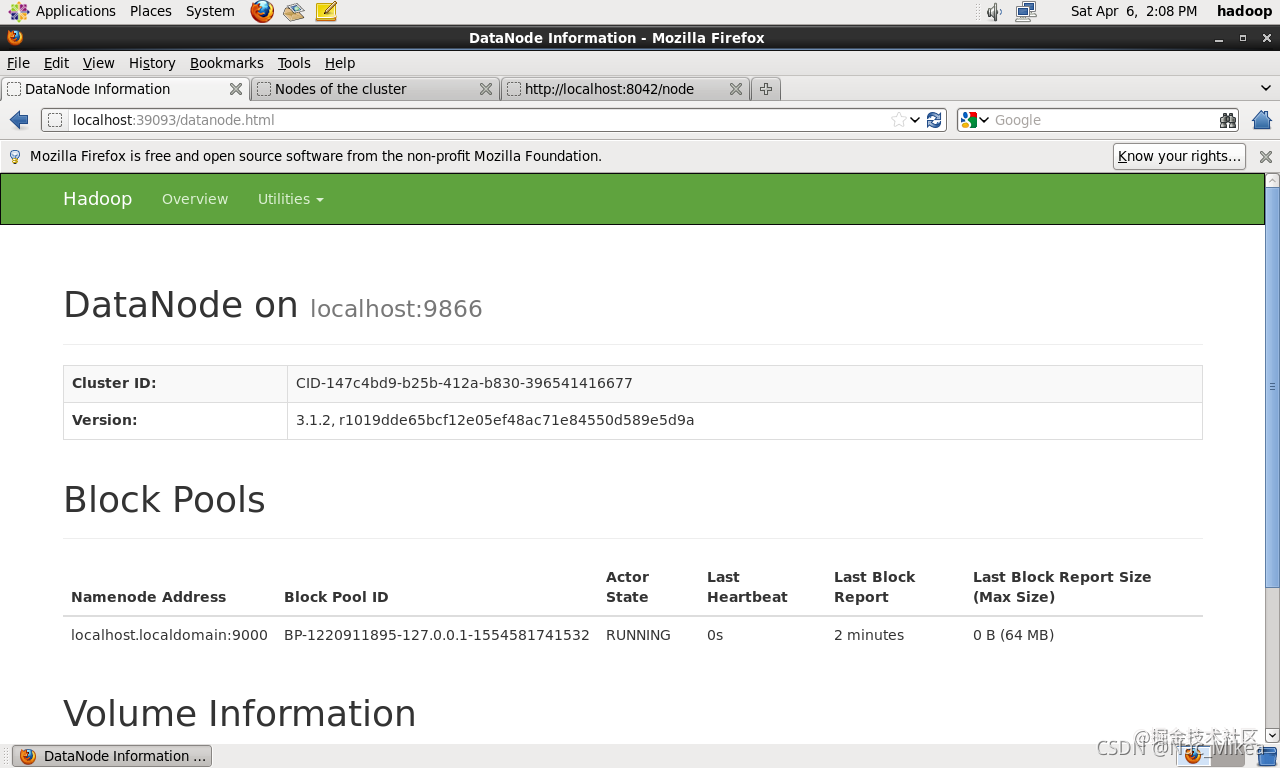
远程copy
scp -r 本地文件路径 主机名:/对应文件路径异常处理
-
Error: Cannot find configuration directory: /etc/hadoop
解决方式: 在
hadoop-env.sh添加export HADOOP_CONF_DIR=/usr/hadoop-2.6.1/etc/hadoop/然后再更新 source hadoop-env.sh
或者是:
export HADOOP_HOME= # 自己安装的路径 export HADDOP_HOME=/usr/local/hadoop export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
Exception in thread “main” java.lang.IllegalArgumentException异常处理
- 原因:
因为我们在程序中,通常会将代码以打jar包的方式,放到集群中运行,所以会导入hdfs-site.xml和core-site.xml等文件,当我们导入这两个文件的后,再次运行程序时会读取到该文件,因此会访问hdfs存储系统中的目录,因此会报错。
- 解决方法:
将这两个文件名添加后缀.bak,如上图所示,问题就解决了。
-
问题:
localhost: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).解决:
如果无法使用ssh无密码连接其他节点的主机,那么在启动hadoop的时候会出现的输入其他主机的密码,即使正确输入也无法认证
-
问题:localhost: ERROR: Unable to write in /usr/local/hadoop/logs. Aborting.
解决:
sudo chmod 777 -R /usr/local/hadoop/ -
问题:
localhost: /usr/local/hadoop/bin/…/libexec/hadoop-functions.sh: line 1842: /tmp/hadoop-hadoop-namenode.pid: Permission denied
localhost: ERROR: Cannot write namenode pid /tmp/hadoop-hadoop-namenode.pid
解决:
修改
hadoop-env.shexport HADOOP_PID_DIR=/usr/local/hadoop/tmp/pid-
问题:
[hadoop@localhost hadoop]$ ./sbin/start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [localhost] 2019-04-06 07:26:22,110 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable解决:
cd /usr/local/hadoop/lib ldd libhadoop.so.1.0.0 ./libhadoop.so.1.0.0: /lib64/libc.so.6: version `GLIBC_2.14' not found (required by ./libhadoop.so.1.0.0) linux-vdso.so.1 => (0x00007fff901ff000) libdl.so.2 => /lib64/libdl.so.2 (0x00007f8ceda5d000) libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f8ced83f000) libc.so.6 => /lib64/libc.so.6 (0x00007f8ced4ac000) /lib64/ld-linux-x86-64.so.2 (0x00000031c1e00000) # download wget http://ftp.gnu.org/gnu/glibc/glibc-2.14.tar.bz2 wget http://ftp.gnu.org/gnu/glibc/glibc-linuxthreads-2.5.tar.bz2 # 解压 tar -xjvf glibc-2.14.tar.bz2 cd glibc-2.14 tar -xjvf ../glibc-linuxthreads-2.5.tar.bz2 # 加上优化开关,否则会出现错误'#error "glibc cannot be compiled without optimization"' cd ../ export CFLAGS="-g -O2" glibc-2.14/configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin --disable-sanity-checks make sudo make install -
问题:
2019-04-06 13:08:58,376 INFO util.ExitUtil: Exiting with status 1: java.io.IOException: Cannot remove current directory: /usr/local/data/hadoop/tmp/dfs/name/current解决:
问题原因是权限问题
sudo chown -R hadoop:hadoop /usr/local/data/hadoop/tmp sudo chmod -R a+w /usr/local/data/hadoop/tmp
-
配置参考
-
core-site.xml配置参考:http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-common/core-default.xml
-
hdfs-site.xml配置参考:http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
-
mapred-site.xml配置参考:http://hadoop.apache.org/docs/r2.3.0/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
-
yarn-site.xml配置参考:http://hadoop.apache.org/docs/r2.3.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml















 7776
7776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









